
通义万相Wan2.1-VACE开源!业内首个视频编辑统一模型!附推理教程
阿里巴巴正式开源通义万相Wan2.1-VACE!这是目前业界功能最全的视频生成与编辑模型,单一模型可同时支持文生视频、图像参考视频生成、视频重绘、视频局部编辑、视频背景延展以及视频时长延展等多种生成和
01.前言
阿里巴巴正式开源通义万相Wan2.1-VACE!
这是目前业界功能最全的视频生成与编辑模型,单一模型可同时支持文生视频、图像参考视频生成、视频重绘、视频局部编辑、视频背景延展以及视频时长延展等多种生成和编辑能力。
https://live.csdn.net/v/477540
02.开源内容
本次开源Wan2.1-VACE,有1.3B和14B两个版本,支持480P和 720P。其中1.3B版本可在消费级显卡运行。
GitHub:https://github.com/Wan-Video/Wan2.1
ModelScope: https://www.modelscope.cn/organization/Wan-AI
Huggingface: https://huggingface.co/Wan-AI
Technical Report: https://arxiv.org/abs/2503.07598
03.小编敲重点
开源效果
Wan2.1-VACE支持以下几种能力:
-
图像参考视频生成,支持基于主体和背景图像参考的视频生成;
-
视频的可控重绘,支持基于人体姿态、运动光流、画面景深、运动轨迹、着色等控制生成;
-
视频的局部编辑,通过指定视频的局部区域,可以实现视频元素的替换、增加和删除等操作;
-
视频扩展,在时间维度上支持视频任意片段生成,给定任意片段、首尾帧进行完整视频的补全。在空间维度上支持视频的扩展生成,这个能力的更进一步的应用是视频的背景替换,即可以保留主体不变来根据prompt变换背景或拓展视频画面。
最重要的是,作为一个统一的多任务模型,VACE还支持上述单任务能力的自由组合,从而破解了传统的单任务专家模型各司其职的协同难题。VACE统一模型的优势在于能够自然地实现前面所述基础能力的自由组合,不必再为了单一功能训练一个新的专家模型。通过组合各种能力,可以解锁各种各样的视频创作方式。这样一来,不仅大大简化了用户的工作流程,而且极大程度地扩展了AI视频生成创意的边界。
https://live.csdn.net/v/477541
技术优势:
1.采用多模态信息输入,提高视频生成可控性
文本提示词通常无法满足用户对于角色一致性、布局、运动姿态和幅度等要素的控制需求,特别是对于专业AI视频创作者而言。
为解决这一难题,VACE在Wan2.1文生视频基模型的基础上,增加了更多常见的输入形式,形成了集文本、图像、视频、mask和控制信号于一体的视频编辑统一模型。AYSCALE

其中:
对于图像输入,VACE可以接受物体参考图或者视频帧;
对于视频,用户可以通过抹除、局部扩展等操作,使用VACE进行重新生成;
对于局部区域,用户可以通过0/1二值信号来指定编辑区域;
对于控制信号,VACE支持深度图、光流、布局、灰度、线稿和姿态等。
2.统一的单一模型,为多种任务提供更加统一的解决方案
由于VACE的多模态输入模块和Wan2.1强大的视频生成能力,传统专家模型能实现的功能VACE可以轻松驾驭。例如:
图像参考能力,给定参考主体和背景,可以完成元素一致性生成。视频重绘能力,包括姿态迁移、运动控制、结构控制、重新着色等;局部编辑能力,包括主体重塑、主体移除、背景延展、时长延展等。
3.多任务自由组合,可以更加深度地挖掘视频生成的创意潜力。
VACE视频编辑统一模型的优势在于比较自然地支持各种原子能力的自由组合,不必再为了单一功能训练一个新的专家模型。
例如:
1.组合图片参考和主体重塑功能,可以实现视频的物体替换功能。
2.组合运动控制和首帧参考功能,可以实现静态图片的姿态控制。
3.组合图片参考、首帧参考、背景扩展和时长延展功能,可以将一张竖版图片,变成一个横版视频,并且在其中加入参考图片中的元素。
04.VACE统一框架
VACE的强大能力源于通义万相团队对模型框架的设计,以下是VACE框架的三个设计。
1.视频条件单元 VCU
首先,通义万相团队深入分析和总结了文生视频、参考图生视频、视频生视频,基于局部区域的视频生视频4大类视频生成和编辑任务的输入形态,提出了一个更加灵活统一的输入范式:视频条件单元 VCU。
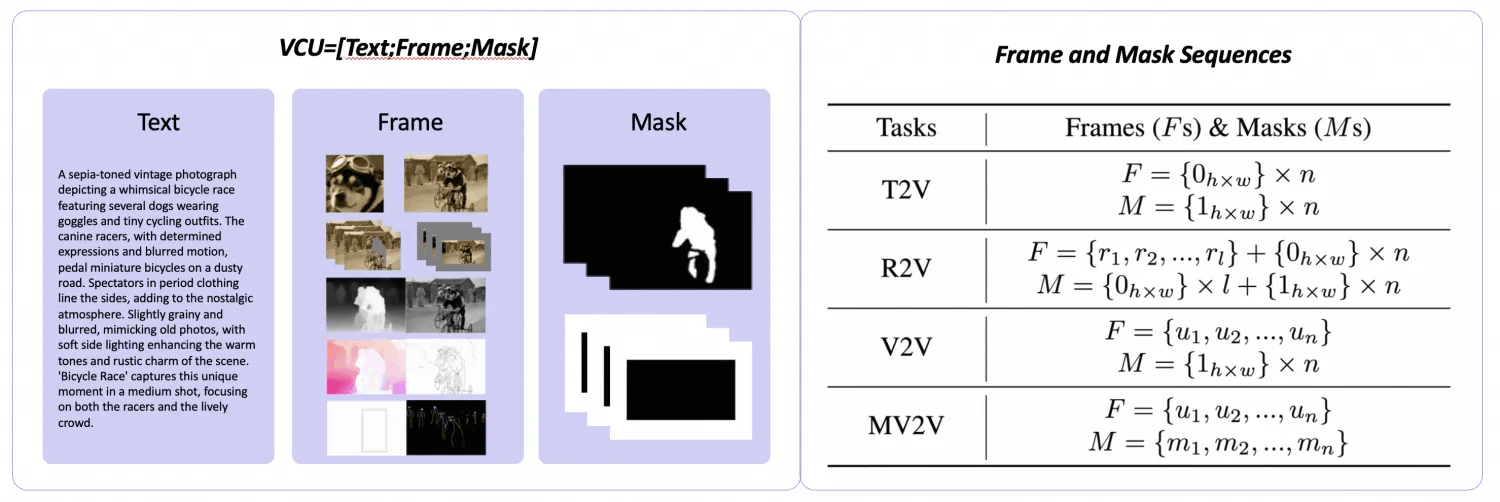
它将多模态的各类上下文输入,总结成了文本、帧序列、mask序列三大形态,在输入形式上统一了4类视频生成和编辑任务。
另外值得注意的是,VCU中的帧序列和mask序列在数学上可以相互叠加,从而给各种任务的自由组合创造了条件。
2.多模态输入的token序列化FINE-TUNING
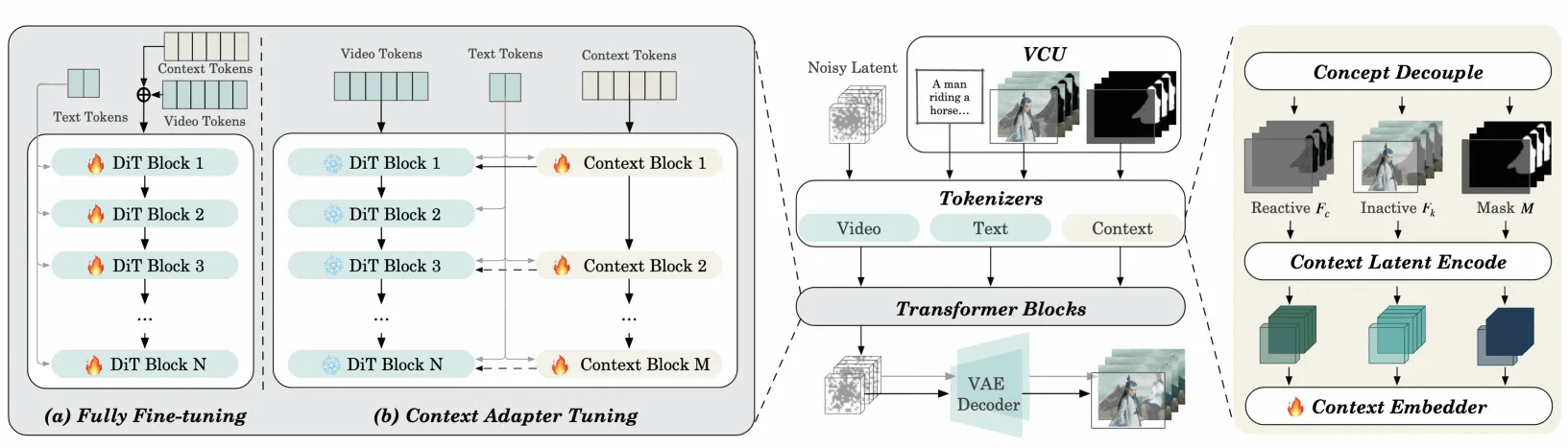
VACE解决的另一大难题是多模态输入的token序列化。token序列化(Tokenization)是Wan2.1的视频扩散Transformer架构能正确处理输入信息的前提条件。这里,VACE首先将VCU输入的Frame序列进行概念解耦。具体做法是,把需要保持不变的RGB像素,和需要重新生成的像素,例如控制信号等,分开重构成可变帧序列和不变帧序列。
然后,将可变帧序列、不变帧序列、mask序列分别进行编码至隐空间。这里可变帧序列、不变帧序列会通过VAE被编码至与DiT模型噪声的维度一致,通道数为16。而mask序列通过变形和采样,编码成时空维度一致,而通道数为64的隐空间特征。最后,将frame序列和mask序列的隐空间特征合一,并通过可训练参数映射为DiT的token序列。
3.上下文适配微调
在训练策略上我们对比了全局微调和上下文适配微调两种方案。全局微调通过训练全部的DiT参数,较少地新增参数,能取得更快的推理速度。而上下文适配微调方案是固定原始的基模型参数,仅选择性地复制并训练一些原始Transformer层作为额外的适配器。STEP
通过实验验证,两种训练策略在最终的验证损失上差别不大,但是上下文适配微调可以取得更快的收敛速度,并且避免了全局微调可能隐含的基础能力丢失的问题。在本次开源的版本使用了上下文适配器微调作为训练方式。
05.如何运行推理代码
安装代码库
下载Wan2.1代码库并安装对应的依赖
git clone https://github.com/Wan-Video/Wan2.1.git
cd Wan2.1
pip install -r requirements.txt
pip install modelscope模型下载
VACE有两个版本,分别是VACE-1.3B和VACE-14B,使用以下两个命令分别下载两个模型。
modelscope download Wan-AI/Wan2.1-VACE-1.3B --local_dir ./Wan2.1-VACE-1.3B
modelscope download Wan-AI/Wan2.1-VACE-14B --local_dir ./Wan2.1-VACE-14B运行推理脚本
以VACE-1.3B模型为例,运行参考图生成视频和视频编辑两个任务。
基于参考图生成视频(Reference-to-Video Generation):
运行如下推理命令,以参考图生成视频:
python generate.py --task vace-1.3B --size '832*480' --ckpt_dir ./Wan2.1-VACE-1.3B --src_ref_images examples/girl.png,examples/snake.png --prompt "在一个欢乐而充满节日气氛的场景中,穿着鲜艳红色春服的小女孩正与她的可爱卡通蛇嬉戏。她的春服上绣着金色吉祥图案,散发着喜庆的气息,脸上洋溢着灿烂的笑容。蛇身呈现出亮眼的绿色,形状圆润,宽大的眼睛让它显得既友善又幽默。小女孩欢快地用手轻轻抚摸着蛇的头部,共同享受着这温馨的时刻。周围五彩斑斓的灯笼和彩带装饰着环境,阳光透过洒在她们身上,营造出一个充满友爱与幸福的新年氛围。"|
输入参考图1 |
输入参考图2 |
 |
 |
|
输出的视频 |
|
在NVIDIA A100显卡上,生成832x480分辨率5秒长的视频,单次推理时间(不包含模型加载)为310秒,显存占用为28GB。
视频编辑(Video-to-Video Editing)
运行视频编辑功能,需要下载VACE官方代码库并安装对应的依赖
cd ..
git clone https://github.com/ali-vilab/VACE.git && cd VACE
pip install torch==2.5.1 torchvision==0.20.1 --index-url https://download.pytorch.org/whl/cu124 # 这一步需要根据CUDA版本调整安装源
pip install -r requirements.txt
pip install -r requirements/annotator.txt同时,将VACE-Annotators下载到VACE/models/VACE-Annotators下:
modelscope download iic/VACE-Annotators --local_dir ./models/VACE-Annotators然后,使用VACE-Annotators得到预处理的深度视频:
python vace/vace_preproccess.py --task depth --video assets/videos/test.mp4|
输入的原始视频 |
输出的深度视频 |
然后,将输出的深度视频拷贝到Wan2.1代码库,回到Wan2.1代码库路径下,运行如下命令进行视频编辑:
cd ../Wan2.1/
python generate.py --task vace-1.3B --ckpt_dir ./Wan2.1-VACE-1.3B --src_video src_video-depth.mp4 --prompt "两只戴着蓝色圈套的猫咪在打拳击比赛"|
编辑后的视频 |
在NVIDIA A100显卡上,生成832x480分辨率5秒长的视频,推理时间和显存占用同上。
06.直播精彩回放

点击链接,即可跳转模型~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)