
QWen2.5解读-闭源模型的挑战者
本文深入剖析了QWen2.5模型的核心特性和底层技术。QWen2.5在保持与前代一致结构的基础上,创新性地引入了专用工具调用模板,大幅提升了结构化数据的处理能力。模型经过18T数据的深度训练,输出长度扩展至8K,综合性能显著增强。在垂直领域,QWen2.5-Coder模型通过5.5T代码数据的训练,实现了对92种编程语言的高效支持,同时保留了卓越的数学和通用推理能力。
引言
2024年9月19日,阿里巴巴发布了最新一代大语言模型——通义千问2.5,在AI领域掀起巨浪。这一升级不仅全面超越了其前身QWen2,更在多个关键指标上直面甚至超越了GPT-4和Claude等顶尖闭源模型,开源AI开始向闭源霸主发起挑战。本文将深入剖析通义千问2.5的核心特性,探讨其背后的技术创新,揭示这一里程碑式突破对AI格局的深远影响。
文章的整体结构如下:
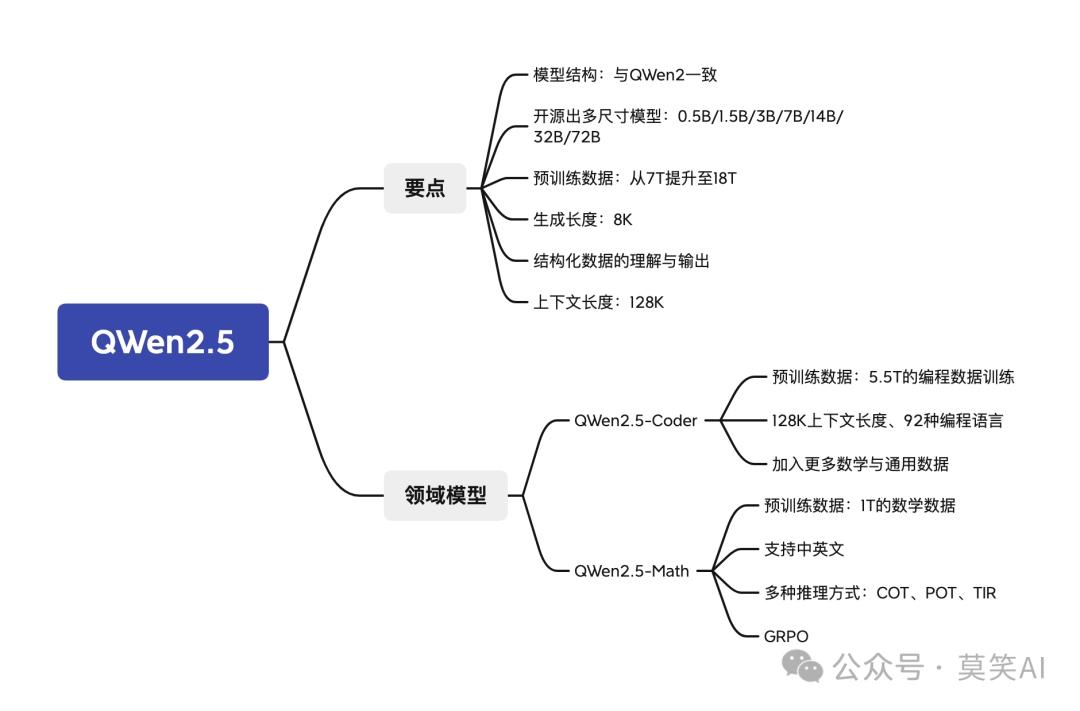
QWen2.5
QWen2.5

x2vFG2
根据QWen博客上晒出的榜单数据,本文将相同能力维度的评测集取平均,评测模型在不同能力上的表现:
-
专业知识:MMLU-Pro、MMLU-redux
-
逻辑推理:GPQA
-
数学能力:MATH、GSM8K
-
代码能力:HumanEval、MBPP、Multiple-E、LiveCodeBench
-
指令遵循:LiveBench、IFEval、AlignBench
|
| 专业知识 | 逻辑推理 | 数学能力 | 代码能力 | 指令遵循 |
| — | — | — | — | — | — |
| QWen2.5-72B-Instruct | 78.95 | 49 | 89.45 | 76.35 | 72.66666667 |
| QWen2-72B-Instruct | 73 | 42.4 | 81.1 | 66.9 | 66.86666667 |
| Claude3.5 sonnet | 81.05 | 59.4 | 83.75 | 78.825 | 74.76666667 |
| GPT4-o | 82.65 | 53.6 | 86.35 | 75.2 | 73.93333333 |
整体来说,Qwen2.5相较Qwen2在各项能力上均有显著提升:专业知识增长7.5%,逻辑推理提升13.5%,数学能力提高9.3%,代码能力增强12.3%,指令遵循能力提高7.9%。与领先模型相比,Qwen2.5在数学能力上超越GPT-4和Claude,在代码能力、指令遵循和专业知识方面差距缩小,但复杂逻辑推理仍有较大差距。
下面让我们详细看一下QWen2.5的模型结构与模型特色,探究清楚这些特色的实现方式。
模型结构
从开放出的模型config文件可以看到,QWen2.5的结构与QWen2的结构是保持一致的:

neO2qt
Scaling-Law
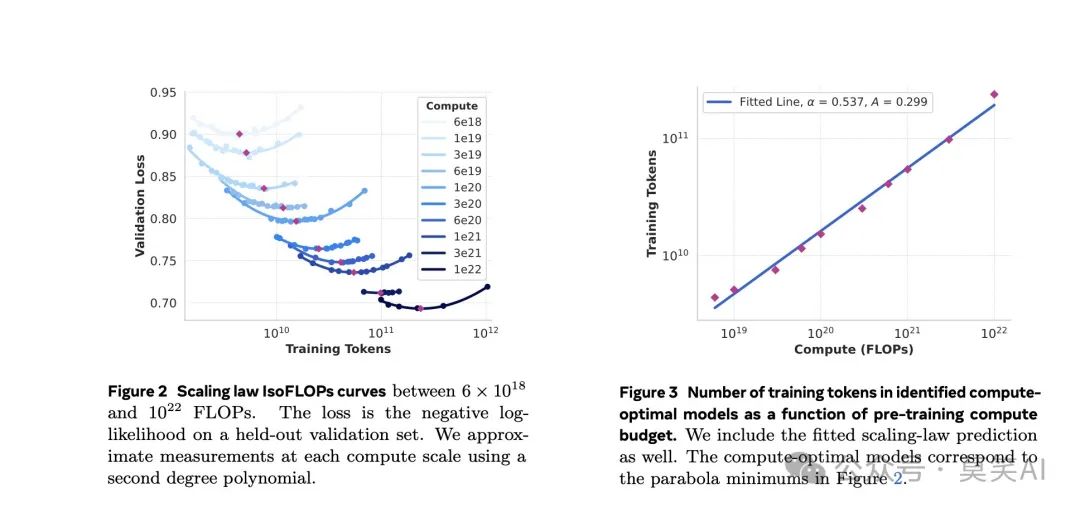
正如QWen2博客的结尾所说,QWen团队进一步探索模型和数据的Scaling Law,在QWen2.5的预训练阶段使用了高达18T Token的训练数据。

dfG7RS
期待QWen2.5技术报告中关于Scaling-Law的详细介绍,下面是LLaMA3.1中关于Scaling Law的介绍部分,而在DeepSeek模型解读:Scaling Law,MLA,MoE中,也提及Scaling Law不同的原因与数据集的质量相关:
pi0pVj
详细的计算公式如下:
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

长文本生成
QWen2.5支持长达8K的文本生成,那么这项技术是如何实现的呢?
这就需要关联到GLM团队放出的LongWriter论文:
论文:https://arxiv.org/abs/2408.07055
代码:https://github.com/THUDM/LongWriter
模型:
Huggingface:https://huggingface.co/THUDM/LongWriter-glm4-9b
魔搭:https://modelscope.cn/models/ZhipuAI/LongWriter-glm4-9b
数据:
Huggingface:https://huggingface.co/datasets/THUDM/LongWriter-6k
魔搭:https://modelscope.cn/datasets/ZhipuAI/LongWriter-6k
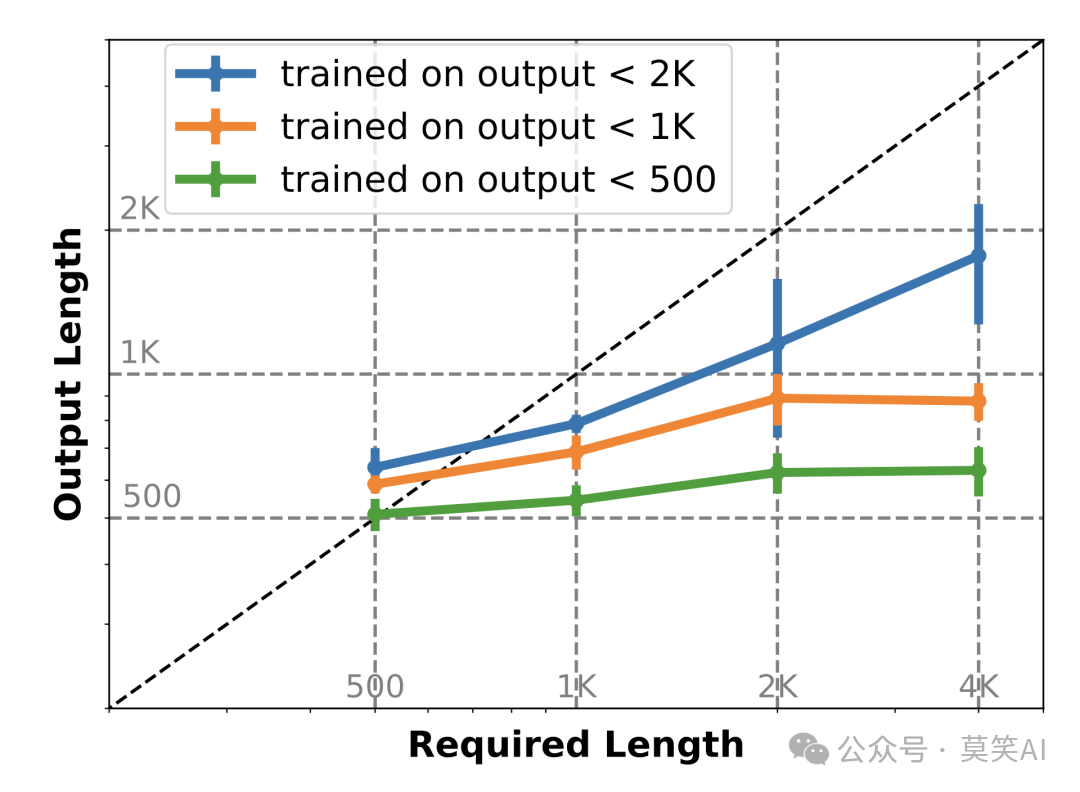
该论文发现当前最先进的大模型在面对长文本输出的指令要求时,输出长度均不超过2K:

cyW1m4
论文中关于该现象的结论是:尽管长文本模型在预训练阶段接触了更长的文本序列,但其最大生成长度实际上被 SFT 数据集中输出长度的上限所限制。换句话说,模型“读”到的内容决定了它能“写”多长。
8skMCA
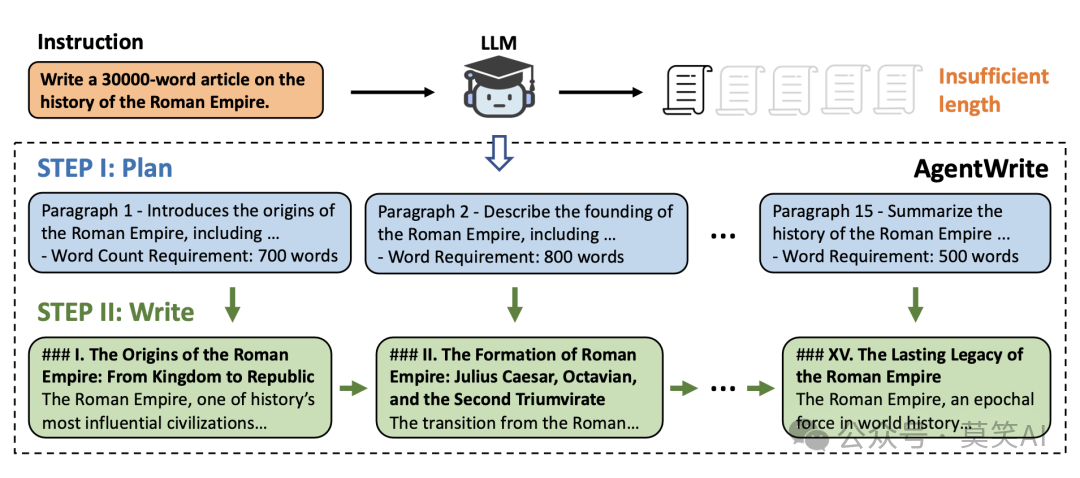
GLM团队因此设计了一个名为AgentWrite的 pipeline,通过分解长生成任务,让现有模型来生成更长的具备连贯性的输出。
具体来说,AgentWrite
-
首先,会根据用户的输入生成一个详细的写作计划,包括每段内容的结构和目标字数
-
其次,模型依次完成每个子任务,并将生成的段落串联起来,最终形成完整的长文本输出。
hUobPI
通过这种方法,AgentWrite 能够生成超过 20,000 字的高质量文本。
最终通过在该数据集上的SFT与DPO有效提升了模型的输出质量与长文本生成中遵循长度要求的能力:

ef4vW4
结构化理解
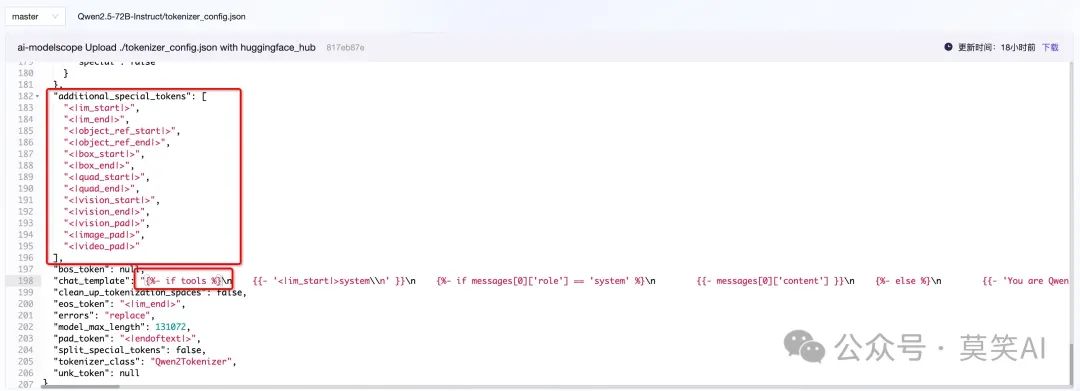
QWen2.5与QWen2在配置文件上还存在些许不同,在tokenizer上添加了许多special token,对话模版上针对工具调用作了处理:
VitDos
下面是一个工具调用的示例:
prompt = "Give me a short introduction to large language model."
def get_current_temperature(location: str, unit: str) -> float:
"""
Get the current temperature at a location.
Args:
location: The location to get the temperature for, in the format "City, Country"
unit: The unit to return the temperature in. (choices: ["celsius", "fahrenheit"])
Returns:
The current temperature at the specified location in the specified units, as a float.
"""
return 22. # A real function should probably actually get the temperature!
def get_current_wind_speed(location: str) -> float:
"""
Get the current wind speed in km/h at a given location.
Args:
location: The location to get the temperature for, in the format "City, Country"
Returns:
The current wind speed at the given location in km/h, as a float.
"""
return 6. # A real function should probably actually get the wind speed!
tools = [get_current_temperature, get_current_wind_speed]
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tools=tools,
tokenize=False,
add_generation_prompt=True
)
print(text)
编码输出为,可以清楚的看到QWen2.5关于工具调用的模版:
<|im_start|>system
You are Qwen, created by Alibaba Cloud. You are a helpful assistant.
# Tools
You may call one or more functions to assist with the user query.
You are provided with function signatures within <tools></tools> XML tags:
<tools>
{"type": "function", "function": {"name": "get_current_temperature", "description": "Get the current temperature at a location.", "parameters": {"type": "object", "properties": {"location": {"type": "string", "description": "The location to get the temperature for, in the format \"City, Country\""}, "unit": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The unit to return the temperature in."}}, "required": ["location", "unit"]}, "return": {"type": "number", "description": "The current temperature at the specified location in the specified units, as a float."}}}
{"type": "function", "function": {"name": "get_current_wind_speed", "description": "Get the current wind speed in km/h at a given location.", "parameters": {"type": "object", "properties": {"location": {"type": "string", "description": "The location to get the temperature for, in the format \"City, Country\""}}, "required": ["location"]}, "return": {"type": "number", "description": "The current wind speed at the given location in km/h, as a float."}}}
</tools>
For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{{"name": <function-name>, "arguments": <args-json-object>}}
</tool_call><|im_end|>
<|im_start|>user
Give me a short introduction to large language model.<|im_end|>
<|im_start|>assistant
QWen2.5-Coder

5ISTWZ
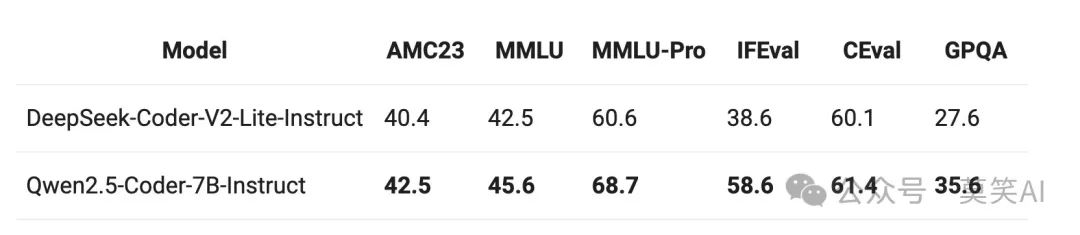
Qwen2.5-Coder 最多 128K tokens 上下文,支持 92 种编程语言,并在多个代码相关的评估任务中都取得了显著的提升,包括代码生成、多编程语言代码生成、代码补全、代码修复等。值得注意的是,本次开源的 7B 版本 Qwen2.5-Coder,甚至打败了更大尺寸的 DeepSeek-Coder-V2-Lite 和 Codestral-20B,成为当前最强大的基础代码模型之一。
其中Qwen2.5-Coder的核心点包括代码训练数据的进一步 scaling,以及探索在提升代码能力的同时保持数学和通用能力。
-
码无止境:Qwen2.5-Coder 基于强大的 Qwen2.5 初始化,扩增了更大规模的代码训练数据持续训练,包括源代码、文本代码混合数据、合成数据等共计 5.5T tokens。使得 Qwen2.5-Coder 在代码生成、代码推理、代码修复等任务上都有了显著提升。
-
学无止境:希望 Qwen2.5-Coder 在提升代码能力的同时,也能保持在数学、通用能力等方面的优势。因此,我们在 Qwen2.5-Coder 中加入了更多的数学、通用能力数据,为未来的真实应用提供更为全面的基座。
Qwen2.5-Coder出色的地方在于:
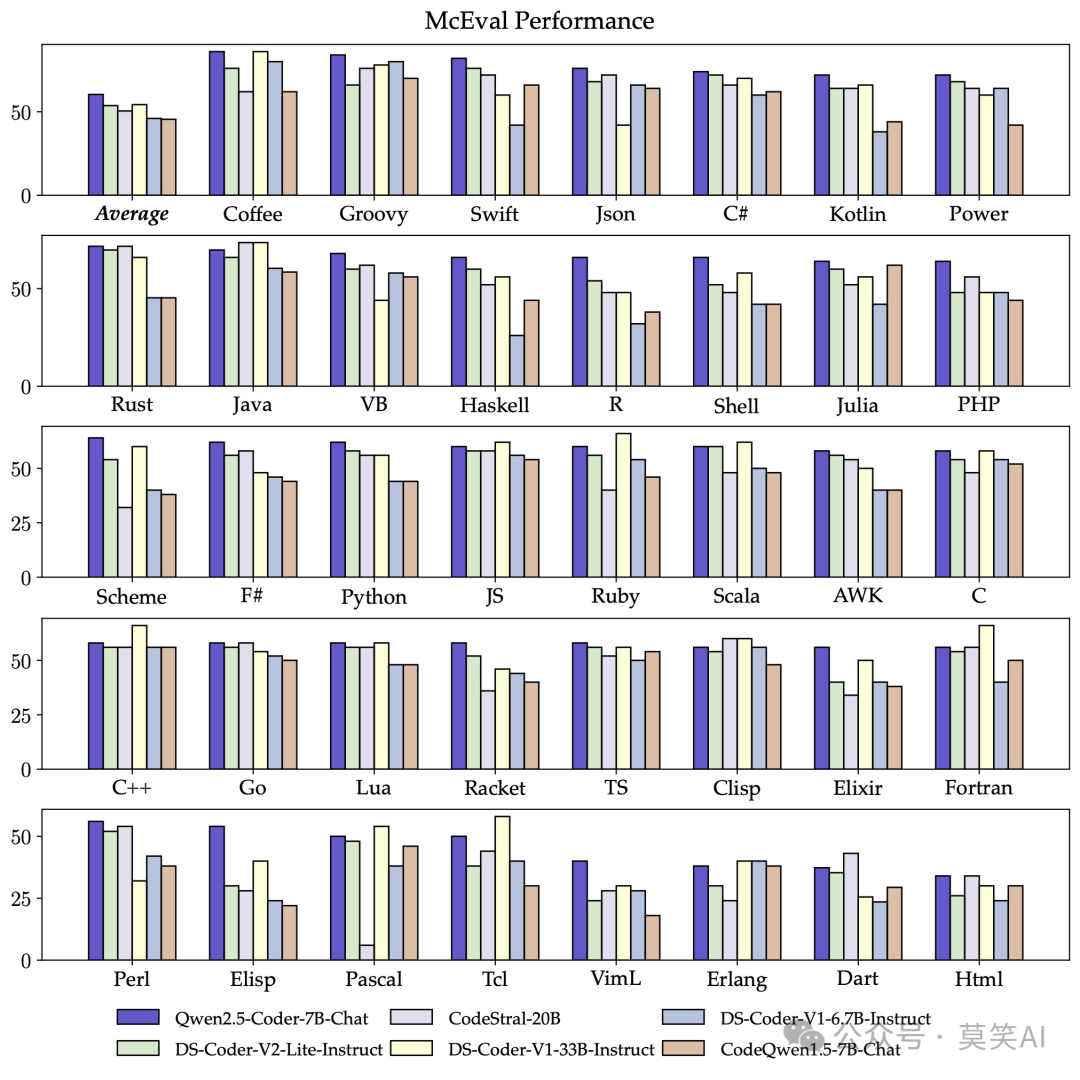
- 多编程语言的支持:支持了92中编程语言,虽然HumanEval这些还逊于Claude、GPT4,但是多编程语言能力评测Multiple-E已经超过了一众闭源模型。
YT66ry
- 数学与推理能力:通过混合数学与通用数据,Qwen2.5-Coder也具有优秀的数学和推理能力。

AWs1DL

tq9IjP
- 通用能力:通过混合数学与通用数据,Qwen2.5-Coder也保留了一定的通用能力。
vrxbmv
QWen2.5-Math

I94tmH
Qwen2.5-Math系列相比上一代Qwen2.5-Math在中文和英文的数学解题能力上均实现了显著提升。并且同时支持使用思维链和工具集成推理(TIR) 解决中英双语的数学题。
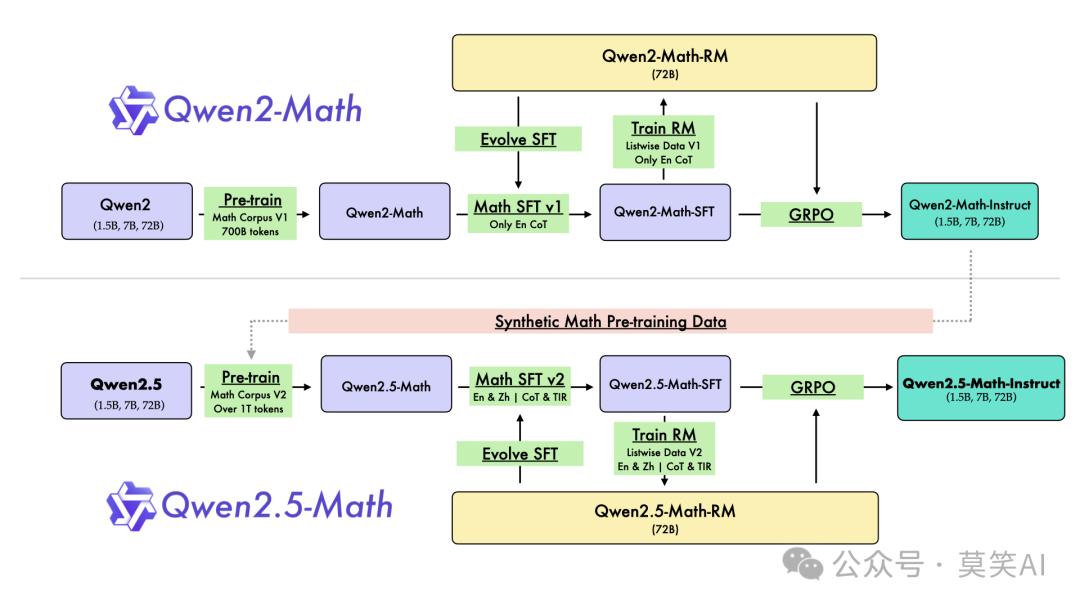
Qwen2-Math 和 Qwen2.5-Math 的整体训练流程如下图所示,包含完整的Pretrain、SFT、RLHF过程。
CiLupf
Pre-training
QWen2.5 Math中采用了1T Token 上下文长度为4K的预训练数据集,该数据集构成方式为:
1)利用 Qwen2-Math-72B-Instruct 模型合成更多高质量的数学预训练数据。
2)通过多轮召回从网络资源、书籍和代码中获取更多高质量的数学数据,尤其是中文数学数据。
3)利用 Qwen2.5 系列基础模型进行参数初始化,它们相比Qwen2有更强大的语言理解、代码生成和文本推理能力。
Post-training
Qwen2.5-Math-72B 训练了一个数学专用奖励模型 Qwen2.5-Math-RM-72B。此 RM 通过拒绝抽样构建 SFT 数据,也用于 SFT 之后的 GRPO 强化学习。
在拒绝采样的过程中,额外使用 Qwen2-Math-Instruct 模型和 Qwen2.5-Math-RM-72B 进行了迭代,以在拒绝抽样期间进一步提高解题过程的质量。
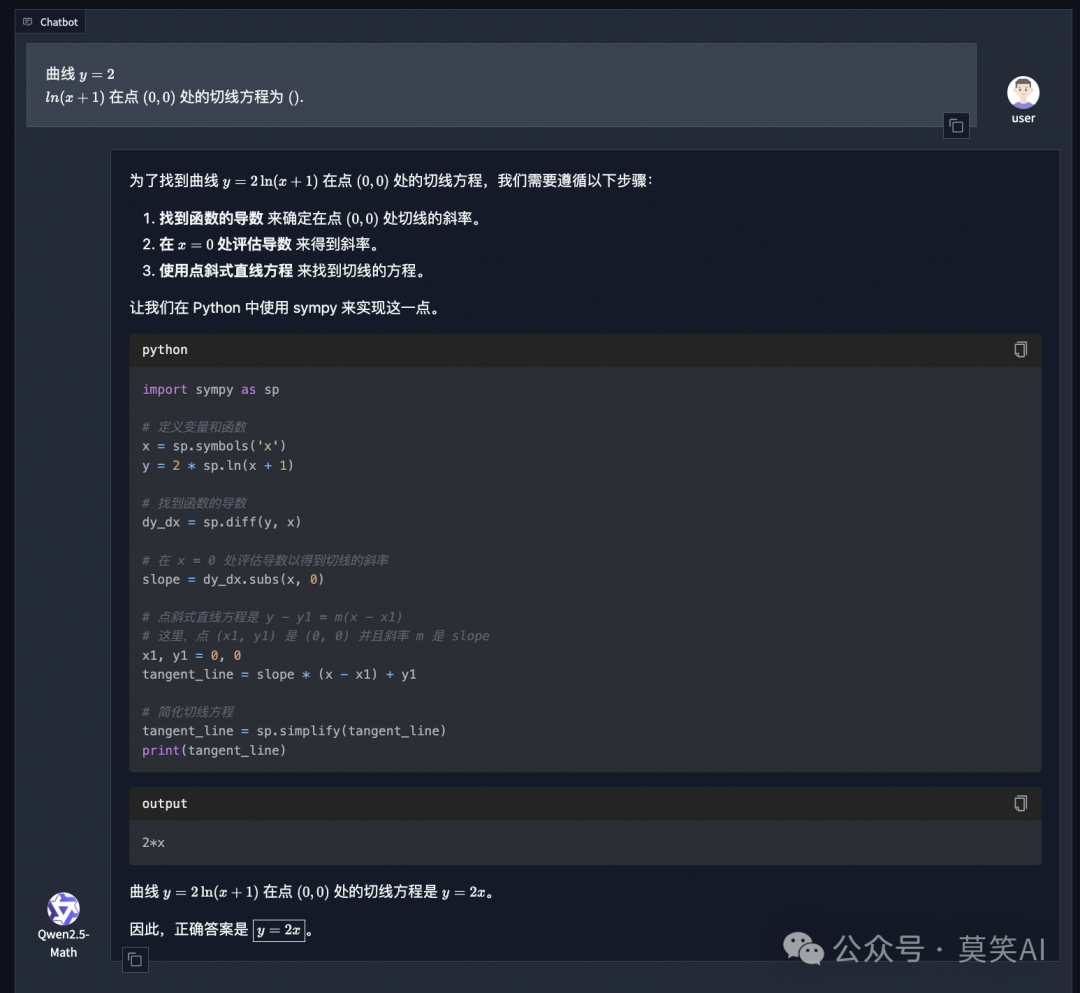
在数据上, Qwen2.5 后训练进一步引入了中文和英文的 TIR 数据和 CoT 数据。虽然 CoT 在增强 LLM 的推理能力方面发挥着重要作用,但它在实现计算精度和处理复杂的数学或算法推理任务方面依然面临挑战,例如寻找二次方程的根或计算矩阵的特征值等等。而 TIR(如使用python解释器)可以进一步提高模型在精确计算、符号操作和算法操作方面的能力。Qwen2.5-Math-1.5B/7B/72B-Instruct 使用 TIR 在 MATH 基准测试中分别达到 79.7、85.3 和 87.8的高分。
使用python解释器与Coder又有异曲同工之妙,下面是一个TIR的示例:
BuHEhv
总的来说,Qwen2.5-Math,它有以下几个关键的技术亮点:
(1)在预训练阶段大量使用来自Qwen2-Math的合成数学数据。
(2)在后训练阶段迭代生成微调数据并在奖励模型的指导下进行强化训练。
(3)支持双语(英语和中文)解题,以及思路链和工具集成推理能力。
总结
本文深入剖析了QWen2.5模型的核心特性和底层技术。QWen2.5在保持与前代一致结构的基础上,创新性地引入了专用工具调用模板,大幅提升了结构化数据的处理能力。模型经过18T数据的深度训练,输出长度扩展至8K,综合性能显著增强。
在垂直领域,QWen2.5-Coder模型通过5.5T代码数据的训练,实现了对92种编程语言的高效支持,同时保留了卓越的数学和通用推理能力。而QWen2.5-Math模型更是突破性地超越多个闭源对手,凭借1T高质量数学数据的训练,结合COT和TIR等先进技术,在数学领域展现出了非凡的表现。
如何学习AI大模型?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
想正式转到一些新兴的 AI 行业,不仅需要系统的学习AI大模型。同时也要跟已有的技能结合,辅助编程提效,或上手实操应用,增加自己的职场竞争力。
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
那么针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

学习路线

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

{kind=link}
所有评论(0)