

近日,法国人工智能初创公司 Mistral AI 发布了一款新模型 Mistral 7B,其在每个基准测试中,都优于 Llama 2 13B,同时已免费开源可商用!
Mistral 7B 因 性能更强,硬件需求更少,有2023年的知识,安全对齐更靠谱,开源协议更宽松,广受赞誉。
尤其在泛化能力上, Mistral 7B 在公开提供的指令数据集上进行了微调后的模型 Mistral 7B Instruct,在 MT-Bench 上超越了其他 7B 模型,并可与 13B 聊天模型相媲美。这一成就暗示了该模型在各种专业应用中的潜力。
今天,魔搭特围绕 Mistral 7B Instruct、以及OpenBuddy团队基于Mistral 7B微调后的多语言对话模型 openbuddy-mistral-7b,在PAI-DSW的免费算力环境A10的下进行推理、微调最佳实践教程,感受“笔记本上轻松跑”,与大家分享。
-
python 3.8及以上版本
-
pytorch 1.12及以上版本,推荐2.0及以上版本
-
建议使用CUDA 11.4及以上
使用步骤
本文的推理可在PAI-DSW的免费算力环境A10下运行 (显存要求16G)
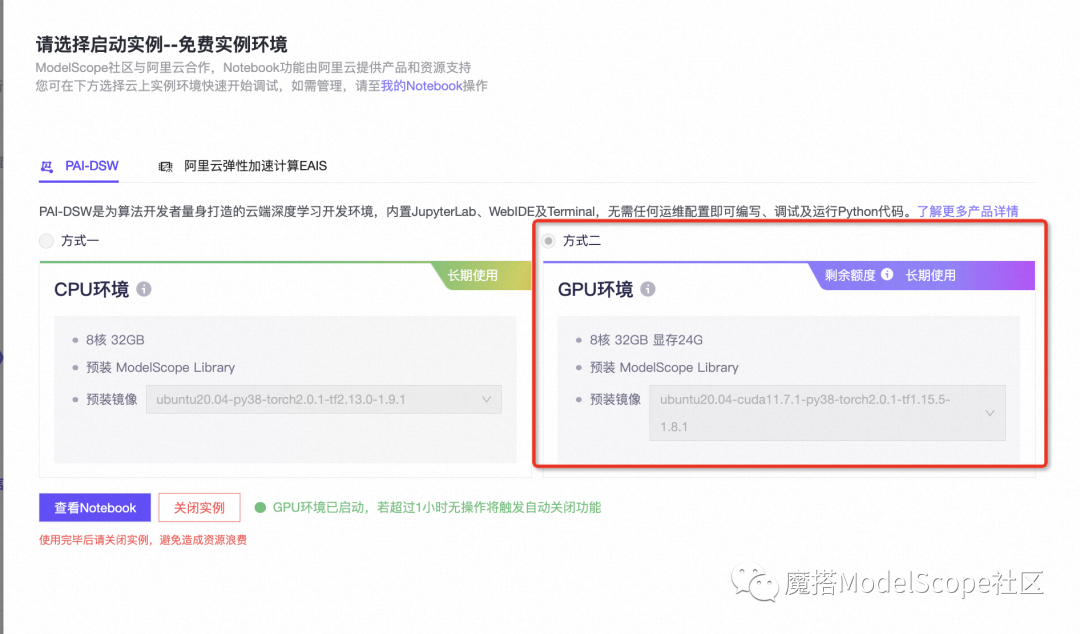
实验环境配置:
pip install "modelscope>=1.9.2"
mistral-7b-instruct
模型链接:
https://modelscope.cn/models/AI-ModelScope/Mistral-7B-Instruct-v0.1/summary
模型weights下载:
from modelscope import snapshot_download
model_dir = snapshot_download('AI-ModelScope/Mistral-7B-Instruct-v0.1', revision='v1.0.0')
openbuddy-mistral-7b
模型链接:
https://modelscope.cn/models/OpenBuddy/openbuddy-mistral-7b-v13.1/summary
模型weights下载:
from modelscope import snapshot_download
model_dir = snapshot_download('OpenBuddy/openbuddy-mistral-7b-v13.1', revision = 'v1.0.0')
mistral-7b-instruct模型推理代码:
from modelscope import AutoModelForCausalLM, AutoTokenizer, snapshot_download
import torch
device = "cuda" # the device to load the model onto
model_dir = snapshot_download('AI-ModelScope/Mistral-7B-Instruct-v0.1', revision='v1.0.0')
model = AutoModelForCausalLM.from_pretrained(model_dir, torch_dtype=torch.bfloat16, device_map=device)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
openbudy-mistral-7b模型推理代码:
from modelscope import snapshot_download
from modelscope import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" # the device to load the model onto
model_dir = snapshot_download('OpenBuddy/openbuddy-mistral-7b-v13.1', revision = 'v1.0.0')
model = AutoModelForCausalLM.from_pretrained(model_dir, torch_dtype=torch.bfloat16, device_map=device)
tokenizer = AutoTokenizer.from_pretrained(model_dir)
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
微调代码开源地址: https://github.com/modelscope/swift/tree/main/examples/pytorch/llm
clone swift仓库并安装环境
git clone https://github.com/modelscope/swift.git
cd swift
pip install .
cd examples/pytorch/llm
pip install -r requirements.txt -U
LoRA微调mistral-7b-instruct
模型微调脚本 (lora+ddp+deepspeed)
微调数据集: https://modelscope.cn/datasets/AI-ModelScope/leetcode-solutions-python/summary
# Experimental environment: 2 * A10
# 2 * 21GB GPU memory
nproc_per_node=2
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0,1 \
torchrun \
--nproc_per_node=$nproc_per_node \
--master_port 29500 \
src/llm_sft.py \
--model_type mistral-7b-chat \
--sft_type lora \
--template_type llama \
--dtype bf16 \
--output_dir output \
--ddp_backend nccl \
--dataset leetcode-python-en \
--train_dataset_sample -1 \
--num_train_epochs 1 \
--max_length 4096 \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0. \
--lora_target_modules ALL \
--gradient_checkpointing true \
--batch_size 1 \
--weight_decay 0. \
--learning_rate 1e-4 \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
--push_to_hub false \
--hub_model_id mistral-7b-chat-qlora \
--hub_private_repo true \
--hub_token 'your-sdk-token' \
--deepspeed_config_path 'ds_config/zero2.json' \
--only_save_model true \
模型微调后的推理脚本
# Experimental environment: A10
# If you want to merge LoRA weight and save it, you need to set `--merge_lora_and_save true`.
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0 \
python src/llm_infer.py \
--model_type mistral-7b-chat \
--sft_type lora \
--template_type llama \
--dtype bf16 \
--ckpt_dir "output/mistral-7b-chat/vx_xxx/checkpoint-xxx" \
--eval_human false \
--dataset leetcode-python-en \
--max_length 4096 \
--max_new_tokens 2048 \
--temperature 0.9 \
--top_k 20 \
--top_p 0.9 \
--do_sample true \
--merge_lora_and_save false \
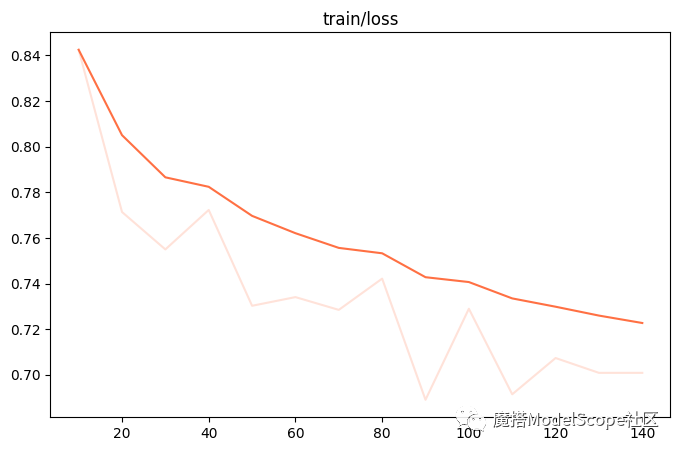
微调的可视化结果
训练损失:
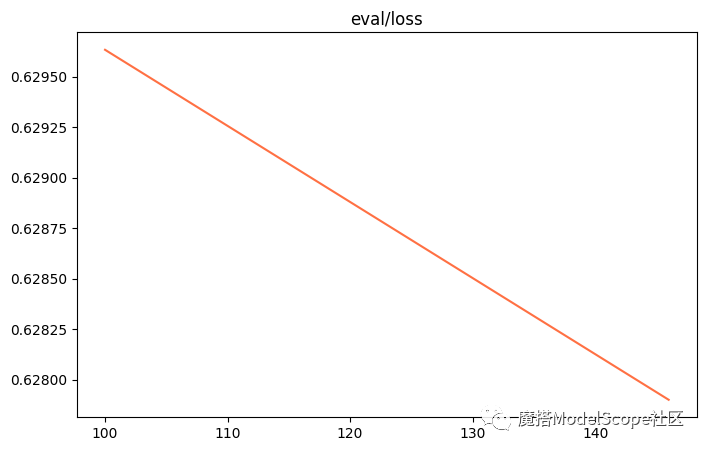
评估损失:
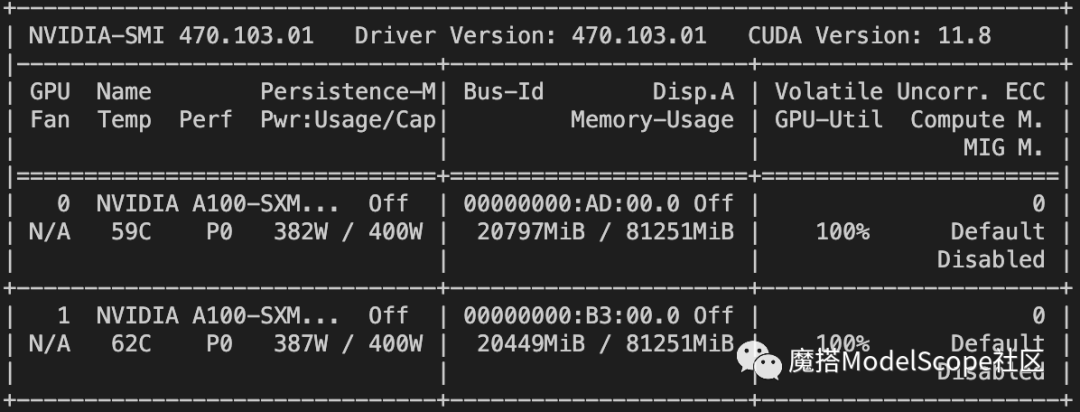
资源消耗:
mistral-7b-instruct使用 lora+ddp+deepspeed 的方式训练的显存占用如下,大约在2*21G.
LoRA微调openbuddy-mistral-7b
模型微调脚本 (lora+ddp+deepspeed)
微调数据集: https://modelscope.cn/datasets/AI-ModelScope/blossom-math-v2/summary
# Experimental environment: 2 * A10
# 2 * 18GB GPU memory
nproc_per_node=2
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0,1 \
torchrun \
--nproc_per_node=$nproc_per_node \
--master_port 29500 \
src/llm_sft.py \
--model_type openbuddy-mistral-7b-chat \
--sft_type lora \
--template_type llama \
--dtype bf16 \
--output_dir output \
--ddp_backend nccl \
--dataset blossom-math-zh \
--train_dataset_sample -1 \
--num_train_epochs 1 \
--max_length 2048 \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0. \
--lora_target_modules ALL \
--gradient_checkpointing true \
--batch_size 1 \
--weight_decay 0. \
--learning_rate 1e-4 \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
--push_to_hub false \
--hub_model_id openbuddy-mistral-7b-chat-lora \
--hub_private_repo true \
--hub_token 'your-sdk-token' \
--deepspeed_config_path 'ds_config/zero2.json' \
--only_save_model true \
模型微调后的推理脚本
# Experimental environment: A10
# If you want to merge LoRA weight and save it, you need to set `--merge_lora_and_save true`.
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0 \
python src/llm_infer.py \
--model_type openbuddy-mistral-7b-chat \
--sft_type lora \
--template_type llama \
--dtype bf16 \
--ckpt_dir "output/openbuddy-mistral-7b-chat/vx_xxx/checkpoint-xxx" \
--eval_human false \
--dataset blossom-math-zh \
--max_length 2048 \
--max_new_tokens 1024 \
--temperature 0.9 \
--top_k 20 \
--top_p 0.9 \
--do_sample true \
--merge_lora_and_save false \微调的可视化结果
训练损失:
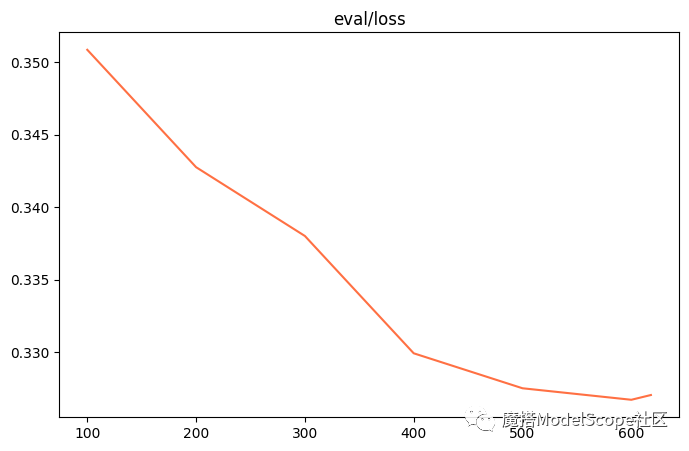
评估损失:
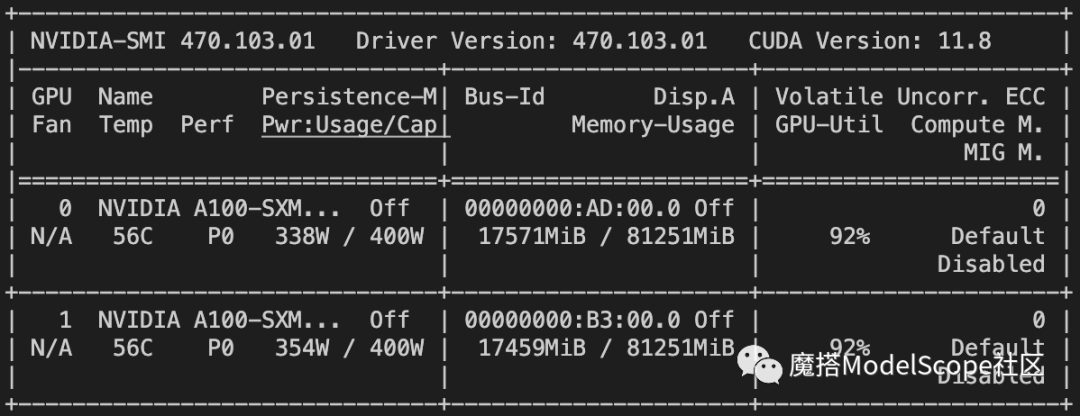
资源消耗:
openbuddy-mistral-7b使用 lora+ddp+deepspeed 的方式训练的显存占用如下,大约在2*18G.
Mistral 7B 凭借其小巧的体积、开源的特性和出色的性能,它有望改变企业在广泛应用中利用人工智能的方式。随着 Mistral AI 的不断创新和开源生态的加持,我们期待预见到人工智能领域将取得更大的进步。
2023 云栖大会 定了!10.31-11.02,来云栖小镇找魔搭玩儿!









 已为社区贡献650条内容
已为社区贡献650条内容

所有评论(0)