
关键点检测从入门到进阶
背景知识
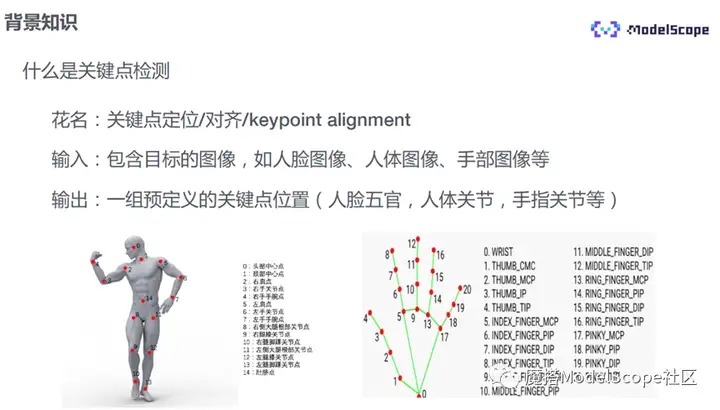
关键点检测,也被称作关键点定位或关键点对齐(keypoint alignment),在不同的任务中名字可能略有差异。比如,在人脸关键点定位中会被称作facemark alignment,在人体关键点检测中称作pose alignment。
通常,它的输入是一张包含目标的图像,比如人脸的图像、人体的图像或手部的图像,输出是一组预先定义好关键点的位置,比如人脸的五官与脸部轮廓、人体的各个关节、手部的各个关节等。
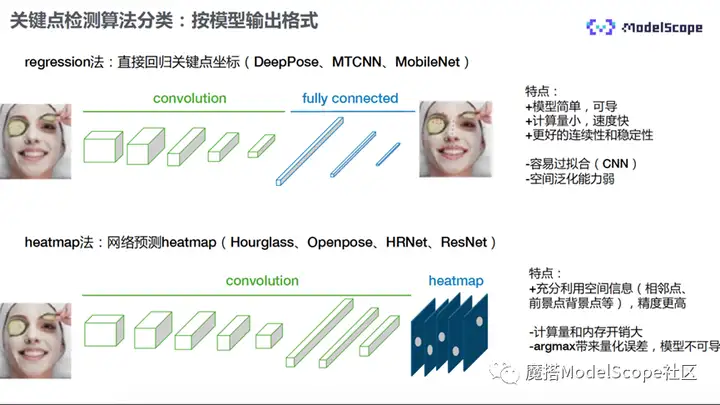
关键点检测算法可以分为两大类。
1)按照模型输出的格式进行分类,又可以分为regression法和heatmap法。
- regression法:直接回归关键点坐标,将输入的图片直接送入卷积网络,再经过全连接层的处理,直接输出关键点的坐标,常见的方法有DeepPose、MTCNN以及MobileNet等。
- heatmap法:其groundtruth以及网络的输出是一张图像,图像包含了多个通道,每一个通道代表一类关键点,有多少关键点便有多少个通道。每个通道中的观测点是以点为中心、r为高斯的分布,从图像中提取关键点,最简单的方式是提取像素值最大点所在位置,即关键点的坐标。其结构输入图经过卷积网络处理之后输出heatmap。常用方法有Openpose、HRnet以及Restnet等。
上述两种方法各有优缺点。
回归法模型比较简单,全程可导。另外,计算量很小,处理速度相对更快。同时,因为它所有的关键点都自最后的一张featuremap,因此具有更好的连续性和稳定性。但全连接层会导致模型容易过拟合,训练时比较难,模型缺乏空间泛化的能力。解决方案为可以用CNN层代替全连接层,优化问题。
heatmap方法在实际中使用较多,它可以充分利用关键点相邻以及空间中的信息,因此其精度更高。但网络结构比较复杂,计算量和内存开销也会比较大。另外,由于提取过程中会有量化的误差,会导致精度的缺失,argmax函数也会导致模型过程不可导。
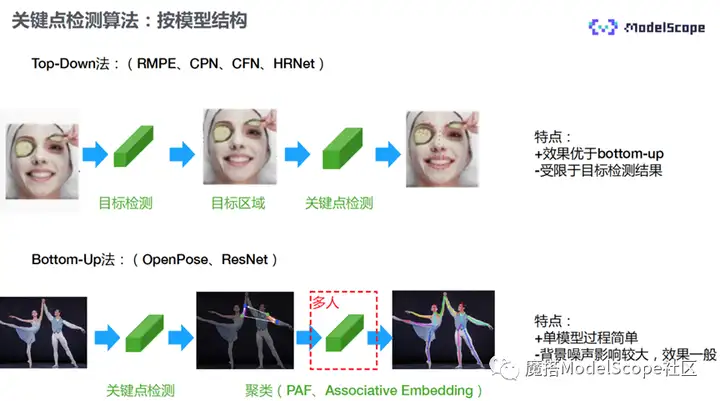
2)按模型的结构进行分类,可以分为自顶向下Top-Down法和自底向上Bottom-up法。
- 自顶向下法:分为两个步骤,首先,对于原始输入图片做目标检测,比如做人脸检测,将人脸区域抠出,单独送进关键点检测模型,最终输出关键点的坐标。比较常见的方法有HMPE、CPN、CFN等模型。
- 自底向上:只有一个模型,不需要进行目标检测,直接将原始图像送进关键点检测模型,即可输出所有关键点。如果有多个目标,则无法区分哪些点属于目标1,哪些点属于目标2。因此有多个目标时,还需要在后面接一个聚类的模块,将各个目标的关键点进行区分。
两种方法各有优缺点。
自顶向下的方法效果优于自底向上,但是受限于目标检测的结果,有可能会出现漏检或者误检情况。
自底向上的模型过程比较简单,但没有剔除背景噪声,因此,部分噪声会影响检测的结果。
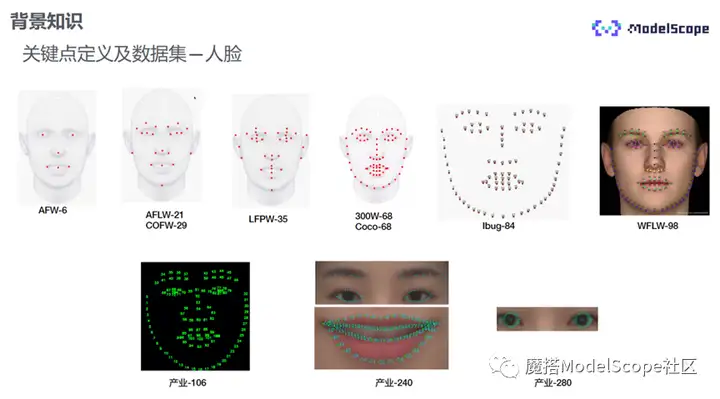
学术界常用的人脸关键点数据集如上图第一行所示,其点位标注基本集中在五官以及脸部轮廓区域,每个数据集的标注点位也各不相同。业界使用最多的是106点,240点为在106基础上眉毛、眼睛与嘴唇部位标注得更稠密,280点为在240基础上将眼珠一圈标注得更稠密。
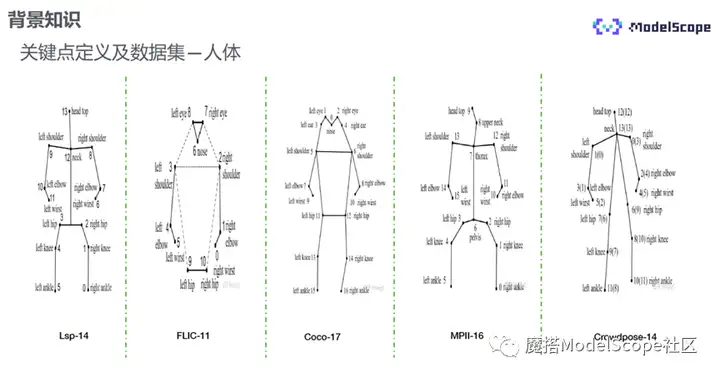
人体关键点的标注位置是人体的各个躯干以及关节,在脸头部、脖子、肚脐和脚部会略有差异。
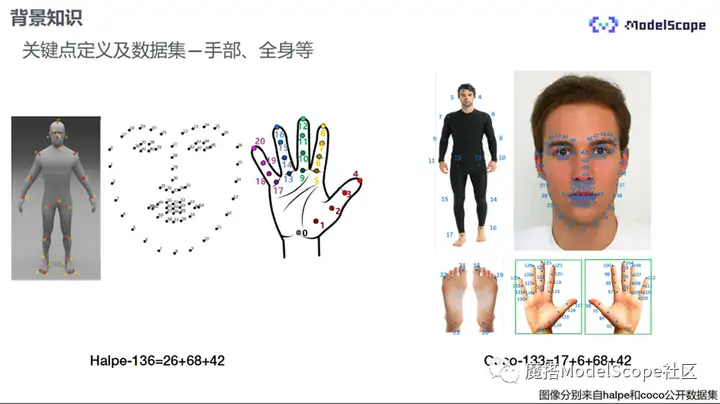
全身和手部的关键点数据集有Halpe-136he Coco-133。Halpe136包含了身体、脸部、脚底和手指的关键点。

目前,关键点检测存在的主要研究难点有:
- 环境多样性(室内室外、光照条件)、遮挡(自遮挡)、复杂姿态和角度多变等因素带来的不确定性导致漏检误检。
- 如何在保持精度不变的条件下减小模型,以适用于移动端等算力受限的场景,尤其是实时场景。
关键点检测的应用

关键点检测可以用于3D的重建、手势的重建交互、人体的重建,还可以用于当前比较火的健身动作的技术指导和AI教练。
关键点检测模型理论加实战训练

ModelScope(Model as a Service)是一个开源的模型即服务的共享平台,也是目前国内最大的AI中文论坛,提供并开源了:
① 丰富的预训练SOTA模型。
② 多元开放的数据集。
③ 简单的模型推理和fintune的能力与代码。
④ 在线的Nodebook开发平台,集成了所有需要的开发环境以及依赖库。
⑤ 可以灵活搭建AI的应用场景和解决方案,比如创空间或AdaDetection。
1. 实战案例:美颜特效
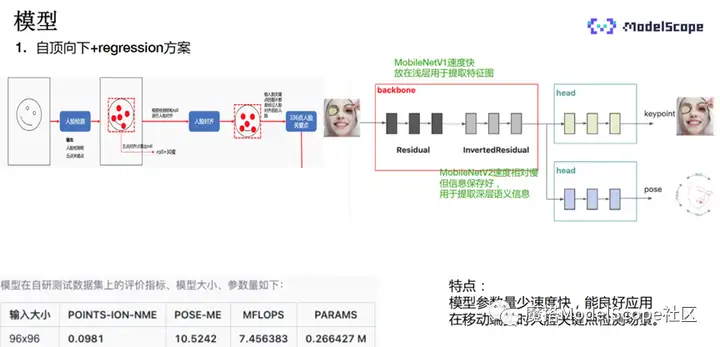
本示例选择了自顶向下+regression的方案。
上图最左侧的图像首先会经过前置网络的处理,对于输入的原始图片进行人脸检测,检测结果包含人脸框以及简单的5点关键点。将人脸单独框出之后,利用人脸的5个关键点的角度信息将人脸转正,然后送入关键点检测模型中进行关键点检测。
转正之后的人脸经过中间网络,网络结构包含backbone和两个head,backbone包含两个子模块,分别是残差模和反向残差模,主要源于MobileNetV1与MobileNetV2。残差模块的相对较小,处理速度快,放在浅层用于提取基本特征,反向残差模块较大,速度相对较慢,信息保存的程度会更好,主要用于提取深层次的语义信息。
经过前置的backbone提取后,送入后面的head模型进行关键点检测,head会输出关键点的坐标,下面的pose模块输出脸部的姿态角。
该模型的主要特点是处理速度快,可以很好地适应移动端实时的场景。
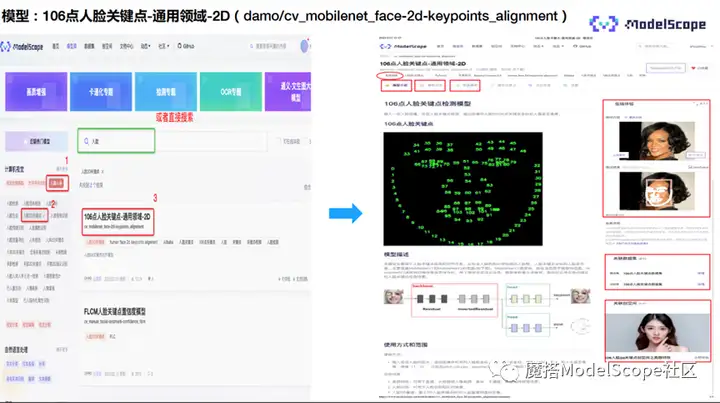
该模型已经开源至ModelScope,欢迎体验。模型的详情页面如上图所示,展示了相关标签,比如模型支持训练,属于2d人脸关键点领域模型,属于Pytorch模型等信息。往下是模型介绍以及快速使用页面。
进入ModelScope的官网,选择模型库页面的左下角近期热门模型-计算机视觉-人脸人体-人脸检测关键点,也可以在搜索框直接搜索人脸关键点。选择106点人脸关键点,进入模型介绍页面。
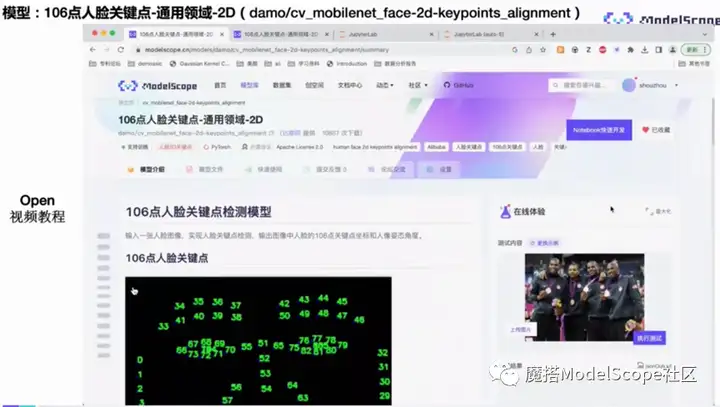
页面左侧显示了模型的基本信息、介绍、模型结构以及相关的代码范例、评价指标等,右侧为在线体验的demo,上传图片之后选择执行,将会显示检测结果。下面是关联的数据集以及关联的创空间应用。
点击右上角Nodebook快速开发,CPU和GPU环境都已经预装了ModelScope library,可以看到每一个环境的 硬件配、预装的镜像版本以及ModelScope版本。选择CPU环境,点击启动。
新建notebook页
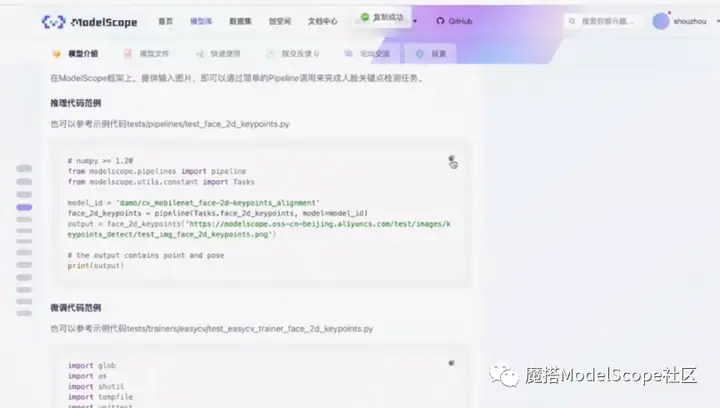
返回模型页面,复制推理代码范例粘贴至notebook。代码实现为,首先申请推理的pipeline,输入task名称以及对应的模型ID,然后将需要处理的图片传至推理pipeline,等待处理返回结果即可。图片的格式可以是网址也可以是本地图片。
运行代码。第一次运行需要申请资源、下载模型和测试图片,因此需要等待一段时间。
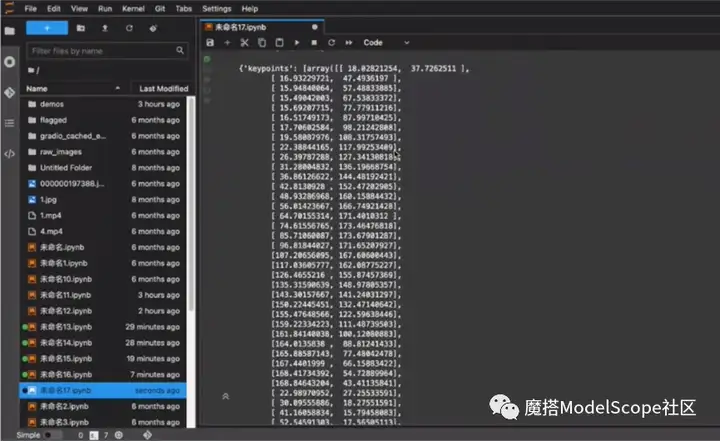
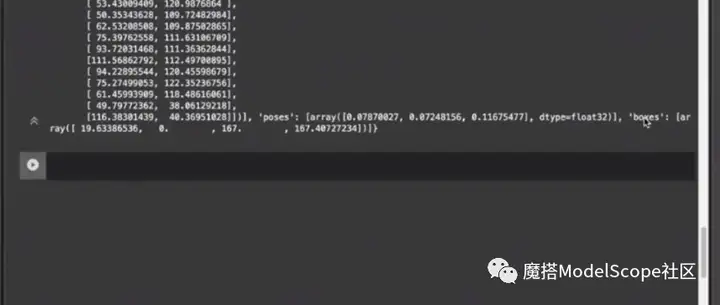
处理结果包含三个部分,keypoint关键点坐标以list的方式返回,以及pose人体的姿态角和人脸框的位置。
创空间指使用Gradio工具快速搭建可视化UI。下面将演示如何使用人脸关键点模型,快速搭建简单的可视化应用。
首先登录ModelScope官网,在页面右上角-个人信息下选择创建创空间,填入相应的信息,接入SDK选择Gradio,点击创建创空间。执行Gitclone命令,将文件下载到本地。
在编辑器中打开创空间,readme里面是基本的配置信息,entry_file是创空间的启动脚本路径,CPU和GPU是需要申请的资源数量。
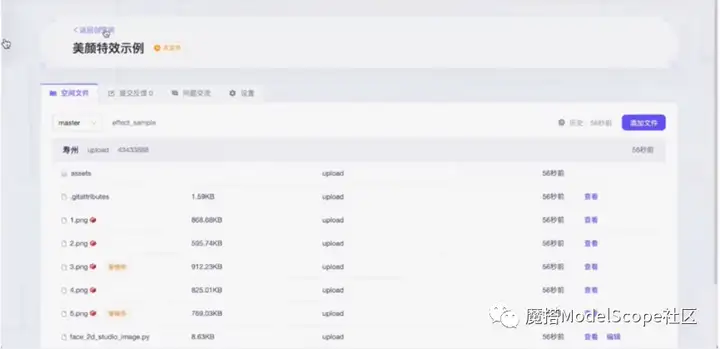
将提前准备好的readme脚本文件直接上传至空间文件。脚本文件上传到远端仓库,输入用户名和密码(复制粘贴ModelScope首页-个人信息-访问令牌里的gittoken即可)。
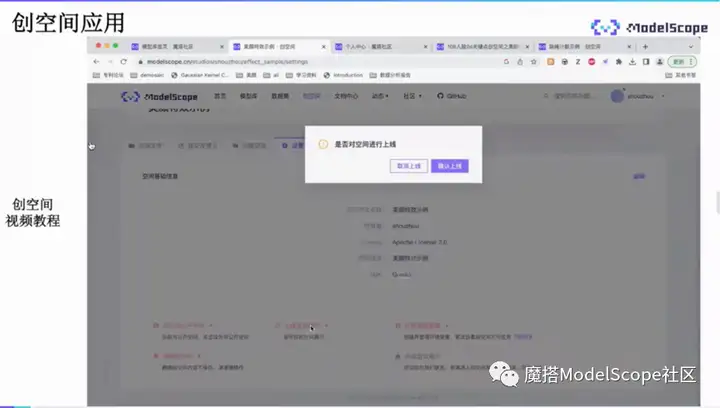
在设置tabe选择上线创空间,点击确认。
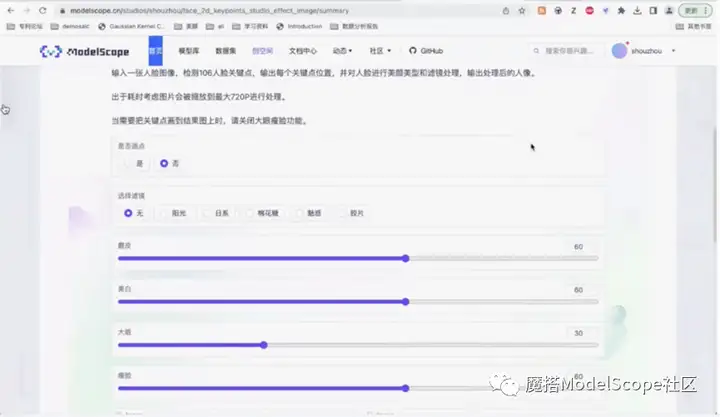
创建好后的页面如上图所示。可以选择是否画出关键点,选择不同的滤镜以及不同的程度。
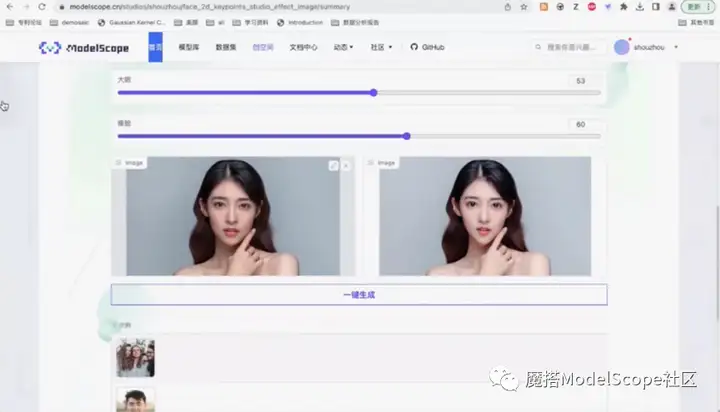
创空间运行后的效果如上图。
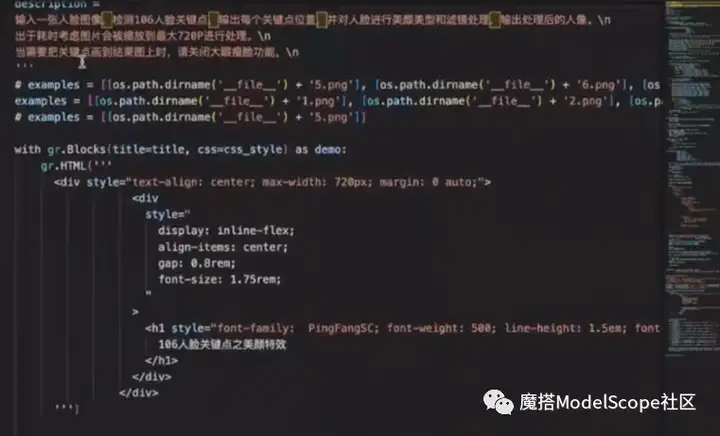
上图为通过gradio实现的UI的界面。
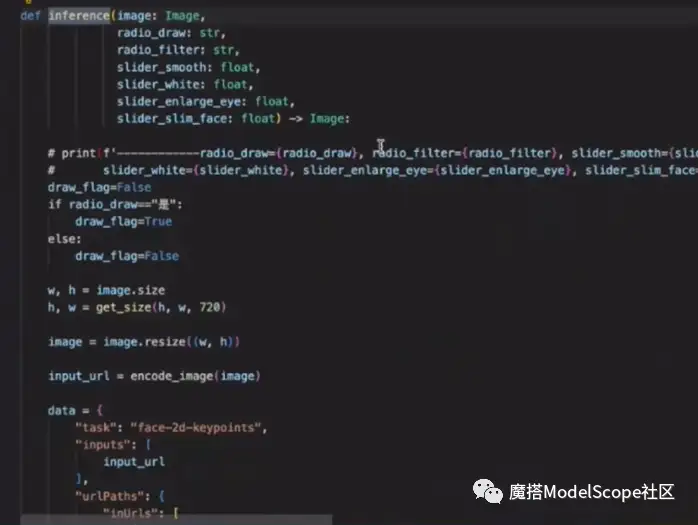
主要实现分为三步:
第一步:inference函数将输入的参数以及图像传给modelservice,将相关参数进行encode。
第二步:encode后统一打包传递给demoservice进行调用,返回检测结果,然后将检测结果送入美颜函数。
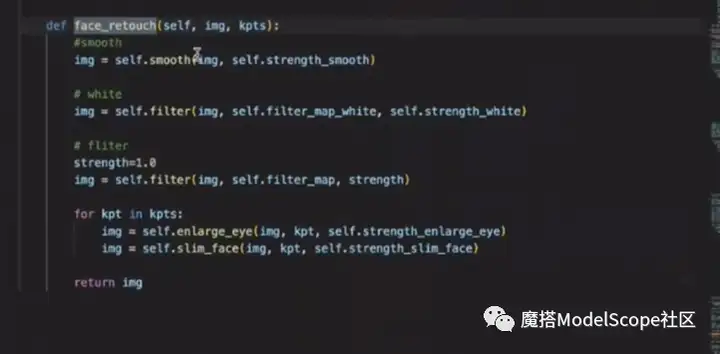
第三步:美颜函数负责进行图像的后处理,进行磨皮、美白滤镜、大眼和瘦脸相关操作。
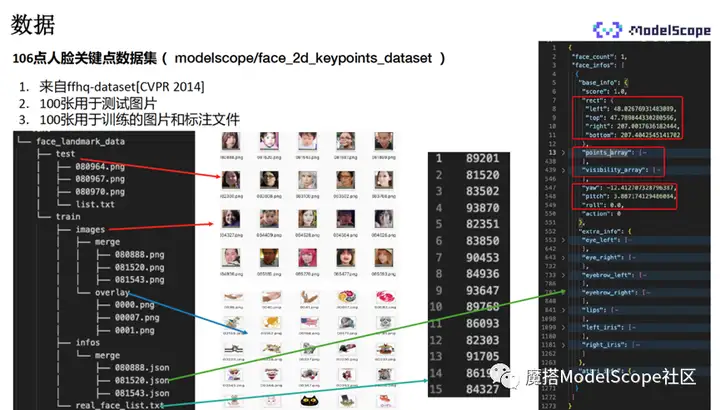
如果需要再特定场景优化检测结果,可以对模型进行fintune。
106点人脸关键点数据集来自ffhq公开的数据集,我们从中摘取了200张图片,其中100张用于测试,100张用于fintune。
数据集结构如左侧所示,包含test和train的文件夹。text是测试数据集,包含图像以及list的文件(内保存了图像的名称),训练文件夹包含了image子文件夹以及info子文件夹。
image文件夹下包含merge和overlay,merge里保存了训练需要使用的图像,overlay内保存了没有人脸的图像,主要用于增加数据训练数据的多样性,用于与前景图片做合成,作为背景使用。
info下的merge文件夹保存了标注的数据,是名称与训练图片一致的JSON文件。JSON文件的数据结构如最右所示,包含人脸框上下左右的坐标,关键点的位置(106*2的list),以及关键点的可见性属性(是否被遮挡)。
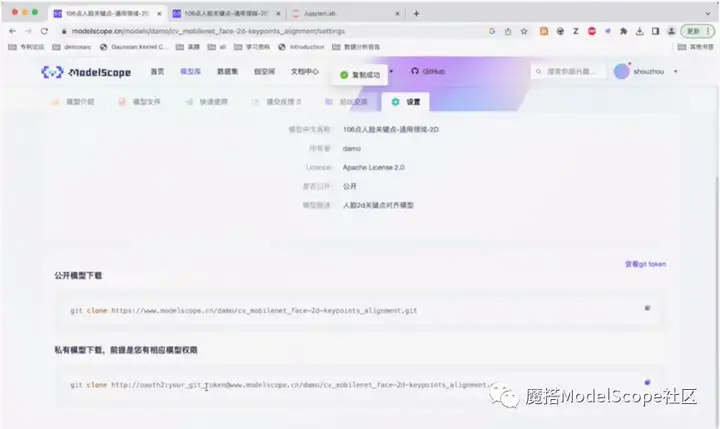
finetune需要使用的参数可以在模型仓库的配置文件中找到,选择设置页面下的下载命令,执行之后即可将仓库下载到本地。
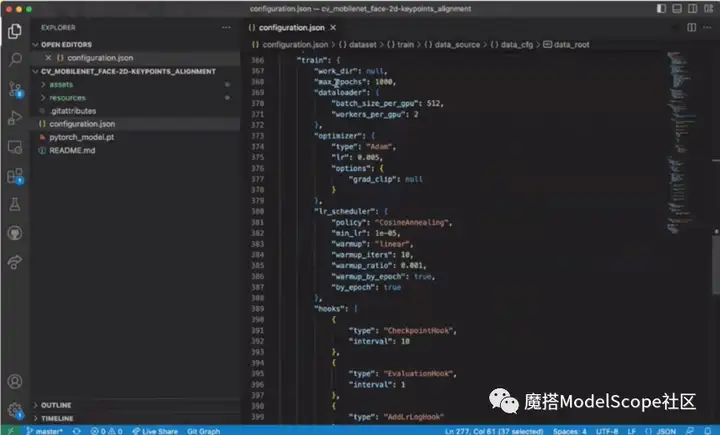
在编辑器中打开config文件,里面包含模型相关的参数信息、数据集相关的参数信息以及训练过程中的参数,比如epoch、batch、size、log以及learningrate与优化策略等信息。
返回模型页面,选择右上角nodebook开发,选择GPU环境,点击左下角启动。
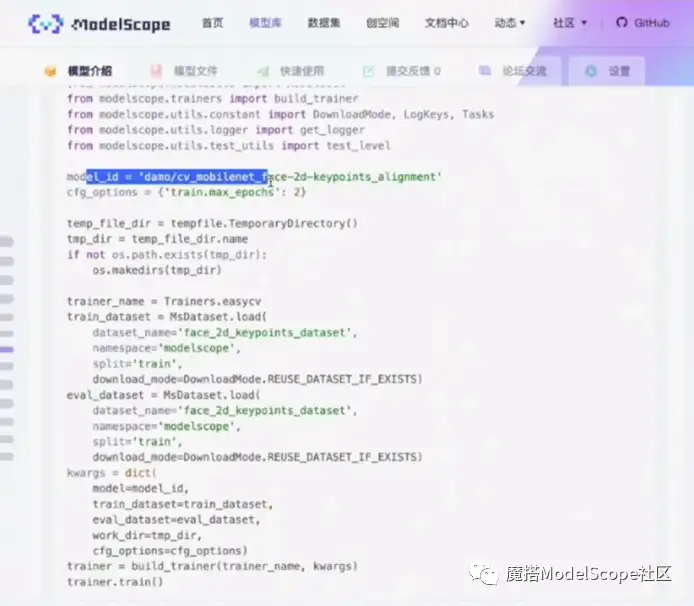
新建页面后,返回模型页面复制微调代码范例。
首先,传入模型ID,在模型仓库中配置文件,config里的所有参数都可以通过cfg_options的方式进行修改,最后通过总的字典传入trainer类。比如这里设置epochs数为2。新建临时目录,用于存放训练的参数以及log信息。
往下是数据集加载的命令,将总的参数通过字典的形式传给trainer,初始化trainer的类,最后调用trainer.train()启动训练。训练完成之后,所有参数以及log信息都会保存在临时路径下。

本示例中,示例代码被保存在临时目录中,最后临时目录会被删除。实际操作时建议将删除语句注释掉。
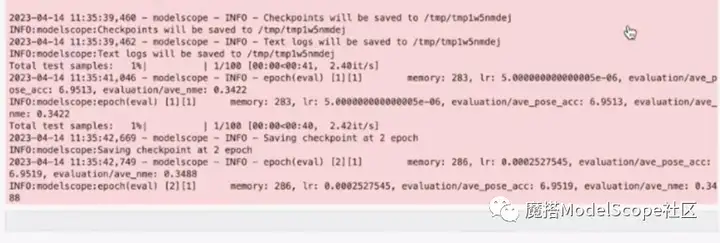
训练完成后,代码显示如上图。
实战案例:跳绳计数
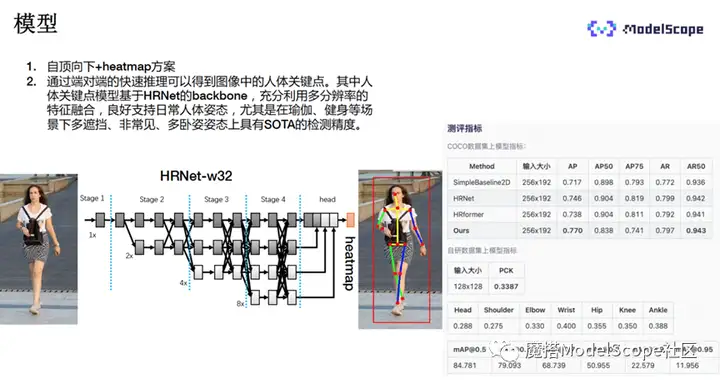
本示例主要使用自顶向下+heatmap的方法。
backbone主要采用HRNet,输入的图像经过人体检测后送入HRNet模型,模型提供了多尺度的操作。经过head结构,将四个不同分辨率的feature结合在一起,输出最终的heatmap,送入后处理的decode过程,比如使用argmax提取heatmap图像上的最大值位置当中的关键点作为输出。
该模型的好处是可以端到端地做人脸关键点的检测。HRNet充分利用多分辨率,融合了不同size上的特征,再加上训练集补充了很多日常的健身动作、瑜伽动作等场景数据,能良好地支持人体的姿态以及瑜伽健身场景下比较tough的案例。
右侧表格数据显示,该模型在Coco的开源数据集上也取得了比较不错的结果。
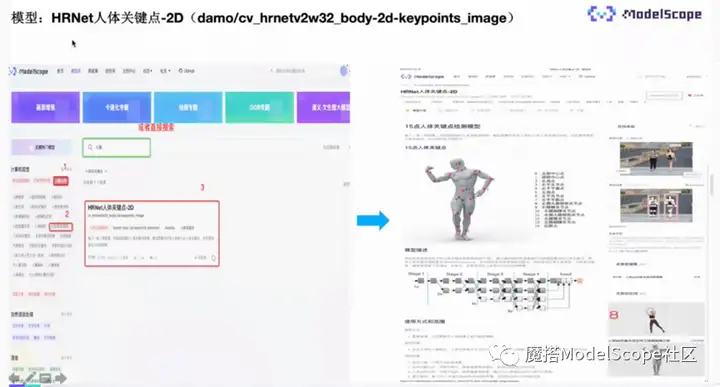
该模型已经开源至ModelScope,欢迎搜索体验。右下角关联了基于视频的跳绳应用以及单帧图片的人体关键点检测。
下面将演示人体关键点模型推理的使用方法。
首先登录ModelScope官网,搜索HRNet人体关键点-2D。点击右上角的nodebook快速开发,选择DSW-CPU环境,点击左下角启动。
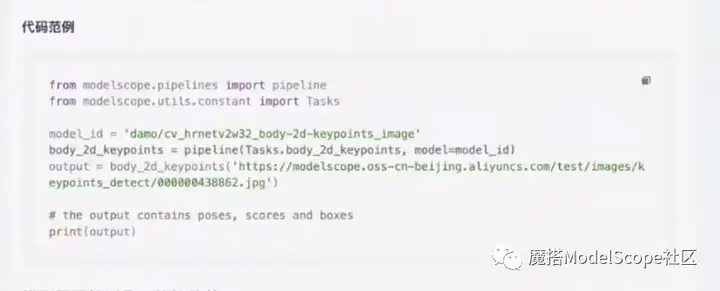
新建页面,复制模型页面的范例代码粘贴到Nodebook执行。
首先申请检测的pipeline,输入两个参数,分别是task名称以及modelID。将需要检测的图片地址传给检测的pipeline,即可进行检测。地址可以是网页链接,也可以是本地图片的路径。
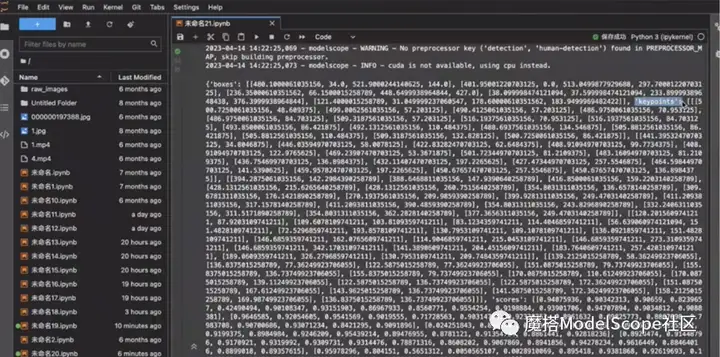
返回结果如上图,包含人体框的位置信息、关键点坐标的信息以及关键点score。
下文将演示如何使用人体关键点快速搭建一个基于视频的可视化应用。
登录ModelScope官网,在页面左上角-个人信息下选择创建创空间,填入相关的信息,接入SDK选择gradio,创建创空间。
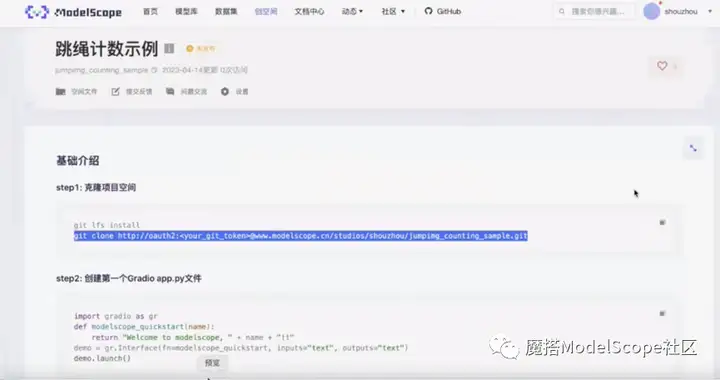
克隆项目空间,将空间下载到本地。
将已经创建好的脚本拷贝到空间目录下,用户名和密码在首页-个人信息-访问令牌。
返回到设置页面,点击上线空间展示。
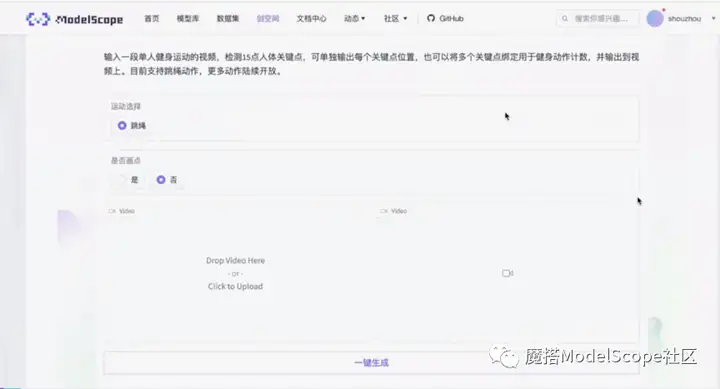
上线后的界面如上图,选择sample视频,点击一键生成。
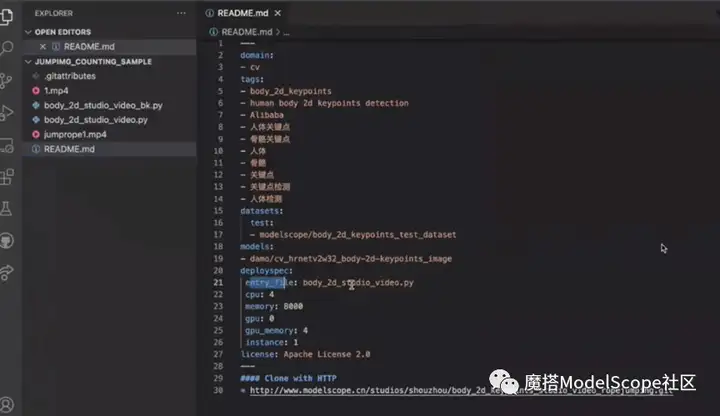
在编辑器中打开创空间,readme里面是基本的配置信息,entry_file是创空间的启动脚本路径,CPU和GPU是需要申请的资源数量。
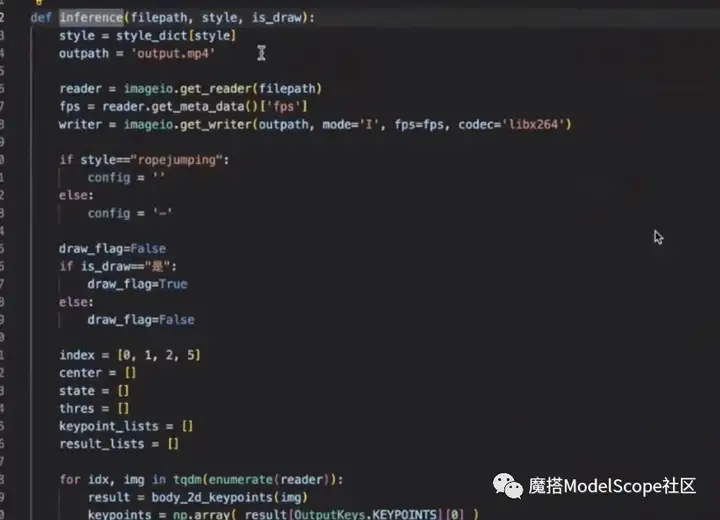
代码实现为:调用inference函数,将传入的视频分解成一帧一帧的图像,对每一帧图像进行关键点检测,检测结果统一保存。
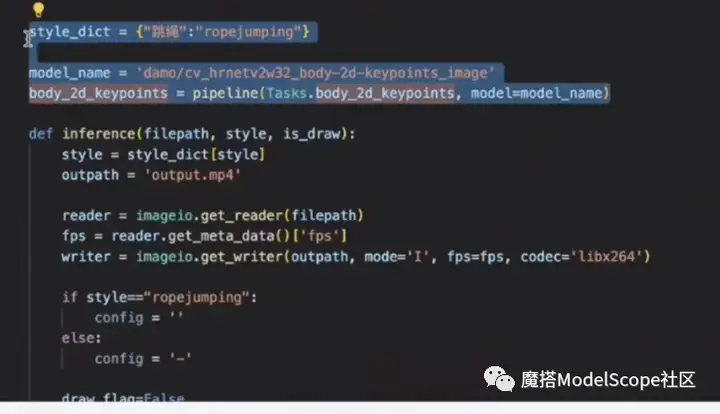
调用modelservice上的推理pipeline代码,进行关键点的检测。检测之后,将所有关键点缓存到list中,并对关键点做平滑处理,消除抖动。然后调用count函数,对关键点的序列进行计数操作。
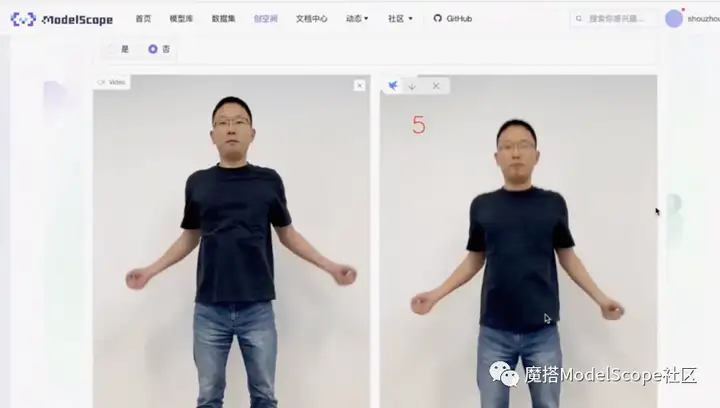
最后将跳绳计数合成在返回图像上,合成最终视频,如上图所示。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 2
2 0
0- 0



 已为社区贡献651条内容
已为社区贡献651条内容

所有评论(0)