
!git clone https://github.com/deepseek-ai/Janus.git
%cd Janus
!pip install -e .Deepseek开源多模态LLM模型框架Janus,魔搭社区最佳实践
deepseek近期推出了简单、统一且灵活的多模态框架Janus,它能够统一处理多模态理解和生成任务。让我们一起来了解一下吧。
·
01
引言
deepseek近期推出了简单、统一且灵活的多模态框架Janus,它能够统一处理多模态理解和生成任务。与之前的研究不同的是,Janus将视觉编码解耦为独立的路径,并利用单一、统一的transformer架构进行处理。这种方法不仅缓解了视觉编码器在理解和生成任务中的冲突,还增强了框架的灵活性。
Janus采用了独立编码方法将纯文本理解、多模态理解和视觉生成分别转换为特征序列,并通过一个统一的自回归Transformers处理这些特征序列。对于纯文本理解任务,使用预训练模型中的分词器将文本转换为离散ID并获取每个ID对应的特征表示;对于多模态理解任务,使用SigLIP编码器从图像中提取高维语义特征并将它们展平成一维序列,然后使用理解适配器将这些图像特征映射到预训练模型的输入空间;对于视觉生成任务,使用VQ Tokenizer 将图像转换为离散ID,并将ID序列展平成一维序列,然后使用生成适配器将与每个 ID 对应的codebook embedding映射到 LLM 的输入空间中。最后,将这些特征序列连接起来形成一个多模态特征序列,并将其馈送给预训练模型进行处理。整个模型遵循自回归框架,无需特别设计attention mask。
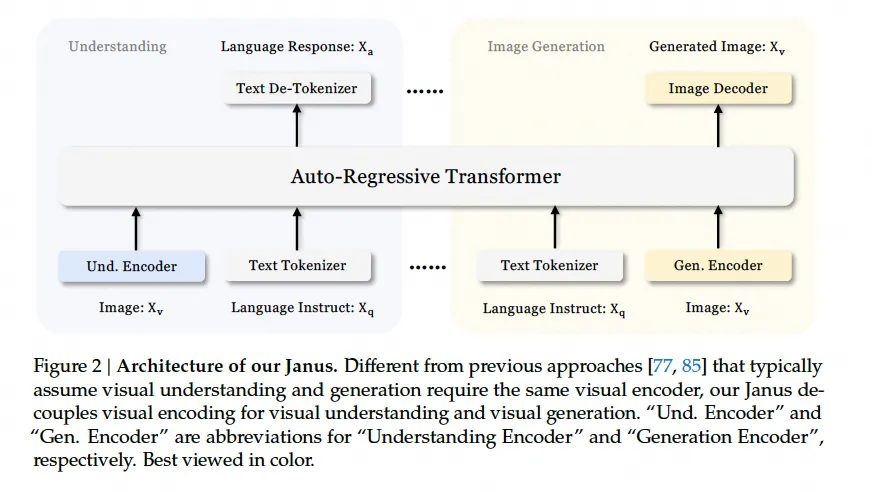
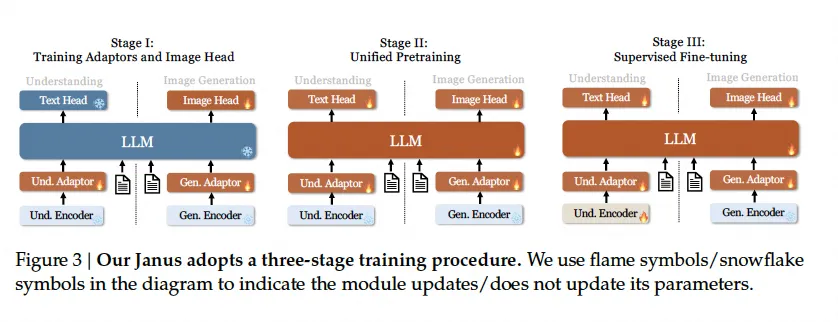
Janus框架的主要改进在于其简单、统一且灵活的设计。首先,在架构上,Janus采用了独立编码方法将不同类型的输入转换为特征序列,并通过一个统一的自回归transformers处理这些特征序列,从而避免了针对不同类型输入设计不同的模块或attention mask。其次,在训练过程中,Janus采用了三个阶段的训练过程:第一阶段训练adapter和image head,第二阶段进行统一预训练,第三阶段进行监督微调。这种训练方式使得Janus能够逐步学习多模态理解和生成能力,并在各种场景下保持灵活性。
Janus主要解决了多模态理解与生成的问题。传统的多模态模型通常需要针对不同类型输入设计不同的模块或attention mask,这导致模型复杂度较高且难以扩展。而Janus通过采用独立编码方法将不同类型的输入转换为特征序列,并通过一个统一的自回归transformers处理这些特征序列,实现了多模态的理解与生成,并且具有简单、统一且灵活的特点。此外,Janus还支持多种扩展,例如选择更强的视觉编码器、采用动态高分辨率技术等,以进一步提高模型性能。
02
魔搭最佳实践
模型推理
环境安装
视觉理解
import torch
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_images
from modelscope import snapshot_download
# specify the path to the model
model_path = snapshot_download("deepseek-ai/Janus-1.3B")
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
conversation = [
{
"role": "User",
"content": "<image_placeholder>\nConvert the formula into latex code.",
"images": ["/mnt/workspace/Janus/images/equation.png"],
},
{"role": "Assistant", "content": ""},
]
# load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device)
# # run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
# # run the model to get the response
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)显存占用:
图片生成
import os
import PIL.Image
import torch
import numpy as np
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from modelscope import snapshot_download
# specify the path to the model
model_path = snapshot_download("deepseek-ai/Janus-1.3B")
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
conversation = [
{
"role": "User",
"content": "A stunning princess from kabul in red, white traditional clothing, blue eyes, brown hair",
},
{"role": "Assistant", "content": ""},
]
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt="",
)
prompt = sft_format + vl_chat_processor.image_start_tag
@torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
prompt: str,
temperature: float = 1,
parallel_size: int = 16,
cfg_weight: float = 5,
image_token_num_per_image: int = 576,
img_size: int = 384,
patch_size: int = 16,
):
input_ids = vl_chat_processor.tokenizer.encode(prompt)
input_ids = torch.LongTensor(input_ids)
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
for i in range(parallel_size*2):
tokens[i, :] = input_ids
if i % 2 != 0:
tokens[i, 1:-1] = vl_chat_processor.pad_id
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
for i in range(image_token_num_per_image):
outputs = mmgpt.language_model.model(inputs_embeds=inputs_embeds, use_cache=True, past_key_values=outputs.past_key_values if i != 0 else None)
hidden_states = outputs.last_hidden_state
logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
logits = logit_uncond + cfg_weight * (logit_cond-logit_uncond)
probs = torch.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
dec = mmgpt.gen_vision_model.decode_code(generated_tokens.to(dtype=torch.int), shape=[parallel_size, 8, img_size//patch_size, img_size//patch_size])
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec
os.makedirs('generated_samples', exist_ok=True)
for i in range(parallel_size):
save_path = os.path.join('generated_samples', "img_{}.jpg".format(i))
PIL.Image.fromarray(visual_img[i]).save(save_path)
generate(
vl_gpt,
vl_chat_processor,
prompt,
)显存占用:
模型体验
图片理解
Q:<image_placeholder>\nConvert the formula into latex code.
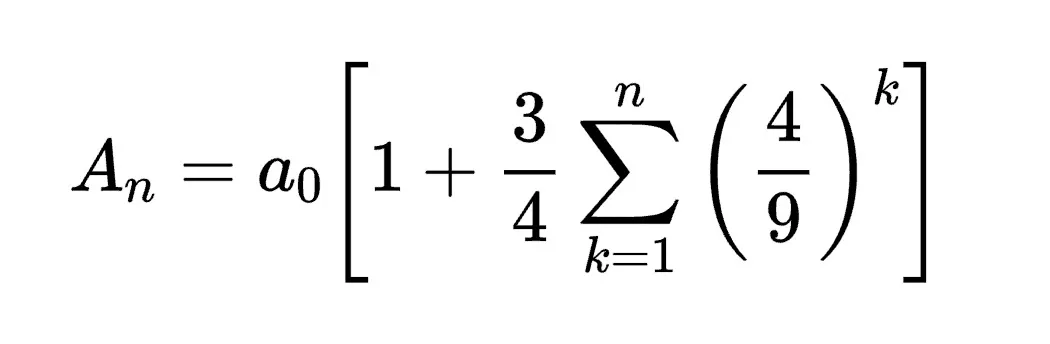
A:Sure, here is the LaTeX code for the formula:
\[ A_n = a_0 \left[ 1 + \frac{3}{4} \sum_{k=1}^{n} \left( \frac{4}{9} \right)^k \right] \]
图片生成:
prompt:A stunning princess from kabul in red, white traditional clothing, blue eyes, brown hair
生成图片:

模型微调
我们使用ms-swift对deepseek-janus进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型微调推理框架。
ms-swift开源地址:
https://github.com/modelscope/ms-swift
当前ms-swift只支持对deepseek-janus的vision tower、aligner和llm进行微调,暂时不支持对generator部分微调。通常,多模态大模型微调会使用自定义数据集进行微调。在这里,我们将展示可直接运行的demo。我们使用Latex-OCR数据集:https://modelscope.cn/datasets/AI-ModelScope/LaTeX_OCR进行微调。
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .[llm]微调脚本:
# 默认:微调 LLM & aligner, 冻结 vision encoder
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type deepseek-janus-1_3b \
--model_id_or_path deepseek-ai/Janus-1.3B \
--sft_type lora \
--dataset latex-ocr-handwrite#5000 \
--target_modules ALL
# Deepspeed ZeRO2
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type deepseek-janus-1_3b \
--model_id_or_path deepseek-ai/Janus-1.3B \
--sft_type lora \
--dataset latex-ocr-handwrite#5000 \
--deepspeed default-zero2 \
--target_modules ALL训练显存占用:
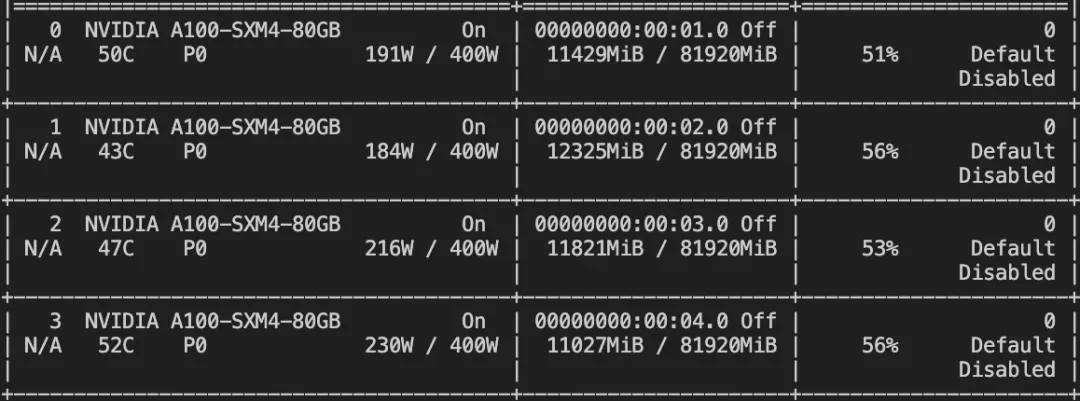
如果要使用自定义数据集,只需按以下方式进行指定:
# val_dataset可选,如果不指定,则会从dataset中切出一部分数据集作为验证集
--dataset train.jsonl \
--val_dataset val.jsonl \{"query": "<image>55555", "response": "66666", "images": ["image_path"]}
{"query": "<image><image>eeeee", "response": "fffff", "history": [], "images": ["image_path1", "image_path2"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["query1", "response1"], ["query2", "response2"]]}训练loss:
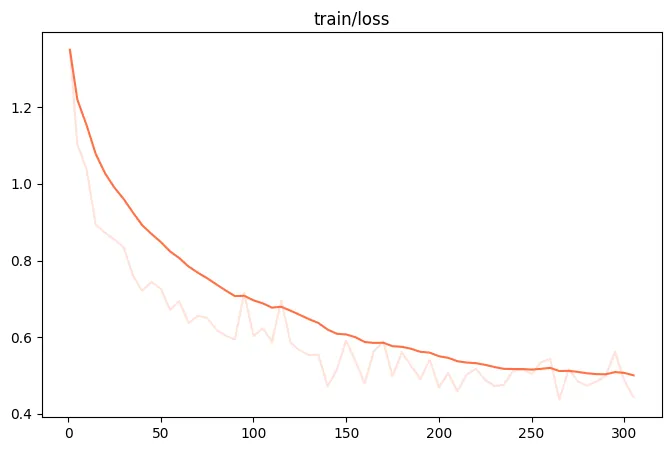
微调后推理脚本如下:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/deepseek-janus-1_3b/vx-xxx/checkpoint-xxx \
--load_dataset_config true
# merge-lora & infer
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/deepseek-janus-1_3b/vx-xxx/checkpoint-xxx \
--load_dataset_config true --merge_lora true推理效果:



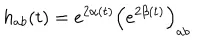
点击链接👇,即可跳转数据集~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献653条内容
已为社区贡献653条内容

所有评论(0)