

背景
Modelscope-Agent(https://github.com/modelscope/modelscope-agent)是魔搭GPTs 开源的实现方案的底层框架,基于chatbot允许用户通过聊天、直接配置的方式进行agent的定制生成,可以允许用户使用自定义知识库以及接入多工具的能力。于此同时,Modelscope-Agent当前支持的知识库功能存在:可读文件类型有限、效果不稳定、召回策略固定、对大文件和多文件的支持较弱等问题。
为增强Modelscope-Agent的知识库能力,我们兼容适配了常用的RAG开源方案来增强这方面能力,目前主要功能以llama-index为主。llama-index 是一个简单、灵活的RAG数据框架,用于将自定义数据源连接到大型语言模型 (LLM)。同时llama-index提供插件市场,支持社区开发者贡献不同类型文件reader、不同召回策略、chunk方法等。结合社区能力,可很好地对modelscope_agent的知识库能力做补充。
简介
本系列文章,集中探索了利用开源的技术方案让Modelscope-Agent在不同的RAG场景中具备更强的方案解决能力,更灵活的配置能力,以及在一些核心场景中的更高的准确率和性能效果。
本文重点介绍通过引入llama-index后,Modelscope-Agent在多策略和多模态召回两个场景上的应用案例,后续还有更多其他能力的介绍。
架构方案
在整体RAG能力提升的设计方案提出之初,希望开源方案,如llama-index的引入不对原有的知识库召回链路使用体验造成影响。因此,知识库的RAG处理沿用之前的方案,分为2个阶段:
-
对知识库内容构建索引, 即初始化阶段,相关的文档信息传入,索引构建在这一步发生
-
根据query召回知识库对应的内容并生成返回,即runtime 召回阶段,根据query召回相关信息。
在原有方案中,memory承载了所有长短期记忆包括外挂知识库RAG的操作,这样设计的目的是,映射人类学习新东西到记忆中,并且凭借记忆去寻找新学习到的技能的具体方法。
具体使用如下所示:
from modelscope_agent.memory import MemoryWithRag
memory = MemoryWithRag(urls=['tests/samples/常见QA.pdf'])
print(memory.run(query='高德天气api怎么申请'))在Modelscope-Agent中支持RAG链路的的架构如下图所示,其中知识库内容的索引构建沿着浅绿色箭头所示,根据query召回知识库对应内容如深绿色箭头所示。
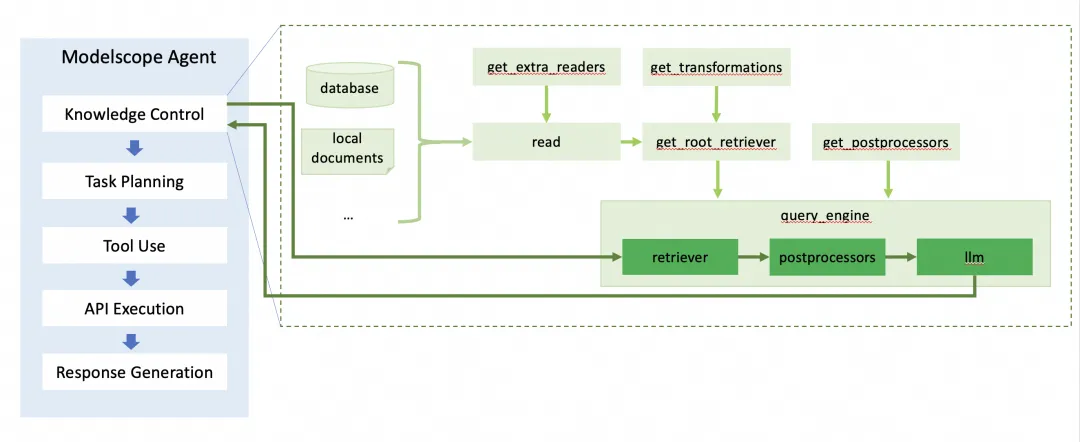
在一个实际的agent使用场景下,RAG链路在Modelscope-Agent的应用如下所示。
from modelscope_agent.memory import MemoryWithRag
from modelscope_agent.agents import RolePlay
# 初始化个性化agent
role_template = '知识库查询小助手,可以优先通过查询本地知识库来回答用户的问题'
llm_config = {'model': 'qwen-max', 'model_server': 'dashscope'}
function_list = []
bot = RolePlay(function_list=function_list,llm=llm_config, instruction=role_template)
# 初始化memory
memory = MemoryWithRag(urls=['./tests/samples/常见QA.pdf'], use_knowledge_cache=False)
query = "高德天气API在哪申请"
use_llm = True if len(function_list) else False # 如果agent需要调用工具,则让memory提前总结一次,获得更好的工具调用效果。
ref_doc = memory.run(query, use_llm=use_llm)
response = bot.run(query, remote=False, print_info=True, ref_doc=ref_doc)
text = ''
for chunk in response:
text += chunk
print(text)按照上述流程,内部各模块都支持可灵活配置。接下来将依次介绍各个模块的使用细节。
文件读取
文件读取(read)模块会从不同来源、不同类型文档中读取信息。read中默认提供如下类型文件的读取:`.hwp`, `.pdf`, `.docx`, `.pptx`, `.ppt`, `.pptm`, `.jpg`, `.png`, `.jpeg`, `.mp3`, `.mp4`, `.csv`, `.epub`, `.md`, `.mbox`, `.ipynb`, `txt`, `.pd`, `.html`。其他类型的文件未配置默认reader,可在插件市场选取更多类型文件reader、或自定义reader传入使用。未配置reader的其他类型文件传入时将被忽略。
from modelscope_agent.memory import MemoryWithRag
from llama_index.readers.json import JSONReader
memory = MemoryWithRag(urls=['/home/test.json'], loaders={'.json': JSONReader})构建索引
构建索引(indexing)包括对文档切片、将每个文档片段向量化(如有)等。由于索引构建方式与召回方式强相关,因此这部分内容与retriever的初始化(get_root_retriever)在一个函数内实现。其中,大文档chunk策略默认使用按语义切片(sentence_spliter)、默认使用向量召回、默认的embedding模型为dashscope提供的text-embedding-v2。
如果您想使用其他chunk方式或emb模型,可以通过transformations和emb参数传入。其中,transformations参数允许接收的类包括:TextSplitter、NodeParser、MetadataExtractor,详情可参考llama-index相关文档;emb模型可在插件市场选用
from modelscope_agent.memory import MemoryWithRag
from llama_index.core.extractors import TitleExtractor
from llama_index.embeddings.openai import OpenAIEmbedding
# transformations参数以TitleExtractor为例
# emb模型切换以OpenAIEmbedding为例。注意,使用该emb模型时,需要在可访问openai接口的环境中(在环境变量中配置openai的api-key,且需要在能够访问openai的网络环境中)
memory = MemoryWithRag(transformations=[TitleExtractor],emb=OpenAIEmbedding)缓存加载
缓存(storing)将indexing后的信息保存成文件,以便后续再次使用时无需重新indexing,同时也方便将indexing文件移动切换到其他环境使用。默认存储路径在./run下。可以通过storage_path配置。同时通过use_knowledge_cache控制初始化时是否使用cache。
from modelscope_agent.memory import MemoryWithRag
# 将2个文件indexing后存储到./tmp/目录
MemoryWithRag(
urls=['tests/samples/modelscope_qa_2.txt', 'tests/samples/常见QA.pdf'],
storage_path='./tmp/',
use_knowledge_cache=False,
)
# 从./tmp/目录加载
memory = MemoryWithRag(
storage_path='./tmp/',
use_knowledge_cache=True,
)查询
查询(querying):根据query内容从候选的indexed数据中进行召回,用召回的chunks访问llm,得到整合总结后的结果返回给用户。使用上可以在初始化时将文档链接通过urls传入。
from modelscope_agent.memory import MemoryWithRag
memory = MemoryWithRag(urls=['tests/samples/常见QA.pdf', 'tests/samples/modelscope_qa_2.txt'])
print(memory.run(query='高德天气api怎么申请'))在运行过程中,可以指定本次访问使用的文档范围。如果某个文档在初始化时未被传入,在run的过程中也会先对该文档进行加载、索引、存储。
from modelscope_agent.memory import MemoryWithRag
memory = MemoryWithRag()
print(memory.run(query='模型大文件上传失败怎么办', url=['tests/samples/modelscope_qa_2.txt']))querying的流程主要可分为3步:从候选文档中召回相关片段、对召回内容后处理、传入llm进行总结。
召回
根据查询的请求内容,在候选知识库中找到相关性最高的一个或多个。前面介绍index时提到,召回方法默认为向量召回。如果您想使用其他召回方法,可以通过配置retriever参数实现。
from modelscope_agent.memory import MemoryWithRag
from llama_index.retrievers.bm25 import BM25Retriever
memory = MemoryWithRag(retriever=BM25Retriever)后处理
在querying的流程中,支持对召回的知识库片段内容进行自定义后处理。比如召回多条内容时,可按照与query的相关性进行重排;您可以在llama-index的插件市场找到不同的后处理方法。后处理方法可通过post_processors传入;如果该参数不传入,默认不进行后处理。
from modelscope_agent.memory import MemoryWithRag
from llama_index.postprocessor.dashscope_rerank import DashScopeRerank
memory = MemoryWithRag(post_processors=[DashScopeRerank])llm调用
召回的文档片段可能内容很多,其中与query查询相关的内容可能仅有一两句,或者需要总结。因此需要llm对召回后的内容进行有效信息抽取总结。您可以配置不同的llm,这个llm可以是modelscope-agent的模型对象或llm_config配置方法;也可以是llama-index插件市场中的,初始化完成的llm对象。不配置时,默认使用dashscope提供的qwen-max。
from modelscope_agent.memory import MemoryWithRag
llm_config = {'model': 'qwen-max', 'model_server': 'dashscope'}
memory = MemoryWithRag(llm=llm_config)深度使用
在实际应用中,对于同一文档中的不同组成部分(如pdf的标题、文字、与插图)、或不同来源的信息,对召回的需求不一致。如长文本召回需要模糊匹配,而代码片段的召回则需要精准匹配。为了达到更好的召回效果,可以对整个流程进行混合自定义。

多策略
如果单一的召回策略无法满足使用需求,需要定制复杂多策略。可以自定义实现多种召回器混用的召回策略。以下示例实现了一个混用向量召回和最佳匹配的召回器:
from typing import List
from llama_index.core import VectorStoreIndex
from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core.base.base_retriever import BaseRetriever
from llama_index.core.schema import NodeWithScore
from llama_index.core.schema import QueryBundle
from modelscope_agent.memory import MemoryWithRag
class MyRetriever(BaseRetriever):
def __init__(self, index: VectorStoreIndex, **kwargs) -> None:
self._vector_retriever = index.as_retriever()
self._best_match_retriever = BM25Retriever.from_defaults(index)
super().__init__(**kwargs)
def _retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
vector_nodes = self._vector_retriever.retrieve(query_bundle)
bs_nodes = self._best_match_retriever.retrieve(query_bundle)
print(f'向量召回的节点:{vector_nodes}\n')
print(f'bm25召回的节点:{bs_nodes}\n')
vector_ids = {n.node.node_id for n in vector_nodes}
bs_ids = {n.node.node_id for n in bs_nodes}
combined_dict = {n.node.node_id: n for n in vector_nodes}
combined_dict.update({n.node.node_id: n for n in bs_nodes})
retrieve_ids = vector_ids.union(bs_ids)
retrieve_nodes = [combined_dict[rid] for rid in retrieve_ids]
return retrieve_nodes
memory = MemoryWithRag(retriever=MyRetriever, urls=['tests/samples/modelscope_qa_2.txt', 'tests/samples/常见QA.pdf'], use_knowledge_cache=False)
print(memory.run(query='高德天气API怎么申请?'))能看到运行结果中,向量召回的节点有2个,其中第一个节点的文档包含我们想要的内容:“⾼德天⽓ API 请在这⾥申请:https://lbs.amap.com/api/javascript-api-v2/guide/services/weather \n”:
[
NodeWithScore(node=TextNode(id_='2ce30d75-244f-49ac-ad99-2c419f84d6cb', embedding=None, metadata={'page_label': '4', 'file_name': '常见QA.pdf', 'file_path': 'tests/samples/常见QA.pdf', 'file_type': 'application/pdf', 'file_size': 898222, 'creation_date': '2024-06-06', 'last_modified_date': '2024-06-06'}, excluded_embed_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], excluded_llm_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='f9871165-1501-4dd1-a4c8-55f29e71a352', node_type=<ObjectType.DOCUMENT: '4'>, metadata={'page_label': '4', 'file_name': '常见QA.pdf', 'file_path': 'tests/samples/常见QA.pdf', 'file_type': 'application/pdf', 'file_size': 898222, 'creation_date': '2024-06-06', 'last_modified_date': '2024-06-06'}, hash='02ab04742f5c544bb2d390fa529db2d179d8e3f052635fb73047175367e252a3'), <NodeRelationship.PREVIOUS: '2'>: RelatedNodeInfo(node_id='a64fcd33-d497-4165-a9d5-ca6ff166d818', node_type=<ObjectType.TEXT: '1'>, metadata={'page_label': '3', 'file_name': '常见QA.pdf', 'file_path': 'tests/samples/常见QA.pdf', 'file_type': 'application/pdf', 'file_size': 898222, 'creation_date': '2024-06-06', 'last_modified_date': '2024-06-06'}, hash='ea966d431e644b64f3baddc19af26273c8936aa177bb4328e84861ca0889e6a9'), <NodeRelationship.NEXT: '3'>: RelatedNodeInfo(node_id='33f28073-49e1-4ff2-874f-4b5b803a6330', node_type=<ObjectType.TEXT: '1'>, metadata={}, hash='89a1d1e1805f714f0577089ddd4eb1b932977b9d29fc92271e96e848363218f1')}, text='4 / 5对应的 KEY 申请链接:千问、万相、艺术字的 API 统⼀在这⾥申请:\nhttps://help.aliyun.com/zh/dashscope/developer-reference/activate-dashscope-and-create-an-api-\nkey。\n⾼德天⽓ API 请在这⾥申请:https://lbs.amap.com/api/javascript-api-v2/guide/services/weather \n7.如何贡献tool ?\n可以将 API 注册为 Tool ,成为 smart API ,⽅便社区其他⽤户使⽤。具体注册流程请⻅Agent实操\n(三):将 API 注册为 tool ,成为 smart API ,⽅便社区开发者调⽤:\nhttps://modelscope.cn/headlines/article/268 \n8.如何调⽤API\n具体⽂档可参考:低代码调⽤API 创建更加酷炫的\nAgenthttps://modelscope.cn/headlines/article/267 \n①进⼊ “ Configure (配置) ” 类的 Agent 创建\n②选择 “ OpenAPI Configuration ” 对其 “schema配置”进⾏配置,规范如下:\nOpenapi\nschema\n 编写解释,根据 api 详情进⾏编写 复制代码\n③“Authentication Type ” 选择:\nAuthentication Type 选择了 None ,则⽆需填写。\nAuthentication Type 选择了 API Key ,则这⾥需要填⼊ key (也可被称为 token )。dashscope 的 key\n的获取⽅式⻅⽂档:https://help.aliyun.com/zh/dashscope/developer-reference/activate-\ndashscope-and-create-an-api-key/?spm=a2c4g.11174283.0.0.', start_char_idx=0, end_char_idx=873, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n'), score=0.4076330930534659),
NodeWithScore(node=TextNode(id_='c79298d9-5deb-4760-b49f-7181aba08959', embedding=None, metadata={'page_label': '2', 'file_name': '常见QA.pdf', 'file_path': 'tests/samples/常见QA.pdf', 'file_type': 'application/pdf', 'file_size': 898222, 'creation_date': '2024-06-06', 'last_modified_date': '2024-06-06'}, excluded_embed_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], excluded_llm_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='39809dc5-830c-4f21-8527-5a1f57bb15da', node_type=<ObjectType.DOCUMENT: '4'>, metadata={'page_label': '2', 'file_name': '常见QA.pdf', 'file_path': 'tests/samples/常见QA.pdf', 'file_type': 'application/pdf', 'file_size': 898222, 'creation_date': '2024-06-06', 'last_modified_date': '2024-06-06'}, hash='ccac944f78a9b50a6601a958c732626c22dbcdb37fdc55c386bc4a141cf175b9'), <NodeRelationship.PREVIOUS: '2'>: RelatedNodeInfo(node_id='50a487c6-eab8-4a60-97ba-e7c07baf5cc5', node_type=<ObjectType.TEXT: '1'>, metadata={'page_label': '1', 'file_name': '常见QA.pdf', 'file_path': 'tests/samples/常见QA.pdf', 'file_type': 'application/pdf', 'file_size': 898222, 'creation_date': '2024-06-06', 'last_modified_date': '2024-06-06'}, hash='b2b79f4dfb9613a5d16dba31f26d3fd16b3a738fe346140dfbb71f204d9827f8'), <NodeRelationship.NEXT: '3'>: RelatedNodeInfo(node_id='a64fcd33-d497-4165-a9d5-ca6ff166d818', node_type=<ObjectType.TEXT: '1'>, metadata={}, hash='1248852b934bf9ea7cc6de4178a6567e47139f9b678f0d17c34e2ef4bfa26c64')}, text='2 / 5⾼德天⽓ API 请在这⾥申请:https://lbs.amap.com/api/javascript-api-v2/guide/services/weather后\n填⼊\n3-2:AGENT_URL 保持默认即可\n4.如何找到我发布的 Agent\n4-1:通过创空间⻚⾯查询:进⼊创空间⻚⾯,点击筛选条件 “ 更新时间 ” 即可查询。\n4-2:通过⾸⻚ “ 我创建的 ” 查询:https://modelscope.cn/my/myspace \n5.如何修改已发布的 Agent\n背景知识:agent 的 instruction 等信息被存在 AGENT_URL', start_char_idx=0, end_char_idx=288, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n'), score=0.3573998250977543)]而bm25召回的2个节点中,并不包含有高德天气API的内容,其召回内容主要集中在传入的第一个url。
[
NodeWithScore(node=TextNode(id_='828f0384-028b-4bf5-8ee9-193f0684517a', embedding=None, metadata={'file_path': 'tests/samples/modelscope_qa_2.txt', 'file_name': 'modelscope_qa_2.txt', 'file_type': 'text/plain', 'file_size': 2174, 'creation_date': '2024-01-11', 'last_modified_date': '2024-01-11'}, excluded_embed_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], excluded_llm_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='ff093ebe-9d34-4298-8012-74d3d231d378', node_type=<ObjectType.DOCUMENT: '4'>, metadata={'file_path': 'tests/samples/modelscope_qa_2.txt', 'file_name': 'modelscope_qa_2.txt', 'file_type': 'text/plain', 'file_size': 2174, 'creation_date': '2024-01-11', 'last_modified_date': '2024-01-11'}, hash='44a9f5346e712206f940ae909dbb992a5429e9522666302ba3eec202c5ffed12'), <NodeRelationship.NEXT: '3'>: RelatedNodeInfo(node_id='0ef0404b-e5c9-4272-9696-64e88971bf80', node_type=<ObjectType.TEXT: '1'>, metadata={}, hash='c9e633a6f17f545e5f3f4d51cd39747778c4595a03655901484c96f5048f9615')}, text="Q8:多卡环境,如何指定卡推理?\n\n推理可以传递参数 device,pipeline 参数: device 设置 'gpu:0' 即可。\n\nQ9:zero-shot 分类模型可以用下游的自己的数据作微调吗?\n\n可以。如果您的数据 label 变化较大,出于追求模型效果,classifier 可以 init weight 处理。如果您的数据 label 变化不大,可以直接在 classifier 上继续微调。\n\nQ10:在哪里可以看得到 ModelScope 教程和实战资料?\n\n您可以查看 ModelScope 实战训练营,点击报名后即可查看所有录制的视频课程。\n\nQ11:ModelScope 有没有已经搭好的 docker 镜像,以及我应该在哪里下载使用?\n\nModelScope 提供 GPU 镜像和 CPU 镜像,具体可在环境安装内查看最新版本镜像信息。\n\nQ12:ModelScope 是否支持算法评测?\n\n目前 API 支持单个模型的 finetune 和评测,批量评测功能还在持续建设中,您暂时可以写个脚本来实现。关于算法评测,可以参考这里。\n\nQ13:ModelScope 是否会推出纯离线的 SDK 版本?\n\n现在模型大部分还是需要基于服务端的算力支持,纯端上的模型的剪枝和转化可以需要用一些工具来解决,这部分工具能力还在规划开放中。\n\nQ14:通过 SDK 上传数据集或模型时,报错“requests.exceptions.HTTPError: 400 Client Error: Bad Request for url:”怎么办?\n\n您可以先检查下当前的 Library 版本,确认下是否为最新。", start_char_idx=0, end_char_idx=711, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n'), score=0.0),
NodeWithScore(node=TextNode(id_='0ef0404b-e5c9-4272-9696-64e88971bf80', embedding=None, metadata={'file_path': 'tests/samples/modelscope_qa_2.txt', 'file_name': 'modelscope_qa_2.txt', 'file_type': 'text/plain', 'file_size': 2174, 'creation_date': '2024-01-11', 'last_modified_date': '2024-01-11'}, excluded_embed_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], excluded_llm_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='ff093ebe-9d34-4298-8012-74d3d231d378', node_type=<ObjectType.DOCUMENT: '4'>, metadata={'file_path': 'tests/samples/modelscope_qa_2.txt', 'file_name': 'modelscope_qa_2.txt', 'file_type': 'text/plain', 'file_size': 2174, 'creation_date': '2024-01-11', 'last_modified_date': '2024-01-11'}, hash='44a9f5346e712206f940ae909dbb992a5429e9522666302ba3eec202c5ffed12'), <NodeRelationship.PREVIOUS: '2'>: RelatedNodeInfo(node_id='828f0384-028b-4bf5-8ee9-193f0684517a', node_type=<ObjectType.TEXT: '1'>, metadata={'file_path': 'tests/samples/modelscope_qa_2.txt', 'file_name': 'modelscope_qa_2.txt', 'file_type': 'text/plain', 'file_size': 2174, 'creation_date': '2024-01-11', 'last_modified_date': '2024-01-11'}, hash='ce683c72508ea8d2768fbd7678f548bd4165021fc5eb8e84d516d39c63716369'), <NodeRelationship.NEXT: '3'>: RelatedNodeInfo(node_id='50a487c6-eab8-4a60-97ba-e7c07baf5cc5', node_type=<ObjectType.TEXT: '1'>, metadata={}, hash='63a25c47fe4e6e1e2ea871f2934bd009333cb93abb9d5c798a7910858e8605d9')}, text='关于算法评测,可以参考这里。\n\nQ13:ModelScope 是否会推出纯离线的 SDK 版本?\n\n现在模型大部分还是需要基于服务端的算力支持,纯端上的模型的剪枝和转化可以需要用一些工具来解决,这部分工具能力还在规划开放中。\n\nQ14:通过 SDK 上传数据集或模型时,报错“requests.exceptions.HTTPError: 400 Client Error: Bad Request for url:”怎么办?\n\n您可以先检查下当前的 Library 版本,确认下是否为最新。然后检查下采用的 token 是否为 SDK token。若还不能解决该问题,请联系官方协助您解决。\n\nQ15:使用官方镜像,但加载模型过程中会存在报错,应该怎么解决?\n您可以先通过 pip list 等方式,对照环境安装内版本号看当前镜像是否为最新版本,若非最新版本,可更新后重试。若重试依然无法解决问题,请通过官方钉钉群联系我们。\n\nQ16: 模型大文件上传遇到问题如何解决?\n模型文件一般都比较大,我们通过 git lfs 管理模型中的大文件,首先确保您安装了正确版本的 git-lfs, 另外请确保您的大文件在文件列表中(.gitattributes 文件).', start_char_idx=466, end_char_idx=995, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n'), score=0.0)]取两个召回器召回内容并集的结果,memory.run总结得到输出:
高德天气API可以在以下链接申请:[https://lbs.amap.com/api/javascript-api-v2/guide/services/weather](https://lbs.amap.com/api/javascript-api-v2/guide/services/weather)不同的召回方式对不同类型文档的召回能力表现各有差异,灵活混用可以让各召回器在各自擅长的领域发挥最大作用。
多模态
前面介绍文件读取时有提到,默认支持的除文本文件外,还支持 .jpg, .png, .jpeg, .mp3, .mp4等图片、音频、视频模态文件。以图片模态为例,图片对应的阅读器是ImageReader,其参数`parse_text`为True时,会自动从hf下载调用识图模型naver-clova-ix/donut-base-finetuned-cord-v2,对图像内容进行理解,作为图像信息供后续的召回参考。由于从hf下载模型需要在特定的网络环境下,因此默认不使用读图功能,因此在默认配置中,图像模态给到召回器可参考的信息只有:这是个图像+图片路径与文件名。例如有一个名为rag的图片:
from modelscope_agent.memory import MemoryWithRag
memory = MemoryWithRag(urls=['tests/samples/rag.png'], use_knowledge_cache=False)
print(memory.run('我想看rag的流程图'))
# 输出结果:我无法直接提供文件内容或显示图像,但您可以查看位于tests/samples/rag.png的流程图来获取所需信息。
print(memory.run('我想看rag的流程图', use_llm=False))
# 输出结果:file_path: tests/samples/rag.png后续我们会对此进行优化,增加图像理解模型的可选范围。如果当前您想使用图像理解功能,在能够使用 naver-clova-ix/donut-base-finetuned-cord-v2 的环境下可以这样操作:
from modelscope_agent.memory import MemoryWithRag
from llama_index.readers.file import ImageReader
memory = MemoryWithRag(urls=['tests/samples/rag.png'], loaders={'.png': ImageReader(parse_text=True)})更多ModelScope-Agent介绍:
开源地址:
https://github.com/modelscope/modelscope-agent
论文:
https://arxiv.org/abs/2309.00986
点击链接👇直达原文
https://www.modelscope.cn/brand/view/agent?from=csdnzishequ_text








 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)