
UGMathBench:评估语言模型数学推理能力的动态基准测试数据集
近年来,人工智能蓬勃发展,自然语言模型(LLM)进展显著。语言模型被广泛应用于自动翻译、智能客服、甚至医疗、金融、天气等领域。而研究者们仍在不断努力,致力于提高语言模型的规模和性能。随着语言模型的蓬勃
01.摘要
近年来,人工智能蓬勃发展,自然语言模型(LLM)进展显著。语言模型被广泛应用于自动翻译、智能客服、甚至医疗、金融、天气等领域。而研究者们仍在不断努力,致力于提高语言模型的规模和性能。随着语言模型的蓬勃发展,评估一个语言模型的性能变得越来越重要。其中一个重要的评估指标,就是衡量语言模型的推理能力和解决数学问题的能力。
在数学领悟中,几年前的基准测试数据集逐渐被快速进步的模型所攻克。新的语言模型往往能在这些数据集上获得90% 以上的准确率。于是,人们开始引入更具挑战性的基准测试,在不同的专业和水平上挖掘并建立更具挑战性的数据集。然而,这些数据集在本科数学方面的范围和规模的覆盖有限。
与此同时,数据污染问题越来越受到重视。人们发现有些基准测试的数据集可能直接出现在了某些语言模型的训练集中。为了避免这一问题,人们引入了动态的数据集:对旧的数据集进行功能化,以通过变量改变数学问题中的数字,从而产生随机变化的动态问题。
为了填补本科数学这一领域的空白,并且保证数据的动态化,团队从在线作业评分系统中精心收集、提取和整理了大量的本科数学问题,并发布了一个多样化且动态的基准测试数据集UGMathBench,旨在评估语言模型在本科广泛的科目中的数学推理能力。同时,团队也发布了相关技术报告,全面解析数据集的构建过程,对23 个先进的语言模型进行了评估,并展示评估结果。
主要贡献总结如下:
-
发布UGMathBench,这是一个广泛覆盖本科数学且动态的基准测试数据集。
-
根据动态数据集的特点,提出了三个关键指标:有效准确率(EAcc)、推理差距(Δ) 和稳健性效率(RE),用于评估语言模型在基准测试中的有效准确率和推理稳定性。
-
对23 个先进的模型进行了评估,比较其有效准确率和稳健性效率。
数据集下载地址:
https://www.modelscope.cn/datasets/xinxu02/UGMathBench
https://huggingface.co/datasets/UGMathBench/ugmathbench
技术报告地址:
https://arxiv.org/abs/2501.13766
02.UGMathBench 的组成和构建
UGMathBench 涵盖基础算术、单变量微积分、多变量微积分、微分方程、概率等,共16 个科目。(Figure 1)这16 个科目又细分为111 个主题UGMathBench 一共有5062 个题目。有别于其他主要评估单种答案类型的数据集,UGMathBench 包含8 种基礎答案类型(例如数值、表达式)和2种復合答案類型(有序或无序的答案组合)。UGMathBench 的一个主要特点,是为每个题目提供了3 个不同的随机版本。通过观察语言模型是否能完成不同版本的题目,有助于研究者进一步了解LLM的内在推理逻辑和评估LLM 的真实推理能力。为了衡量题目对本科生的实际难度,团队随机抽取了 100 道题目,查询了在线评分系统中记录的学生表现。这 100 道题由99 到1537 名学生完成。需要指出的是,学生在回答错误后,可以再次尝试
答题。根据记录,第一次答题的平均准确率为56.5%,而经过数次尝试后最后一次答题的平均准确率为96.1%。
团队的UGMathBench 创建过程分为三个阶段:数据收集、整理和去重、答案类型注释。
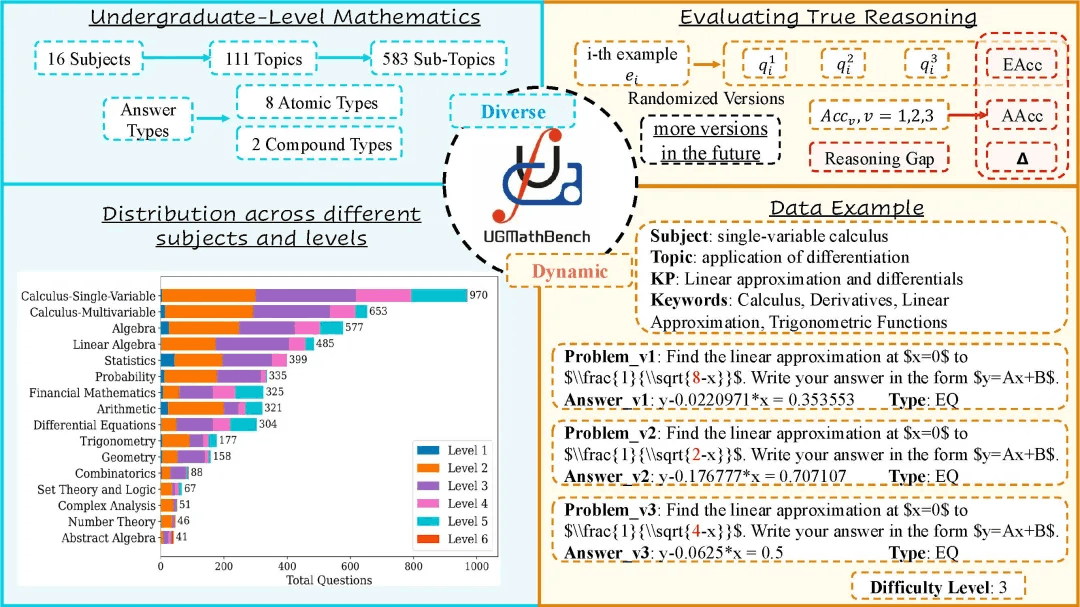
Figure 1: UGMathBench 的概览
2.1 数据收集
UGMathBench 的数据集是从学院本科课程的在线评分系统(Webwork)
中精心收集整理的。在线评分系统中的大部分题目的数值都是由程序随机生成。这些程序指定了数值的随机范围,根据解答的公式计算答案,来实现题目的随机性和答案的正确性。此外,部分题目会指定数值之间的关系,以保证解答方案的一致性。
为了创建动态的数据集,团队排除了没有随机版本的静态题目以及包含图片的题目,以制作纯文本的数据集。然而,这些收集来的题目是以HTML格式保存的。
2.2 整理和去重对
对于HTML 格式的题目,团队利用Python 包bs41 和re2,将它们全部转换为LaTeX。由于转换的过程并不完美,团队参照原HTML 文件,手动验证转换后的LaTeX 文件并修整。然后将LaTeX 文件进一步重组成图 1 所示的格式。此外,在线评分系统中包含的科目、主题、难度等元信息,将一并保留在LaTeX 文件中。此后,团队根据text-embedding-ada-002 生成的embeddings 在每个科目内进行去重,以删除重复的题目。
2.3 答案类型注释
为了确保语言模型可以正确地理解答题要求,团队对答案的类型进行分类,并作为元信息保存到LaTeX 文件(Figure 1)。答案的类型分为两大类:基础答案和复合答案。对于答案只需填写一个值的题目,我们归为基础答案类型。其中,基础答案类型可以进一步分为八个种类(Table 1)。对于需要填写多个基础答案的题目,则归为复合答案类型,通过由逗号分割的基础答案数组表示。根据这些基础答案是否需要按顺序填写,复合答案类型又进一步细分为有序数组与无序数组。
|
Type |
Example |
|
Numerical Value |
π/4 |
|
Expression |
x2 + 1 |
|
Equation |
x2 + y2 = 1 |
|
Interval |
(−∞,−1] |
|
True/False |
Yes |
|
MC with single answer |
A |
|
MC with multiple answers |
ACF |
|
Open-Ended |
h(1-x) |
Table 1: Examples of eight atomic answer types.
03.评估指标
3.1 有效准确率(EAcc)
如果一个语言模型能够正确地通过推理来解决一个题目,那么它应该能够准确地解答这个题目的所有随机版本。因此,我们定义了有效准确率(EAcc),用于表示所有随机版本都被准确解答的题目的比例:
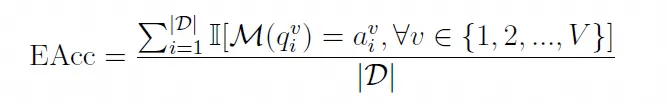
其中 是指数据集, 是指随机版本的总数,是指受评估的语言模 型 针对第 个题目的第 个随机版本所作出的答案, 则是指这个问题的正确答案。
3.2 推理差距(Δ)
推理差距定义为平均准确率(AAcc) 和有效准确率(EAcc) 的差,表示为
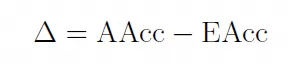
其中平均准确率(AAcc) 被定义为:
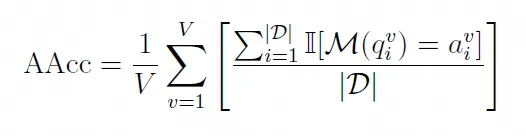
3.3 稳健性效率(RE)
稳健性效率定义为推理差距(Δ) 与有效准确率(EAcc) 的比率,表示为
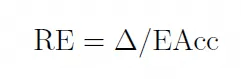
稳健性效率(RE) 透过观察数学推理的有效性来捕捉稳健性。较低的稳健性效率(RE) 表示语言模型在UGMathBench 中,适应相同问题的不同随机版本的能力更优异。
实现更高的有效准确率(EAcc) 和更低的推理差距(Δ) 会导致更低的RE,这可以反映语言模型的真实推理能力的稳健性有所提高。
04.UGMathBench 实验
基于UGMathBench,团队对23 个先进的语言模型的数学推理能力进行了全面的评估,包括商业闭源的语言模型和开源的语言模型。评估的语言模型如下:
-
对于闭源的语言模型,我们选择了OpenAI-o1-mini,GPT4o,GPT4omini,和Claude-3-Opus
-
对于开源的通用语言模型,我们评估了LLaMA-3-Instruct 系列(8B,70B),Qwen2-Instruct (7B, 72B),Yi-1.5-Chat (6B, 9B, 34B),Mistral-7B-Instruct,Mistral-Nemo-Instruct-2407,Mistral-Small-Instruct-2409,Mistral-Large-Instruct-2407,DeepSeek-MOE-16B-Chat,和DeepSeek-V2-Lite-Chat
-
团队同时也评估了一些针对数学进行过强化的语言模型: DeepSeekMath-7B (-RL, -Instruct),Qwen2-Math (7B, 72B),Mathstral-7B , 和NuminaMath-7B-CoT
在实验过程中,我们使用平均准确率(AAcc) 来衡量所有题目的所有随机版本上的平均性能,使用有效准确率(EAcc) 来量化语言模型的真实推理能力,使用推理差距(Δ) 来评估推理的稳健性。为了消除少数提示的敏感性的影响,我们所有的实验都使用零次提示,针对不同的答案类型进行定制,以确保答案符合规则和更好地提取答案。为了确保评估的一致性并方便重现,我们将最大输出长度设定为2048 个token,并采用温度为0 的贪婪解码策略。此外,我们使用了vLLM 来加快评估过程。
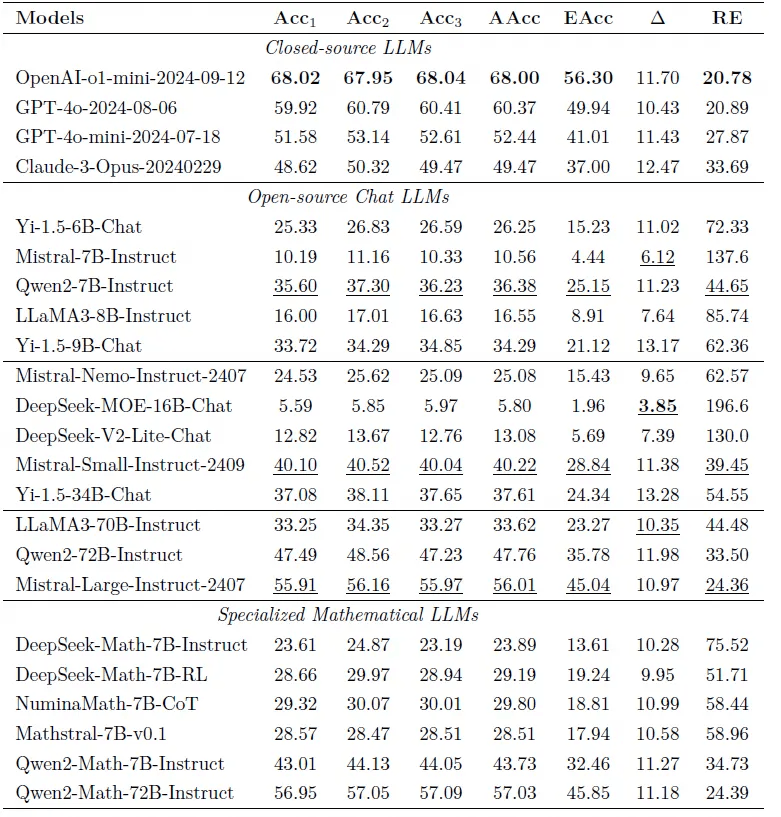
整体实验结果如Table2 所示。
通关实验,我们观察到:UGMathBench 在评估语言模型数学推理能力方面是一个具有挑战性的基准。即使是具有最先进的推理能力的语言模型OpenAI-o1(mini) 在UGMathBench 中也只能达到56.3% 的有效准确率(EAcc),而大多数开源语言模型都难以达到30% 有效准确率(EAcc)。并且,即使是领先的语言模型,在解决多个随机版本的问题时,仍然存在不一致。平均准确率(AAcc) 大于20% 的语言模型,表现出的推理差距(Δ) 超过(或接近)10%。这些结果指出了当前语言模型的局限性,并促使我们开发具有高有效准确率(EAcc) 和推理差距(Δ) 的真正的“大型推理模型”
Table 2: UGMathBench 的主要评估结果。每一列中结果最好的值用粗体
字标示。其中,额外为开源模型中表现最好的值标上下划线
点击链接阅读原文,即可跳转体验~
https://www.modelscope.cn/datasets/xinxu02/UGMathBench

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)