
B站开源SOTA动画视频生成模型 Index-AniSora!
B站升级动画视频生成模型Index-AniSora技术并开源,支持番剧、国创、漫改动画、VTuber、动画PV、鬼畜动画等多种二次元风格视频镜头一键生成!
00.前言
B站升级动画视频生成模型Index-AniSora技术并开源,支持番剧、国创、漫改动画、VTuber、动画PV、鬼畜动画等多种二次元风格视频镜头一键生成!
整个工作技术原理基于B站提出的 AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era(https://arxiv.org/abs/2412.10255)实现,该工作已经被IJCAI25接收。在此基础上进一步提出了首个专为二次元视频生成打造的强化学习技术框架,全面提升动画内容的生产效率与质量 Aligning Anime Video Generation with Human Feedback(https://arxiv.org/abs/2504.10044)
所有的工作全部开源!快戳地址:https://github.com/bilibili/Index-anisora/tree/main
模型链接:
https://modelscope.cn/models/bilibili-index/Index-anisora
体验链接:
https://modelscope.cn/studios/bilibili-index/Anisora
上Demo!
https://live.csdn.net/v/478102
喜欢的漫画一键出动画效果,支持多种小众画风,效果更加丰富,从此告别“PPT动画”
Case1
首帧

Prompt
画面中一个人在快速向前奔跑,他奔跑的速度很快使得人物有些模糊
生成视频
Case2
首帧

Prompt
画面中的人物向上抬了下手臂,他手臂上的气体在流动
生成视频

Case3
首帧

Prompt
左边男人紧紧抿着嘴唇,脸上刻满了愤怒和决心。他的表情传达出无尽的挫折与坚定信念。与此同时,另一个男人的嘴巴张得大大的,仿佛即将开口大声说话或大喊大叫
生成视频

时域条件控制(对应任务如视频插帧、扩写开头)
首帧

尾帧

生成视频

运动空间条件控制
首帧

运动掩码

生成视频(带有掩码的可视化)

运动强度控制
首帧

Prompt
一个穿着粉红色开襟羊毛衫的年轻女子坐在一间舒适房间的地板上。她轻轻地抚摸着她的黑猫,它正在一个小盒子上的碗里吃东西
正常强度

大幅强度

接下来,将为大家介绍相关的技术方案 👇
(或者直接阅读 B站自研动画视频生成模型全链路技术报告)
01.方法
研究团队提出了一套专门用于动漫视频生成任务的对齐pipeline,其整体框架如图1所示。研究团队构建了首个面向动漫领域的高质量奖励数据集,共包含 30,000 条人工标注的动漫视频样本。人工评估包括两个方面:视觉外观(Visual Appearance)与 视觉一致性(Visual Consistency)。
其中,视觉外观的评价仅考虑视频帧的质量,包括视觉平滑度(VS)、视觉运动(VM)与视觉吸引力(VA)三个维度。而视觉一致性则进一步扩展了基本的文本-视频一致性(TC),引入了图像到视频(I2V)任务中的图像-视频一致性(IC)与动漫内容中特有的角色一致性(CC),确保更全面的评价。通过这六个维度,研究团队对动漫视频的整体质量进行系统性评估,从而更准确地反映人类在奖励建模中的偏好。基于此,研究团队进一步提出了 AnimeReward,一个专为动漫视频生成对齐设计的多维度高可信奖励系统。由于不同维度所关注的视觉特征存在差异,研究团队为不同维度采用专门的视觉-语言模型进行奖励回归,以更贴近地拟合人类偏好。研究团队进一步提出了 差距感知偏好优化(GAPO) ,显式地将正负样本对之间的偏好差距融入损失函数,从而提升对齐训练的效率和最终性能。
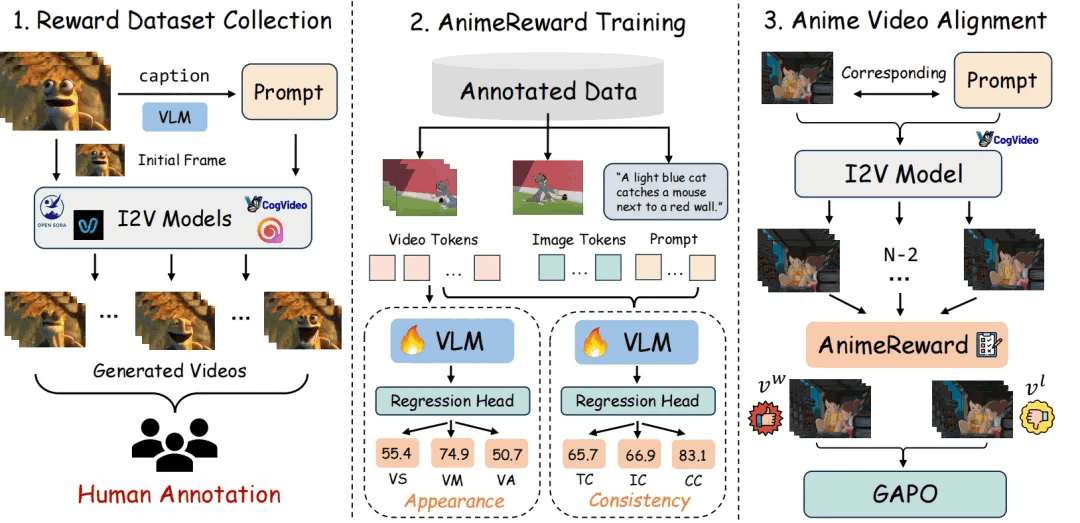
研究团队提出了一套专门用于动漫视频生成任务的对齐pipeline,其整体框架如图1所示。研究团队构建了首个面向动漫领域的高质量奖励数据集,共包含 30,000 条人工标注的动漫视频样本。人工评估包括两个方面:视觉外观(Visual Appearance)与 视觉一致性(Visual Consistency)。z z
图1 对齐管线整体概述
1. 动漫奖励数据集构建
为了增强数据集的动作类别多样性,研究团队收集的视频样本涵盖多种动作类别,包括说话、行走、挥手、亲吻、哭泣、拥抱、推拉等典型行为场景。通过人工标注,研究团队从 100 多种常见动作中总结出标准化的动作标签,对每个标签收集约 30~50 个视频片段,最终得到 5000 条真实动漫视频作为基础数据源。在文本提示词的设计方面,研究团队采用 Qwen2-VL 模型[1]对视频打标自动生成提示词,并使用 CogVideoX[2]中提出的提示词优化策略,生成文本提示。
原始图像采用每个视频的第三帧,以作为图像到视频生成的输入。基于这些提示词和原始图像,研究团队使用了 5 个先进的图像到视频生成模型(Hailuo、Vidu、OpenSora[3]、OpenSora-Plan[4]和 CogVideoX[2]),生成多样化的动漫视频。结合初始的 5000 条GT视频,研究团队构建了一个包含 30000 条动漫视频的奖励数据集,用于奖励模型的训练。此外,研究团队还构建了一个包含 6000 条动漫视频的测试集,并严格保证测试集与训练集在初始图像和提示内容上无重叠,以确保测试评估的准确性与泛化性。
为了全方位评估生成动漫视频的质量,人工标注从两个方面衡量视频质量:视觉外观与视觉一致性。其中,视觉外观主要衡量视频的基础质量,关注其视觉表现,包括视觉的平滑度(visual smoothness)、运动幅度(visual motion)以及整体的视觉吸引力(visual appeal);而视觉一致性则更加侧重于多模态之间的协调性,具体包含文本与视频的语义对齐(text-video consistency)、图像与视频的时空一致性(image-video consistency),以及动漫角色在视频中的稳定性(character consistency)。研究团队共邀请了 6 名专业标注人员参与标注过程,对每段视频从上述 6 个维度分别打分,评分范围为 1 到 5 分,5 分表示质量最佳。每个维度的最终得分由所有标注者的打分取平均值,以确保评价的客观性和鲁棒性。

02.实验
数据集
在对齐训练中,研究团队采用开源模型 CogVideoX-5B[2] 作为基线模型。研究团队首先构建了一个包含 2000 条原始动漫图像及其对应文本提示的初始训练集。基于该数据集,研究团队使用基线模型为每组数据采样生成 段动漫视频,再利用 AnimeReward,对每组生成视频进行偏好奖励评分,选择其中得分最高和得分最低的两个视频,构成一个偏好样本对。最终得到包含 2000 对偏好样本的集合作为后续偏好对齐优化的训练集。
实验结果
研究团队采用自动化评测和人工评测两种方式来评估模型的对齐效果。自动化评测包含 VBench-I2V[11]、VideoScore[12] 和研究团队提出的 AnimeReward 三种方法。人工评测邀请了三位专业的评测人员给出主观评价。只有当三位评测者中至少两位都认为视频 比 更好或更差时,视频 才会被认为赢或输 。
VBench-I2V [11]基准的评测结果如表1所示,研究团队提出的偏好对齐方法在总分上取得了最优表现,在几乎所有评估指标上均显著优于基线模型,并在大多数情况下超越了 SFT(监督微调)模型。值得注意的是,在 I2V Subject 和 Subject Consistency 两个关键指标上的提升尤为显著,表明研究团队的对齐方法能够帮助视频生成模型在保持动漫角色一致性方面具备更强的能力。
如表2所示,在 AnimeReward 评价体系下,除 Visual Motion 外,研究团队的方法在所有维度上均实现了大幅提升,说明研究团队的对齐模型在视觉外观与一致性方面更贴近人类偏好。在 VideoScore [12]评估中,研究团队的方法在三个维度上均优于基线模型与 SFT 模型,表现出更好的视觉质量和时序稳定性。同时,研究团队也观察到了,在动态程度(即 Visual Motion/ Dynamic Degree)这一指标上,对齐后的模型表现略逊于基线与 SFT 方法。对此,研究团队认为,高动态程度的视频更容易引发空间扭曲与伪影,从而大大降低整体视觉质量,对人类主观偏好产生负面影响。这一结果也表明,人类通常喜欢具有更高视觉质量、更强一致性与更好稳定性的视频内容,而非单纯追求高动态幅度的生成结果。

表1 在VBench-I2V上的定量性能比较

表2 在AnimeReward和VideoScore上的量化性能比较
图3展示了人工评测的对比实验结果,研究团队的对齐模型相较于基线模型与 SFT 模型展现出显著优势,整体胜率超过 60%。尽管 SFT 模型使用了偏好分数最高的优质样本进行训练,但其生成视频的质量并未得到明显提升,甚至在人工评测中的胜率低于基线模型。
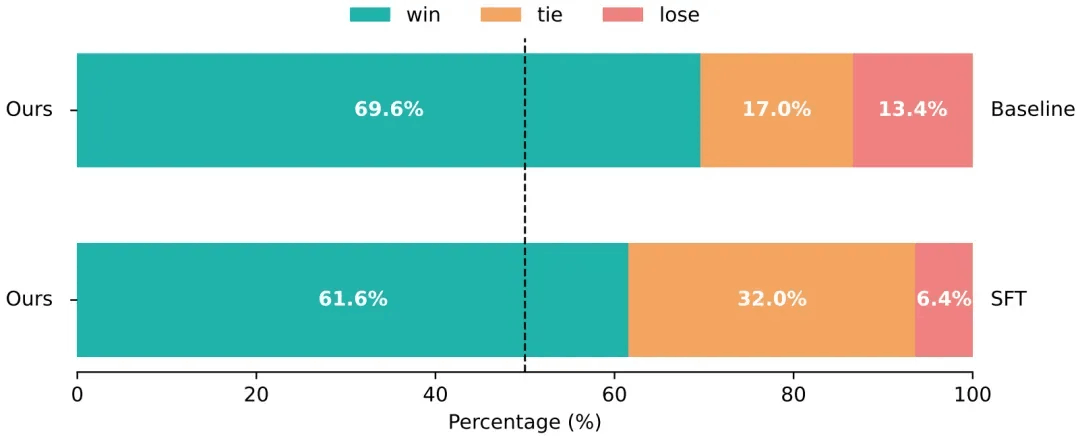
图3 不同模型生成的动漫视频的人工评测结果
消融研究
为验证研究团队提出的差距感知偏好优化(GAPO) 相较于传统DPO的优势,研究团队在保持实验设置一致的前提下,仅更换偏好优化算法,进行对比实验。研究团队在前述三种评价体系上对不同模型进行了系统评估,实验结果如表3所示。其中,AnimeReward(AR) 和 VideoScore(VS) 的最终得分为各维度得分的平均值。从结果来看,GAPO 在三个评价体系中均取得了最优表现,尤其在 VBench-I2V(V-I2V) 和 AnimeReward(AR)上相较 DPO 获得了显著提升。
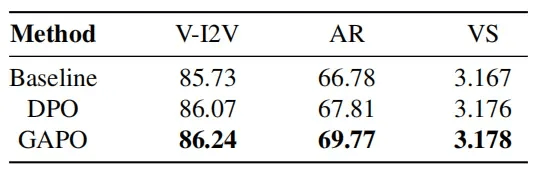
表3 对GAPO在三个评价体系上的消融研究结果
为验证 AnimeReward 奖励模型在动漫视频偏好对齐任务中的优势,研究团队设计了对比实验,使用 VideoScore [12]作为替代的奖励模型进行对齐训练。实验结果如表4所示。从结果可以看出,使用 AnimeReward 训练的模型在两个评价体系中均优于使用 VideoScore 训练的模型;而 VideoScore 仅仅在其自身评价体系中取得优势。为了更客观地评估两者的对齐性能,研究团队在图4展示了它们相对于基线模型在第三方评价基准 VBench-I2V [11]各个维度上的可视化评价结果。除 Dynamic Degree 外,基于 AnimeReward 的对齐模型在其余 7 个维度上全面优于 VideoScore。

表4 基于不同奖励模型的消融研究结果
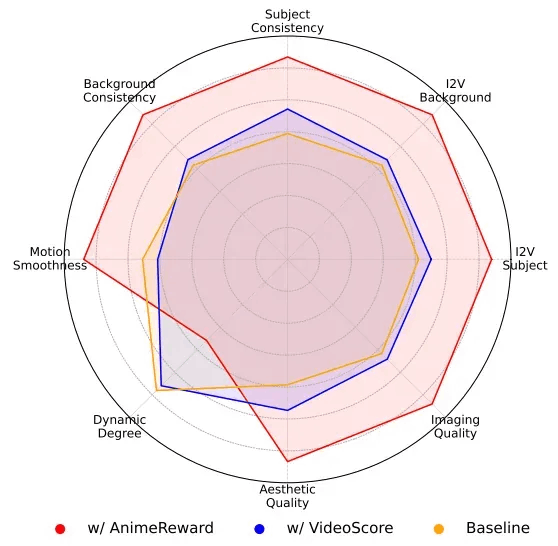
图4 基于不同奖励模型在VBench-I2V多个维度上的可视化评估结果
03.结论
以上提出了首个针对动漫视频生成的奖励模型 AnimeReward,旨在模拟人类偏好对生成动漫视频进行全方位的评价。研究团队基于两大方面设计了六个评价维度,从多个角度衡量生成动漫视频的质量。基于 AnimeReward,研究团队进一步提出了一种新颖的优化对齐策略 差距感知偏好优化(Gap-Aware Preference Optimization, GAPO),在优化损失中显式引入偏好差距信息,从而高效提升生成模型的对齐性能。实验结果表明,仅仅依赖基线模型生成的视频数据,研究团队提出的对齐管线依然能够显著提升动漫视频的生成质量,使结果更贴近人类偏好,验证了该方法在偏好对齐任务中的有效性与实用性。
04.参考文献
[1] Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. arXiv preprint arXiv:2409.12191, 2024.
[2] Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072, 2024.
[3] Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404, 2024.
[4] Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Liuhan Chen, et al. Open-sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131, 2024.
[5] Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning. arXiv preprint arXiv:2405.01483, 2024.
[6] Mengmeng Wang, Jiazheng Xing, and Yong Liu. Actionclip: A new paradigm for video action recognition. arXiv preprint arXiv:2109.08472, 2021.
[7] Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wenlong Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, et al. Grounding dino 1.5: Advance the "edge" of open-set object detection. arXiv preprint arXiv:2405.10300, 2024.
[8] Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, et al. Sam 2: Segment anything in images and videos. In ICLR, 2025.
[9] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, 2022.
[10] Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In NeurIPS, 2023.
[11] Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, et al. Vbench: Comprehensive benchmark suite for video generative models. In CVPR, 2024.
[12] Xuan He, Dongfu Jiang, Ge Zhang, Max Ku, Achint Soni, Haonan Chen, Abhranil Chandra, Ziyan Jiang, et al. Videoscore: Building automatic metrics to simulate fine-grained human feedback for video generation. In EMNLP, 2024.
点击链接, 即可跳转模型~
https://modelscope.cn/models/bilibili-index/Index-anisora
5月23日 14:00-17:00,在杭州 · 阿里云云谷园区,魔搭社区ModelScope核心开发者共创会来袭!本次活动聚焦大语言模型应用开发、AIGC轻量化训练、Agent开发框架等技术方向,与新老朋友们共同探讨开源社区共建、企业AI应用落地!

点击链接,跳转模型
https://modelscope.cn/models/bilibili-index/Index-anisora

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献662条内容
已为社区贡献662条内容

所有评论(0)