

引言
在当前的人工智能领域,特别是大语言模型、文生图等领域,基于预训练模型完成机器学习模型的开发部署已成为重要的应用范式,开发者们依赖于这些先进的开源预训练模型,以简化机器学习应用的开发并加速创新。
PAI 是阿里云上端到端的机器学习平台,支持开发者完成机器学习模型的开发部署全生命周期流程。通过与魔搭 ModelScope 社区合作,开发者可以使用预置的 PAI Python SDK 代码模版,轻松地在 PAI 上使用 ModelScope 上丰富的预训练模型,完成模型的开发和部署。
通过 PAI SDK 使用 ModelScope 模型
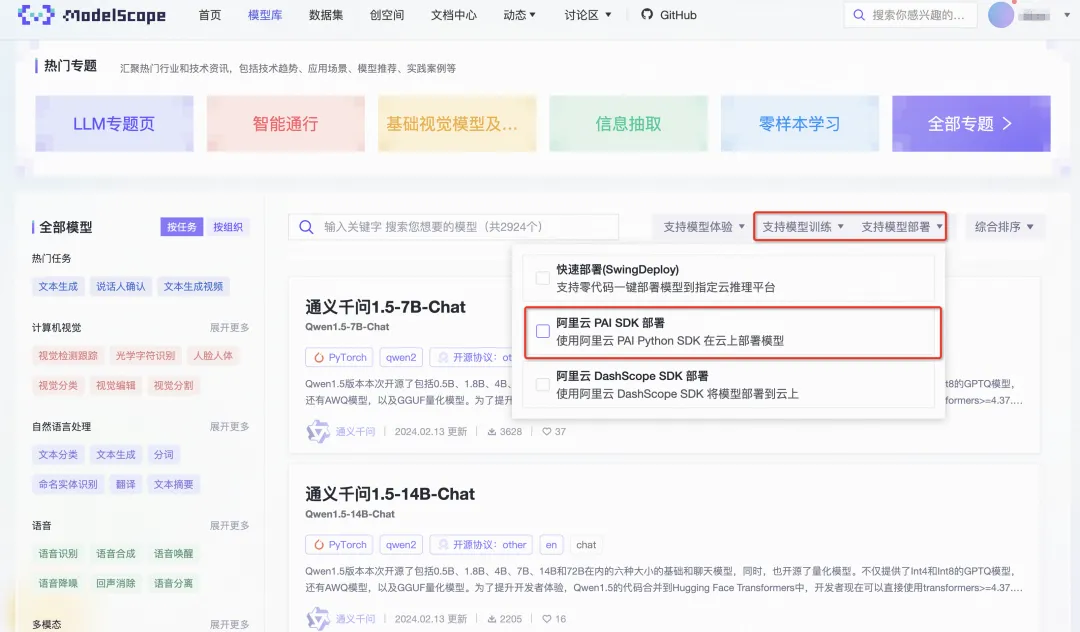
通过 ModelScope 社区的模型搜索功能,我们可以通过“阿里云PAI SDK部署/训练”过滤选项,找到当前支持使用 SDK 部署/训练的模型。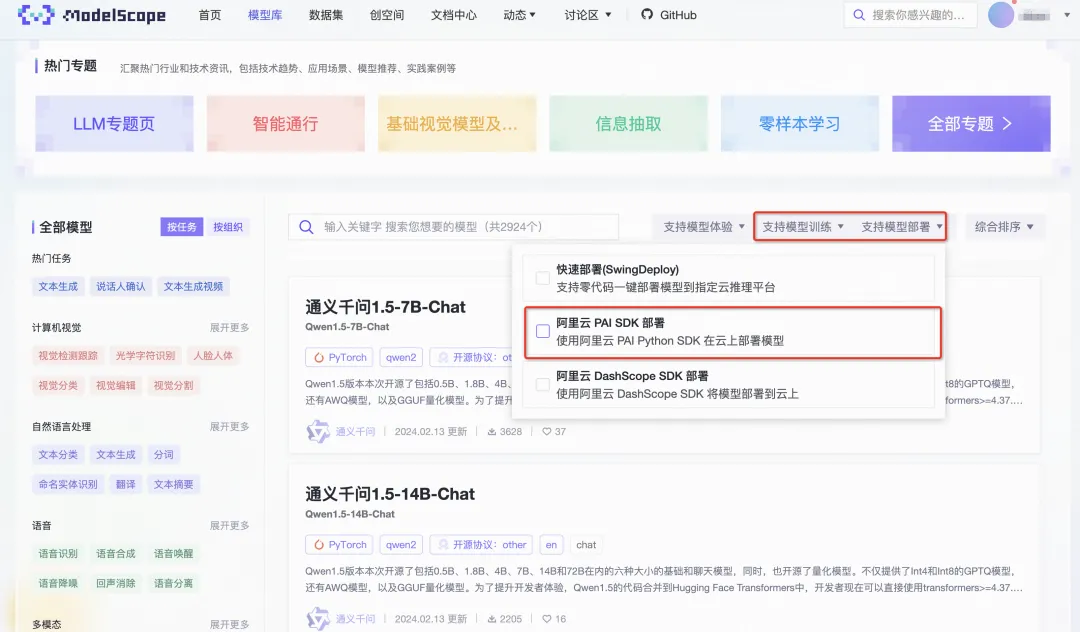
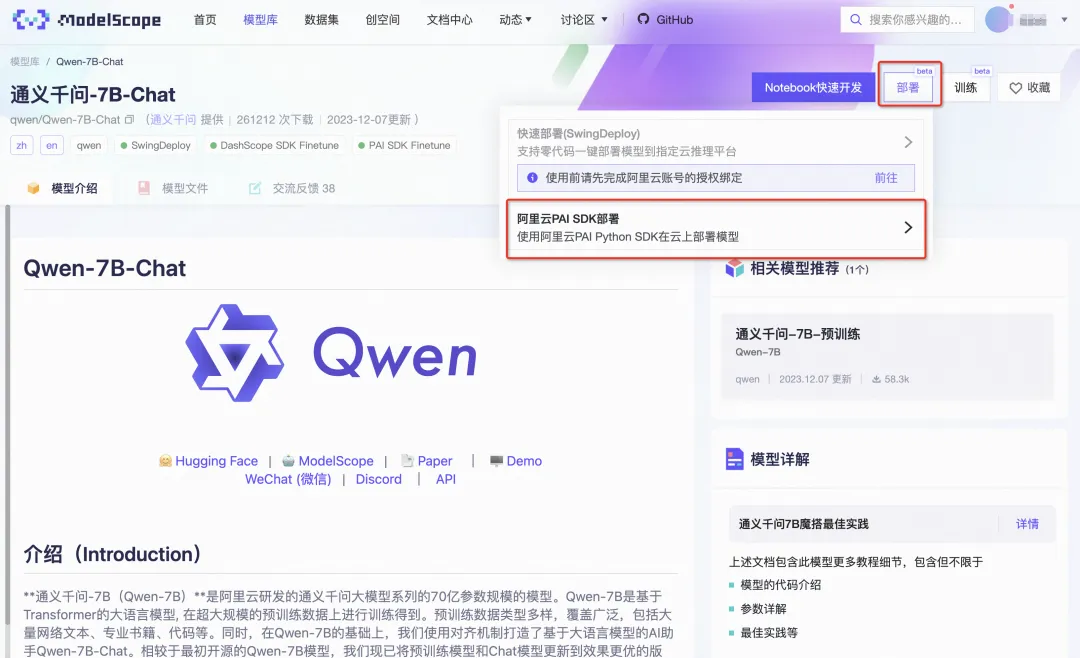
通过模型卡片详情页的“部署”和“训练”入口,查看“阿里云PAI SDK部署/训练”,我们可以获取到相应模型的训练或是部署的示例代码。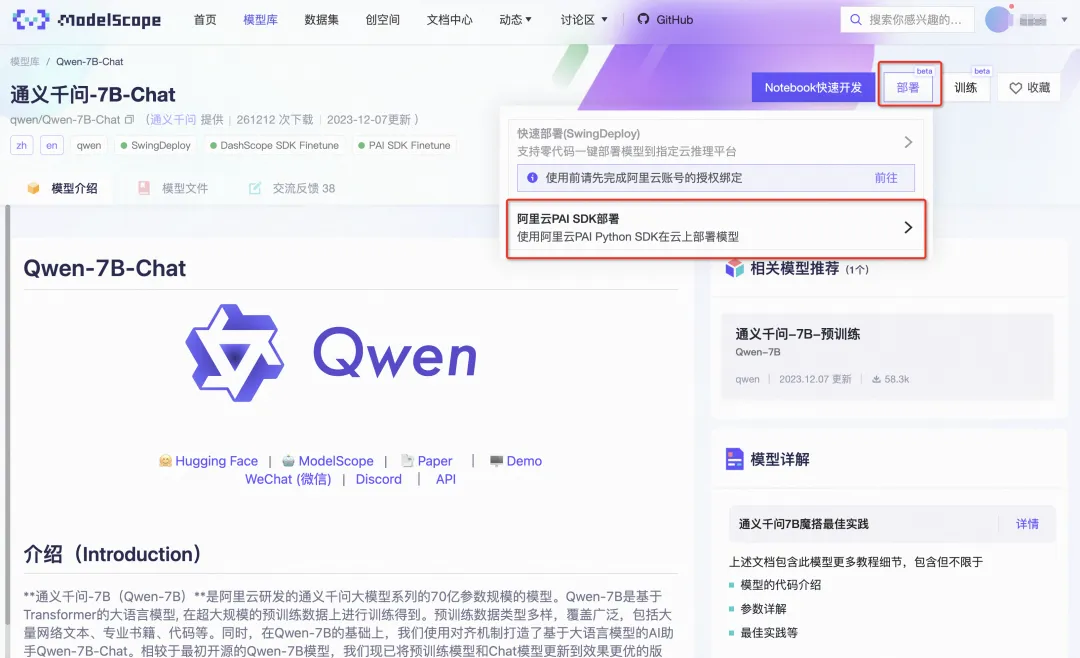
开发者可以根据自己的需求,参考代码模版注释和 SDK 文档修改代码后提交执行。
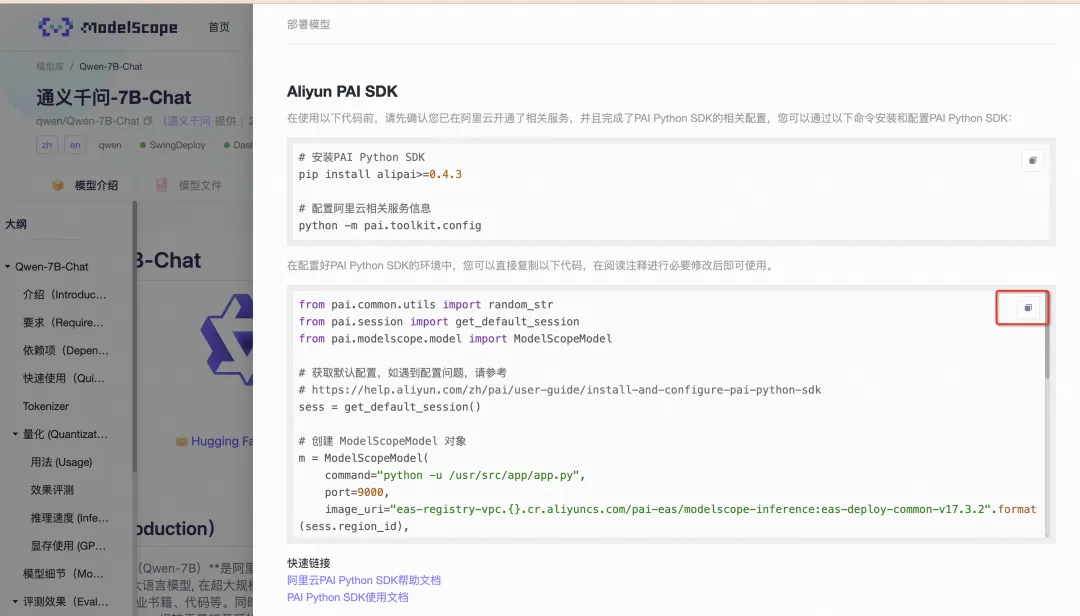
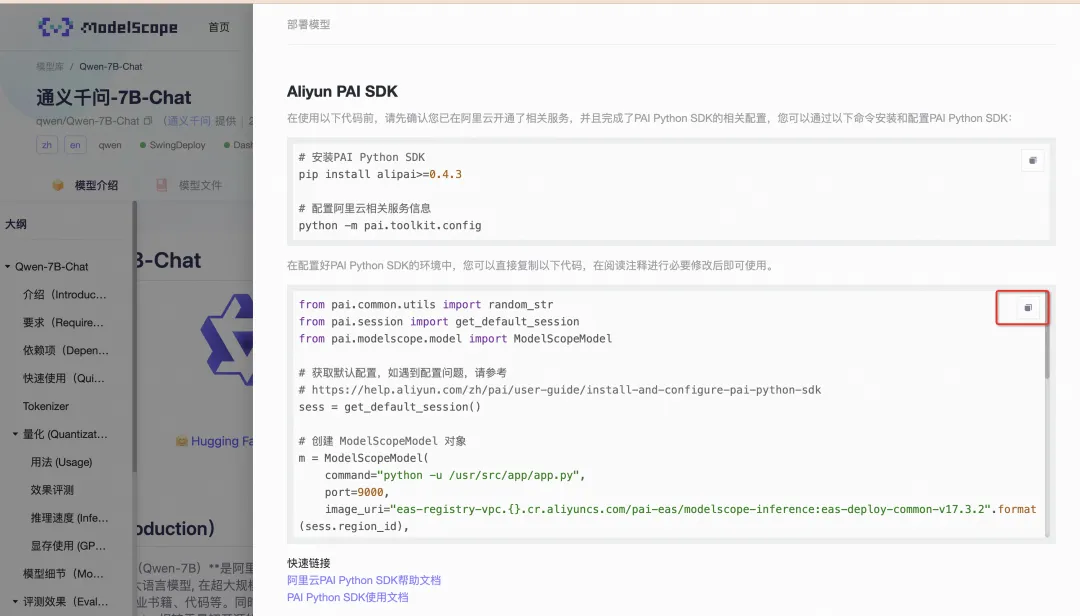
Qwen1.5-7B-Chat训练和部署示例
Qwen1.5-7B-Chat 是阿里云通义千问系列开源模型的一员,模型性能在同尺寸的模型中属于头部梯队,对推理和微调硬件要求不高,可以直接部署,或是通过微调对模型进行定制优化。
Qwen1.5-7B-Chat模型卡片链接:https://modelscope.cn/models/qwen/Qwen1.5-7B-Chat/summary
以下我们将以Qwen1.5-7B-Chat模型的训练和部署为示例进行介绍。
前提准备
在运行以下示例代码之前,需要完成以下准备:
-
PAI 产品开通
具体请参考文档:
开通PAI并创建默认工作空间_人工智能平台 PAI(PAI)-阿里云帮助中心
注意:模型的训练任务将产生 PAI-DLC 账单费用,创建推理服务将产生 PAI-EAS 账单费用。
-
PAI Python SDK 安装和初始化
在命令行中执行以下命令,完成 SDK 的方案和配置
python -m pip install -U alipai
# 配置鉴权密钥,PAI工作空间等信息
python -m pai.toolkit.config
具体请参考文档:
如何安装和配置PAI Python SDK_人工智能平台 PAI(PAI)-阿里云帮助中心
模型部署
Qwen1.5-7B-Chat 部署的示例模版代码如下:
from pai.common.utils import random_str
from pai.session import get_default_session
from pai.modelscope import ModelScopeModel
sess = get_default_session()
# 创建 ModelScopeModel 对象。
model = ModelScopeModel(
# 推理服务启动命令
command=(
"python webui/webui_server.py --model-path=Qwen/Qwen1.5-7B-Chat "
"--model-type=qwen2 --backend=vllm "
# vLLM engine arguments
" --max-model-len=4096 --gpu-memory-utilization=0.95"
),
# 推理服务镜像
image_uri=f"eas-registry-vpc.{sess.region_id}.cr.aliyuncs.com/pai-eas/chat-llm-webui:3.0.3-vllm",
)
# 部署创建推理服务
predictor = model.deploy(
# 服务名称
service_name=f"ms_serving_{random_str(6)}",
# 服务使用的机型规格
instance_type="ecs.gn7i-c8g1.2xlarge",
options={
"metadata.enable_webservice": True,
"metadata.rpc.keepalive": 300000,
"features.eas.aliyun.com/extra-ephemeral-storage": "30Gi",
}
)以上的代码将使用 PAI 提供的大语言模型推理镜像,使用 vLLM 作为推理引擎在 PAI-EAS 上创建一个推理服务实例。
deploy 方法返回的 Predictor 对象指向创建的推理服务,它提供了 predict 方法支持调用推理服务。代码模版中也提供了调用示例,供开发者参考。基于大语言模型部署的推理服务,支持通过OpenAI SDK调用。
# 大语言模型推理服务支持OpenAI API风格
openai_api = predictor.openai()
# 通过OpenAI SDK调用推理服务
resp = openai_api.chat.completions.create(
model="default",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the meaning of life?"},
],
max_tokens=1024,
)
print(resp.choices[0].message.content)
# 注意测试完成后删除部署的服务,避免产生额外费用
# predictor.delete_service()
模型微调训练
Qwen1.5-7B-Chat 模型的训练代码基于ModelScope Swift,它是 ModelScope 社区提供的轻量级模型训练框架,开发者可以通过一行命令即可完成大语言模型的微调和部署,具体可以参考 ModelScope Swift框架介绍:
https://github.com/modelscope/swift
Qwen1.5-7B-Chat 的训练模版示例代码如下,它将使用指定的机器规格,在 PAI 上执行一个训练任务。训练任务将使用 PAI 上预置的镜像 ModelScope 训练镜像,使用 Swift 框架完成模型的微调训练。
from pai.modelscope.estimator import ModelScopeEstimator
# 模型训练超参
hyperparameters = {
"model_type": "qwen1half-0_5b-chat",
"sft_type": "lora",
"tuner_backend": "swift",
# 模型输出地址,请勿修改,只有该地址下的输出文件才会被保存
"output_dir": "/ml/output/model/",
"dtype": "AUTO",
"dataset": "ms-bench",
"train_dataset_sample": "5000",
"num_train_epochs": "2",
"max_length": "1024",
"check_dataset_strategy": "warning",
"lora_rank": "8",
"lora_alpha": "32",
"lora_dropout_p": "0.05",
"lora_target_modules": "ALL",
"gradient_checkpointing": "True",
"batch_size": "1",
"weight_decay": "0.01",
"learning_rate": "1e-4",
"gradient_accumulation_steps": "16",
"max_grad_norm": "0.5",
"warmup_ratio": "0.03"
}
# 创建 ModelScopeEstimator 对象
est = ModelScopeEstimator(
# 指定训练脚本的启动命令,通过 $PAI_USER_ARGS 传入所有超参信息,请参考:
# https://help.aliyun.com/zh/pai/user-guide/submit-a-training-job
command="swift sft $PAI_USER_ARGS",
# 任务使用的机型规格
instance_type="ecs.gn6e-c12g1.3xlarge",
# 使用相应 modelscope_version 的训练镜像
modelscope_version="1.13.3",
hyperparameters=hyperparameters,
base_job_name="modelscope-sdk-train",
# 第三方依赖包
requirements=["ms_swift==2.0.3.post1"],
)
# 提交创建一个训练任务(产生PAI-DLC账单费用)
est.fit(wait=False)
# 创建并打开一个TensorBoard实例
tb = est.tensorboard()
print(tb.app_uri)
# 等待训练作业执行完成
est.wait()
# 查看训练任务所产出的模型地址
print(est.model_data())
以上的代码同时也会在 PAI 上创建一个与作业关联的 TensorBoard 实例,可以通过TensorBoard监控模型的训练进度和性能。
训练任务产出的模型,默认保存到用户的 OSS Bucket,可以通过 ossutils 等工具下载到本地。开发者也可以直接将模型部署到 PAI-EAS 创建一个推理服务,具体可以参考以下的“使用 ModelScope Swift 框架完成大语言模型的微调训练和部署” Notebook 示例。
Notebook示例
开发者可以通过以下Notebook了解更多如何基于 PAI Python SDK 在 PAI 使用 ModelScope 模型的示例。
|
打开Notebook |
示例描述 |
|
Github DSW Gallery |
在PAI快速部署ModelScope模型。 |
|
Github DSW Gallery |
使用ModelScope Swift框架完成大语言模型的微调训练和部署。 |
|
Github DSW Gallery |
基于ModelScope library自定义代码完成ViT图片分类模型的微调训练和部署。 |
|
Github DSW Gallery |
在训练作业中使用 TensorBoard |
|
Github DSW Gallery |
提交 PyTorch 分布式作业 |
参与PAI免费使用
通过参与阿里云免费试用,首次开通PAI的用户可以获得 PAI-DLC(训练服务)和 PAI-EAS(推理服务)免费试用资源包。用户可以在提交训练作业,或是部署推理服务选择免费试用的规格实例,使用免费资源包,具体可以参考阿里云PAI免费试用:https://help.aliyun.com/zh/pai/product-overview/free-quota-for-new-users
PAI-DLC 训练服务支持的免费使用实例类型:
|
实例规格 |
CPU |
内存 |
GPU |
GPU显存 |
|
ecs.g6.xlarge |
4 |
16 GB |
- |
- |
|
ecs.gn6v-c8g1.2xlarge |
8 |
32 GB |
1 * NVIDIA V100 |
1 * 16 GB |
|
ecs.gn7i-c8g1.2xlarge |
8 |
30 GB |
1 * NVIDIA A10 |
1 * 24 GB |
PAI-EAS 推理服务支持的免费试用实例类型:
|
实例规格 |
CPU |
内存 |
GPU |
GPU显存 |
|
ecs.g6.xlarge.limit |
4 |
16 GB |
- |
- |
|
ecs.gn6i-c8g1.2xlarge.limit |
8 |
31 GB |
1 * NVIDIA T4 |
1 * 8 GB |
|
ecs.gn7i-c8g1.2xlarge.limit |
8 |
30 GB |
1 * NVIDIA A10 |
1 * 24 GB |
相关资源链接
-
ModelScope 社区:
https://modelscope.cn/
-
阿里云免费试用:
https://help.aliyun.com/zh/pai/product-overview/free-quota-for-new-users
-
PAI Python SDK Github:
https://github.com/aliyun/pai-python-sdk








 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)