

社区供稿 | 创作《哈利波特与异界魔书》的过程和心得
可图Kolors-LoRA风格故事挑战赛一等奖作品,以下是团队创作过程的详细回顾
在探索AI生成与艺术创作的交汇点时,我们的团队在可图Kolors-LoRA风格故事挑战赛中,通过AI生成模型、LoRA微调等技术,将技术与创意完美融合,创作出了一部独特的视听作品--《哈利波特与异界魔书》。很荣幸获得了可图Kolors-LoRA风格故事挑战赛决赛一等奖,以下是我们创作过程的详细回顾:
01创作过程
人物模型训练
在人物模型训练方面,我们面临着如何平衡特征明显与自然度的挑战。对于赫敏角色,我们尝试了两种不同的数据集:一种是以“赫敏”为prompt生成的图片,另一种是真人图像。我们发现,前者特征明显但不够自然,后者则相反。
AI生成数据集

真人图像数据集

混合数据集

为了解决这一问题,我们采取了1:1混合数据集的方法,最终训练出的LoRA模型成功地结合了两者的优点,既保留了人物的主要特征,又使姿态看起来更自然。
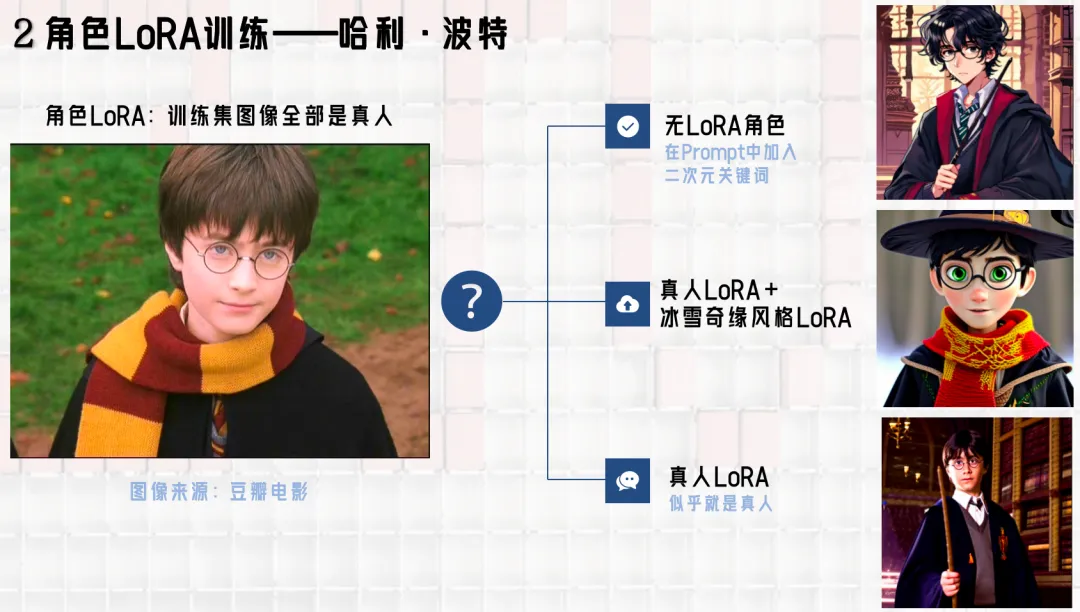
哈利角色的LoRA模型则完全基于真人剧照,我们尝试将其与冰雪奇缘风格的LoRA模型融合,以期获得更二次元的效果,但由于冰雪奇缘风格模型中有不少人物会影响角色模型稳定性,最终没有采用。
哈利波特数据集
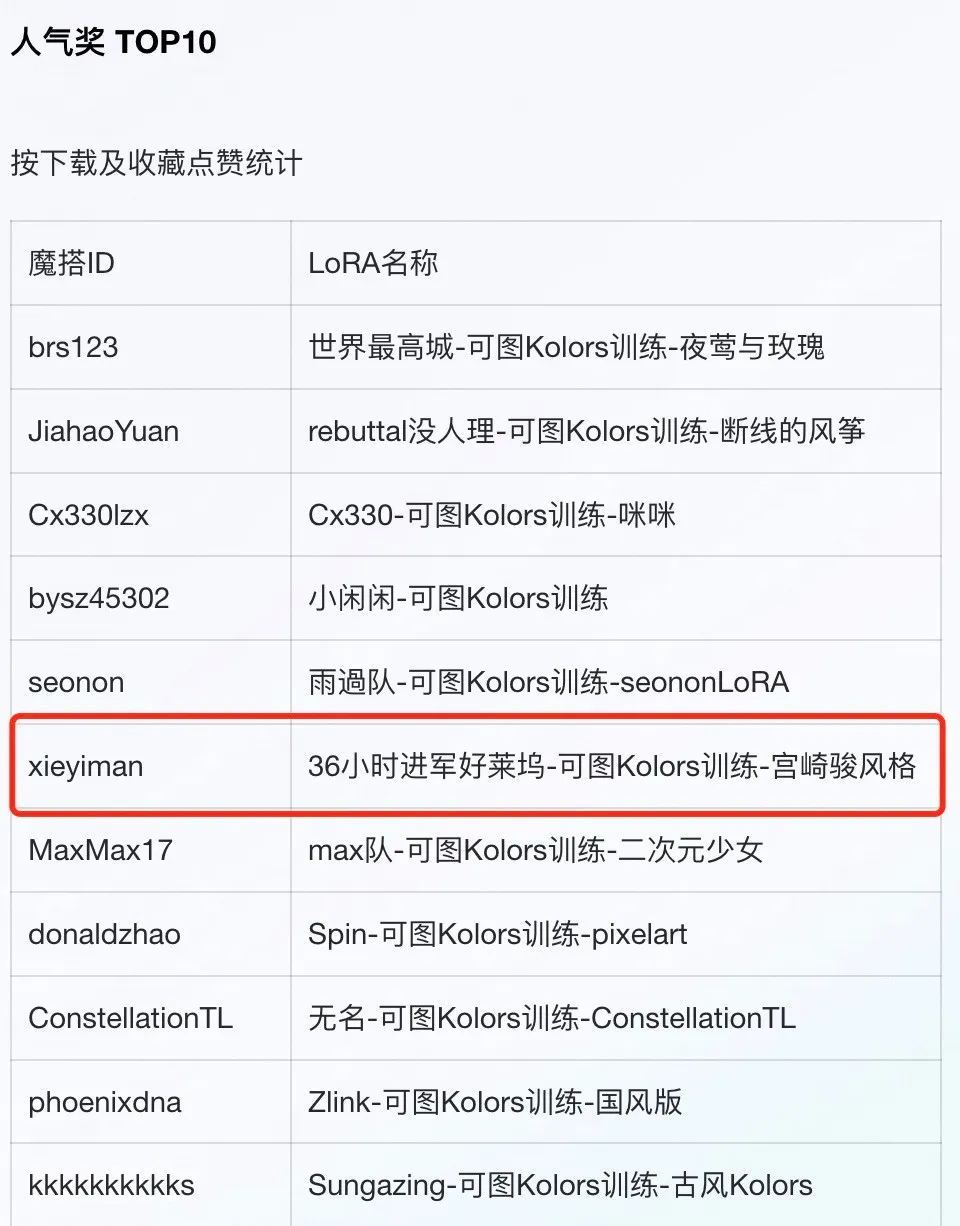
宫崎骏风格模型训练
在风格模型方面,我们从吉卜力官网获取了大量高清原画,经过多次参数调整,最终确定了宫崎骏风格的LoRA模型参数,使得作品风格独特,美学评估更高。值得一提的是,我们的宫崎骏风格模型在初赛中获得了人气top10模型的荣誉。

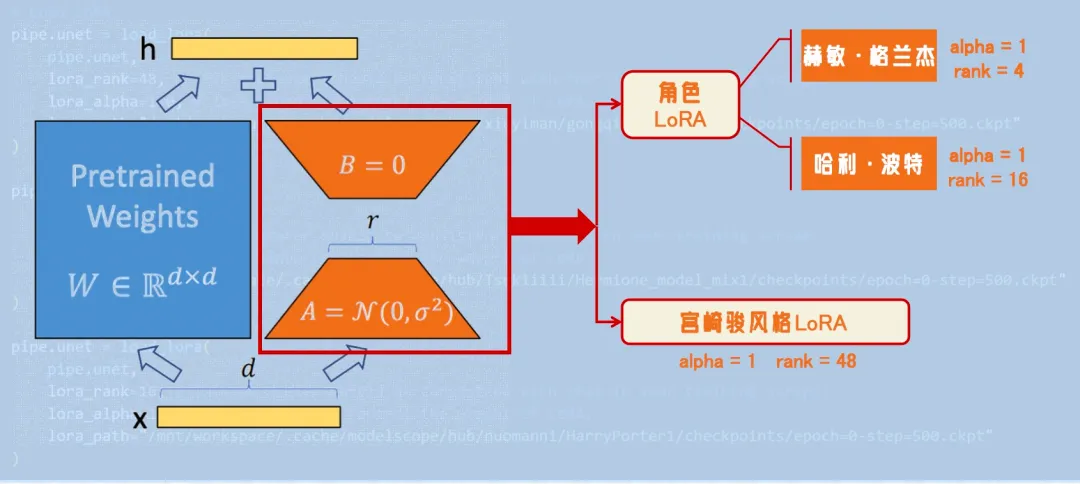
模型融合
在模型融合阶段,我们在基础的Kolors文生图模型上叠加了角色LoRA和宫崎骏风格LoRA,通过细致的参数调试,找到了最佳的融合效果。
图片生成
在图片生成过程中,我们通过概括性描述和细节调整,不断优化prompt和negative prompt,以确保人物稳定、风格统一、画面和谐。尽管过程中遇到了诸多挑战,但我们通过不懈努力,最终完成了18张故事分镜的创作。

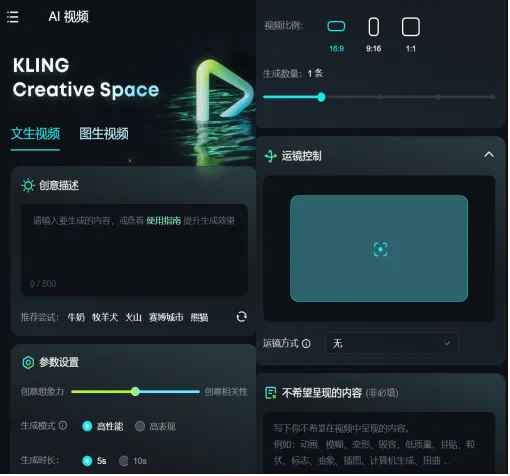
视频生成
在视频生成阶段,我们调研并测试了多种图生视频模型,最终选择了以可灵AI为主的方法。因为使用开源的 ExVideo 生成视频时无法对视频画面进行指导和微调,而可灵AI模型使用3D时空联合注意力机制,支持表情和身体驱动,且能基于其自研的3D面部和身体重建技术,结合背景稳定性和重定向模块,实现表情和身体全驱动技术,我们决定使用快手平台的可灵AI模型,使用图像+Prompt的方式生成视频。取得很不错的效果。
音频生成
结合科大讯飞的语音合成技术,为视频添加了合适的旁白。通过编写python后端程序调用模型WebAPI生成所需音频,在虚拟机环境下使用ffmpeg库处理音频,得到如每段音频的时长等信息。
02心得
此次可图Kolors-LoRA风格故事挑战赛中,我们团队利用AI生成模型,加入采用先进的LoRA技术,训练角色模型,并引入宫崎骏风格的LoRA模型,将两者融合并利用文生图模型,生成宫崎骏风格的哈利波特电影角色。接着通过调整模型参数,实现了人物特征的稳定呈现与自然姿态的完美结合,创作出18张精美的故事分镜。视频生成上,我们采用可灵图生视频模型,以及科大讯飞的语音合成技术,为作品注入了生动的动态表现和旁白。这部作品不仅是一次视听艺术的探索,也是技术与创意的出色融合。通过此次比赛,我们深刻感受到LoRA微调技术、Stable Diffusion等的快速发展和应用,以及AI生成在未来的广阔前景。
点击链接👇,即可跳转作品品牌馆~ https://modelscope.cn/brand/view/Kolors

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献393条内容
已为社区贡献393条内容

所有评论(0)