
多模态vlm综述:An Introduction to Vision-Language Modeling 论文解读
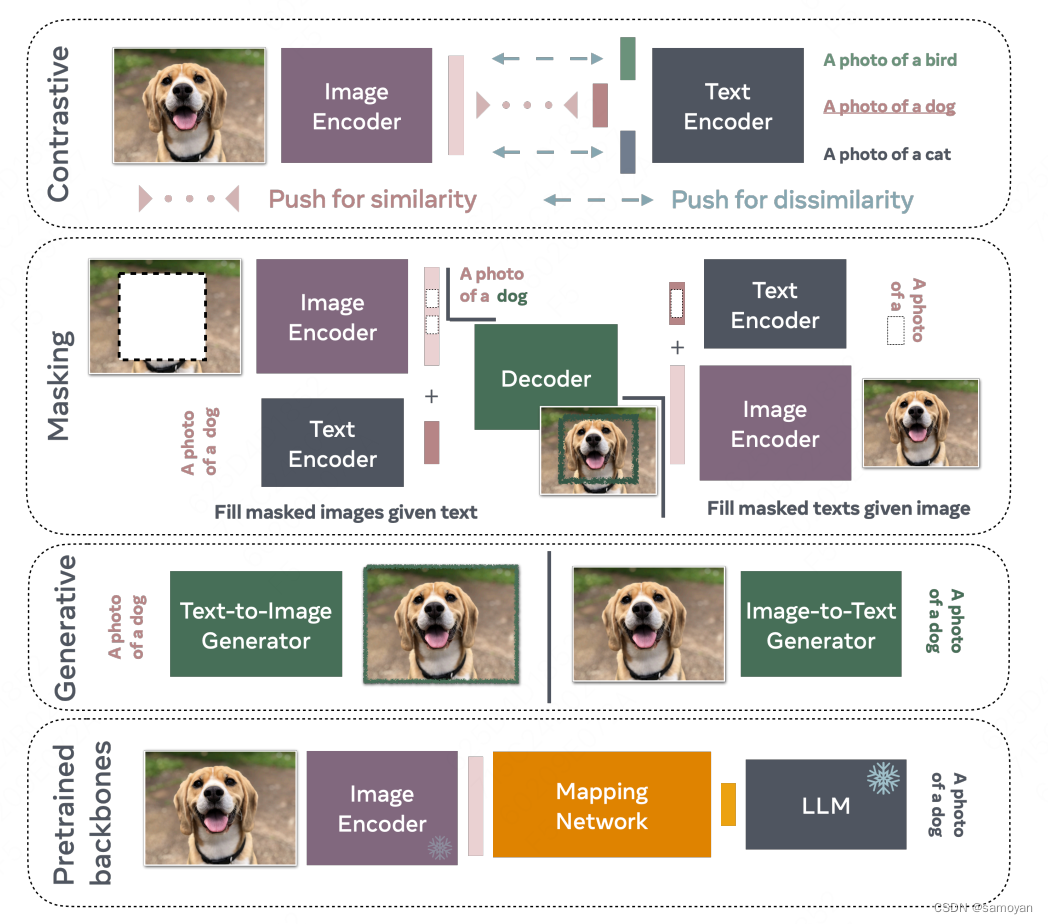
论文:这里主要整理了多模态的技术发展历程,没有一些实验对比的数据。VLM家族:1)对比训练是一种广泛应用的策略,它采用正面例子和负面例子的配对方式。视觉语言模型(VLM)通过这种方式被训练,以针对正面配对预测出相似的表示,同时对于负面配对则预测出不同的表示。2)掩码技术是另一种训练VLM的策略,它通过重构给定的未掩码文本字幕中缺失的部分来实现。类似地,通过在字幕中掩码词语,也可以训练VLM来重构给
目录
论文: https://arxiv.org/pdf/2405.17247
这里主要整理了多模态的技术发展历程,没有一些实验对比的数据。

VLM家族:
1)对比训练是一种广泛应用的策略,它采用正面例子和负面例子的配对方式。视觉语言模型(VLM)通过这种方式被训练,以针对正面配对预测出相似的表示,同时对于负面配对则预测出不同的表示。
2)掩码技术是另一种训练VLM的策略,它通过重构给定的未掩码文本字幕中缺失的部分来实现。类似地,通过在字幕中掩码词语,也可以训练VLM来重构给定未掩码图像中的这些词语。
3)尽管大多数方法采用中间表示或部分重构技术,但生成式VLM经过特殊训练后,能够生成完整的图像或极长的字幕。考虑到这些模型的复杂性,它们通常需要较高的训练成本。
4)基于预训练主干网络的VLM经常利用像Llama这样的开源大型语言模型(LLM),学习图像编码器(也可能事先经过训练)与LLM之间的映射关系。重要的是,这些模型不是互斥的;许多方法依赖于对比、掩蔽和生成几种标准的结合。
1、基于对比学习的VLMs
基于对比的训练通常可以通过基于能量的模型(Energy-Based Models, EBM)的观点来更好地解释,如LeCun等人在2006年提出的,其中一个由参数θ定义的模型Eθ,被训练以赋予观察到的变量较低的能量,而未观察到的变量则赋予较高的能量。来自目标分布的数据应该具有较低的能量,而其他任何数据点则应具有较高的能量。为了训练这些模型,我们考虑输入数据x与一个能量函数Eθ(x),该能量函数由参数θ给出。相应的学习目标的玻尔兹曼分布密度函数可以写成:

其中归一化因子为 𝑍𝜃=∑𝑥𝑒−𝐸𝜃(𝑥)。为了估计输入数据抽取的目标分布PD,我们原则上可以使用传统的最大似然目标函数:

其梯度为:

然而,上述方法需要从模型分布 𝑃𝜃(𝑥) 中采样出样本 𝑥−,而这样的样本可能难以得到。目前有几种技术可以近似地模拟这种分布。一种方法依赖于马尔可夫链蒙特卡罗(MCMC)技术,通过迭代过程找出能够最小化预测能量的样本。第二种方法依赖于得分匹配[Hyvärinen, 2005]和去噪得分匹配[Vincent, 2011]的标准,它们通过只学习输入数据相对于概率密度的梯度来移除归一化因子。另一类方法,最近在自监督学习(SSL)和视觉语言模型(VLM)的研究中使用最多的,是噪声对比估计(NCE)[Gutmann和Hyvärinen, 2010]。
与其使用模型分布来采样负样本,NCE背后的直觉是,采样自噪声分布 𝑢′∼𝑝𝑛(𝑢′) 在某些情况下可能足够好地近似模型分布样本。尽管从理论上难以证明这种方法为何可行,但是广泛的实验证据表明,近期自监督学习文献中基于NCE的方法是成功的[Chen等人,2020]。原始的NCE框架可以描述为一个二元分类问题,模型应当为来自真实数据分布的样本预测标签 𝐶=1,而为来自噪声分布的样本预测 𝐶=0。通过这种方式,模型学会了区分真实数据点和噪声数据点。因此,损失函数可以定义为具有交叉熵的二元分类:
𝐿𝑁𝐶𝐸(𝜃):=−∑𝑖log𝑃(𝐶𝑖=1∣𝑥𝑖;𝜃)−∑𝑗log𝑃(𝐶𝑗=0∣𝑥𝑗;𝜃)
其中 𝑥𝑖 是从数据分布中采样的,而 𝑥𝑗∼𝑝𝑛(𝑥),𝑗≠𝑖 是从噪声分布中采样的。
Wu等人[2018]提出了一种无需正样本对的噪声对比估计(NCE)方法,该方法采用非参数化Softmax函数,通过显式归一化和一个温度参数τ实现。而Oord等人[2018, CPC]在使用正样本对的同时保留了非参数化Softmax,并将这种方法命名为InfoNCE,具体如下:

InfoNCE损失不是简单地预测一个二元值,而是利用如余弦相似度这样的距离度量,在模型的表示空间中进行计算。这就需要计算正样本对之间的距离,以及所有负样本对之间的距离。通过Softmax函数,模型学习预测在表示空间中最相近的一对样本,同时将较低的概率赋予其他所有的负样本对。在如SimCLR [Chen et al., 2020]这样的自监督学习(SSL)方法中,正样本对被定义为一张图片及其经过手工数据增强的版本(例如,对原始图片应用灰度转换),而负样本对则是用一张图片与小批量(mini-batch)中的所有其他图片构建。InfoNCE基方法的主要缺点是引入了对小批量内容的依赖性。这通常需要大的小批量来使得对比训练准则在正负样本之间更为有效。
1.1 CLIP
一个常用的使用InfoNCE损失的对比方法是对比语言-图像预训练(CLIP)[Radford et al., 2021]。正样本对被定义为一张图像及其对应的真实标注文字,而负样本则是相同的图像配上mini-batch中描述其他图片的所有其他标注文字。CLIP的一个创新之处在于训练一个模型来在共享的表示空间中结合视觉和语言。CLIP训练随机初始化的视觉和文本编码器,通过对比损失将图像和其标注的表示映射到相似的嵌入向量中。在网络上收集的4亿个标注-图像对上进行训练的原始CLIP模型显示出了显著的零样本分类迁移能力。具体来说,使用ResNet-101架构的CLIP达到了与受监督ResNet[He et al., 2015]模型相匹配的性能(实现了76.2%的零样本分类准确率),并在多个鲁棒性基准测试中超越了它。
SigLIP [Zhai et al., 2023b] 类似于CLIP,不同之处在于它使用基于二元交叉熵的原始NCE损失,而不是使用基于InfoNCE的CLIP的多类别目标。这一改变使得在比CLIP更小的batch大小上获得了更好的零样本表现。
潜在语言图像预训练(Llip)[Lavoie et al., 2024]考虑到一幅图像可以有多种不同的描述方式。它提出通过交叉注意力模块将图像的编码与目标字幕相关联。考虑到字幕的多样性能增加表示的表现力,通常能够提高下游零样本转移分类和检索的性能。
2、基于mask的VLMs
masking是深度学习研究中常用的技术。它可以被视为一种特殊形式的去噪自编码器[Vincent等人,2008],其中噪声具有空间结构。它也与修复策略相关,Pathak等人[2016]使用它来学习强大的视觉表征。更近期地,BERT [Devlin等人,2019] 在训练期间使用遮蔽语言建模(MLM)来预测句子中缺失的标记。masking尤其适用于变换器架构[Vaswani等人,2017],因为输入信号的分词化使得更容易随机丢弃特定的输入标记。在视觉方面,也有一些工作通过使用masking图像建模(MIM)来学习表征,如MAE[He等人,2022]或I-JEPA[Assran等人,2023]。很自然地,也有一些工作将这两种技术结合起来训练VLM。首先是FLAVA[Singh等人,2022],它利用掩蔽在内的多种训练策略来学习文本和图像表征。其次是MaskVLM[Kwon等人,2023],这是一个独立的模型。最后,我们对信息论和masking策略之间的关系进行了一些探讨。
2.1 FLAVA
masking技术基础的第一个例子是基础语言与视觉对齐(FLAVA)[Singh等人,2022]。它的架构包括三个核心部件,每个部件都基于变换器框架,并针对特定的模态进行了定制。图像编码器采用视觉变换器(ViT)[Dosovitskiy等人,2021]来处理图像,将其分割为线性嵌入和基于变换器的表征的小块,包括分类标志([CLSI])。文本编码器使用变换器[Vaswani等人,2017]对文本输入进行标记并嵌入到向量中进行上下文处理,输出隐藏状态向量并伴随分类标志([CLST])。这两个编码器都采用掩蔽技术进行训练。在此基础上,多模态编码器融合了图像和文本编码器的隐藏状态,利用学习到的线性投影和变换器框架内的交叉注意力机制,将视觉和文本信息整合起来,同时突出了一个附加的多模态分类标志([CLSM])。该模型采用了综合训练方案,结合了多模态和单模态遮蔽建模损失以及对比目标。它在七千万公开可用的图像和文本对的数据集上进行了预训练。通过这种方法,FLAVA展现出了卓越的多功能性和效力,在包含视觉、语言和多模态基准在内的35项多样化任务里取得了最先进的性能,由此展示了该模型理解和整合不同领域信息的能力。
2.2 MaskVLM
FLAVA的一个局限是使用了像dVAE [Zhang等人,2019]这样的预训练的视觉编码器。为了打造一个对第三方模型依赖性更小的VLM,Kwon等人[2023]引入
了MaskVLM,它直接在像素空间和文本标记空间应用掩蔽。使它在文本和图像上均有效的关键是使用来自一种模态到另一种模态的信息流动;文本重建任务接收来自图像编码器的信息,反之亦然。
2.3 关于VLM目标的信息理论视角
Federici等人[2020]首先展示了VLM可以被理解为解决一个速率失真问题,通过减少多余信息并最大化预测信息。Dubois等人[2021]更具体地显示,我们可以理解对数据X进行任何变换f(X),隐式地引入一个等价关系,将空间f(X)划分成不相交的等价类。我们旨在限制条件密度在一个区域内是常数,即𝑓(𝑥)∼𝑓(𝑥′)⇒𝑝(𝑧∣𝑓(𝑥))=𝑝(𝑧∣𝑓(𝑥′)),其中Z是X的学习表示。这一视角统一了掩蔽和其他形式的数据增强,以及在两种数据模态之间选择函数;所有这些都可以被表示为对数据的某种变换。
我们可以公式化相关的速率失真问题[Shwartz Ziv 和 LeCun, 2024]:
arg min𝑝(𝑧∣𝑥) 𝐼(𝑓(𝑋);𝑍)+𝛽⋅𝐻(𝑋∣𝑍)

为了得出掩蔽VLM的目标,我们约束等式(3):
𝐿=−∑𝑥∈𝐷𝐸𝑝(𝑓)𝑝(𝑍∣𝑓(𝑥))[log𝑞(𝑧)+𝛽⋅log𝑞(𝑥∣𝑧)]

其中log𝑞(𝑧)是一个熵瓶颈,限制了速率𝐼(𝑓(𝑋);𝑍),移除了多余的信息。请注意,在掩蔽VLM中的熵瓶颈通常由一个常数界定,而这个常数取决于掩蔽移除的信息量。对于多模态VLM,𝑍中的信息量被减少到源头中最小量的信息。术语log𝑞(𝑥∣𝑧)限制了失真𝐻(𝑍∣𝑋)并确保信息的保存,从而最大化了预测信息。在实践中,该术语通过自编码实现。作为对比,对比损失可以被看作无需数据重构的压缩。这里的失真,参见(2),评分了两个表征的等价性。InfoNCE通过分类哪个𝑍与等效示例𝑋相关联,以保持必要的信息,通过这种方法,掩蔽VLM训练目标与信息理论形成联系,为进一步发展视觉语言模型提供了理论基础。
3、基于生成的VLM
与以往主要操作潜在表示、构建图像或文本抽象然后相互映射的训练范式不同,生成范式考虑了文本和/或图像的生成。一些方法,如CoCa [Yu 等人,2022b],学习了一个完整的文本编解码器,使得图片字幕的生成成为可能。一些其他方法,如Chameleon Team [2024] 和 CM3leon [Yu 等人,2023],是明确训练来生成文本和图像的多模态生成模型。最后,一些模型只训练基于文本生成图像,比如Stable Diffusion [Rombach 等人,2022],Imagen [Saharia 等人,2022] 和 Parti [Yu 等人,2022c]。然而,即使它们只受训于生成图像,它们也可以用于处理多个视觉-语言理解任务。
3.1 学习文本生成器的例子:
CoCa 除了在CLIP中效果良好的对比损失之外,对比字幕器(CoCa) [Yu 等人,2022b] 还采用了生成损失,这是对应于由多模态文本解码器生成的字幕的损失,该解码器采用 (1) 图像编码器输出和 (2) 单模态文本解码器生成的表征为输入。新的损失允许执行新的多模态理解任务(例如,视觉问答VQA)而无需使用多模态融合模块进行进一步适应。CoCa从零开始通过简单地将带注释的图像标签视为文本进行预训练。预训练依赖于两个数据集:包含约1.8B张带有替代文本的图片的ALIGN,以及由>29.5k个类别作为标签的内部数据集JFT-3B,但将标签视为替代文本。
3.2 多模态生成模型的示例:
Chameleon和CM3leon Yu等人[2023]介绍了CM3Leon,一个基础模型用于文本到图像和图像到文本的生成。CM3Leon借用了Gafni等人[2022]的图像分词器,将256×256的图像编码为来自8192词汇表的1024个标记。它借用了张等人[2022]的文本分词器,词汇表大小为56320。它引入了一个特殊的标记<break>来表示模态之间的转换。这种标记化方法允许模型处理交错的文本和图像。然后,将标记化的图像和文本传递给一个仅解码器的变压器模型[Brown等,2020,Zhang等,2022],该模型参数化了CM3Leon模型。 CM3Leon模型经历了两阶段的训练过程。第一阶段是检索增强的预训练。这个阶段使用一个基于CLIP的编码器[Radford等,2021]作为一个密集的检索器来获取相关的、多样的多模态文档,并将这些文档添加到输入序列的前面。然后,模型使用输入序列上的下一个令牌预测进行训练。检索增强有效地增加了在预训练期间可用的令牌,从而提高了数据效率。第二阶段涉及到监督的微调(SFT),其中模型进行多任务指令调整。这个阶段允许模型处理和生成不同模态的内容,显著提高了其在包括文本到图像生成和语言引导的图像编辑等各种任务上的性能。这些阶段共同使CM3Leon在多模态任务中实现了最先进的性能,显示了自回归模型处理文本和图像之间复杂交互的能力的显著提高。
这项工作的扩展是变色龙,这是一种新的混合模态基础模型系列[团队,2024],可以生成和推理交错的文本和图像内容的混合序列。这种能力允许进行全面的多模态文档建模,超越了典型的多模态任务,如图像生成、图像理解和仅文本的语言模型。变色龙从一开始就被独特地设计成混合模态,使用统一的架构从头开始以端到端的方式在所有模态的混合上进行训练——图像、文本和代码。这种集成方法采用了对图像和文本都完全基于令牌的表示。通过将图像转换为离散的令牌,类似于文本中的单词,可以将相同的变压器架构应用到图像和文本令牌的序列上,而不需要为每种模态提供单独的编码器。这种早期融合策略,即所有模态从一开始就映射到一个共享的表示空间,使得在不同模态之间的推理和生成变得无缝。然而,这也引入了重大的技术挑战,特别是在优化稳定性和扩展性方面。这些挑战通过一系列的架构创新和训练技术得到了解决,包括对变压器架构的新颖修改,如查询键归一化和修订的层规范位置,这对于在混合模态环境中的稳定训练至关重要。此外,他们演示了如何将用于仅文本语言模型的监督微调方法适应到混合模态的环境,实现了大规模的强对齐。
3.3 使用生成的文本到图像模型进行下游视觉语言任务
近期在语言条件下的图像生成模型方面取得了巨大的进步[Bie等,2023,Zhang等,2023a],从像Stable Diffusion[Rombach等,2022]和Imagen[Saharia等,2022]这样的扩散模型到像Parti[Yu等,2022c]这样的自回归模型。虽然重点一直在他们的生成能力上,
实际上,这些生成模型可以直接用于分类或字幕预测等判别性任务,无需重新训练。
这些生成模型经过训练,能够估计给定文本提示𝑐时图像𝑥的条件可能性𝑝𝜃(𝑥∣𝑐)。然后,给定一个图像𝑥以及一组𝑛个文本类别{𝑐𝑖}𝑖=1𝑛,通过贝叶斯定理可以轻松地完成分类:

用条件生成模型进行判别任务并非新概念——生成分类,或称为“合成分析”[Yuille and Kersten, 2006],一直是诸如朴素贝叶斯 [Rubinstein 等人,1997, Ng和Jordan,2001] 和线性判别分析 [Fisher,1936] 这样的基础方法的核心概念。这些生成方法对分类的应用传统上受到生成建模能力弱的限制;然而,如今的生成模型已经如此优越,致使生成分类器再次具有了竞争力。
使用自回归模型进行可能性估计。大多数先进的自回归模型(如在语言或语音模态中的模型)是基于离散标记操作的,而不是基于原始输入。这对于本质上是离散的模态(如语言和语音)相对简单,但对于连续的模态(如图像)则相对困难。为了有效地利用自回归建模技术,例如大型语言模型(LLMs),从业者通常会训练一个图像分词器,将图像映射成一系列离散标记(𝑡1,…,𝑡𝐾)。将图像转化为一系列离散标记(例如,图像分词化)后,估计图像的可能性就变得简单了:

其中𝑝𝜃由自回归VLM参数化。考虑到分词化是自回归VLM的关键部分,人们可能会问:我们如何训练图像分词器?许多当前的图像分词器基于向量量化-变分自编码器(VQ-VAE)[Van Den Oord 等人,2017]框架,它将一个自编码器(负责创建优质的压缩连续表征)与一个向量量化层(负责将连续表征映射到离散表征)结合起来。这种架构通常是一个卷积神经网络(CNN)[LeCun 和 Bengio, 1998]编码器,紧接着是一个向量量化层,然后是一个CNN解码器。实际的离散化步骤发生在向量量化层中,它将编码器的输出映射到学习过的嵌入表中最近的嵌入中(“学习”在此表示嵌入表在训练过程中更新)。分词器的损失函数是重建损失(例如,输入像素与重建像素之间的L2距离)和码本承诺损失的结合,以鼓励编码器输出和码本嵌入彼此靠近。大多数现代图像分词器在这个VQ-VAE框架的基础上进行改进,要么是通过添加不同的损失,要么是通过改变编码器/解码器的架构。值得注意的是,VQ-GAN [Esser 等人, 2021]加入了感知损失和对抗损失(涉及在真实图像和重建图像之间包含一个判别器),以捕捉更细微的细节。VIT-VQGAN [Yu 等人, 2022a]使用视觉变换器代替CNN作为编码器和解码器的架构。
使用扩散模型进行可能性估计。用扩散模型获得密度估计更具挑战性,因为它们不直接输出𝑝𝜃(𝑥∣𝑐)。相反,这些𝜖𝜃网络通常被训练用于估计带噪图像𝑥𝑡中的噪声𝜖。因此,基于扩散的分类技术[Li 等人, 2023a;Clark 和 Jaini, 2023]估计条件图像可能性的(通常被重新加权的)变分下界:

噪声预测误差越低,条件可能性𝑝𝜃(𝑥∣𝑐)就越高。方程(7)中的下界依赖于重复取样以获得蒙特卡洛估计。Li 等人[2023a]和Clark和Jaini[2023]开发了减少所需样本数量的技术,动态地将样本分配给最可能的类别,并确保增加的噪声𝜖在所有潜在类别中是一致的。然而,即使采用了这些技术,基于条件的扩散模型的分类仍然计算成本很高,随着类别数量的增加而增加,并且每个测试图像需要数百个甚至数千个网络估值。因此,尽管基于扩散模型的分类性能相当好,但在进一步优化之前,推理是不切实际的。
生成分类器的优势。尽管这些生成分类器的推断成本更高,但它们确实有显著的优势。生成分类器具有更高的“有效鲁棒性”,这意味着在给定内部分布准确性的条件下,它们具有更好的超出分布的性能[Li等人,2023a]。在像Winoground [Thrush 等人,2022]这样的组合推理任务上,生成分类器远远优于像CLIP [Li等人,2023a; Clark和Jaini,2023]这样的判别方法。无论是自回归(比如Parti)还是基于扩散的(比如Imagen),生成分类器都显示出更多的形状偏见,并且更符合人类的判断[Jaini等人,2024]。最后,生成分类器可以在测试时与判别模型一起使用仅未标记的测试样本进行联合调整[Prabhudesai等人,2023]。这已被证明可以提高分类、分割和深度预测任务的性能,特别是在在线分布转移场景中。
4、 基于预训练主干网络的视觉语言模型(VLM)
从头开始训练VLM的缺点
VLM的一个缺点是从头开始训练成本高昂。它们通常需要数百到数千个GPU,并且需要使用数亿张图片和文本对。因此,已有许多研究工作试图利用现有的大型语言模型和/或现有的视觉提取器,而不是从头开始训练模型。这些工作的动机在于许多大型语言模型是开源的,因此可以轻松使用。通过利用这些模型,可以仅学习文本模态和图像模态之间的映射。学习这样的映射使得LLM能够在需要较低计算资源的情况下回答视觉问题。在本节中,我们仅介绍其中的两个模型,第一个是利用预训练LLM的Frozen [Tsimpoukelli et al., 2021],然后我们介绍Mini-GPT [Zhu et al., 2023a]模型家族。
4.1 Frozen
Frozen [Tsimpoukelli et al., 2021] 是第一个利用预训练LLM的模型示例。这项工作提出通过一个轻量级映射网络将视觉编码器连接到已冻结的语言模型,该网络将视觉特征投影到文本标记嵌入中。视觉编码器(NF-ResNet-50 [Brock et al., 2021])和线性映射从头开始训练,而语言模型(在C4 [Raffel et al., 2020]上训练的70亿参数变换器)保持冻结(这对于保持预训练模型已经学到的特征至关重要)。该模型在Conceptual Captions [Sharma et al., 2018b]上使用简单的文本生成目标进行监督。在推理时,语言模型可以条件化在交错的文本和图像嵌入上。作者展示了该模型能够快速适应新任务,快速访问一般知识,并快速绑定视觉和语言元素。尽管性能只是适中,Frozen已经是朝向当前能够进行开放式多模态零/少次学习的多模态LLM的重要第一步。
4.2 MiniGPT模型示例
MiniGPT-4的应用
从Flamingo [Alayrac et al., 2022]等模型开始,近期的趋势是训练多模态语言模型,其中输入包含文本和图像,输出包含文本(可选图像)。MiniGPT-4 [Zhu et al., 2023a]接受文本和图像输入,并产生文本输出。在MiniGPT-4中,使用了一个简单的线性投影层来对齐图像表示(使用与BLIP-2 [Li et al., 2023e]中相同的视觉编码器,该编码器基于Q-Former和ViT主干)与Vicuna语言模型 [Chiang et al., 2023]的输入空间。鉴于视觉编码器和Vicuna语言模型已经预训练并作为现成产品使用,MiniGPT-4仅需要训练线性投影层,该训练分为两轮进行。第一轮包括20k训练步骤(批量大小为256),相当于大约500万个来自Conceptual Caption [Sharma et al., 2018b]、SBU [Ordonez et al., 2011]和LAION [Schuhmann et al., 2021]的图像-文本对。作者仅使用四个A100 GPU大约十小时,因为只需要训练线性投影层的参数。第二轮训练利用了高度策划的数据,采用指令调整格式,仅需要400个训练步骤(批量大小为12)。
MiniGPT-5的扩展
MiniGPT-5 [Zheng et al., 2023] 扩展了MiniGPT-4,使输出可以包含与图像交错的文本。为了同时生成图像,MiniGPT-5使用了生成性标记,这些特殊的视觉标记可以(通过变换层)映射到特征向量,然后可以输入到已冻结的Stable Diffusion 2.1模型 [Rombach et al., 2021]中。作者在下游任务(例如,多模态对话生成和故事生成)上使用了监督训练。
MiniGPT-v2的多任务应用
受到LLM作为许多语言相关应用的通用接口(例如,通用聊天机器人)的启发,MiniGPT-v2 [Chen et al., 2023b] 提出执行各种视觉语言任务,如图像字幕生成、视觉问答和对象定位,通过统一的接口。为了有效地实现这些目标,MiniGPT-v2在训练时为不同任务引入了独特的标识符,使模型能够轻松区分每个任务指令并高效学习。在视觉问答和视觉定位基准测试上的实验结果表明,MiniGPT-v2展示了强大的视觉语言理解能力。
4.3 使用预训练主干的其他热门模型
Qwen模型
与MiniGPT-4类似,Qwen-VL和Qwen-VL-Chat [Bai et al., 2023b]模型依赖于LLM、视觉编码器和一种机制,该机制将视觉表示对齐到LLM的输入空间。在Qwen中,LLM从Qwen-7B [Bai et al., 2023a]初始化,视觉编码器基于ViT-bigG,并使用了一层交叉注意模块将视觉表示压缩为固定长度(256)的序列,然后输入到LLM中。
BLIP-2模型
Li et al. [2023e]引入了BLIP-2,这是一个视觉语言模型,接受图像输入并生成文本输出。它利用预训练的冻结模型大大缩短了训练时间:视觉编码器(如CLIP)产生图像嵌入,这些嵌入被映射到LLM(如OPT)的输入空间。一个相对较小的(约100-200M参数)组件称为Q-Former进行此映射训练——它是一个变换器,接收固定数量的随机初始化的“查询”向量;在前向传递中,查询通过Q-Former中的交叉注意与图像嵌入相互作用,随后通过一个线性层将查询投影到LLM的输入空间。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)