SeqGPT是一个不限领域的文本理解大模型。无需训练,即可完成实体识别、文本分类、阅读理解等多种任务。该模型基于Bloomz在数以百计的任务数据上进行指令微调获得。模型可以在低至16G显存的显卡上免费使用。目前SeqGPT已经在魔搭社区开源,欢迎体验!
ModelScope开源直达:
论文地址:https://arxiv.org/abs/2308.10529
github地址: https://github.com/Alibaba-NLP/SeqGPT
本文将为大家展开关于SeqGPT的详细技术解析介绍
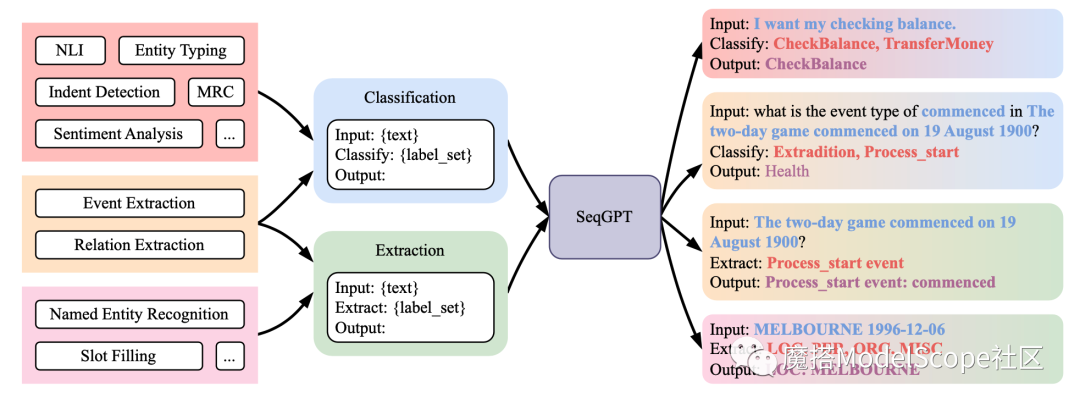
本模型可用于任何自然语言理解任务。用户只需给定类型标签即可。不同任务的标签给定方式可以参考以下例子:
训练分类两个阶段,分别为:预训练和微调,两阶段数据分别为:预训练数据:包含来自多个领域(包括维基百科、新闻和社交媒体等)极其多样化的标签集的数据。
我们主要选择了三个任务:分类(CLS)、实体分类(ET)和实体识别(NER)。我们通过调用ChatGPT为每个样本获得伪标签。
最终,PT数据集包含1,146,271个实例和817,075个不同的标签。微调数据:我们收集了来自不同领域的大规模高质量NLU数据集进行微调。如下图所示,我们的微调(FT)数据集包含110个NLU数据集,涵盖英语和中文两种语言以及10大类任务。除了任务多样性外,领域(包括医学、新闻和与AI助手的对话)的多样性以及标签多样性也保证了数据多样性。每个任务被转化为原子任务,共产生了139个分类原子任务和94个抽取原子任务。
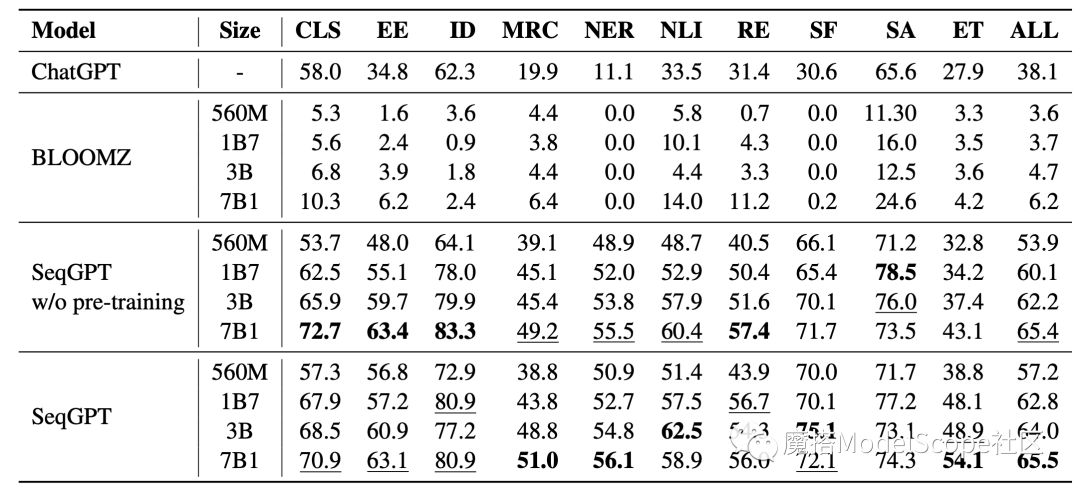
模型评估及结果:
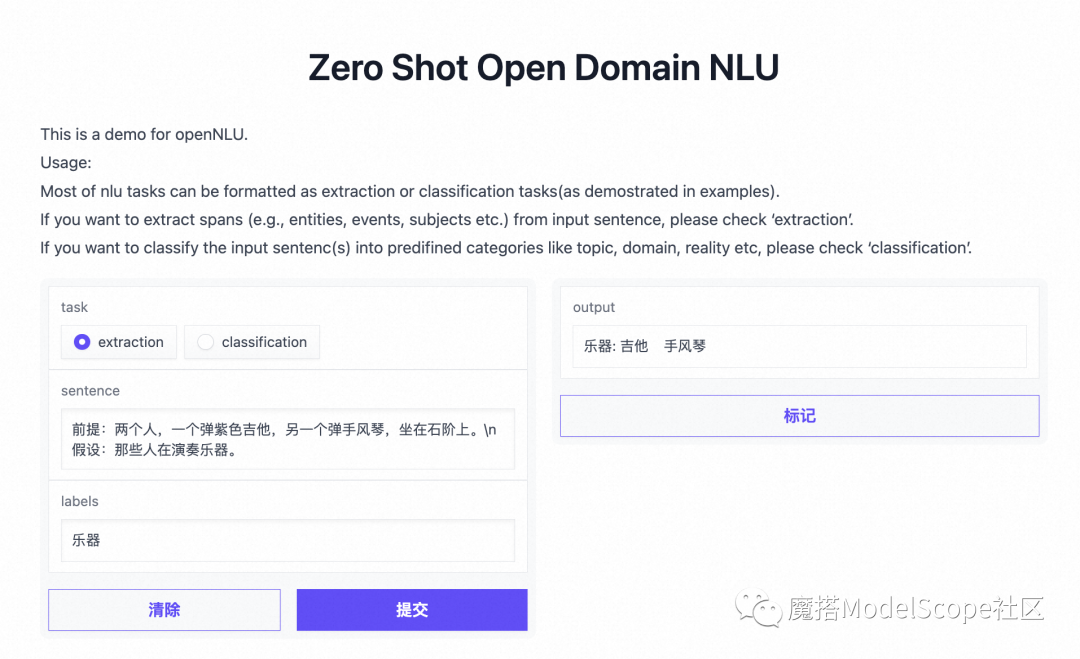
在创空间可以零门槛体验开放域NLU模型的能力,示例如下:
模型推理
在魔搭社区免费NoteBook环境,使用ModelScope的最新master分支
git clone https://github.com/modelscope/modelscope.git
cd modelscope
pip install .
模型推理代码
from modelscope.utils.constant import Tasks
from modelscope.pipelines import pipeline
# task可选值为 抽取、分类。text为需要分析的文本。labels为类型列表,中文逗号分隔。
inputs = {'task': '抽取', 'text': '杭州欢迎你。', 'labels': '地名'}
# PROMPT_TEMPLATE保持不变
PROMPT_TEMPLATE = '输入: {text}\n{task}: {labels}\n输出: '
prompt = PROMPT_TEMPLATE.format(**inputs)
pipeline_ins = pipeline(task=Tasks.text_generation, model='damo/nlp_seqgpt-560m')
print(pipeline_ins(prompt))
# {'text': '地名: 杭州\n'}
本文介绍了SeqGPT,用一个统一的模型,通过将不同的NLU任务转化为两个通用的原子任务来处理。SeqGPT提供了一致的输入输出格式,使其能够通过任意变化的标签集来解决未见过的任务,而不需要繁琐的提示工程而且结果易于解析。
https://www.modelscope.cn/studios/TTCoding/open_ner/summary










 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)