
谷歌发布开源LLM Gemma,魔搭社区评测+最佳实践教程来啦!
导读
Gemma是由Google推出的一系列轻量级、先进的开源模型,他们是基于 Google Gemini 模型的研究和技术而构建。它们是一系列text generation,decoder-only的大型语言模型,对英文的支持较好,具有模型权重开源、并提供预训练版本(base模型)和指令微调版本(chat模型)。本次Gemma开源提供了四个大型语言模型,提供了 2B 和 7B 两种参数规模的版本,每种都包含了预训练版本(base模型)和指令微调版本(chat模型)。
官方除了提供pytorch版本之外,也提供了GGUF版本,可在各类消费级硬件上运行,无需数据量化处理,并拥有高达 8K tokens 的处理能力,Gemma 7B模型的预训练数据高达6万亿Token,也证明了通过大量的高质量数据训练,可以大力出奇迹,小模型也可以持续提升取得好的效果。
那Gemma模型的能力怎么样呢?下面是Gemma模型的基础版本与其他开源模型在公开榜单的对比:
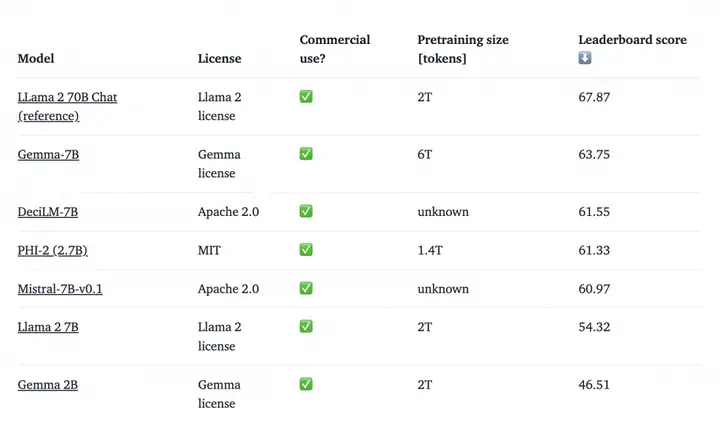
数据来源https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
从榜单中可以看到,Gemma-7B模型超过了Mistral-7B模型,取得了一个很好的结果。
技术报告链接:
https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
开源代码链接:
https://github.com/google/gemma_pytorch
目前魔搭社区已经支持 Gemma的下载、推理、微调一站式体验,并提供对应最佳实践教程,欢迎感兴趣的开发者小伙伴们来玩!
我们体验了Gemma指令微调后的模型,初步总结的如下的优点和可提升点:
| 优点 | 可提升点 |
| 英文表现强,逻辑推理能力较强 | 中文表现力较弱,偶尔会出现codeswitch情况 |
| 数学和代码能力不错 | 窗口长度为8K,在长窗口场景,比如论文分析,小说续写上,窗口长度略小。 |
| 多轮效果不佳,可持续提升 | |
| prompt template暂时不支持system role |
定量分析(以gemma-2b-it为例,在公开数据集,使用客观方式评测)
| 模型 | 能力项 | 数据集 | 平均得分 | 能力评价 |
| gemma-2b-it | 数学 | GSM8K | 0.15 | 对于2B大小的模型来说,在GSM8K上的表现比较不错 |
| 中文知识推理 | C-Eval | 0.3358 | 中文推理能力中等偏下,有些场景无法很好的完成指令跟随和知识推理 |
- 备注:
- 数据来源:使用LLM评估工具 https://github.com/modelscope/llmuses 生成评估结果
- 数据集经过采样处理
总之,Gemma是非常好的基础模型,同时在中文和多轮上还有非常大的提升空间,期待社区开发者的积极反馈,同时期待中国开发者基于Gemma模型优化中文和多轮对话能力,在此基础上做出更好的模型。
Gemma模型体验
英文常识&推理问答能力,效果不错:
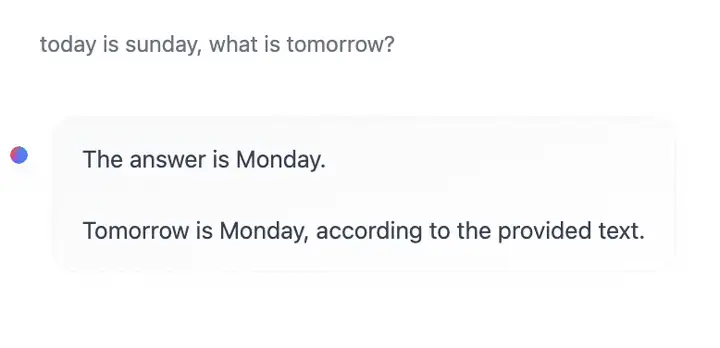
中文常识问答能力:

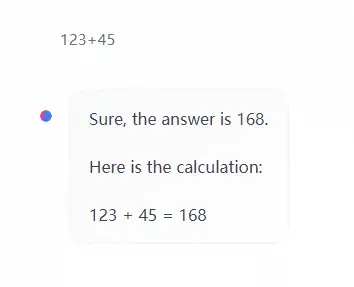
数学:确实不错,在四则运算和中文应用题解题上都能正确解答
四则运算
中文应用题

代码能力,试跑了2题,相对一般:
经典快排问题
最后输出排序结果不正确
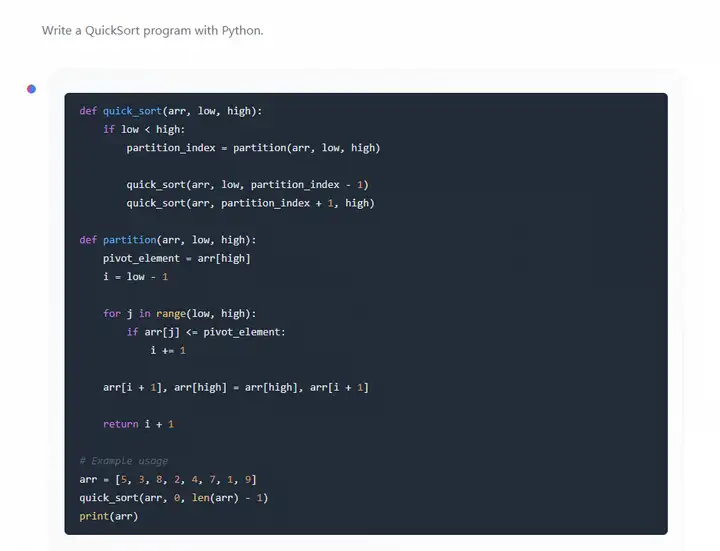
代码执行结果,排序存在问题:
def quick_sort(arr, low, high):
if low < high:
partition_index = partition(arr, low, high)
quick_sort(arr, low, partition_index - 1)
quick_sort(arr, partition_index + 1, high)
def partition(arr, low, high):
pivot_element = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot_element:
i += 1
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
# Example usage
arr = [5, 3, 8, 2, 4, 7, 1, 9]
quick_sort(arr, 0, len(arr) - 1)
print(arr)
# [1, 2, 3, 8, 5, 4, 7, 9]
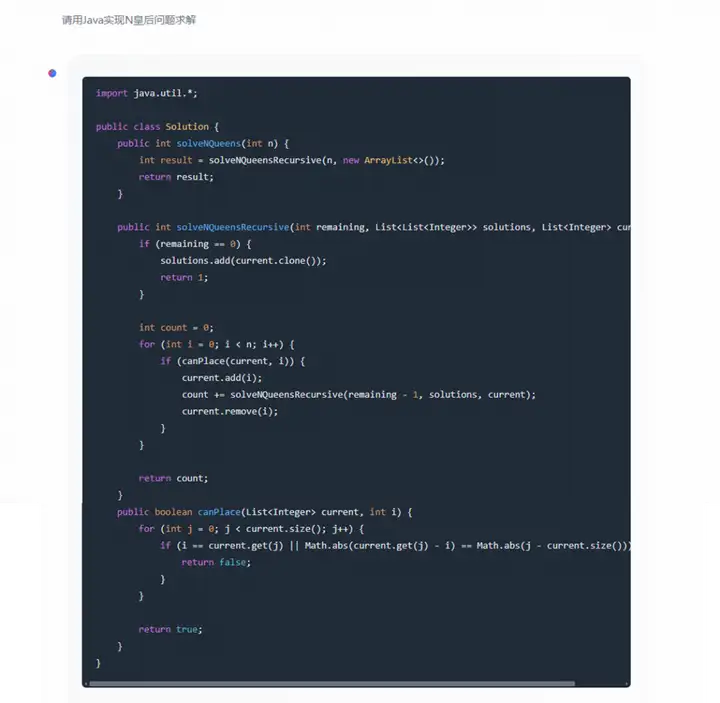
用Java实现N皇后问题求解
测试该程序无法运行
多轮对话能力,比较一般:

环境配置与安装
- python 3.10及以上版本
- pytorch 1.12及以上版本,推荐2.0及以上版本
- 建议使用CUDA 11.4及以上
- transformers>=4.38.0
可以使用魔搭社区的免费算力:
Gemma模型链接和下载
Gemma模型系列现已在ModelScope社区开源,包括:
Gemma-2b:
https://modelscope.cn/models/AI-ModelScope/gemma-2b
Gemma-2b-it:
https://modelscope.cn/models/AI-ModelScope/gemma-2b-it
Gemma-7b:
https://modelscope.cn/models/AI-ModelScope/gemma-7b
Gemma-7b-it:
https://modelscope.cn/models/AI-ModelScope/gemma-7b-it
体验链接:
https://modelscope.cn/studios/AI-ModelScope/google-gemma-demo/summary
社区支持直接下载模型的repo:
from modelscope import snapshot_download
model_dir = snapshot_download("AI-ModelScope/gemma-7b-it")Gemma模型推理
Gemma-7b-it推理代码:
需要使用tokenizer.apply_chat_template获取指令微调模型的prompt template:
from modelscope import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("AI-ModelScope/gemma-7b-it")
model = AutoModelForCausalLM.from_pretrained("AI-ModelScope/gemma-7b-it", torch_dtype = torch.bfloat16, device_map="auto")
input_text = "hello."
messages = [
{"role": "user", "content": input_text}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
input_ids = tokenizer([text], return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids,max_new_tokens=256)
print(tokenizer.decode(outputs[0]))
资源消耗:
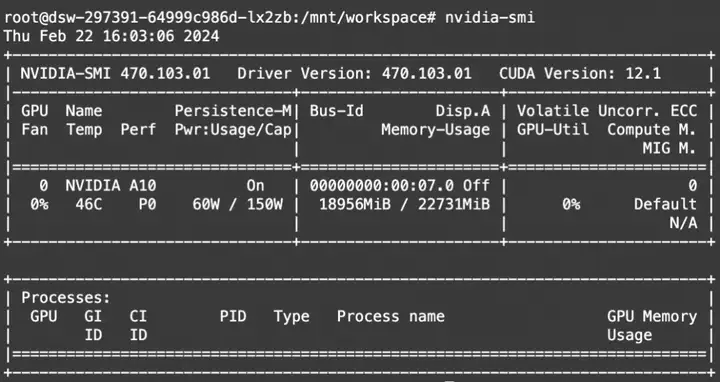
Gemma-2b-it
模型微调和微调后推理
我们使用SWIFT来对模型进行微调,SWIFT是魔搭社区官方提供的LLM&AIGC模型微调推理框架。
微调代码开源地址:
https://github.com/modelscope/swift
我们使用hc3-zh分类数据集进行微调. 任务是: 判断数据样本的回答来自human还是chatgpt.
环境准备:
git clone https://github.com/modelscope/swift.git
cd swift
pip install .[llm]
微调脚本: LoRA
# https://github.com/modelscope/swift/blob/main/examples/pytorch/llm/scripts/gemma_2b_instruct/lora
# Experimental environment: V100, A10, 3090
# 12GB GPU memory
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model_id_or_path AI-ModelScope/gemma-2b-it \
--sft_type lora \
--tuner_backend swift \
--template_type AUTO \
--dtype AUTO \
--output_dir output \
--dataset hc3-zh \
--train_dataset_sample 5000 \
--num_train_epochs 1 \
--max_length 2048 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules ALL \
--gradient_checkpointing true \
--batch_size 1 \
--weight_decay 0.01 \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--max_grad_norm 0.5 \
--warmup_ratio 0.1 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
训练过程也支持本地数据集,需要指定如下参数:
--custom_train_dataset_path xxx.jsonl \
--custom_val_dataset_path yyy.jsonl \
自定义数据集的格式可以参考:
微调后推理脚本: (这里的ckpt_dir需要修改为训练生成的checkpoint文件夹)
# Experimental environment: V100, A10, 3090
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--ckpt_dir "output/gemma-2b-instruct/vx_xxx/checkpoint-xxx" \
--load_dataset_config true \
--max_length 2048 \
--max_new_tokens 2048 \
--temperature 0.1 \
--top_p 0.7 \
--repetition_penalty 1. \
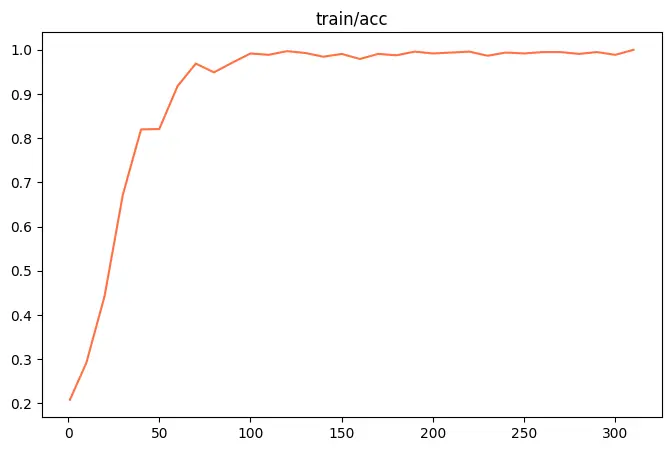
--do_sample true \微调的可视化结果
训练准确率:
训练后生成样例:
[PROMPT]<bos><start_of_turn>user
Classification Task: Are the following responses from a human or from ChatGPT?
Question: 能帮忙解决一下吗
Answer: 当然,我很乐意帮助你解决问题。请提出你的问题,我会尽力给出最好的帮助。
Category: Human, ChatGPT
Output:<end_of_turn>
<start_of_turn>model
[OUTPUT]ChatGPT<end_of_turn>
[LABELS]ChatGPT
---------------------------------------------------
[PROMPT]<bos><start_of_turn>user
Classification Task: Are the following responses from a human or from ChatGPT?
Question: 请问哪样存钱好
Answer: 若需了解招商银行存款利率,可进入招行主页在网页右下侧“实时金融信息”下方选择“存款利率”查看。
Category: Human, ChatGPT
Output:<end_of_turn>
<start_of_turn>model
[OUTPUT]Human<end_of_turn>
[LABELS]Human
点击直达模型卡片:gemma-7b-it · 模型库 (modelscope.cn)

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献653条内容
已为社区贡献653条内容

所有评论(0)