

近期,一条由AI全流程制作的《流浪地球3》预告短片大火,不禁让人惊叹一把生成式AI真的有在悄悄惊艳所有人,也给AI驱动视频创作市场提供了更大的想象空间。
上周,魔搭社区低调开源了时间、空间可控的视频生成模型 VideoComposer,近日,又一鼓作气继续开源了I2VGen-XL项目,包含了图生视频模型 Image2Video和Video2Video,仅提供1张图片,0提示词即可生成惊艳视频。
以下是生成的一些示例:
https://modelscope.cn/models/damo/Image-to-Video/summary




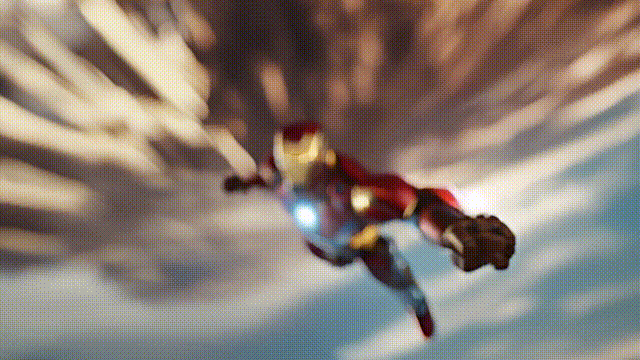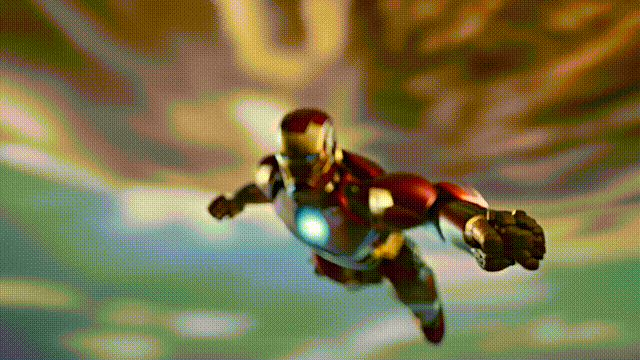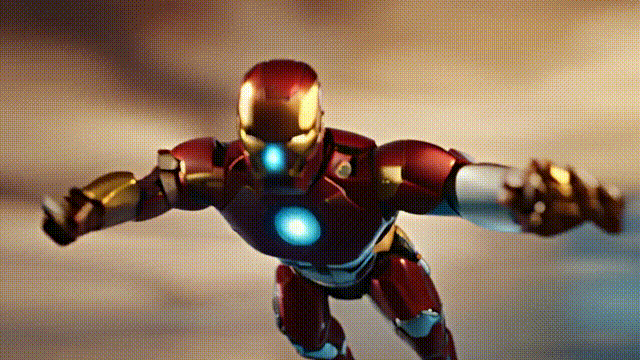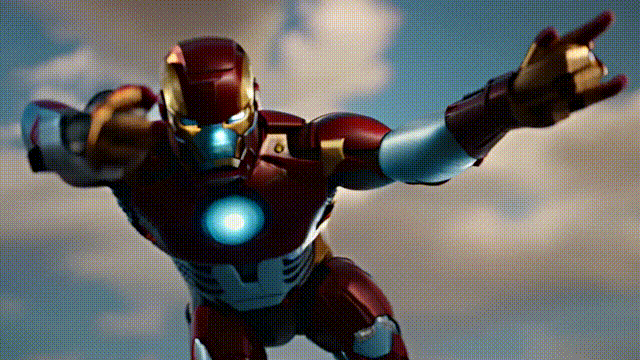
接下来,为大家进一步介绍I2VGen-XL的技术原理,及通过魔搭快速玩转起来的实操指引:
I2VGen-XL
本项目I2VGen-XL包含2个模型:图片生成视频模型MS-Image2Video和视频生成视频模型MS-Vid2Vid。
MS-Image2Video旨在解决根据输入图像生成高清视频的任务。MS-Image2Video由达摩院研发的高清视频生成基础模型,其核心部分包含两个阶段,分别解决语义一致性和清晰度的问题,参数量共计约37亿,模型经过大规模视频和图像数据混合预训练,并在少量精品数据上微调得到,该数据分布广泛、类别多样化,模型对不同的数据均有良好的泛化性。与现有的视频生成模型相比,MS-Image2Video在清晰度、质感、语义、时序连续性等方面均具有明显的优势。
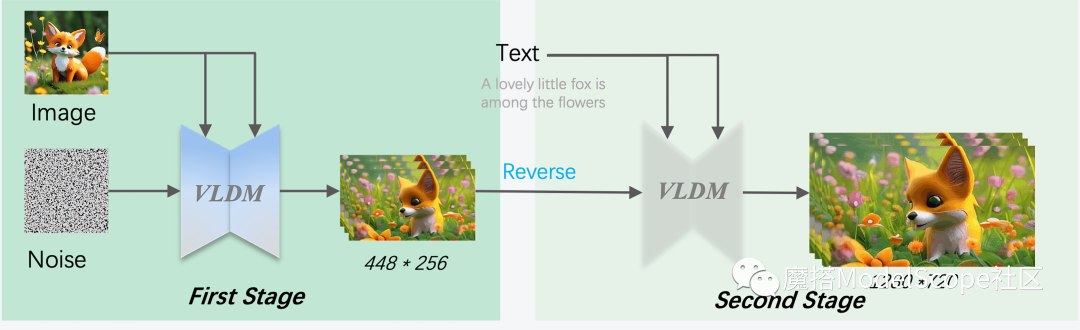
MS-Image2Video建立在Stable Diffusion之上,如上图所示,通过专门设计的时空UNet在隐空间中进行时空建模并通过解码器重建出最终视频。
为能够生成720P视频,我们将MS-Image2Video分为两个阶段,第一阶段保证语义一致性但低分辨率,第二阶段通过DDIM逆运算并在新的VLDM上进行去噪以提高视频分辨率以及同时提升时间和空间上的一致性。通过在模型、训练和数据上的联合优化。
本项目主要具有以下几个特点:
-
高清&宽屏,可以直接生成720P(1280*720)分辨率的视频,且相比于现有的开源项目,不仅分辨率得到有效提高,其生产的宽屏视频可以适合更多的场景
-
无水印,模型通过我们内部大规模无水印视频/图像训练,并在高质量数据微调得到,生成的无水印视频可适用更多视频平台,减少许多限制
-
连续性,通过特定训练和推理策略,在视频的细节生成的稳定性上(时间和空间维度)有明显提高
-
质感好,通过收集特定的风格的视频数据训练,使得生成的模型在质感得到明显提升,可以生成科技感、电影色、卡通风格和素描等类型视频
MS-Vid2Vid由达摩院研发和训练,主要用于提升文生视频、图生视频的分辨率和时空连续性,其训练数据包含了精选的海量的高清视频、图像数据(最短边>720),可以将低分辨率的(16:9)的视频提升到更高分辨率(1280 * 720),可以用于任意低分辨率的的超分。
MS-Vid2VidL是基于Stable Diffusion设计而得,其设计细节延续我们自研VideoComposer,具体可以参考其技术报告。如下示例中,左边是低分(448 * 256),细节会存在抖动,时序一致性较差 右边是高分(1280 * 720),总体会平滑很多,在很多case具有较强的修正能力
如下示例:

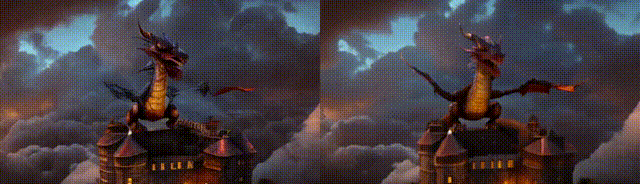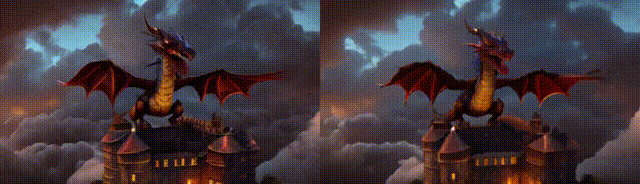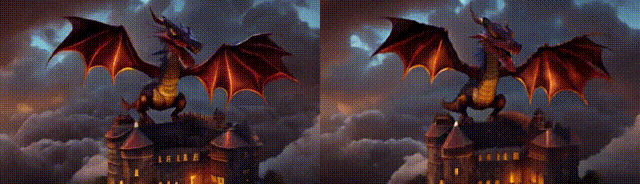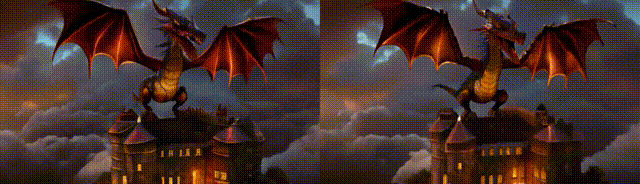
环境配置与安装
1、 本文在1*A100的环境配置下运行 (可以单卡运行, 图生视频模型显存要求20G,视频生成视频显存要求28G)
2、torch2.0.1+cu117,python>=3.8
服务器连接与环境准备
# 安装miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 一直[ENTER], 最后一个选项yes即可
sh Miniconda3-latest-Linux-x86_64.sh
# conda虚拟环境搭建
conda create --name ms-sft python=3.8
conda activate ms-sft
# 安装最新的ModelScope
pip install "modelscope" --upgrade -f https://pypi.org/project/modelscope/
# 确定你的系统安装了ffmpeg命令,如果没有,可以通过以下命令来安装
sudo apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
# 安装依赖库
pip install xformers==0.0.20
pip install torch==2.0.1
pip install torchsde
pip install open_clip_torch>=2.0.2
pip install opencv-python-headless
pip install opencv-python
pip install einops>=0.4
pip install rotary-embedding-torch
pip install fairscale
pip install scipy
pip install imageio
pip install pytorch-lightning模型的下载和推理
MS-Image2Video模型现已在ModelScope社区开源
模型链接:
https://modelscope.cn/models/damo/Image-to-Video/summary
https://modelscope.cn/models/damo/Video-to-Video/summary
通过以下代码,实现模型的下载和推理。
第一步:图生视频 (所需显存单卡20G)
from modelscope.pipelines import pipeline
from modelscope.outputs import OutputKeys
pipe = pipeline(task="image-to-video", model='damo/Image-to-Video', model_revision='v1.1.0')
# IMG_PATH: your image path (url or local file)
IMG_PATH = './example.png'
output_video_path = pipe(IMG_PATH, output_video='./output.mp4')[OutputKeys.OUTPUT_VIDEO]
print(output_video_path)
第二步:提升视频分辨率 (所需显存单卡28G)
pipe =pipeline(task="video-to-video", model='damo/Video-to-Video', model_revision='v1.1.0')
# VID_PATH: your video path
# TEXT : your text description
VID_PATH = './output.mp4'
TEXT = 'A lovely little fox is among the flowers.'
p_input = {
'video_path': VID_PATH,
'text': TEXT
}
output_video_path = pipe(p_input, output_video='./output.mp4')[OutputKeys.OUTPUT_VIDEO]
print(output_video_path)
另外,I2VGen-XL的魔搭创空间搭建中。
链接:https://modelscope.cn/studios/damo/I2VGen-XL-Demo/summary,大家先期待一把吧!








 已为社区贡献653条内容
已为社区贡献653条内容

所有评论(0)