

引言
7.23晚,Meta正式发布Llama 3.1,包含8B、70B 和405B三个规模,最大上下文提升到了128k。Llama系列模型是目前开源领域中用户最多、性能最强的大型模型系列之一。
官方公布的Benchmark显示,Llama3.1 405B已在多项基准测试中超越GPT-4o和Claude 3.5 Sonnet,这是开源大模型首次赶超最强闭源模型!
本次Llama 3.1的要点有:
1.共有8B、70B及405B三种版本,其中405B版本是目前最大的开源模型之一;
2.该模型最大参数规模达到4050亿参数,在性能上超越了现有的顶级AI模型;
3.模型引入了更长的上下文窗口(最长可达128K tokens),能够处理更复杂的任务和对话;
4. 支持多语言输入和输出,增强了模型的通用性和适用范围;
5.提高了推理能力,特别是在解决复杂数学问题和即时生成内容方面表现突出。
模型评估
Llama 3.1版本在 150 多个涵盖多种语言的基准数据集上评估了性能。此外,还进行了广泛的人工评估,在真实场景中将 Llama 3.1 与竞争模型进行了比较。通过实验评估表明,Llama 3.1的旗舰模型在一系列任务中与领先的基础模型相媲美,包括 GPT-4、GPT-4o 和 Claude 3.5 Sonnet。此外,Llama 3.1的小型模型与具有相似数量参数的封闭和开放模型相媲美。
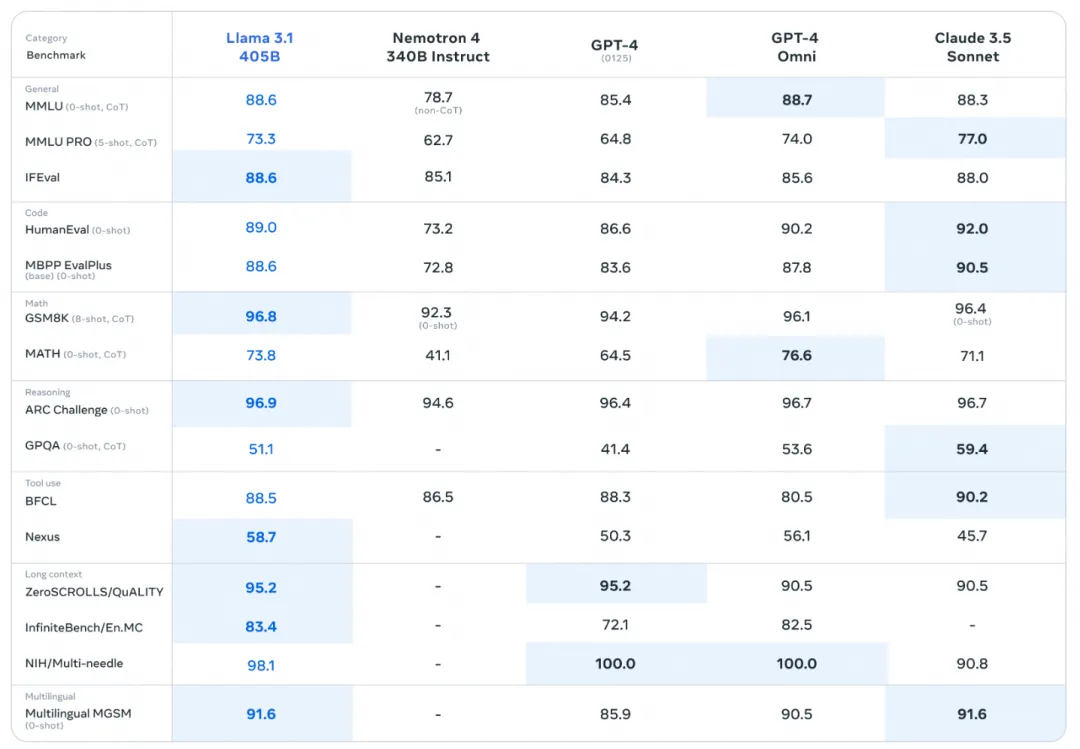
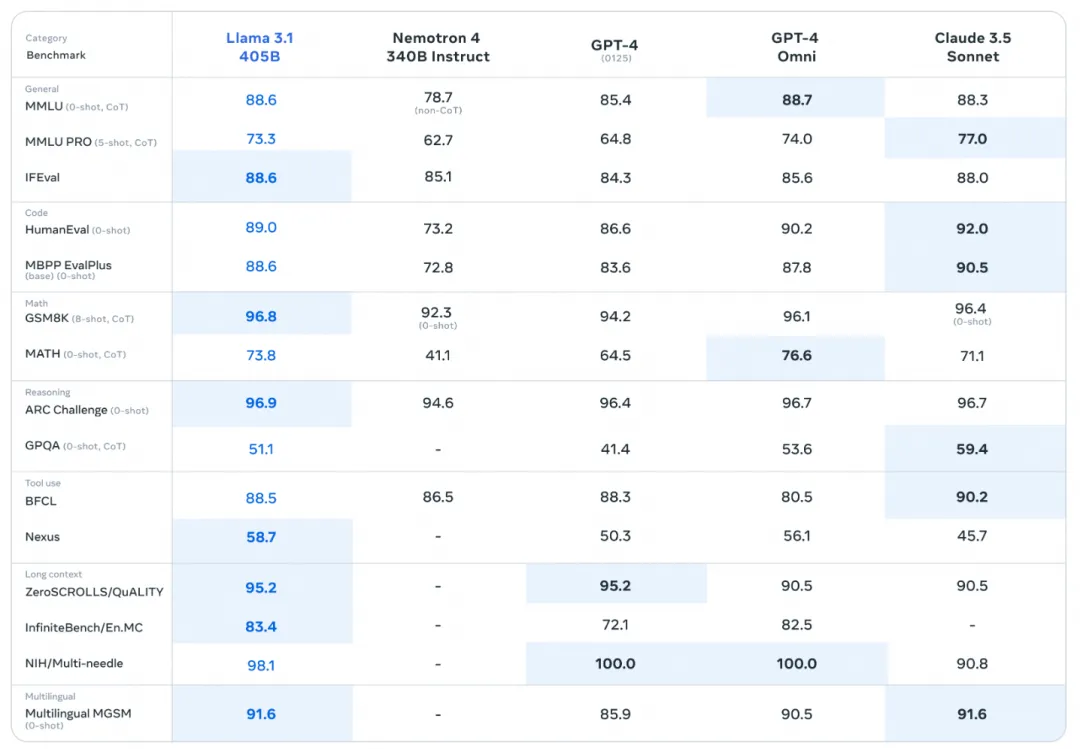
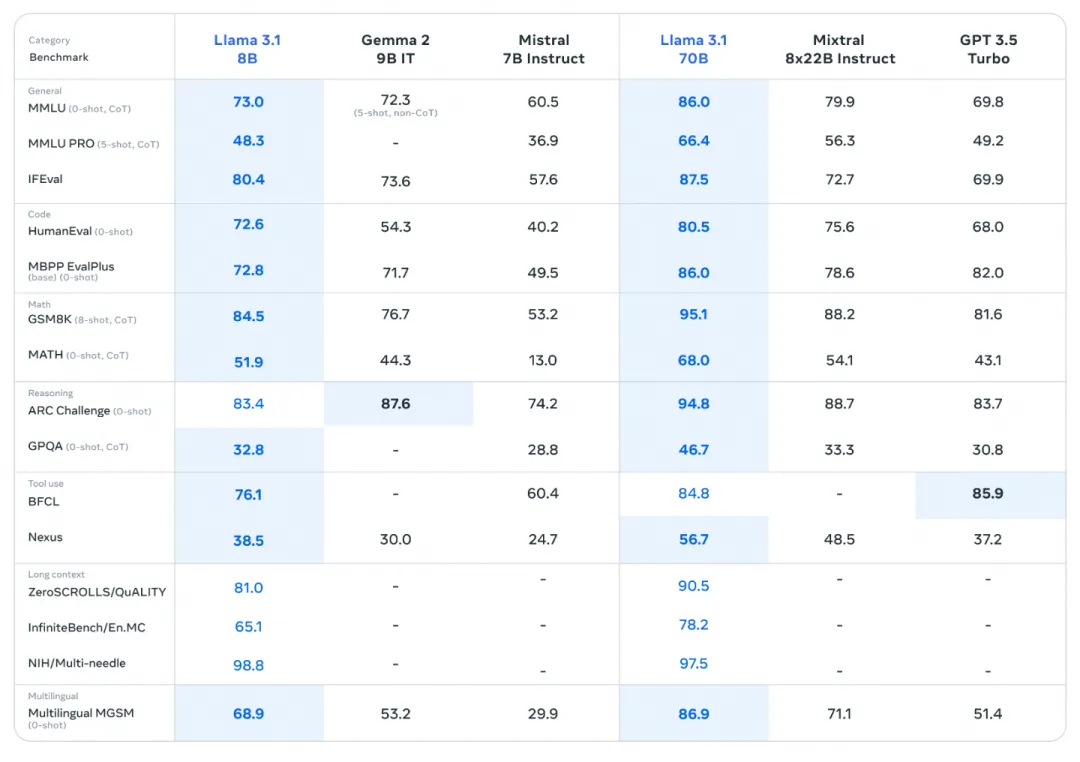
更多技术细节和评测报告关注官方技术报告:
https://ai.meta.com/blog/meta-llama-3-1/
以下是魔搭社区为大家带来的一站式模型体验、下载、推理、微调、部署实战教程!
模型链接
Llama-3.1-8B
https://www.modelscope.cn/models/LLM-Research/Meta-Llama-3.1-8B
Llama-3.1-8B-Instruct
https://www.modelscope.cn/models/LLM-Research/Meta-Llama-3.1-8B-Instruct
Llama-3.1-8B-Instruct-GGUF
https://www.modelscope.cn/models/LLM-Research/Meta-Llama-3.1-8B-Instruct-GGUF
Llama-3.1-70B
https://www.modelscope.cn/models/LLM-Research/Meta-Llama-3.1-70B
Llama-3.1-70B-Instruct
https://www.modelscope.cn/models/LLM-Research/Meta-Llama-3.1-70B-Instruct
Llama-3.1-70B-Instruct-AWQ-INT4
https://www.modelscope.cn/models/LLM-Research/Meta-Llama-3.1-70B-Instruct-AWQ-INT4
Llama-3.1-405B-Instruct-FP8
https://www.modelscope.cn/models/LLM-Research/Meta-Llama-3.1-405B-Instruct-FP8
模型体验
llama3.1 405B体验直达:
https://www.modelscope.cn/studios/LLM-Research/Meta-Llama-3.1-405B-Instruct-FP8-demo
模型推理
以Llama-3.1-8B-Instruct为例:
import transformers
import torch
from modelscope import snapshot_download
model_id = snapshot_download("LLM-Research/Meta-Llama-3.1-8B-Instruct")
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
模型微调
我们介绍使用ms-swift对llama3_1-8b-instruct进行古文翻译腔微调,并对微调前后模型进行推理。swift是魔搭社区官方提供的LLM工具箱,支持300+大语言模型和50+多模态大模型的微调、推理、量化、评估和部署。
swift开源地址:
https://github.com/modelscope/swift
古文翻译腔数据集:
https://modelscope.cn/datasets/swift/classical_chinese_translate
如果需要使用其他数据集进行微调,只需要修改 --dataset即可。自定义dataset支持传入本地路径、modelscope和huggingface中的dataset_id。文档可以查看:https://swift.readthedocs.io/zh-cn/latest/LLM/%E8%87%AA%E5%AE%9A%E4%B9%89%E4%B8%8E%E6%8B%93%E5%B1%95.html
在开始微调之前,请确保您的环境已正确安装
# 安装ms-swift
git clone https://github.com/modelscope/swift.git
cd swift
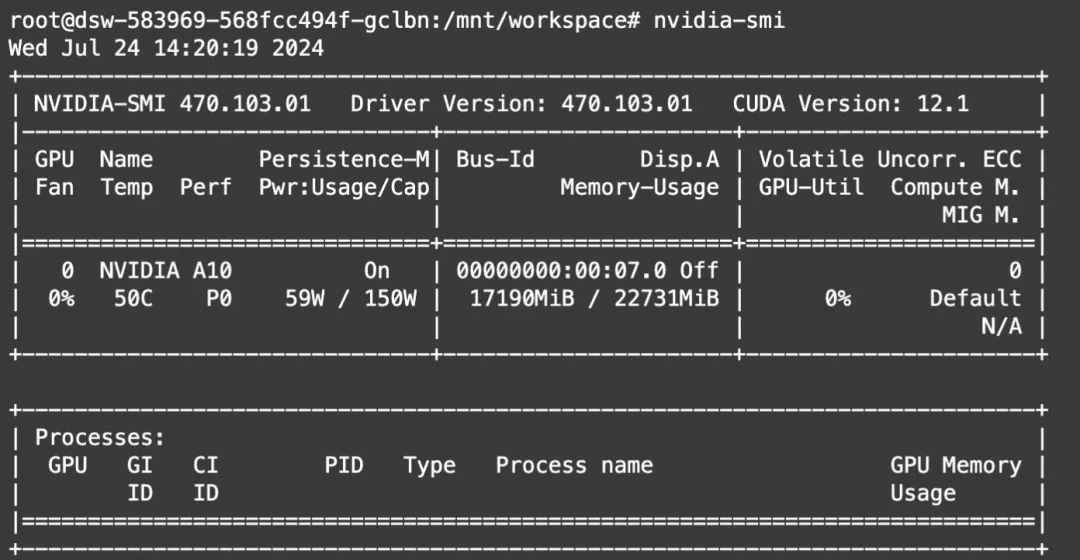
pip install -e .[llm]微调脚本:(如果出现OOM,请降低max_length)
# 实验环境: 3090/A10
# 显存占用: 24GB
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model_type llama3_1-8b-instruct \
--sft_type lora \
--output_dir output \
--dataset classical-chinese-translate \
--num_train_epochs 1 \
--max_length 2048 \
--gradient_checkpointing true \
--batch_size 1 \
--gradient_accumulation_steps 16 \
--warmup_ratio 0.1 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit -1 \
--logging_steps 10
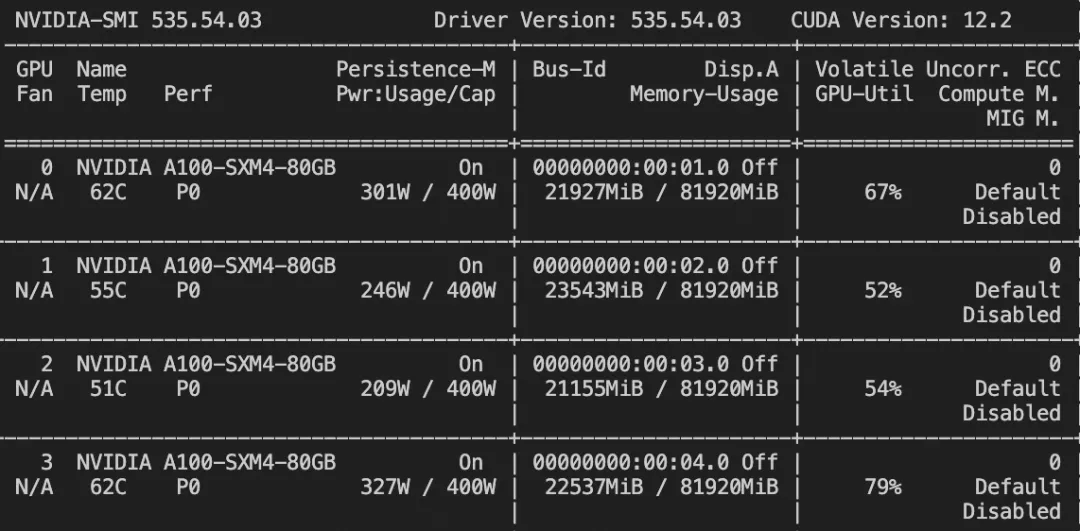
# 实验环境: 4 * 3090/A10
# 显存占用: 4 * 24GB
# DDP + ZeRO2
nproc_per_node=4
NPROC_PER_NODE=$nproc_per_node \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model_type llama3_1-8b-instruct \
--sft_type lora \
--output_dir output \
--dataset classical-chinese-translate \
--num_train_epochs 1 \
--max_length 2048 \
--gradient_checkpointing true \
--batch_size 1 \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--warmup_ratio 0.1 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit -1 \
--logging_steps 10 \
--deepspeed default-zero2微调显存消耗:

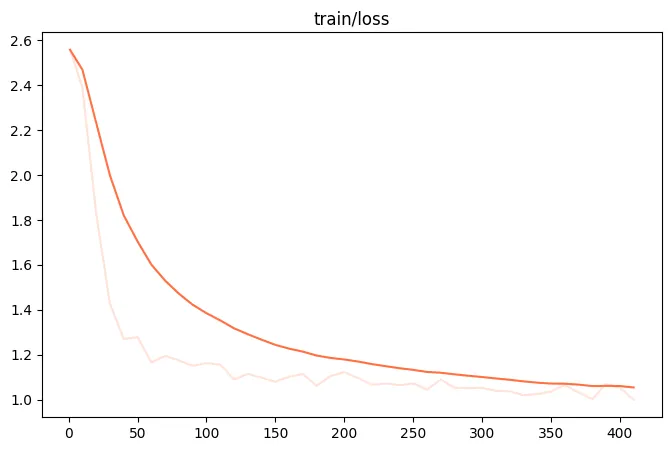
微调过程的loss可视化:

微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的last checkpoint文件夹。我们可以使用vLLM对merge后的checkpoint进行推理加速。
pip install vllm -U # vllm>=0.5.3.post1
# Experimental environment: A10, 3090, V100, ...
CUDA_VISIBLE_DEVICES=0 swift export \
--ckpt_dir output/llama3_1-8b-instruct/vx-xxx/checkpoint-xxx \
--merge_lora true
# 使用vLLM进行推理加速
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/llama3_1-8b-instruct/vx-xxx/checkpoint-xxx-merged \
--infer_backend vllm --max_model_len 4096微调后模型对验证集进行推理的示例:


模型部署
使用vLLM部署Llama3.1-70B-Instruct
部署Llama3.1-70B-Instruct需要至少2卡80GiB A100 GPU,部署方式如下:
服务端:
# 请确保已经安装了git-lfs
git lfs install
GIT_LFS_SKIP_SMUDGE=1 git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3.1-70B-Instruct.git
cd Meta-Llama-3.1-70B-Instruct
git lfs pull
# 实验环境:2 * A100
# <local_path>传入本地路径
CUDA_VISIBLE_DEVICES=0,1 vllm serve <local_path> \
--dtype bfloat16 --served-model-name llama3_1-70b-instruct \
--gpu_memory_utilization 0.96 --tensor_parallel_size 2 \
--max_model_len 50000
# or 实验环境:4 * A100
CUDA_VISIBLE_DEVICES=0,1,2,3 vllm serve <local_path> \
--dtype bfloat16 --served-model-name llama3_1-70b-instruct \
--tensor_parallel_size 4客户端:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "llama3_1-70b-instruct",
"messages": [{"role": "user", "content": "晚上睡不着觉怎么办?"}],
"max_tokens": 1024,
"temperature": 0
}'模型输出:
{"id":"chat-d1b12066eedf445bbee4257a8c3a1b30","object":"chat.completion","created":1721809149,"model":"llama3_1-70b-instruct","choices":[{"index":0,"message":{"role":"assistant","content":"答:如果你晚上睡不着觉,可以尝试以下方法:1. 保持卧室安静、黑暗和凉爽。2. 避免在睡前使用电子设备。3. 不要在睡前饮用含有咖啡因的饮料。4. 尝试放松技巧,如深呼吸、冥想或瑜伽。5. 如果问题持续,可以咨询医生或睡眠专家。","tool_calls":[]},"logprobs":null,"finish_reason":"stop","stop_reason":null}],"usage":{"prompt_tokens":19,"total_tokens":128,"completion_tokens":109}}GGUF格式在ollama上使用
Ollama 是一款极其简单的基于命令行的工具,用于运行 LLM。它非常容易上手,可用于构建 AI 应用程序。
模型下载
使用ModelScope命令行工具下载单个模型
modelscope download --model=LLM-Research/Meta-Llama-3.1-8B-Instruct-GGUF --local_dir . Meta-Llama-3.1-8B-Instruct-Q5_K_M.ggufLinux环境使用
Liunx用户可使用魔搭镜像环境安装【推荐】
# 使用命令行前,需要通过pip install modelscope 安装。
modelscope download --model=modelscope/ollama-linux --local_dir ./ollama-linux
# 运行ollama安装脚本
cd ollama-linux
sudo chmod 777 ./ollama-modelscope-install.sh
./ollama-modelscope-install.sh创建ModelFile
复制模型路径,创建名为“ModelFile”的meta文件,内容如下
FROM /mnt/workspace/Meta-Llama-3.1-8B-Instruct-Q5_K_M.gguf
PARAMETER stop "<|start_header_id|>"
PARAMETER stop "<|end_header_id|>"
PARAMETER stop "<|eot_id|>"
TEMPLATE """{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"""启动Ollama服务
ollama serve创建自定义模型
使用ollama create命令创建自定义模型
ollama create my-llama-3.1 --file ./ModelFile运行模型:
ollama run my-llama-3.1测试自定义模型,使用终端与您的自定义模型聊天,以确保其行为符合预期。验证它是否根据自定义的系统提示和模板做出响应。
>>> hello
Hello! How are you today? Is there something I can help you with or would you like to chat?
>>> who is your creator
I was created by Meta AI, a subsidiary of Meta Platforms, Inc. (previously known as Facebook, Inc.). My specific architecture and training data were developed by a team of researchers and engineers at Meta AI.
My primary function is to assist and communicate with humans through text-based conversations. I'm based on a type of artificial intelligence called a transformer
model, which allows me to process and respond to natural language inputs in a highly efficient and effective way.
If you'd like to know more about my capabilities or the technology behind me, feel free to ask!中文效果还不错
>>> 你好,你能说中文吗
我可以理解一些中文,但我的能力有限。虽然我被训练以处理大量语言,包括中文,但我的响应可能不如母语人士那么准确或流畅。
如果您愿意用中文与我交流,我将尽量努力理解和回复。但请注意,我的中文理解可能会受到以下限制:
1. 语法和词汇:虽然我对一些常见的中文语法和词汇有所了解,但我的知识可能不够深入或准确。
2. 文化背景:作为一个外国机器人,我可能缺乏充分的文化背景知识,导致我无法理解某些中国人的习俗、幽默或其他社会规范。
然而,如果您愿意尝试用中文与我交流,我仍然会尽力帮助您。>>> 写一篇介绍杭州的文章
**杭城之美——探索温暖的西湖背后**
杭州,是中国浙江省的一座城市,也是该省的省会。杭州以其自然风光、历史文化和现代生活方式而闻名于世,成为中国最受欢迎的旅游目的地之一。
**西湖——杭城的明珠**
西湖是杭州最著名的地标之一,是一座面积约为6.4平方公里的大型淡水湖泊。湖面上泛着光波,湖边的树木绿荫浓郁,水面上的荷花红艳欲滴。在西湖的尽头,有著历史悠久的岳王亭和天目山。每年春夏之交,西湖就会被一层薄薄的雾气所笼罩,这让人感到神秘而迷离。
**杭州古城**
杭州古城依山傍水,建有数千年的历史,是中国最美丽的城市之一。古城内的街道狭窄曲折,每条小巷都有着自己的故事和传说。在古城内,有著著名的西湖文化艺术馆、浙江省博物馆等文化旅游景点。
**杭州当代生活**
除了自然风光和历史文化之外,杭州也是一座现代化的城市。市区内布满了高楼大厦,繁华商业街每天都有成千上万的人潮涌动。在杭州,还有一座著名的滨江新城,这里汇聚着最前沿的国际建筑设计和先进的生活方式。
**结语**
杭州,是一座充满了自然美景、历史文化遗产和现代生活方式的城市。它是中国最受欢迎的旅游目的地之一,吸引着来自世界各地的人潮涌来。无论你是出于游览、探索还是工作的目的,都会发现杭州是一个充满了温暖与活力的城市。Llama3.1 工具调用服务实战
环境准备
Llama3.1部署依赖vllm 最新补丁版本 0.5.3.post1
# speed up if needed
# pip config set global.index-url https://mirrors.cloud.aliyuncs.com/pypi/simple
# pip config set install.trusted-host mirrors.cloud.aliyuncs.com
pip install https://github.com/vllm-project/vllm/releases/download/v0.5.3.post1/vllm-0.5.3.post1+cu118-cp310-cp310-manylinux1_x86_64.whl依赖modelscope-agent项目下的modelscope-agent-server进行tool calling能力调用
git clone https://github.com/modelscope/modelscope-agent.git
cd modelscope-agent模型准备
模型链接:
meta-llama/Meta-Llama-3.1-8B-Instruct:
https://modelscope.cn/models/LLM-Research/Meta-Llama-3.1-8B-Instruct
模型下载:
from modelscope import snapshot_download
model = snapshot_download("LLM-Research/Meta-Llama-3.1-8B-Instruct")打印 model获得model本地地址/path/to/weights
服务调用
利用modelscope-agent-server的能力,允许用户在本地拉起一个支持openai SDK调用的chat/completions服务,并且赋予该模型tool calling 的能力。这样子可以让原本仅支持prompt调用的模型,可以通过modelscope的服务快速进行tool calling的调用。
服务拉起
具体使用方式参考vllm即可,原本用vllm拉起meta-llama/Meta-Llama-3.1-8B-Instruct 模型的命令如下:
python -m vllm.entrypoints.openai.api_server --served-model-name meta-llama/Meta-Llama-3.1-8B-Instruct --model path/to/weights现在,在modelscope-agent项目目录底下输入以下命令即可拉起由modelscope-agent内核支持的tool calling服务:
sh scripts/run_assistant_server.sh --served-model-name meta-llama/Meta-Llama-3.1-8B-Instruct --model path/to/weights相关服务会在默认的31512端口上启动,可以通过http://localhost:31512进行访问。
服务curl调用
于此同时, 服务启动以后,可以通过以下方式curl 使用带有tool的信息调用服务。
curl -X POST 'http://localhost:31512/v1/chat/completions' \
-H 'Content-Type: application/json' \
-d '{
"tools": [{
"type": "function",
"function": {
"name": "amap_weather",
"description": "amap weather tool",
"parameters": [{
"name": "location",
"type": "string",
"description": "城市/区具体名称,如`北京市海淀区`请描述为`海淀区`",
"required": true
}]
}
}],
"tool_choice": "auto",
"model": "meta-llama/Meta-Llama-3.1-8B-Instruct",
"messages": [
{"content": "海淀区天气", "role": "user"}
]
}'返回如下结果:
{
"request_id": "chatcmpl_84a66af2-4021-4ae6-822d-8e3f42ca9f43",
"message": "",
"output": null,
"id": "chatcmpl_84a66af2-4021-4ae6-822d-8e3f42ca9f43",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "工具调用\nAction: amap_weather\nAction Input: {\"location\": \"北京市\"}\n",
"tool_calls": [
{
"type": "function",
"function": {
"name": "amap_weather",
"arguments": "{\"location\": \"北京市\"}"
}
}
]
},
"finish_reason": "tool_calls"
}
],
"created": 1721803228,
"model": "meta-llama/Meta-Llama-3.1-8B-Instruct",
"system_fingerprint": "chatcmpl_84a66af2-4021-4ae6-822d-8e3f42ca9f43",
"object": "chat.completion",
"usage": {
"prompt_tokens": -1,
"completion_tokens": -1,
"total_tokens": -1
}
}可以看到通过modelscope-agent-server, 用户可以快速将原本无法使用tool calling的chat模型,快速开始进行调用,从而进行后续工作。
openai SDK调用
另外,用户也可以使用openai SDK进行调用,具体使用方式如下:
from openai import OpenAI
api_base = "http://localhost:31512/v1/"
model = 'meta-llama/Meta-Llama-3.1-8B-Instruct'
tools = [{
"type": "function",
"function": {
"name": "amap_weather",
"description": "amap weather tool",
"parameters": [{
"name": "location",
"type": "string",
"description": "城市/区具体名称,如`北京市海淀区`请描述为`海淀区`",
"required": True
}]
}
}]
tool_choice = 'auto'
client = OpenAI(
base_url=api_base,
api_key="empty",
)
chat_completion = client.chat.completions.create(
messages=[{
"role": "user",
"content": "海淀区天气是什么?"
}],
model=model,
tools=tools,
tool_choice=tool_choice
)70B模型Tool calling调用
对于70B的模型调用依赖4张A100的卡能够跑到llama3.1的max_model_len(131072),或者选择2张卡,可以限制模型的max_model_len=8192 具体示例如下:
export CUDA_VISIBLE_DEVICES=0,1,2,3;sh scripts/run_assistant_server.sh --served-model-name meta-llama/Meta-Llama-3.1-70B-Instruct --model '/path/to/weights' --tensor-parallel-size 4或者双卡 并限制max_model_len
export CUDA_VISIBLE_DEVICES=0,1;sh scripts/run_assistant_server.sh --served-model-name meta-llama/Meta-Llama-3.1-70B-Instruct --model '/path/to/weights' --tensor-parallel-size 2 --max_model_len 8192







 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)