
ModelScope语义匹配-预训练语言模型文本检索
##0. 引言 文本语义匹配是信息检索领域的核心问题, 其在很多信息检索、NLP下游任务中发挥着非常重要的作用。 近几年, BERT等大规模预训练语言模型的出现使得文本表示效果有了大幅度的提升, 基于预训练语言模型构建的文本检索系统在召回、排序效果上都明显优于传统统计模型。结合阿里集团内外部业务对语义匹配、文本检索的技术需求,本文主要以文本搜索任务为背景介绍预训练语言模型在召回和排序阶段的优化策略
##0. 引言
文本语义匹配是信息检索领域的核心问题, 其在很多信息检索、NLP下游任务中发挥着非常重要的作用。 近几年, BERT等大规模预训练语言模型的出现使得文本表示效果有了大幅度的提升, 基于预训练语言模型构建的文本检索系统在召回、排序效果上都明显优于传统统计模型。结合阿里集团内外部业务对语义匹配、文本检索的技术需求,本文主要以文本搜索任务为背景介绍预训练语言模型在召回和排序阶段的优化策略。同时,为了更好的推动中文垂直领域文本检索的研究,达摩院基础NLP团队也联合阿里集团多个搜索团队发布中文多领域文本检索数据集Multi-CPR(相关论文已被SIGIR 2022录用)。基于不同中英文领域数据训练的召回、排序模型也已经通过ModelScope魔搭平台对外开源, 欢迎大家下载使用,一起交流探讨。
1.文本检索背景介绍
1.1 任务定义
文本检索任务可以定义为: 给定一个文档集合,用户输入一个query来表达信息检索需求,借助于一个文本检索系统返回相关文档给用户。日常生活中,我们几乎天天都在用文本检索系统,比如谷歌、百度搜索,淘宝电商搜索,搜索系统已经成为用户获取信息的一个重要入口。对于文本检索任务,抽象出来的核心目标就是怎么去计算用户输入的 query和文档集合中每个doc的文本相似度。
1.2 预训练语言模型在文本检索中的应用
度量用户输入query和doc之间的文本相似度的过程通常包含: 1) 文本表示 2) 相似度计算。传统的基于统计模型的文本检索系统通常都是基于字面匹配来计算相关性, 例如BM25算法, 在统计模型中文本通常被表示成离散的向量。近几年,随着深度学习模型的发展、尤其是预训练语言模型的出现大幅提升了文本向量表示模型的效果。在文本检索领域也开始有研究关注如果利用预训练语言模型来提升文本检索系统的效果。
由于文档候选集合通常比较庞大,实际的工业搜索系统中候选文档数量往往在千万甚至更高的数量级, 为了兼顾效率和准确率,目前的文本检索系统通常是基于召回&精排的多阶段搜索框架。在召回阶段,系统的主要目标是从海量文本中去找到潜在跟query相关的文档,比如候选集合存在1亿doc,召回阶段可能只召回5000个doc。召回完成后, 精排阶段的模型会对这些召回的候选文档进行更加复杂的排序, 产出最后的排序结果。
双塔模型(Dual-Encoder)
考虑到计算效率, 目前召回阶段的主流模型是基于预训练语言模型双塔模型,双塔模型将query和doc编码成连续的向量表示, 之后基于两个向量表示计算向量相似度(例如通过cosine similarity)。在实际的检索系统中,doc集合的向量可以离线预先计算好,利用Proxima、Faiss等向量引擎构建索引。在检索过程中,只需要实时计算query的向量表示即可进行查询。
交互模型(Cross-Encoder)
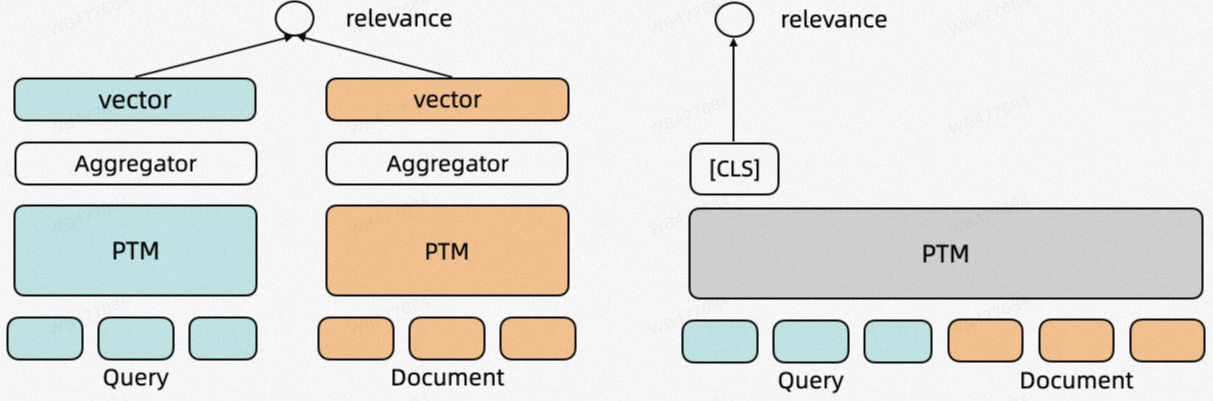
交互模型和双塔模型一样,目标都是建模query和doc的语义相似度。区别在于交互模型输入是Query和Doc拼接得到的文本,最终通过[CLS]位置的表示+线性层计算最终的相关性得分。由于Transformer模型的全连接注意力结构,交互模型建模Query与Doc的之间每个token粒度的相似度特征,对比双塔模型在语义相似度计算上的效果更优。但是,交互模型需要对每个Query-Doc对独立计算相关性分数, 且Doc侧的特征无法预先计算,因此其计算效率更低,所以更适用于用来计算小规模候选集和Query之间的相关性(精排阶段)。
在实际应用中, 不论是训练双塔模型还是交互模型, 核心包括三个要素
1.训练数据, 形式表现为标注的Query-Doc相关性pair, 包括正样本和负样本, 其中负样本非必须
2.预训练语言模型底座, 例如BERT、StructBERT模型
3.Fine tuning方法: 训练策略, 例如损失函数设计等
图1 基于预训练语言模型的双塔模型(左)、交互模型(右)
在实际应用中, 不论是训练双塔模型还是交互模型, 核心包括三个要素
1.训练数据, 形式表现为标注的Query-Doc相关性pair, 包括正样本和负样本, 其中负样本非必须
2.预训练语言模型底座, 例如BERT、StructBERT模型
3.Fine tuning方法: 训练策略, 例如损失函数设计等
图2 预训练语言模型文本检索模型训练要素
基于预训练语言模型的文本检索系统,目前的学术界研究优化的方向也主要集中在以下几个对应的方向:
1.构造更好的训练数据: 例如可以采用微软提出的ANCE[10]的方法迭代式的挖掘难负样本,RocketQA[5]提出的对噪音样本进行过滤筛选等
2.设计针对文本检索场景的预训练模型: 通用的BERT、StructBERT、RoBERTa模型主要还是针对更广泛下游NLU任务设计的,针对文本检索任务的特性设计预训练范式获取更适配下游任务的预训练语言模型底座也是目前主要的优化方向,这里面比较有代表性的工作包括Condenser模型[4]、coCondenser模型[1]、BPROP模型[5]等
3.训练方法: 比较早期的文本向量召回工作DPR论文[9]里面提出的in-batch Negative Loss现在仍然被广泛应用,近期学术界又有一些新的针对损失函数设计、多视角表示[11]训练方法的优化方案
2.预训练语言模型召回
2.1 ROM模型优化思路
本章节将介绍我们团队在针对向量召回场景预训练语言模型底座优化。如前面章节介绍, 通用的语言模型不是为了文本检索场景而设计的, 那怎么样才能让语言模型底座更好的适配文本检索任务呢?
● 语言模型训练中masked language model(MLM)是一个最常用的无监督预训练任务, MLM任务中, 输入句子中一定比例的token会被随机替换成特定的mask字符"[MASK]", 这部分被mask掉的token在输出端会作为预测的目标。我们统计发现, 随机mask策略产出的mask token中, 将近40%的比例是停用词(中英文比例类似)。结合在统计检索模型中的经验,这部分停用词对文本召回任务的贡献是微弱的、甚至是负面的。我们希望预训练语言模型可以更多的学习、关注高权重的term, 这既可以加速预训练过程的效率,也使得训练的得到的预训练语言模型更加贴合文本召回任务。
● 向量召回场景下本质还是训练一个文本表示模型,我们通常会采用[CLS]位置的向量作为最终的文本表示。近期的一些无监督文本表示工作例如SimCSE[12]也启发我们是不是可以在模型预训练的阶段就引入跟文本表示相关的训练目标,从而使得预训练得到的语言模型在向量召回场景具备更好的句子表示能力。
基于上面的两点思考,我们在MLM任务中引入了一种结合term weight的token masking方法, 命名为Retrieval Oriented Masking (ROM),参考图3。在预训练阶段,我们沿用MLM这个任务,但是masking token的选择不是随机的,而是跟term的权重相关,高权重的term会被更高的概率被mask。通过这样的设置,使得预训练语言模型更加关注高权重term的学习。这里, 预训练数据的term weight可以预选计算获取。
此外,为了增强语言模型的句子表示能力,我们再预训练的过程中的引入类似SimCSE中的句子级别的对比学习损失函数。因此,整个预训练过程中的损失函数可以表示为:
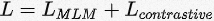
增加对比学习损失函数需要构建句子正样本对,一种方式就是直接采用SimCSE中句子Dropout两次的特征结果作为正样本对, 此外,我们还尝试了类似CoCondenser中的co-training的方法, 实验结果表明, co-training的方法是更优的选择。
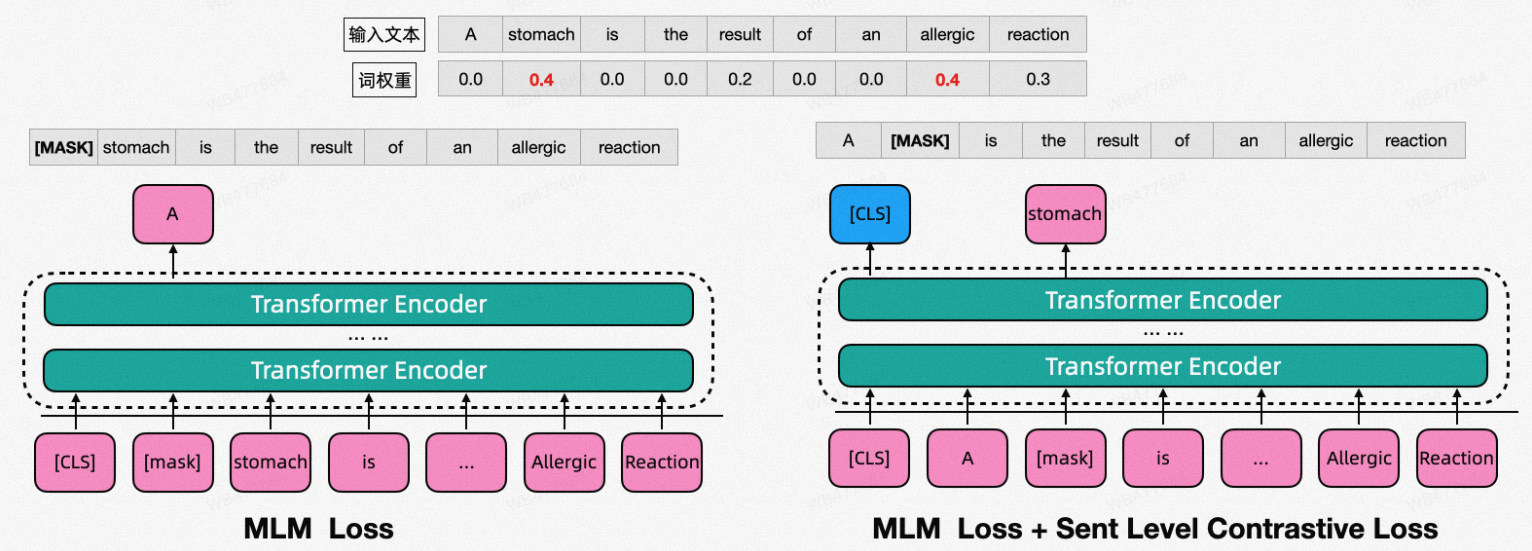
图3 ROM模型示例
2.2 ROM模型实验结果
2.2.1 MS MARCO Passage Ranking召回任务实验结果
我们先介绍在公开学术数据集上的向量召回结果。MS MARCO 数据集是文本检索任务最具代表性的数据集,该数据集由包含800万篇文档,passage任务包含80万query-doc相关pair, 其标注数据来自Bing搜索引擎,与实际工业场景十分接近。此外, MS MARCO数据集有公开的LeaderBoard, 目前吸引了多个知名企业和高校提交实验结果。
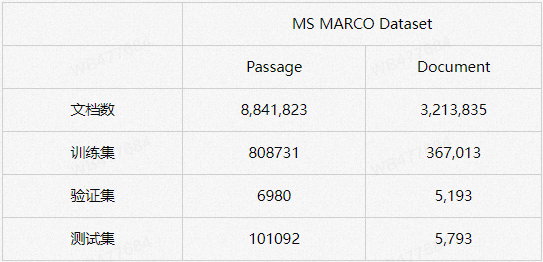
表1 MS MARCO数据集
表2中详细展示对比了MS MARCO Passage Ranking任务召回阶段不同模型的效果, 主要包括MRR@10和Recall@1000指标。我们可以发现:
- 借助于大规模标注数据和预训练语言模型, 基于预训练语言模型训练的召回模型效果远优于BM25方法
- 针对文本检索召回优化设计后的预训练语言模型对比基础的BERT-base模型召回效果会有更进一步的提升
- 基于ROM Masking策略预训练的模型对比此前的优化模型召回效果可以取得进一步的提升。同时,Co-training的训练策略同时适用于ROM模型, coROM模型的召回效果明显优于coCondenser模型
| Model | MRR@10 | R@1000 |
|---|---|---|
| BM25 | 18.9 | 85.3 |
| BERT-base | 33.4 | 95.5 |
| Condenser | 36.6 | 97.4 |
| RocketQA | 37.0 | 97.9 |
| ROM | 37.3 | 98.1 |
| coCondenser | 38.2 | 98.4 |
| coROM | 39.1 | 98.6 |
| 表2 MS MARCO Passage Ranking任务召回阶段效果对比 |
2.2.2 垂直搜索业务效果验证
除了公开数据集,我们也在团队内部一些垂直搜索场景和公有云openSearch上的一些搜索客户上验证了ROM模型的效果,实验结果对比如表3-4所示:
| 地址文本搜索向量召回 | 地址文本搜索向量召回 | 对话推理向量召回 | 对话推理向量召回 |
|---|---|---|---|
| Model | Recall@1 | Model | Recall@5 |
| AddreBERT | 63.0 | ALBERT | 34.19 |
| ROM | 69.0 | ROM | 39.56 |
| 表3 地址文本搜索&对话推理向量召回实验结果 |
| 电商搜索向量召回 | 电商搜索向量召回 | 教育行业搜题向量召回 | 教育行业搜题向量召回 |
|---|---|---|---|
| Model | Recall@5 | Model | Recall@1000 |
| StructBERT | 36.00 | StructBERT | 86.72 |
| Condenser | 42.12 | Condenser | 90.23 |
| ROM | 46.15 | ROM | 92.35 |
| 表4 电商搜索向量召回&教育搜题向量召回实验结果 |
需要说明的是, 地址搜索中AddreBERT是指利用地址数据进行过继续预训练的StructBERT模型, 考虑到线上实际使用计算效率,地址向量召回、对话推理、电商搜索向量召回采用的都是4层Tiny模型。
3 预训练语言模型精排
3.1 MS MARCO Passage Ranking任务
章节2中我们重点介绍了召回模型,本章节我们结合我们之前在MS MARCO Passage Ranking任务提交的方案介绍预训练语言模型在精排阶段的应用。在精排阶段,我们采用交互模型。基于精排模型,我们实验对比了三个方面的因素对排序模型结果的影响:预训练语言模型底座,负样本数据以及损失函数。
3.1.1 预训练语言模型底座
对比不同预训练语言模型的在精排阶段的效果。如下表所示,总的来说模型的参数量对于结果有着最直接的影响。在同等参数量的情况下,不同的底座结果也有所差距。
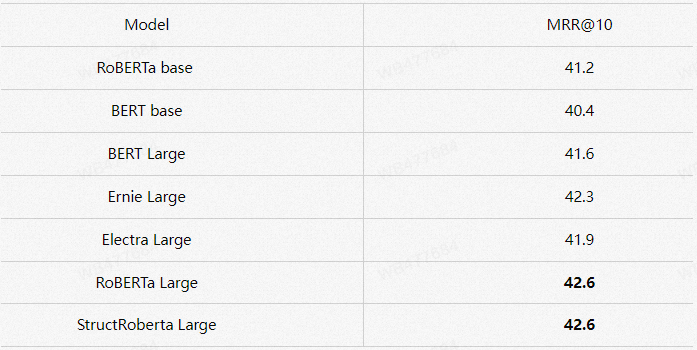
表5 精排模型不同预训练语言模型底座效果对比
3.1.2 负样本数据构造
精排模型的训练数据来自于召回模型的结果,不同的召回模型结果的影响可以分为两个方面。第一,召回阶段的效果优劣意味是否有更多的相关性更好的文档在候选集合中。第二,精排模型的负样本从召回模型的top结果中采样得到,更好的召回模型可以获得更高质量的负样本,提升模型的学习效果。表6中对比了基于不同召回模型数据训练的精排模型的效果。可以看到,对比BM25召回方法,coCondenser和ROM召回模型训练的精排模型效果有明显提升。

表6 基于不同召回模型生产训练数据训练的精排模型效果对比
此外,考虑到精排模型的训练效率,对于每个query我们会采样少量负样本(8-10个)训练模型。实验中,我们发现,不同的负采样方法对结果也有着明显的影响。我们主要尝试了三种不同的策略,第一种在召回的top100结果中随机采样,第二种是从top1000中随机采样,第三种是分块采样,50%的负样本来自top100,50%来自top100-1000,通过这种方法,排序模型可以学习到不同档位负样本的特征,实验结果中也证明了这种采样方法效果最好。

表7 不同负样本采样策略训练的精排模型效果对比
3.1.3 损失函数设计
在损失函数,我们主要对比了margin loss和 constrastive loss 训练排序模型的效果,发现基于对比学习的方法能显著提升模型效果。此外,我们尝试了rdrop[3]作为正则方法,发现该方法能带来0.3左右的效果提升。

表8 不同损失函数、训练策略精排模型效果对比
3.2 HLATR模型
3.2.1 模型背景
在训练精排模型的过程中,我们发现了一个值得注意的现象:排序模型的排序效果随着候选集合的数量增加逐渐下降。这可能是由于其在训练阶段与测试阶段负样本的数据分布的不同导致的。在训练阶段,单个训练步骤里面每个Query仅仅与少量负样本(8-10个)进行训练,尽管我们在不同档位均进行了采样,但是依然与预测阶段的实际数据分布存在差异,因此预测阶段的效果不够稳定。此外,我们还发现, 简单的将召回模型的分数和精排模型的分数加权求和,就能明显改善最终的排序效果:
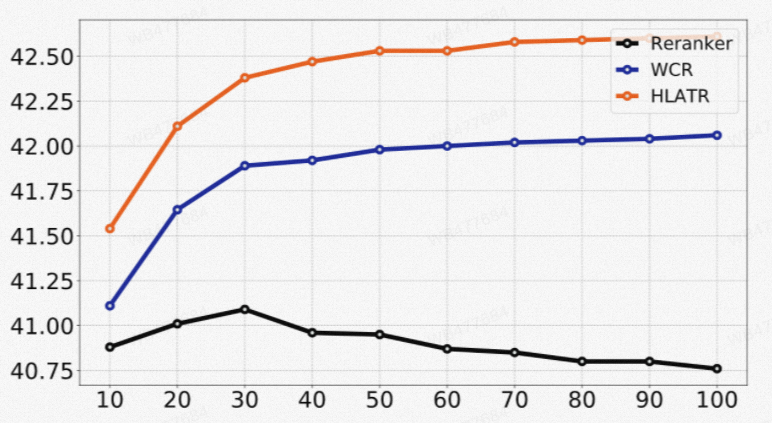
图4 精排模型效果对比. 横轴:预测阶段doc数量, 纵轴: MRR@10指标 Reranker:基础的交互排序模型 WCR(weighted combination reranker):直接将召回模型和精排模型加权排序 HLATR:增加第三阶段重排序模型结果
通过上面的现象观察到, 在训练精排模型过程中,更大的负样本数量能提升模型的效果和鲁棒性(实际上在召回模型训练也是类型的), 其次,耦合召回阶段和精排阶段的特征可以进一步提升排序效果。因此,我们设计了一个轻量化的重排序模型HLATR(Hybrid List Aware Transformer Reranker)。
3.2.2 模型结构
HLATR方法的概况如下图所示,在传统的两阶段召回、排序之后,HLATR增加了一个新的排序阶段,在该排序阶段中,HLATR以query与全部候选doc序列作为输入,一次性输出所有文档的相关性得分作为最终排序结果。
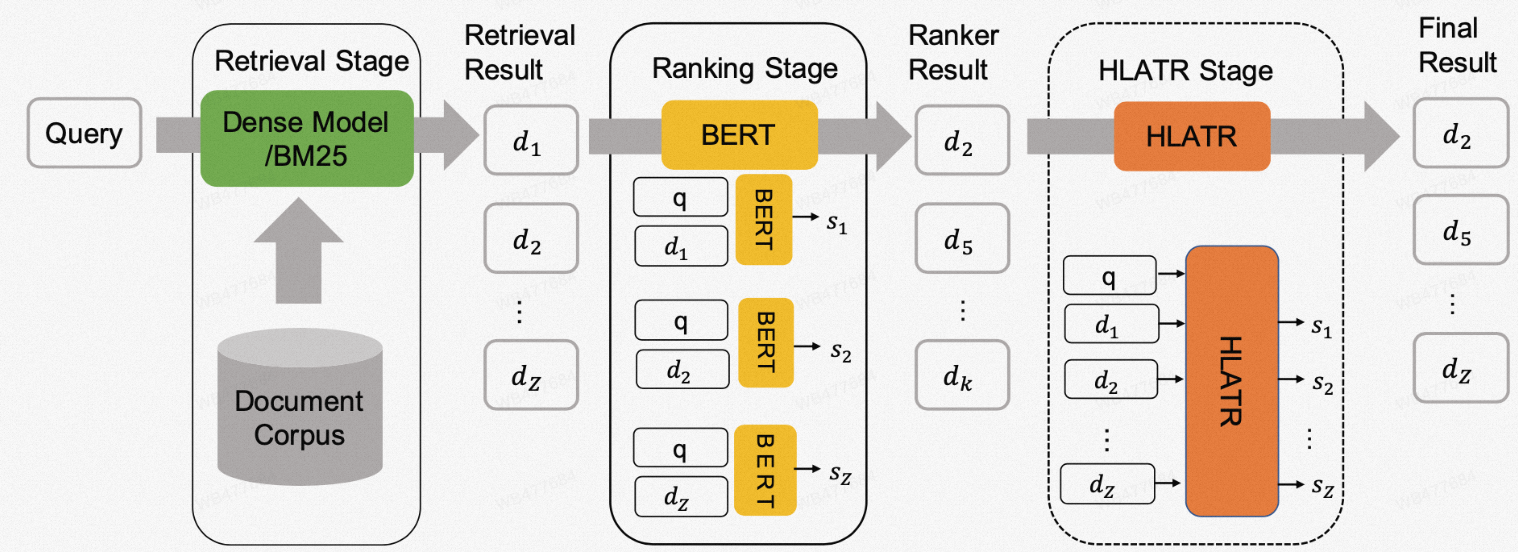
图5 HLATR模型概况
模型的具体结构如下图所示,HLATR采用了一个多层的Transofrmer结构作为encoder。原始Transformer模型的输入包含两部分,一部分是单词的embedding,另一部分是每个单词的position embedding。对应到HLATR中,我们采用每个文档在精排阶段排序模型输出的logits,即预训练模型训练的精排模型最后一层[CLS]位置的表示作为当前doc的embedding表示,同时使用召回阶段该Doc的排序位置计算position embedding。最终将两部分表示相加作为模型的输入。在训练过程中,我们仍然采用对比学习损失函数作为训练目标:
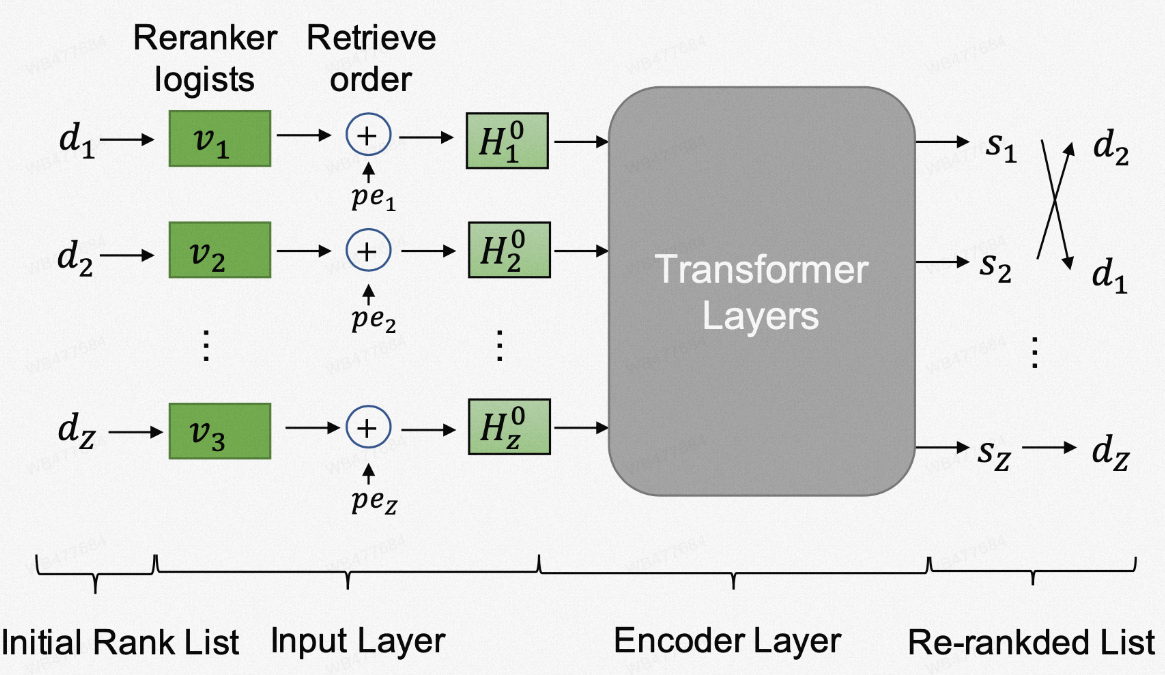
图6 HLATR模型结构
3.2.3 实验效果
我们在MS MARCO Passage 和 MS MARCO Document两个数据集上验证了HLATR方法。可以看到,对于不同的召回模型与排序模型组合,HLATR均能取得明显的提升(表中的dense retrieval 代表 coCondenser 作为召回模型,sparse代表BM25作为召回模型)。
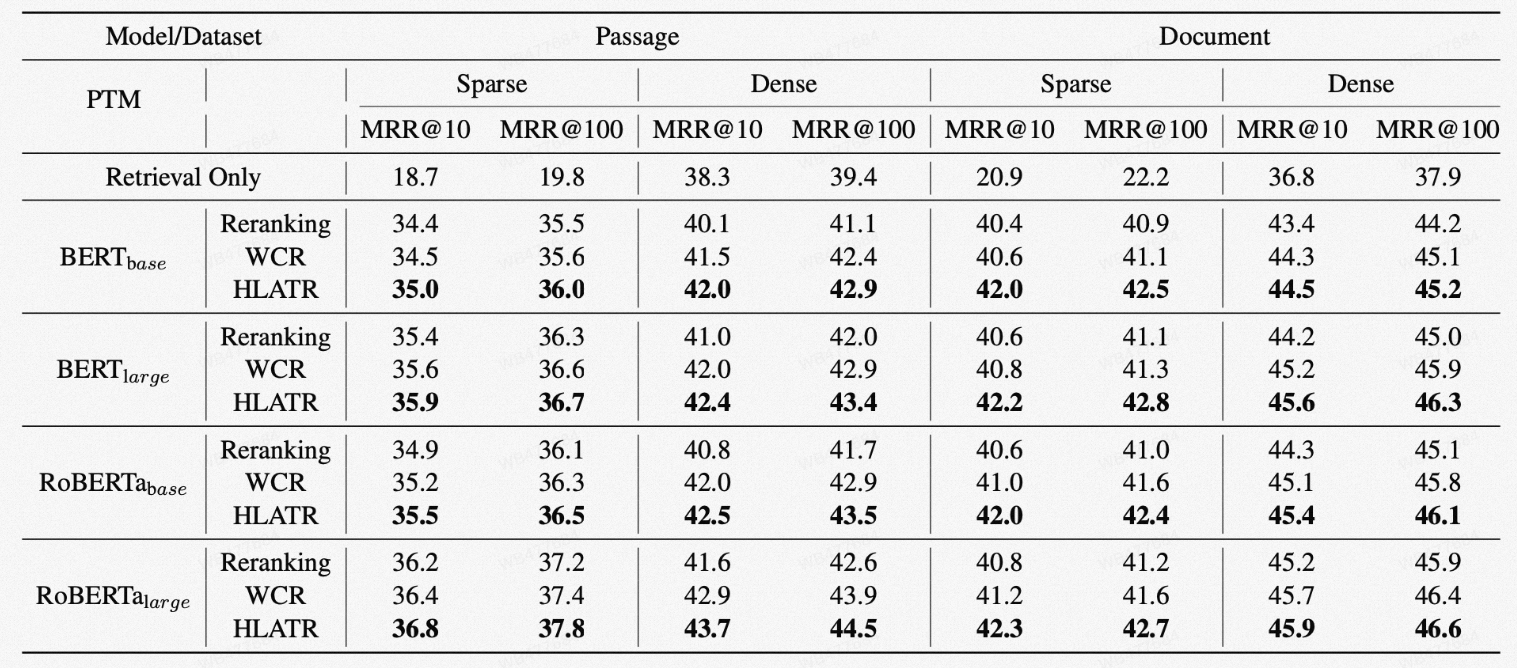
表9 HLATR模型实验结果
3.3 MS MARCO LeaderBoard
在MS MARCO Passage Rnkaing任务上, 通过ROM预训练模型以及HLATR重排序模型,我们提交方案的全链路排序结果较其它团队的工作取得了进一步的提升,目前在MS MARCO Passage Ranking榜单上排名第一[8] 。
4.开源列表
● 论文公开: ROM[14]和HLATR[7]模型相关的介绍论文已经在Arxiv公开
● 数据集开源: 基于阿里内部搜索场景标注的多领域中文检索数据集Multi-CPRgithub公开Multi-CPR: A Multi Domain Chinese Dataset for Passage Retrieval
● 模型开源: 基于通用领域中英文数据、垂直领域中文数据集训练的预训练语言模型文本表示(召回)模型、语义相关性(精排)模型已逐步通过ModelScope平台开源,欢迎大家下载体验
● 文本向量表示模型(召回): 中文通用领域、电商领域、医疗领域,英文通用领域
● 文本语义相关性模型(精排): 中文通用领域、电商领域、医疗领域,英文通用领域
参考文献
[1] Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval. Gao, Luyu and Jamie Callan. ACL (2022).
[2] Rethink Training of BERT Rerankers in Multi-Stage Retrieval Pipeline. Gao, Luyu, Zhuyun Dai and Jamie Callan. ECIR (2021).
[3] R-Drop: Regularized Dropout for Neural Networks.Liang, Xiaobo, Lijun Wu, Juntao Li, Yue Wang, Qi Meng, Tao Qin, Wei Chen, M. Zhang and Tie-Yan Liu. NeurIPS (2021)
[4] Condenser: a Pre-training Architecture for Dense Retrieval. Gao, Luyu and Jamie Callan. EMNLP (2021).
[5] B-PROP: Bootstrapped Pre-training with Representative Words Prediction for Ad-hoc Retrieval. Ma, Xinyu, Jiafeng Guo, Ruqing Zhang, Yixing Fan, Yingyan Li and Xueqi Cheng. SIGIR (2021)
[6] RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering. Qu, Yingqi, Yuchen Ding, Jing Liu, Kai Liu, Ruiyang Ren, Xin Zhao, Daxiang Dong, Hua Wu and Haifeng Wang. NAACL (2021).
[7] HLATR: Enhance Multi-stage Text Retrieval with Hybrid List Aware Transformer Reranking. Zhang, Yanzhao, Dingkun Long, Guangwei Xu and Pengjun Xie. ArXiv(2022).
[8] https://microsoft.github.io/msmarco/
[9] Dense Passage Retrieval for Open-Domain Question Answering. Karpukhin, Vladimir, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Yu Wu, Sergey Edunov, Danqi Chen and Wen-tau Yih. EMNLP(2020).
[10] Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval.Xiong, Lee, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed and Arnold Overwijk. ICLR(2021).
[11] Multi-View Document Representation Learning for Open-Domain Dense Retrieval. Zhang, Shun, Yaobo Liang, Ming Gong, Daxin Jiang and Nan Duan. ACL (2022).
[12] SimCSE: Simple Contrastive Learning of Sentence Embeddings. Gao, Tianyu, Xingcheng Yao and Danqi Chen. EMNLP (2021).
[13] Multi-CPR: A Multi Domain Chinese Dataset for Passage Retrieval. Long, Dingkun, Qiong Gao, Kuan Zou, Guangwei Xu, Pengjun Xie, Ruijie Guo, Jianfeng Xu, Guanjun Jiang, Luxi Xing and Ping Yang. SIGIR(2022)
[14] Retrieval Oriented Masking Pre-training Language Model for Dense Passage Retrieval. Long, Dingkun, Yanzhao Zhang, Guangwei Xu and Pengjun Xie. ArXiv(2022).

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献652条内容
已为社区贡献652条内容

所有评论(0)