
Qwen学习心得
第一课学习的是Qwen大模型的一些原理,作为一位技术小白只能艰难地边生啃其中的内容边恶补一些基础的知识。旋转位置编码是一种特殊的相对位置编码,通过在注意力计算中引入旋转变换,将相对位置编码隐式引入查询和键的点积计算中。也就是说,在做查询和键张量内积的时候实现了相对位置的效果,这点可以从apply_rotary_pos_emb函数看出。3.最后,将门控和更新后的结果通过 down_proj 映射回隐
最近参加了datawhale的五月组队学习,主题是手搓大模型实战课程。第一课学习的是Qwen大模型的一些原理,作为一位技术小白只能艰难地边生啃其中的内容边恶补一些基础的知识。以下是我个人的学习心得,可能多处有谬误,zhendehencai......
Qwen是一个decoder-only的transformer模型,使用SwiGLU激活函数、Rotary Positional Embedding(ROPE)等,以提高模型存储和运行效率。
先跟着课程的老师写了个运行的demo,通过在model处设断点调试可以看到代码进行的流程。
from transformers_sc.src.transformers.models.qwen2 import Qwen2Config, Qwen2Model
import torch
def run_qwen2():
qwen2config = Qwen2Config(vocab_size=151936,
hidden_size=4096//2,
intermediate_size=22016//2,
num_hidden_layers=32//2,
num_attention_heads=32,
max_position_embeddings=2048//2)
qwen2model = Qwen2Model(config=qwen2config)
input_ids = torch.randint(0, qwen2config.vocab_size, (4,30))
res = qwen2model(input_ids)
print(type(res))
if __name__ == "__main__":
run_qwen2()试着读了一下ROPE的具体操作。。。 先准备好ROPE需要的一些参数,主要是cos和sin值。
#定义一个旋转位置嵌入类,通过预计算和缓存cos和sin值,提高模型处理长序列时的效率。
class Qwen2RotaryEmbedding(nn.Module):
#初始化方法,接受维度、最大位置嵌入数量、频率、设备四个参数
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
super().__init__()
self.dim = dim
self.max_position_embeddings = max_position_embeddings
self.base = base
#计算逆频率(register_buffer对逆频率在模型中注册参数,'persistent=False'指该参数在训练过程中不会更新)
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(device) / self.dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
# Build here to make `torch.jit.trace` work.
self._set_cos_sin_cache(
seq_len=max_position_embeddings, device=self.inv_freq.device, dtype=torch.get_default_dtype()
)
def _set_cos_sin_cache(self, seq_len, device, dtype):
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=device, dtype=torch.int64).type_as(self.inv_freq)
#计算t和inv_ferq的外积freqs,其与自身在最后一个维度拼接成一个新张量emb
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
emb = torch.cat((freqs, freqs), dim=-1)
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
#定义前向传播函数forward,其中x为输入张量,seq_len为序列长度
def forward(self, x, seq_len=None):
# x: [bs, num_attention_heads, seq_len, head_size]
if seq_len > self.max_seq_len_cached:
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
return (
self.cos_cached[:seq_len].to(dtype=x.dtype),
self.sin_cached[:seq_len].to(dtype=x.dtype),
)计算出ROPE方法的cos和sin值后,再来实现ROPE。
# Copied from transformers.models.llama.modeling_llama.rotate_half
#定义半旋转函数,将输入张量 x 的后一半维度旋转到前面,同时将前一半维度保持不变
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
# Copied from transformers.models.mistral.modeling_mistral.apply_rotary_pos_emb
def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1):
"""Applies Rotary Position Embedding to the query and key tensors.
Args:
q (`torch.Tensor`): The query tensor.
k (`torch.Tensor`): The key tensor.
cos (`torch.Tensor`): The cosine part of the rotary embedding.
sin (`torch.Tensor`): The sine part of the rotary embedding.
position_ids (`torch.Tensor`):
The position indices of the tokens corresponding to the query and key tensors. For example, this can be
used to pass offsetted position ids when working with a KV-cache.
unsqueeze_dim (`int`, *optional*, defaults to 1):
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
Returns:
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
"""
"""
q: 查询张量Query
k: 键张量Key
cos: 旋转位置编码中的余弦部分
sin: 旋转位置编码中的正弦部分
position_ids: 查询和键张量对应的位置信息。
unsqueeze_dim: 用于广播的维度,默认值为1。
返回是包含了两个torch.Tensor对象即经过旋转位置编码处理后的查询张量(q_embed)和键张量(k_embed)的元组
"""
cos = cos[position_ids].unsqueeze(unsqueeze_dim)
sin = sin[position_ids].unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed旋转位置编码是一种特殊的相对位置编码,通过在注意力计算中引入旋转变换,将相对位置编码隐式引入查询和键的点积计算中。也就是说,在做查询和键张量内积的时候实现了相对位置的效果,这点可以从apply_rotary_pos_emb函数看出。
瞄了眼论文,找了找相关的数学公式。
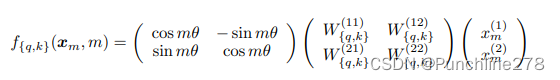
后两项乘起来就是Query向量了,这不就是一个旋转矩阵和Query向量相乘吗?!
然后由于内积线性可加,2D可以推广到General Form,即任意偶数维:
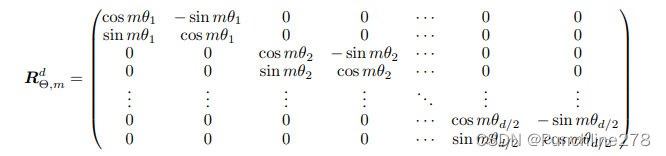
后面的多层感知机函数模块:
class Qwen2MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
# 三个Linear层,有门控机制,将输入张量映射到中间层大小
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
# 激活函数,根据ACT2FN字典里的配置选择相应的激活函数
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
forward 方法定义了模型的前向传播逻辑:
1.首先,通过 gate_proj 将输入 x 映射到中间大小,并应用激活函数 act_fn。
2.将门控后的结果乘以通过 up_proj 映射的输入 x,实现门控的作用。
3.最后,将门控和更新后的结果通过 down_proj 映射回隐藏大小,作为最终的输出。
其中config.hidden_act应该是使用了SwiGLU函数。在configuration的init里找,发现是“silu”.
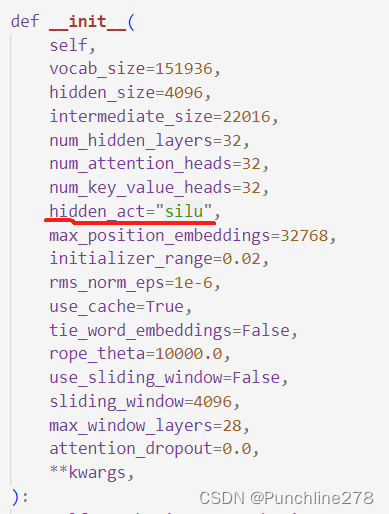
就先到这里吧。。。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)