


近年来,NLP的发展可谓日新月异,过去大家都在自己的细分领域中默默耕耘,比如做分类、匹配的同学研究Bert+MLP;做NER、序列标注的同学折腾BERT+CRF;做翻译、摘要的同学捣鼓Encoder-Decoder框架;那种勃勃生机,万物竞发的场景犹在眼前。
但是,自2020年以来,通用模型已逐渐成为了新的趋势,即把多种自然语言处理任务的能力集成到了一个模型之中。实践证明,通过多任务学习交互往往可以提高模型效果,同时也可显著减少模型开发和应用成本,为开发者和用户都提供了极大便利。
生成 VS 抽取
生成式:
模型自主生成一段基于输入的结果,优势是灵活度高,只要能在输入文本和相应Prompt中清晰说明任务需求即可。劣势是由于结果是自由生成,不与输入严格绑定,因此生成结果不稳定,可能会产生无效结果;且输出需要逐字解码,推理速度较慢。
抽取式:
模型输出结果完全来自于输入内容片段,优势是输出结果稳定。劣势是每次推理时都需要推理n个样本(其中n为标签数量),因此模型推理时间随标签数量线性增长。
生成虽“秀”,抽取更“稳”
在实际生产环境中,对模型输出结果的稳定性往往具有更高的要求,因此,达摩院自然语言智能团队提出了基于「抽取解码」的自然语言理解架构SiamesePrompt,系列模型也在ModelScope进行了开源,开源模型是:
-
零样本自然语言理解SiameseUniNLU
-
零样本通用信息抽取SiameseUIE
-
零样本属性情感抽取SiameseAOE
SiamesePrompt系列模型,基于提示(Prompt)+文本(Text)的构建思路,通过设计适配于多种任务的Prompt,并利用指针网络(Pointer Network)实现片段抽取(Span Extraction),从而实现对自然语言理解全任务的统一处理,在通用性、推理效率、推理精度方面效果都有显著提升。
不仅涵盖了UniMC和DuUIE中提到的所有任务,还通过递归解码支持任意元组(四元组、五元组等)的信息抽取任务;
在零样本情况下,F1 Score较竞品模型提升24.6%,在少样本情况下(去除了部分数量较少的数据集)提升3-5个百分点;
通过Siamese Network结构,将推理速度提升了30%。
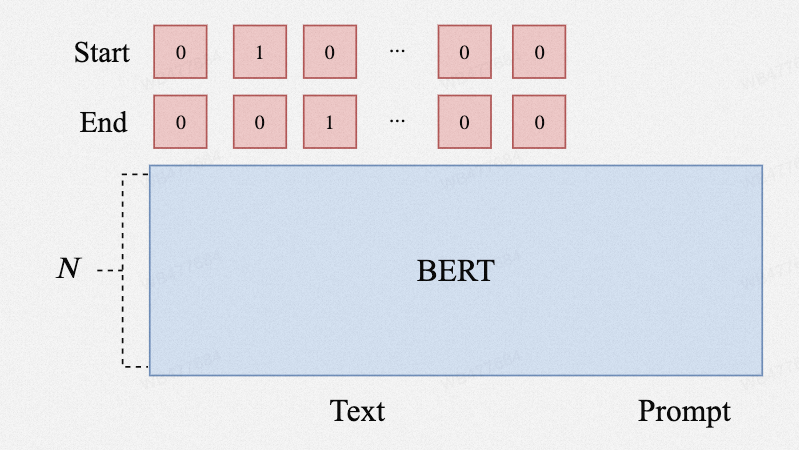
SiamesePrompt架构
在传统的MRC架构中,当我们有多个Prompt时,需要将待推理的Prompt逐个枚举,依次和Text交互,从而获取最终的隐向量表示,这样的一个缺点是Text需要反复编码,因此推理时间和Prompt数量成正相关。
孪生神经网络(Siamese neural networks)是一类神经网络模型,它的基本思想是将两个相同结构的神经网络共享参数,然后将它们分别应用于输入数据,通常用于度量两个输入之间的相似度或差异性。
近年来的研究表明,底层Transformer其实更多的是Local信息的交互,上层才是Global信息的交互,因此,我们将语言模型的前N-n层改为孪生神经网络,将Prompt和Text单独编码,仅让它们在后n层再做融合交互。这样一来,Text的前N-n层的向量表示,我们就可以反复使用。由于Text的长度往往远大于Prompt,因此可以大幅缩短推理时间。
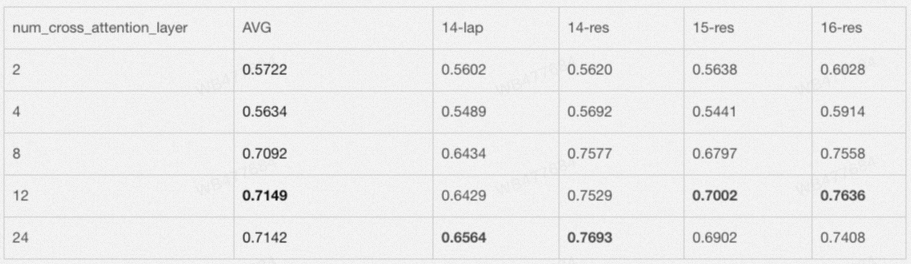
想法验证
为了证实我们的猜想,我们进行了初步的实验验证,我们在四个ABSA数据集上进行实验,最终发现,对于24层transformers的Roberta-large模型,只需要保留8层的Cross-Attention Layer就可以几乎齐平传统MRC(24层Cross-Attention Layer)的效果。
模型实战
安装ModelScope
依据ModelScope的介绍,实验环境可分为两种情况。在此推荐使用第2种方式,点开就能用,省去本地安装环境的麻烦,直接体验ModelScope。
本地环境安装
可参考https://www.modelscope.cn/docs/%E7%8E%AF%E5%A2%83%E5%AE%89%E8%A3%85
Notebook
ModelScope直接集成了线上开发环境,用户可以直接在线训练、调用模型。
打开模型页面,点击右上角“在Notebook中打开”,选择机器型号后,即可进入线上开发环境。
SiameseUIE通用信息抽取模型
模型介绍
SiameseUIE通用信息抽取模型,支持命名实体识别(NER)、关系抽取(RE)、事件抽取(EE)、属性情感抽取(ABSA)等多类任务的抽取。和市面上已有的通用信息抽取模型不同的是:
- 更通用:SiameseUIE基于递归的训练推理架构,不仅可以实现常见的NER、RE、EE、ABSA这类包含一个或两个抽取片段的信息抽取任务,也可以实现包含更多抽取片段的信息抽取任务,例如:比较观点识别五元组任务等等,因此更为通用,几乎可以解决所有的信息抽取问题;
- 更高效:SiameseUIE基于孪生神经网络的思想,将预训练语言模型(PLM)的前 N-n 层改为双流,后 n 层改为单流。我们认为语言模型的底层更多的是实现局部的简单语义信息的交互,顶层更多的是深层信息的交互,因此前N-n层不让Prompt和Text做过多的交互,而是分别单独编码,同时将前N-n层Text的隐向量表示缓存下来,实现将推理速度提升30%;
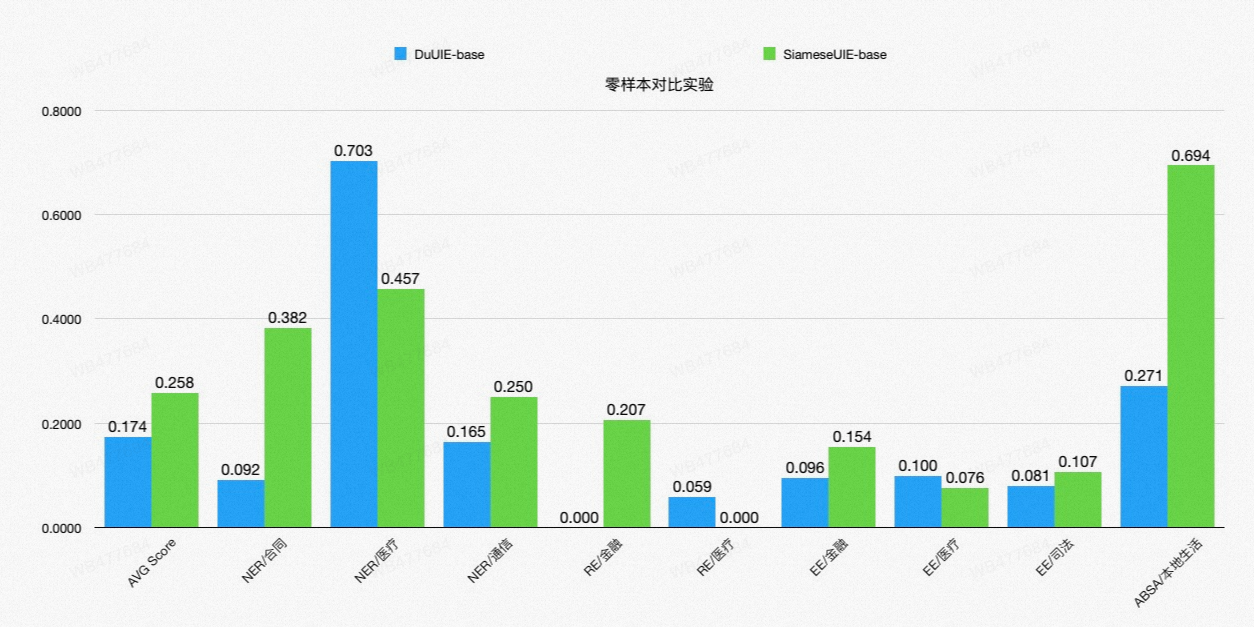
- 更精准:我们在4类任务、6个领域、9个数据集上进行了测试,在零样本情况下,F1 Score较竞品模型提升24.6%,在少样本情况下(去除了部分数量较少的数据集)提升3-5个百分点;数据评估及结果
我们在4类任务、6个领域、9个数据集上进行了测试,我们选择DuUIE作为Baseline,在零样本情况下,F1 Score较DuUIE模型提升24.6%;
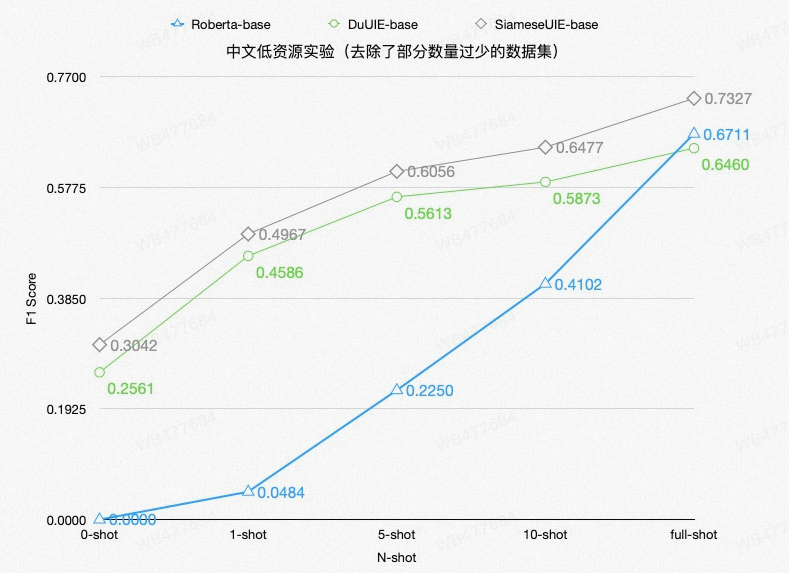
在少样本情况下(去除了部分数量较少无法微调的数据集)F1 Score较竞品模型提升3-5个百分点;
加载模型
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
semantic_uie = pipeline(Tasks.siamese_uie, 'damo/nlp_structbert_siamese-uie_chinese-base', model_revision='v1.0')模型调用
与一般的文本分类模型不同,SiamesePrompt系列模型可以自定义标签(但注意需要按照给定格式),模型将根据给定的标签执行抽取任务。以实体抽取任务为例,构造方式为{实体类型: None}:
schema={
'人物': None,
'地理位置': None,
'组织机构': None
}接着,调用模型:
semantic_uie(
input='1944年毕业于北大的名古屋铁道会长谷口清太郎等人在日本积极筹资,共筹款2.7亿日元,参加捐款的日本企业有69家。',
schema=schema
)返回结果为:
{
'output': [
[{
'type': '人物',
'span': '谷口清太郎',
'offset': [18, 23]
}],
[{
'type': '地理位置',
'span': '日本',
'offset': [26, 28]
}],
[{
'type': '地理位置',
'span': '日本',
'offset': [48, 50]
}],
[{
'type': '组织机构',
'span': '北大',
'offset': [8, 10]
}],
[{
'type': '组织机构',
'span': '名古屋铁道',
'offset': [11, 16]
}]
]
}类似地,对于关系抽取、事件抽取、属性情感抽取任务都有相应的标签构造模版,只要按照模版构造好所需要的标签,就可以让调用模型的不同能力,实现不同需求。
示例
在ModelScope平台上,也可直接调用模型示例感受效果,非常地方便,展示如下:
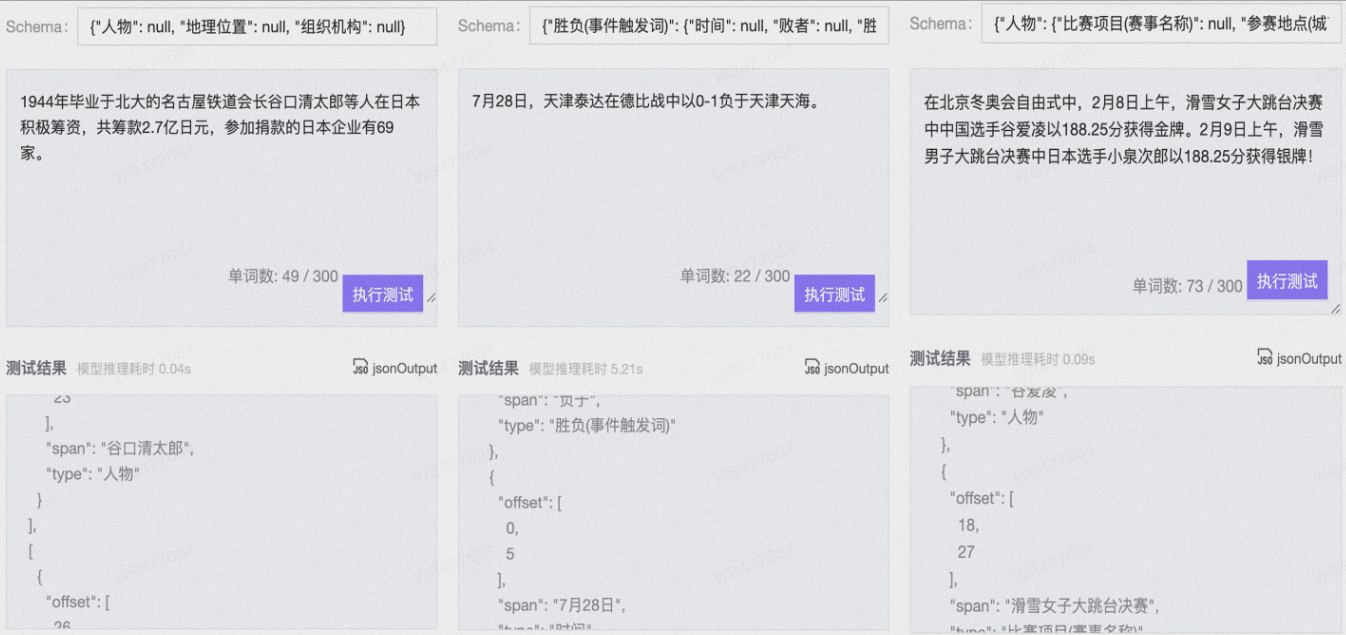
SiameseUniNLU通用自然语言理解模型
模型介绍
SiameseUniNLU通用自然语言理解模型,支持命名实体识别、关系抽取、事件抽取、属性情感抽取、情感分类、文本分类、指代消解、文本匹配、自然语言推理、阅读理解等多类任务,为几乎所有非生成式自然语言理解任务提供了统一的解决方案,其特点为:
更通用:UniNLU为各种理解类任务都设计了相应适配的Prompt,并通过大量训练,使得一个模型几乎可以解决所有自然语言理解类任务,支持的任务包括:
- 命名实体识别:抽取输入文本中的实体片段
- 关系抽取:抽取输入文本中具备特定关系类型的主客实体片段
- 事件抽取:抽取输入文本中相互联系的事件论元片段
- 属性情感抽取:抽取输入文本中特定对象的相关情感词片段
- 指代消解:判断给定代词是否指向文中的某一对象
- 情感分类:给定一段文本和候选情感标签,返回可以恰当表示该段文本情感倾向的标签
- 文本分类:给定一段文本和候选类别标签,返回可以恰当表示该段文本所属类别的标签
- 文本匹配:给定两段文本和相应相似度标签,返回可以恰当表示两段文本相似度的标签,文本相似度标签通常为“相似”,“不相似”两种
- 自然语言推理:给定两段文本和相应文本关系标签,返回可以恰当表示两段文本关系的标签,文本关系标签通常为“蕴含”,“矛盾”,“中立”三种
- 阅读理解:输入问题及参考文本,返回基于该段参考文本的问题答案,通常分为选择类阅读理解和抽取类阅读理解
更高效:与Siamese-UIE类似,基于孪生神经网络的思想,实现推理提速30%;
更精准:我们在10类任务、6个领域、15个数据集上进行了测试,在零样本和少样本两个设定下都远超PCLUE1.5的表现;
我们从自建数据集(10类任务、6个领域、15个数据集)和P-CLUE榜单两个数据集上验证了我们模型在自然语言理解数据上的表现:
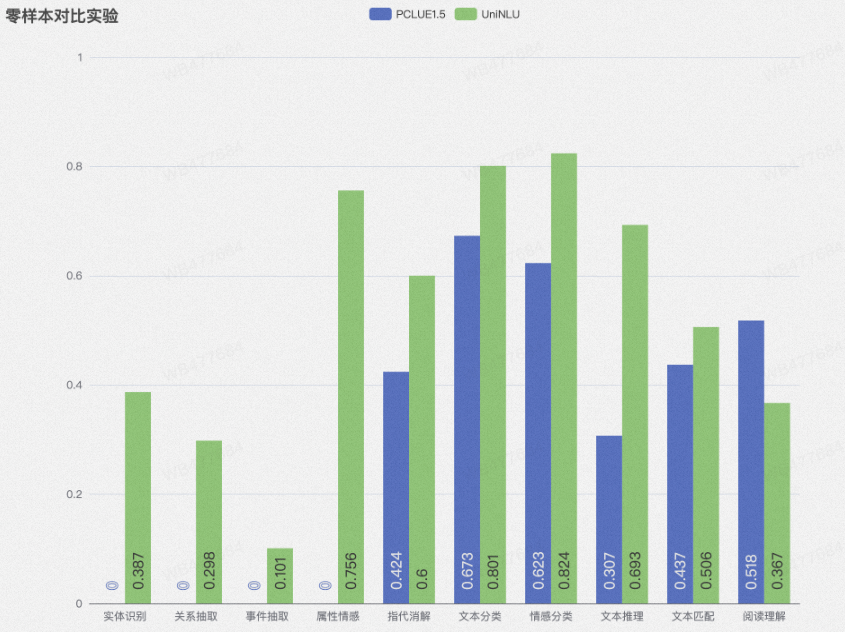
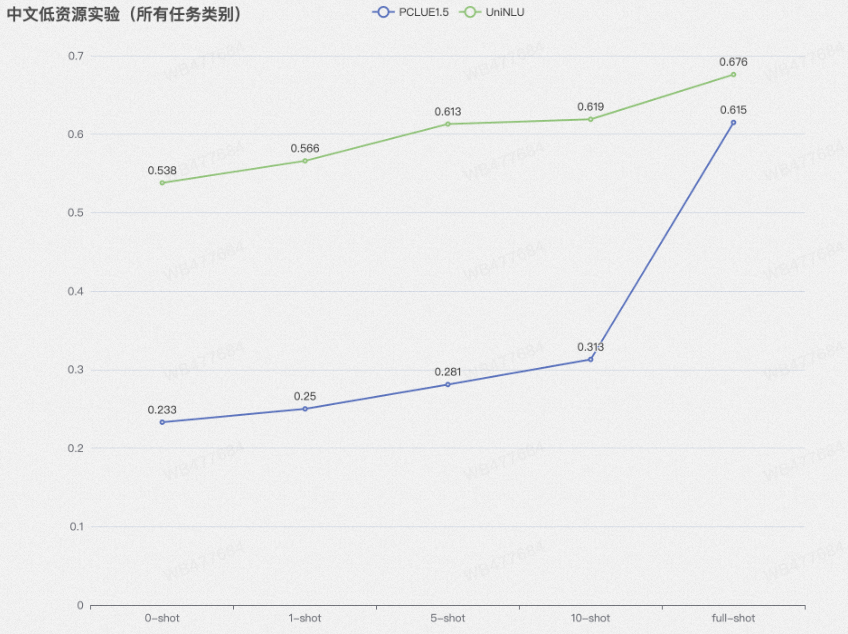
P-CLUE榜单:

我们在推理数据集上达到了榜单SOTA,分类F1页超过了PromptCLUE V1.5的表现,在阅读理解数据集上,由于存在一部分生成式阅读理解任务(SiamesePrompt架构不能做生成任务),因此表现欠佳。
加载模型
使用以下三行命令即可加载SiameseUniNLU模型
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
semantic_nlu = pipeline(Tasks.siamese_uie, 'damo/nlp_structbert_siamese-uninlu_chinese-base', model_revision='v1.0')模型调用
类似地,SiameseUniNLU模型同样可以自定义标签(再次强调要按照给定格式哦),模型将根据给定的标签执行抽取任务。以分类任务为例,文本标签通过英文逗号“,”隔开,拼接在输入文本前面并用“|”分隔,schema构造方式如下,调用模型:
semantic_nlu(
input='民生故事,文化,娱乐,体育,财经,房产,汽车,教育,科技,军事,旅游,国际,证券股票,农业三农,电竞游戏|学校召开2018届升学及出国深造毕业生座谈会就业指导',
schema={
'分类': None
}
)返回结果为:
{
'output': [
[
{
"offset": [
23,
25
],
"span": "教育",
"type": "分类"
}
]
]
}对其他任务也各自按照相应方式构造输入样例即可
示例
模型调用方式与SiameseUIE类似,这里分别展示情感分类,文本匹配,抽取式阅读理解,选择式阅读理解,文本分类,关系抽取任务几个测试样例结果
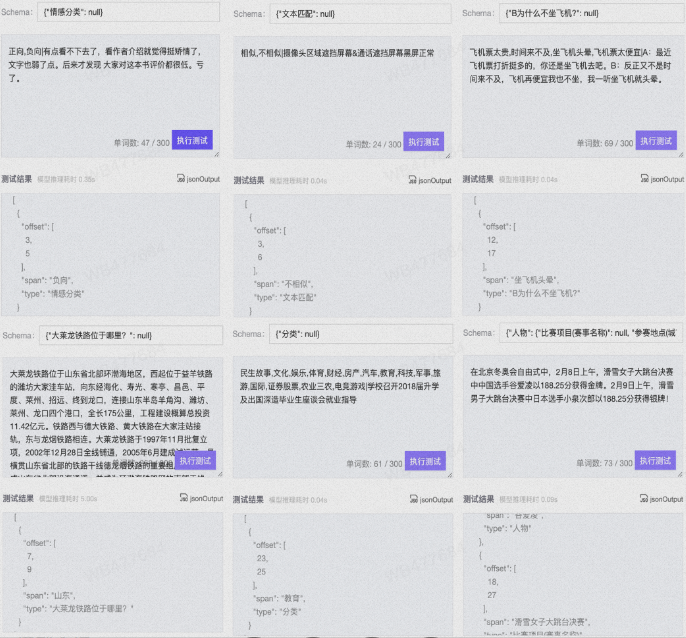
SiameseAOE通用属性情感抽取模型
模型介绍
SiameseAOE通用属性情感模型,是SiamesePrompt系列专门针对属性情感抽取任务的版本,通过在500w条ABSA标注数据集进行预训练得到,在自建测试集上F1达到了0.808。
可支持各类属性情感抽取任务,尤其在商品评价解析领域,能够帮助用户和商家快速把握商品特征和评价反馈。
模型特征和调用方式这里就不赘述了,和上面两个模型都类似,反正就是好用,直接上具体例子吧。
加载模型
使用以下三行命令即可加载SiameseAOE模型
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
semantic_aoe = pipeline(Tasks.siamese_uie, 'damo/nlp_structbert_siamese-aoe_chinese-base', model_revision='v1.0')模型调用
重要内容说三遍,按照给定格式输入内容,schema按照{属性词: {情感词: None}}方式构造,调用模型:
semantic_aoe(
input='很满意,音质很好,发货速度快,值得购买',
schema={
'属性词': {
'情感词': None,
}
}
)输出结果
{
'output': [
[{
'type': '属性词',
'span': '音质',
'offset': [4, 6]
}, {
'type': '情感词',
'span': '很好',
'offset': [6, 8]
}],
[{
'type': '属性词',
'span': '发货速度',
'offset': [9, 13]
}, {
'type': '情感词',
'span': '快',
'offset': [13, 14]
}]
]
}示例

总结
我们这次推出的SiamesePrompt系列模型在模型效果上显著领先于竞品模型,并在部分任务上达到SOTA效果;在任务广度上实现了更全面的统一,涵盖了几乎所有的非生成类自然语言理解任务;同时在推理速度上也实现了明显提升。
SiameseUIE
https://modelscope.cn/models/damo/nlp_structbert_siamese-uie_chinese-base/summary
SiameseUniNLU
https://modelscope.cn/models/damo/nlp_structbert_siamese-uninlu_chinese-base/summary
SiameseAOE
https://modelscope.cn/models/damo/nlp_structbert_siamese-aoe_chinese-base/summary
参考文献
[1] Leveraging Local and Global Patterns for Self-Attention Networks(Xu et al., ACL 2019)
[2] A Unified MRC Framework for Named Entity Recognition(Li et al., ACL 2020)
[3] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(Raffel et al., Journal of Machine Learning Research 2020)
[4] Training language models to follow instructions with human feedback(Ouyang et al., 2022)
[5] Unified Structure Generation for Universal Information Extraction(Lu et al., ACL 2022)
[6] Zero-Shot Learners for Natural Language Understanding via a Unified Multiple Choice Perspective(Yang et al., EMNLP 2022)
[7] https://openai.com/research/instruction-following
[8] https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
[9] https://github.com/CLUEbenchmark/pCLUE






 已为社区贡献598条内容
已为社区贡献598条内容

所有评论(0)