

导读
Google面向全球研究人员和开发者发布并开源 Gemma 2 大语言模型!本次Gemma 2 系列为轻量级开放模型,提供9B和27B参数两种尺寸,采用全新的架构设计,性能表现优异。
官方技术报告总结,Gemma 2是一种新的开放模型标准,旨在实现效率和性能的最优化:
-
27B版本性能在基准测试中超越了比其规模大两倍的模型,这一突破性的效率为开放模型领域树立了新标准;
-
27B模型可用在单个Google Cloud TPU主机、NVIDIA A100 80GB GPU 或NVIDIA H100 GPU上全精度高效运行推理,大幅降低成本的同时保持高性能,让模型部署更普及、实惠;
-
Gemma 2经过优化,可在各种硬件上以惊人的速度运行,从功能强大的游戏笔记本电脑和高端台式机,到基于云的设置。
技术报告:
https://blog.google/technology/developers/google-gemma-2
Benchmark
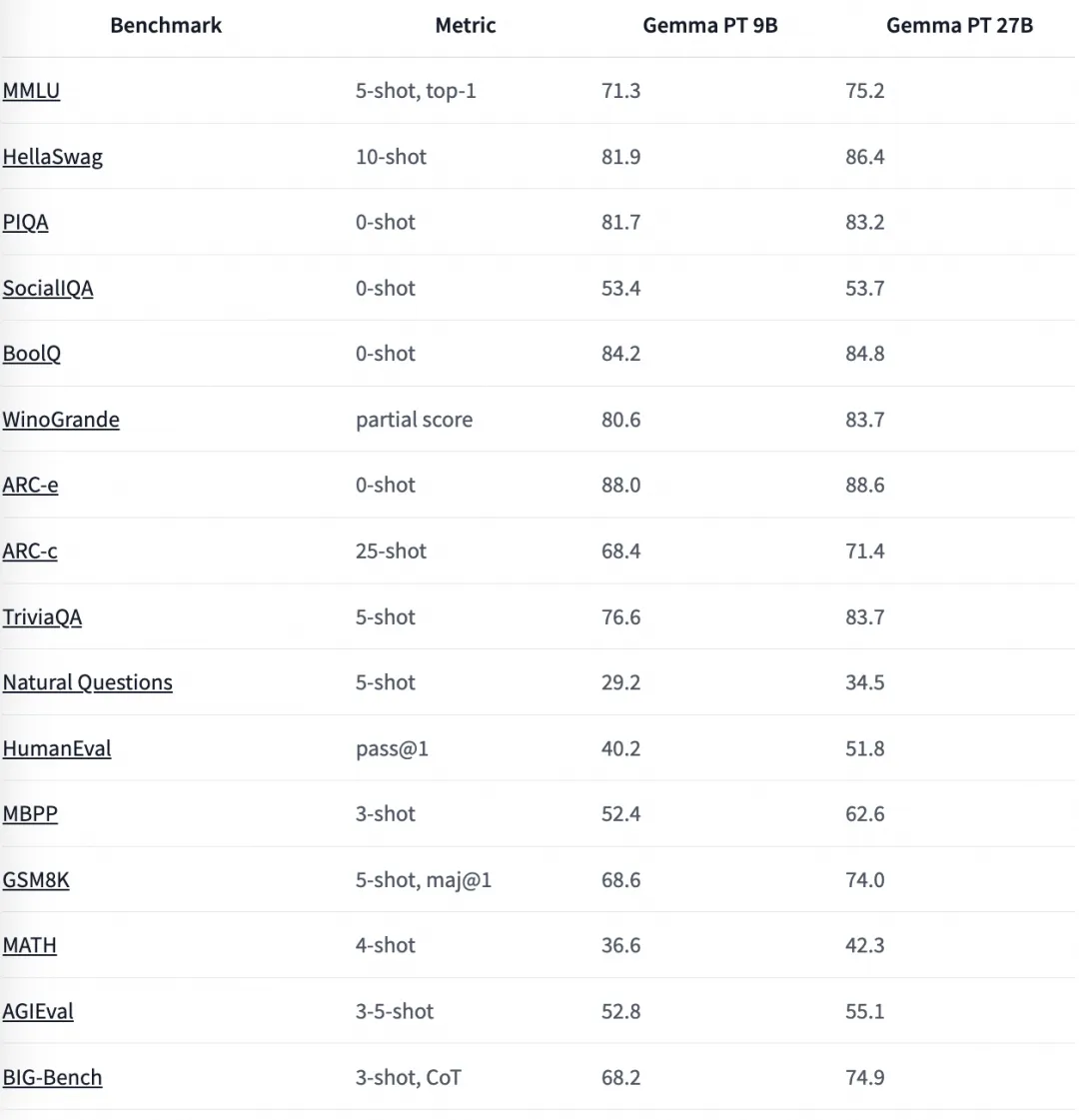
以下为大家带来新鲜的Gemma 2 魔搭社区推理、微调最佳实践教程。
环境配置与安装
本文使用的模型为模型,可在ModelScope的Notebook的环境的配置下运行(显存24G) 。
环境配置与安装
本文主要演示的模型推理代码可在魔搭社区免费实例PAI-DSW的配置下运行(显存24G) :
点击模型右侧Notebook快速开发按钮,选择GPU环境
打开Notebook环境:
模型链接和下载
HF格式模型链接:
https://modelscope.cn/models/LLM-Research/gemma-2-9b-it
社区支持直接下载模型的repo:
from modelscope import snapshot_download
model_dir = snapshot_download("LLM-Research/gemma-2-9b-it")或者使用CLI下载
modelscope download --model=LLM-Research/gemma-2-9b-it --local_dir .GGUF格式模型链接:
https://modelscope.cn/models/LLM-Research/gemma-2-9b-it-GGUF
GGUF模型下载:
modelscope download --model=LLM-Research/gemma-2-9b-it-GGUF --local_dir . gemma-2-9b-it-Q5_K_L.ggufGemma2模型推理
升级transformers
!pip install "transformers==4.42.1" --upgrade模型推理
# pip install accelerate
from modelscope import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("LLM-Research/gemma-2-9b-it")
model = AutoModelForCausalLM.from_pretrained(
"LLM-Research/gemma-2-9b-it",
device_map="auto",
torch_dtype=torch.bfloat16
)
input_text = "Write me a poem about Machine Learning."
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
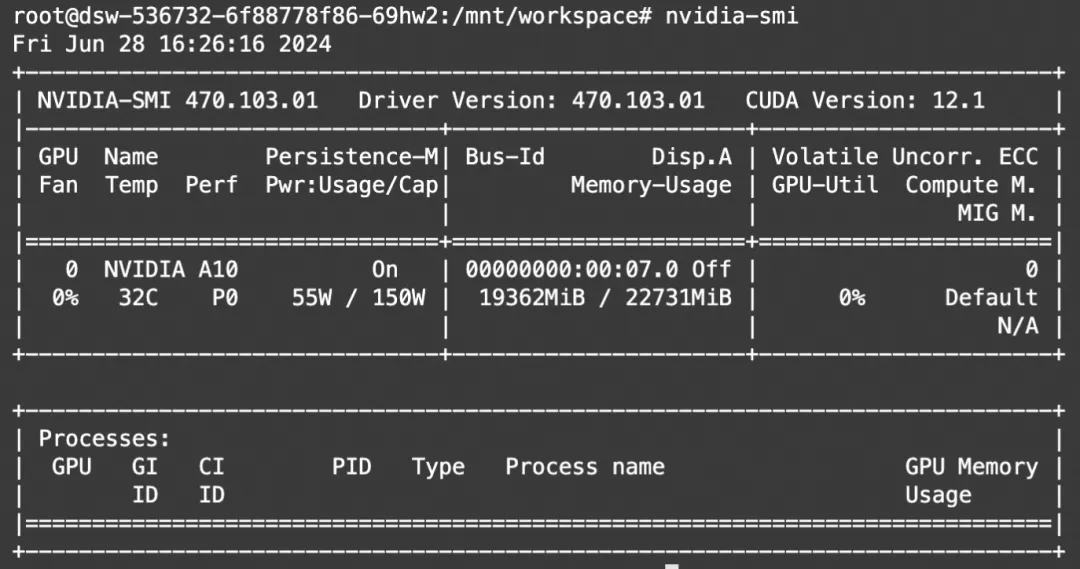
print(tokenizer.decode(outputs[0]))显存占用:
使用Ollama推理
Ollama 是一款极其简单的基于命令行的工具,用于运行 LLM。它非常容易上手,可用于构建 AI 应用程序。
Linux环境使用
Liunx用户可使用魔搭镜像环境安装【推荐】
git clone https://www.modelscope.cn/modelscope/ollama-linux.git
cd ollama-linux
sudo chmod 777 ./ollama-modelscope-install.sh
./ollama-modelscope-install.sh启动Ollama服务
ollama serve创建ModelFile
复制模型路径,创建名为“ModelFile”的meta文件,内容如下:
FROM /mnt/workspace/gemma-2-9b-it-Q5_K_L.gguf
PARAMETER stop "<start_of_turn>"
PARAMETER stop "<end_of_turn>"
TEMPLATE """<start_of_turn>user
{{ if .System }}{{ .System }} {{ end }}{{ .Prompt }}<end_of_turn>
<start_of_turn>model
{{ .Response }} <end_of_turn>"""
# set the system message
SYSTEM """
You are a helpful assistant.
"""创建自定义模型
使用ollama create命令创建自定义模型
ollama create mygemma2 --file ./ModelFile运行模型:
ollama run mygemma2Gemma2中文增强&自我认知微调
我们介绍使用ms-swift对gemma2-9b-it进行中文增强&自我认知微调,并对微调前后模型进行推理与评测效果展示。ms-swift是魔搭社区官方提供的LLM工具箱,支持250+大语言模型和35+多模态大模型的微调、推理、量化、评估和部署,包括:Qwen、Llama、GLM、Internlm、Yi、Baichuan、DeepSeek、Llava等系列模型。代码开源地址:https://github.com/modelscope/swift
ms-swift已接入gemma2系列模型,包括:gemma2-9b, gemma2-9b-it, gemma2-27b, gemma2-27b-it。这里,我们对gemma2-9b-it使用经清洗的中英文SFT通用、代码和数学数据集进行中文增强,并使用自我认知数据集修改模型对自己和作者的认知。
我们使用的数据集链接如下:
SFT数据集:
https://modelscope.cn/datasets/swift/swift-sft-mixture
自我认知数据集:
https://modelscope.cn/datasets/swift/self-cognition
环境准备:
# 设置pip全局镜像 (加速下载)
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 安装ms-swift
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e '.[llm]'
# 安装评测相关依赖
pip install -e '.[eval]'
# gemma2依赖
pip install transformers>=4.42
# 如果要使用vllm对gemma2进行推理加速, 需要使用源代码方式进行安装
git clone https://github.com/vllm-project/vllm.git
cd vllm
pip install -e .原始模型的推理:
# Experimental environment: A100
# 如果是本地模型, 需指定`--model_type gemma2-9b-instruct --model_id_or_path <local_path>`
# 如果使用原生pytorch进行推理, 请设置`--infer_backend pt`
CUDA_VISIBLE_DEVICES=0 swift infer \
--model_id_or_path LLM-Research/gemma-2-9b-it \
--infer_backend vllm原始模型的评测与结果:
# Experimental environment: A100
# 评测后端由llmuses库提供: https://github.com/modelscope/eval-scope
# 推荐使用vllm进行推理加速. 如果使用原生pytorch进行推理, 请设置`--infer_backend pt`
CUDA_VISIBLE_DEVICES=0 swift eval \
--model_id_or_path LLM-Research/gemma-2-9b-it \
--eval_dataset arc ceval gsm8k mmlu --eval_backend Native \
--infer_backend vllm|
Model |
arc |
ceval |
gsm8k |
|
llama3-8b-instruct |
0.7628 |
0.5111 |
0.7475 |
|
gemma2-9b-instruct |
0.8797 |
0.5275 |
0.8143 |
gemma2-7b-it的中文增强微调:
这里为了降低训练的时间,对数据集进行了较少的采样。如果要想进行更多数据集的微调,可以适当增大混合的比例,例如:`--dataset swift-mix:sharegpt#50000 swift-mix:firefly#20000 swift-mix:codefuse#20000 swift-mix:metamathqa#20000 self-cognition#1000`。
我们对embedding层、所有的linear层和lm_head层加上lora,并设置layer_norm层可训练。我们在中文增强的同时,修改模型的自我认知,让模型认为自己是小黄,由魔搭创建。
# Experimental environment: 4 * A100
# 4 * 80GB GPU memory
# 如果是本地模型, 需指定`--model_type gemma2-9b-instruct --model_id_or_path <local_path>`
nproc_per_node=4
MASTER_PORT=29500 \
NPROC_PER_NODE=$nproc_per_node \
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model_id_or_path LLM-Research/gemma-2-9b-it \
--dataset swift-mix:sharegpt#10000 swift-mix:firefly#5000 swift-mix#5000 swift-mix:metamathqa#5000 self-cognition#500 \
--lora_target_modules EMBEDDING ALL lm_head \
--lora_modules_to_save LN \
--adam_beta2 0.95 \
--learning_rate 5e-5 \
--num_train_epochs 5 \
--eval_steps 100 \
--max_length 8192 \
--gradient_accumulation_steps $(expr 64 / $nproc_per_node) \
--model_name 小黄 'Xiao Huang' \
--model_author 魔搭 ModelScope \
--save_total_limit -1 \
--logging_steps 5 \
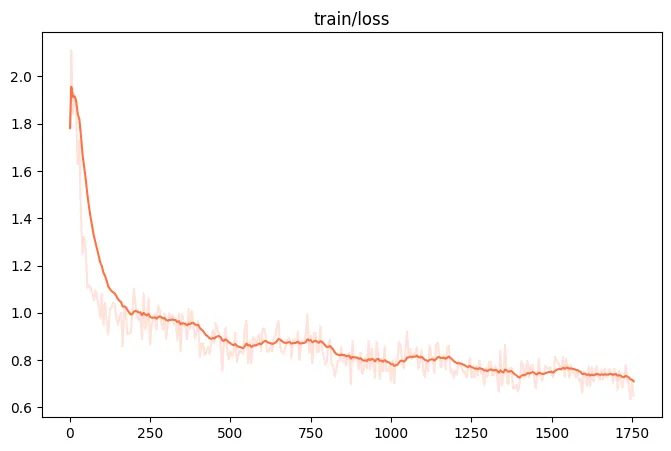
--use_flash_attn true \训练损失可视化:
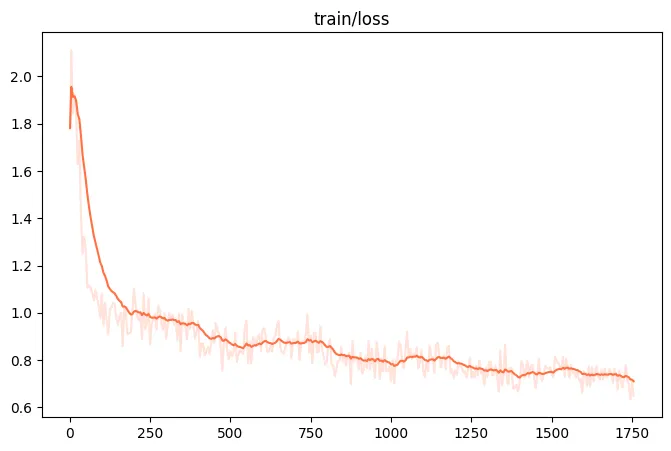
资源占用:
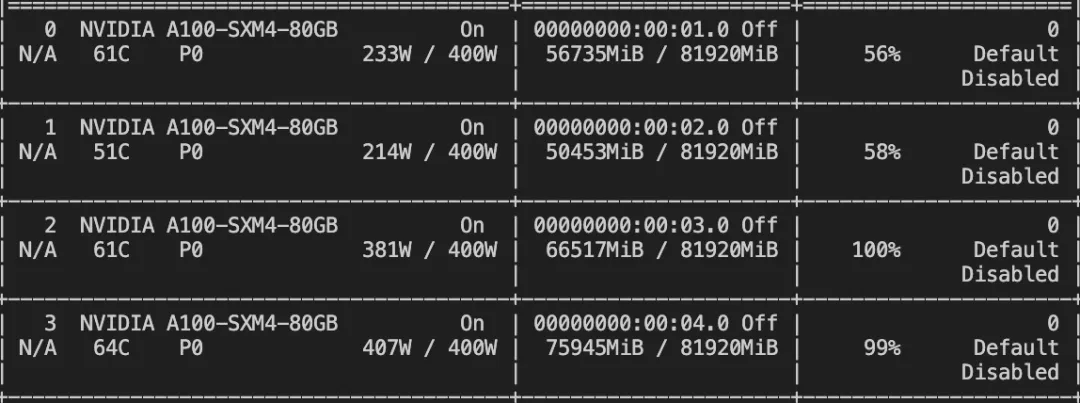
微调后模型的推理:
# Experimental environment: A100
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/gemma2-9b-instruct/vx-xxx/checkpoint-xxx \
--infer_backend vllm --merge_lora true微调后模型的评测与结果:
# Experimental environment: A100
# 评测后端由llmuses库提供: https://github.com/modelscope/eval-scope
CUDA_VISIBLE_DEVICES=0 swift eval \
--ckpt_dir output/gemma2-9b-instruct/vx-xxx/checkpoint-xxx \
--eval_dataset arc ceval gsm8k mmlu --eval_backend Native \
--infer_backend vllm --merge_lora true微调得到的模型将在之后上传modelscope
|
Model |
arc |
ceval |
gsm8k |
|
原始模型 |
0.8797 |
0.5275 |
0.8143 |
|
微调后模型 |
0.872 |
0.5498 |
0.8021 |
点击链接👇直达原文
https://modelscope.cn/models/LLM-Research/gemma-2-9b-it?from=csdnzishequ_text







 已为社区贡献651条内容
已为社区贡献651条内容

所有评论(0)