

引言
SGLang 是一个用于大型语言模型和视觉语言模型的推理框架。基于并增强了多个开源 LLM 服务引擎(包括LightLLM、vLLM和Guidance )的许多优秀设计。SGLang 利用了FlashInfer注意力性能 CUDA 内核,并集成了受gpt-fast启发的 torch.compile 。
此外,SGLang 还引入了RadixAttention等创新技术,用于自动 KV 缓存重用和压缩状态机,用于快速约束解码。SGLang 以其高效的批处理调度程序而闻名,该调度程序完全用 Python 实现。SGLang 高效的基于 Python 的批处理调度程序具有良好的扩展性,通常可以匹敌甚至超越用 C++ 构建的闭源实现。
项目开源地址:https://github.com/sgl-project/sglang
近期,SGLang发布的benchmark显示,在A100 GPU上的许多测试场景中,SGLang性能优于 vLLM,在 Llama-70B 上的吞吐量高达 3.1 倍。如下为SGLang 官方提供的部分测试benchmark。
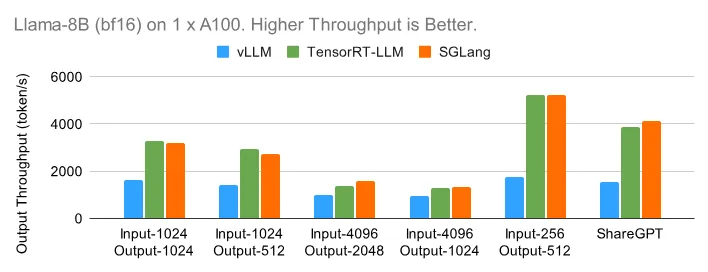
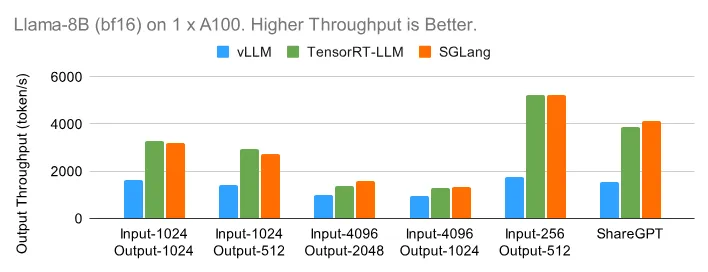
1 x A100 (bf16) 上的 Llama-8B
从小模型 Llama-8B 开始,下图展示了每个引擎在离线设置下在六个不同数据集上可以实现的最大输出吞吐量。TensorRT-LLM 和 SGLang 都可以在输入较短的数据集上实现高达每秒 5000 个 token 的出色吞吐量。
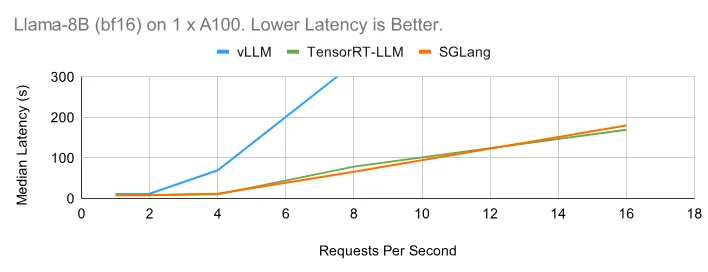
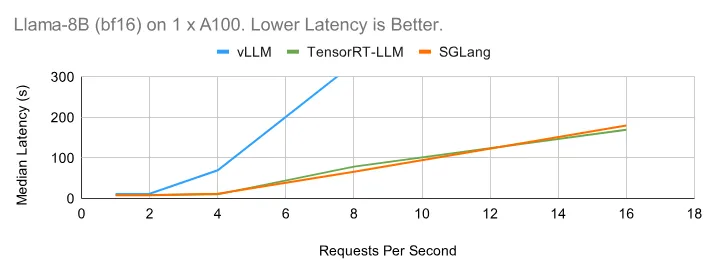
下面的在线benchmark图显示了与离线情况类似的趋势。SGLang 表现出色。
8 卡 A100 (bf16) 上的 Llama-70B
转向在 8 个 GPU 上具有张量并行性的更大的 Llama-70B 模型,趋势与 8B 的情况类似。在下面的离线基准测试中,TensorRT-LLM 和 SGLang 都可以扩展到高吞吐量。
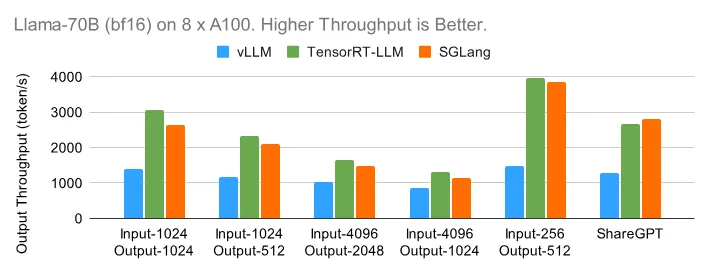
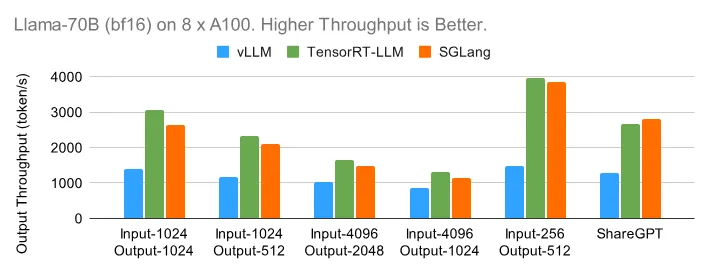
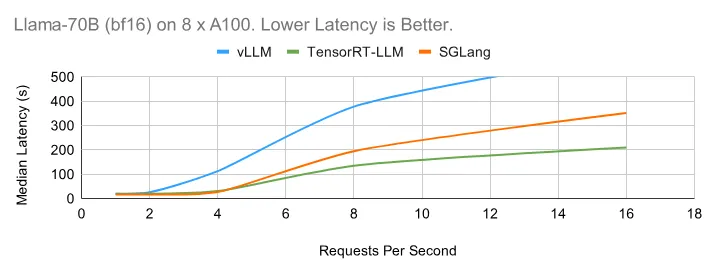
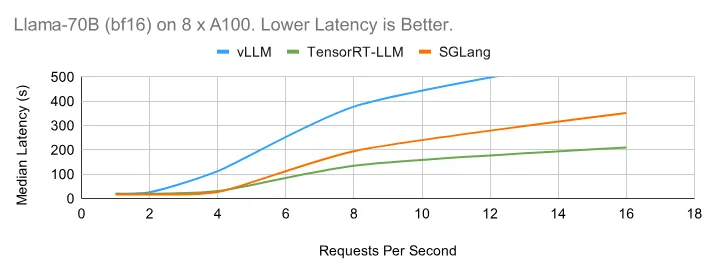
在下面的在线图中,TensorRT-LLM 得益于其高效的内核实现和运行时,表现出了出色的延迟性能。
魔搭最佳实践
在魔搭的免费Notebook环境(22G显存)中使用SGLang+Qwen2-7B-Instruct
环境安装
pip install --upgrade pip
pip install "sglang[all]"
# Install FlashInfer CUDA kernels
wget "https://modelscope.oss-cn-beijing.aliyuncs.com/resource/flashinfer-0.1.2%2Bcu121torch2.3-cp310-cp310-linux_x86_64.whl"
pip install flashinfer-0.1.2+cu121torch2.3-cp310-cp310-linux_x86_64.whl
# Update transformers for Llama3.1
# pip install --upgrade transformers模型下载
模型链接:https://modelscope.cn/models/qwen/Qwen2-7B-Instruct
使用ModelScope CLI完成模型下载
modelscope download --model=qwen/Qwen2-7B-Instruct --local_dir ./Qwen2-7B-Instruct模型部署
使用The SGLang Runtime (SRT) 完成模型高效serving,注意,本文为了让模型可以在消费级显卡(22G显存)上运行,使用了--disable-cuda-graph参数,会损失一部分推理性能。
python -m sglang.launch_server --model-path /mnt/workspace/Qwen2-7B-Instruct --port 30000 --dtype bfloat16 --disable-cuda-graph --context-length 512请求调用
curl
curl http://localhost:30000/generate \
-H "Content-Type: application/json" \
-d '{
"text": "Once upon a time,",
"sampling_params": {
"max_new_tokens": 16,
"temperature": 0
}
}'支持OpenAI格式的API调用
python
import openai
client = openai.Client(
base_url="http://127.0.0.1:30000/v1", api_key="EMPTY")
# Chat completion
response = client.chat.completions.create(
model="default",
messages=[
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": "以杭州的春天为题,写一篇100字的短文"},
],
temperature=0,
max_tokens=150,
)
print(response)性能评估
我们也针对vLLM和SGLang做了性能评估,首先敲重点:
-
SGLang适用场景
-
框架整体性能,尤其是sampler性能,相比模型执行性能更加具有显著优势
-
适用场景:小模型
-
适用场景:大batch(尤其是MoE模型)
-
-
主要性能差距:
-
采样器(sampler):greedy 约10倍差距,sampled 约20倍差距
-
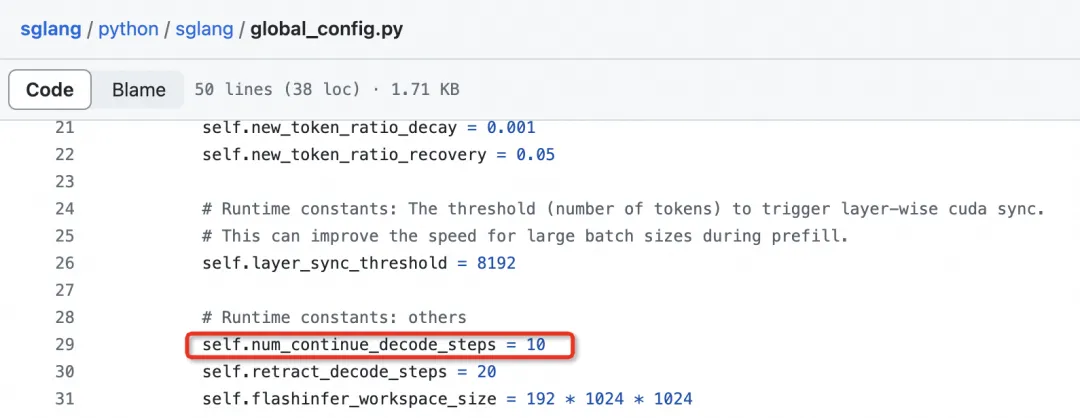
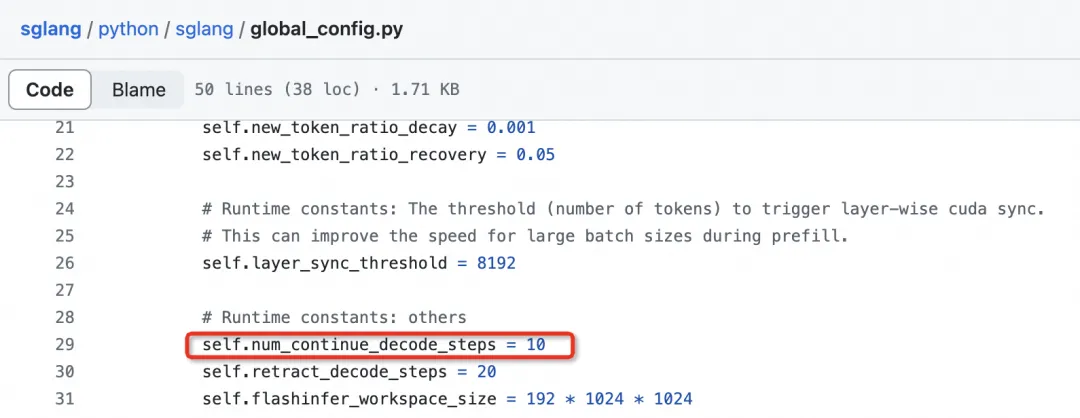
调度:SGLang Runtime增量式维护model inputs data structures,使得模型调度开销更小,同时支持num_continue_decode_steps来实现调度一次,运行k步decode,进一步减小框架额外开销。
-
-
注意事项
-
可能出于性能考虑,SGLang现在的版本不支持presence_penalty,presence_penalty用于用户控制模型生成时整个序列中的重复度。
-
Qwen2-7B-Instruct,H800 x 1
在我们有限的具体测试场景上,性能对比如下:
|
|
整体性能 |
prefill |
decode |
|
性能评估 |
SGLang runtime 显著优于vLLM |
接近 |
SGLang runtime 性能比vLLM高一倍 |
针对batch size 128 + cudagraph + temperature=1.0 的场景,具体性能如下:
|
|
Mean TTFT |
P99 TTFT |
Mean TPOT |
P99 TPOT |
Thorughput( requests/s) |
Thorughput( tokens/s) |
|
SGLang Runtime |
20.31 |
111.82 |
12.95 |
14.59 |
24.57 |
19109.23 |
|
vLLM |
21.37 |
119.69 |
27.03 |
134.54 |
15.71 |
12220.8 |
主要的性能差异在于Sampler:sampler部分性能差10倍(greedy)/ 20倍(sampled)
Qwen2-72B-Instruct,H800 x 4
在我们有限的具体测试场景上,性能对比如下:
|
|
整体性能 |
prefill |
decode |
|
性能评估 |
SGLang runtime 比vLLM高10% |
vLLM比SGLang runtime高约30% |
SGLang runtime 性能比vLLM高约20% |
针对batch size 128 + enforce eager + temperature=1.0 的场景,具体性能如下:
|
|
Mean TTFT |
P99 TTFT |
Mean TPOT |
P99 TPOT |
Thorughput( requests/s) |
Thorughput( tokens/s) |
|
SGLang Runtime |
75.18 |
398.23 |
51.97 |
173.62 |
6.4 |
4978.43 |
|
vLLM |
97.51 |
528.64 |
40.83 |
51.22 |
6.2 |
4764.47 |
主要的性能差异在于Sampler:sampler部分性能差10倍(greedy)/ 20倍(sampled)








 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)