
Qwen3 X ModelScope工具链: 飞速训练 + 全面评测
Qwen3 X ModelScope工具链: 飞速训练 + 全面评测
01.前言
Qwen于近日发布了Qwen3系列模型,包含了各个不同规格的Dense模型和MoE模型。开源版本中,Dense模型基本沿用了之前的模型结构,差别之处在于对于Q和K两个tensor增加了RMSNorm;MoE模型去掉了公共Expert,其他结构基本与前一致。在模型大小上,涵盖了从0.6B到32B(Dense)和235B(MoE)不同的尺寸。在推理能力上,增加了对于thinking能力的选择,使得模型应对不同场景更加自如和游刃有余。
对于私有化,或有垂直行业需求的开发者,一般需要对模型进行二次训练(微调,对齐等),在训练后进行评测和部署。从训练角度来说,需求一般是:
- 具有大量未标注行业数据,需要重新进行CPT。一般使用Base模型进行。
- 具有大量问答数据对,需要进行SFT,根据数据量选用Base模型或Instruct模型进行。
- 需要模型具备独特的回复能力,额外做一次RLHF。
- 需要对模型特定领域推理能力(或思维链)增强,一般会用到蒸馏、采样微调或GRPO
在实际场景中,经常会涉及多种训练的结合。例如,CPT之后一定会进行SFT,或者RLVR(例如GRPO with verifiable rewards)。在硬件需求上,从单卡到多机不等,这带来了训练选型上的困难。此外,在定制训练模型后,如何对于训练后的模型的效果进行全方位的准确评测,也是模型应用落地中的重要一环,如何实现简单易用的评测无缝连接,也是一个较大的挑战,尤其是当涉及到多领域甚至多模态组合场景上,包括寻找评测数据、跟踪评测进度等,都是需要解决的问题。
针对模型开发者的这些实际需求,魔搭社区开发和整理了以SWIFT(训练)+ EvalScope(评测)复合能力,来支持Qwen3系列模型全链路试用起来的方案。特别地,我们完善地为Qwen3-MoE Megatron结构训练提供了支持,较好解决了开源的MoE模型在定制过程中,二次训练成本较高,训练过程复杂等痛点。相较transformers结构训练,我们看到了20%~1000%的训练速度提升。更重要的是,在SWIFT框架中,Megatron结构的训练和transformers结构的训练,保持了大多数参数的一致性,开发者可以灵活切换这两种训练方式,而不引进额外任何成本。
|
场景 |
命令行(Qwen/Qwen3-8B) |
|
CPT |
swift pt --model Qwen/Qwen3-8B --dataset xxx链接:https://github.com/modelscope/ms-swift/blob/main/examples/train/pretrain/train.sh |
|
SFT |
swift sft --model Qwen/Qwen3-8B --dataset xxx链接:https://github.com/modelscope/ms-swift/blob/main/examples/train/tuners/lora/train.sh |
|
Megatron MoE |
megatron sft --model Qwen/Qwen3-8B --dataset xxx链接:https://github.com/modelscope/ms-swift/blob/main/examples/train/megatron/moe.sh |
|
DPO |
swift rlhf --rlhf_type dpo --model Qwen/Qwen3-8B --dataset xxx链接:https://github.com/modelscope/ms-swift/blob/main/examples/train/rlhf/dpo.sh |
|
GRPO |
swift rlhf --rlhf_type grpo --model Qwen/Qwen3-8B --dataset xxx链接:https://github.com/modelscope/ms-swift/blob/main/examples/train/grpo/train_72b_4gpu.sh |
|
Rejected sampling |
example:链接:https://github.com/modelscope/ms-swift/blob/main/examples/train/rft/rft.py |
|
Deployment |
swift deploy --model Qwen/Qwen3-8B --infer_backend vllm链接:https://github.com/modelscope/ms-swift/blob/main/examples/deploy/server/demo.sh |
|
Eval |
swift eval --model Qwen/Qwen3-8B --datasets xxx链接:https://evalscope.readthedocs.io/zh-cn/latest/get_started/basic_usage.html#id1 |
Megatron支持
在多卡场景中,一般以torch的DDP框架为蓝本,增加额外的并行分组来实现LLM训练。例如,目前主流训练卡显存一般为24G、40G、80G不等,部分卡型可以达到96G或者128G,但是这对承载一个32B模型训练是不够的,更不用说更大尺寸的模型。因此在DDP之外,一般增加模型切分机制,使每张卡上仅承载一部分的模型分片,并进行all-gather来收集参数,reduce-scatter来收集梯度,这也是DeepSpeed ZeRO或FSDP的基本原理。但是,对于32B以上尺寸的模型,或者MoE模型,transformers代码实现+DeepSpeed的大量卡间通讯和串行MoE都导致了训练效率不足。
for expert_idx in range(self.num_experts):
expert_layer = self.experts[expert_idx]
idx, top_x = torch.where(expert_mask[expert_idx])
current_state = hidden_states[None, top_x].reshape(-1, hidden_dim)
current_hidden_states = expert_layer(current_state) * routing_weights[top_x, idx, None]
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))现行MoE串行化代码
Megatron来自于NVIDIA的Megatron-LM库。该库一般承担超大规模的训练,而相比之下,transformers库更适应于较为轻量化的训练。这是因为:
- 在一般Dense模型小型训练场景下,轻量训练(LoRA、Quantization)带来的收益比较高,而Megatron的复杂分布式结构并不适合单卡或双卡的场景
- 开发者理解成本比较高,不利于理解和使用。
然而在我们的测试中,即使使用单机八卡环境,Dense模型训练使用Megatron比transformers同模型代码的速度也可以提升20%左右,GPU利用率也更高。在MoE模型上,该优势更加明显,加速比可以达到1000%或更多。
Megatron框架的优点有:
- 对于Attention结构有额外优化,例如算子融合(Fused kernel),这会让模型有更快的训练速度
- 更适配于多机训练,可以合理对机内和机外进行模型分片,保持较低通讯量。
- 对MoE结构有额外并行训练支持
我们可以看出,使用串行训练MoE无法利用多卡的优势,因此SWIFT引入了Megatron的并行技术来加速大模型的训练,包括数据并行、张量并行、流水线并行、序列并行,上下文并行,专家并行。支持Qwen3、Qwen3-MoE、Qwen2.5、Llama3、Deepseek-R1蒸馏系等模型的预训练和微调。
|
Megatron-LM |
DeepSpeed-ZeRO2 |
DeepSpeed-ZeRO3 |
|
|
训练速度 |
9.6s/it |
- |
91.2s/it |
|
显存占用 |
16 * 60GiB |
OOM |
16 * 80GiB |
Qwen3-30B-A3B模型全参数训练速度/显存占用对比
可以看到,MoE训练使用Megatron比使用transformers库+DeepSpeed快10倍左右。
02.RLVR支持
在DeepSeek-R1技术报告之后,业界普遍认识到可以使用verified reward训练模型的思维能力。这种方式相对PRM方式数据要求低很多,同时训练速度也更快,工程实现更简单,这有利于将RL训练应用到有需求的中小开发者场景中。RLVR的普遍训练算法包含PPO、GRPO、DAPO等,使用较多的是GRPO,因为其省略了Critic model,并使用采样代替了模型拟合过程,在工程实现上更加简单和鲁棒。SWIFT对RLVR算法也进行了支持,并且在最新的Qwen3模型上,也直接可以使用。
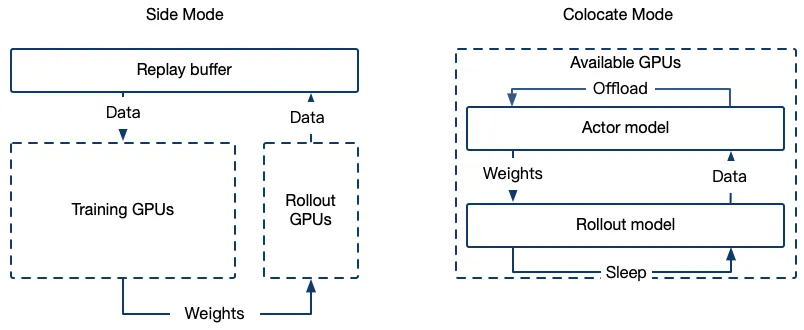
SWIFT GRPO model placement
目前我们支持了两种model placement:
- Side Mode:Actor和Rollout模型分别占用单独的GPU,这种模式下vLLM可以使用全部GPU显存和计算能力,并支持tensor parallel
- Colocate Mode:Actor和Rollout模型复用GPU。这种模式下vLLM和Actor会通过offload/load对GPU进行时分复用,对大规模模型更友好
目前SWIFT的GRPO可以支持百卡(或更大)集群的训练。
03.采样与蒸馏
蒸馏作为知识灌注的主要手段之一,在DeepSeek-R1的技术报告中也有提及。我们在实际训练Qwen3的过程中发现,如果使用自己的数据集直接SFT,可能会产生严重的知识遗忘问题。这个问题虽然一直伴随着近年大模型训练过程,但在最近的模型中体现尤为明显。
因此,我们预计未来模型训练范式的重心,可能从SFT往强化微调方向倾斜。这个方向包含了RLVR这种on-policy训练方法,也包含了拒绝采样微调和蒸馏这样的off-policy方法。使用rollout数据(无论是更大模型的数据,或者模型自身数据)的友好性和精密性比人为生成的数据集训练质量要高很多。例如,在之前的实验中我们发现,使用competition_math对LLM进行SFT,反而导致competition_math测试集掉10个点以上。反而使用蒸馏、MCTS采样、拒绝采样、GRPO方式可以在对应测试集提点的同时保留其他方向的知识。这可以近似理解为是“近端优化(Proximal policy)”的,虽然部分算法中并不带有KL散度正则限制。
同样,我们对模型采样和蒸馏进行了支持,这些支持可以直接应用在Qwen3系列模型上。example可以参考这里如下:
example1:
https://github.com/modelscope/ms-swift/blob/main/examples/sampler/distill/distill.sh
example2:
https://github.com/modelscope/ms-swift/blob/main/examples/train/rft/rft.py
04.评测支持
为了全面评测模型的各方面能力,了解训练前后模型的性能指标变化。ModelScope推出了EvalScope评测工具,提供了统一的平台来整合和管理多种模型在各种benchmark的评测流程,包括大语言模型的代码能力(LiveCodeBench)、数学能力(AIME2024, AIME2025)、知识能力(MMLU-Pro, CEVAL)、指令遵循(IFEval);多模态大模型的视觉理解能力(ChartQA);文生图模型的图文一致性(GenAI-Bench)等等。
通过EvalScope,我们可以方便地进行以下操作:
- 自动化评测流程:减少人工干预,提升评测效率
- 可视化性能分析:查看所有评测结果,便于对模型进行全面分析
- 自定义评测:通过简单的配置扩展到新的评测任务,或构建评测数据集集合
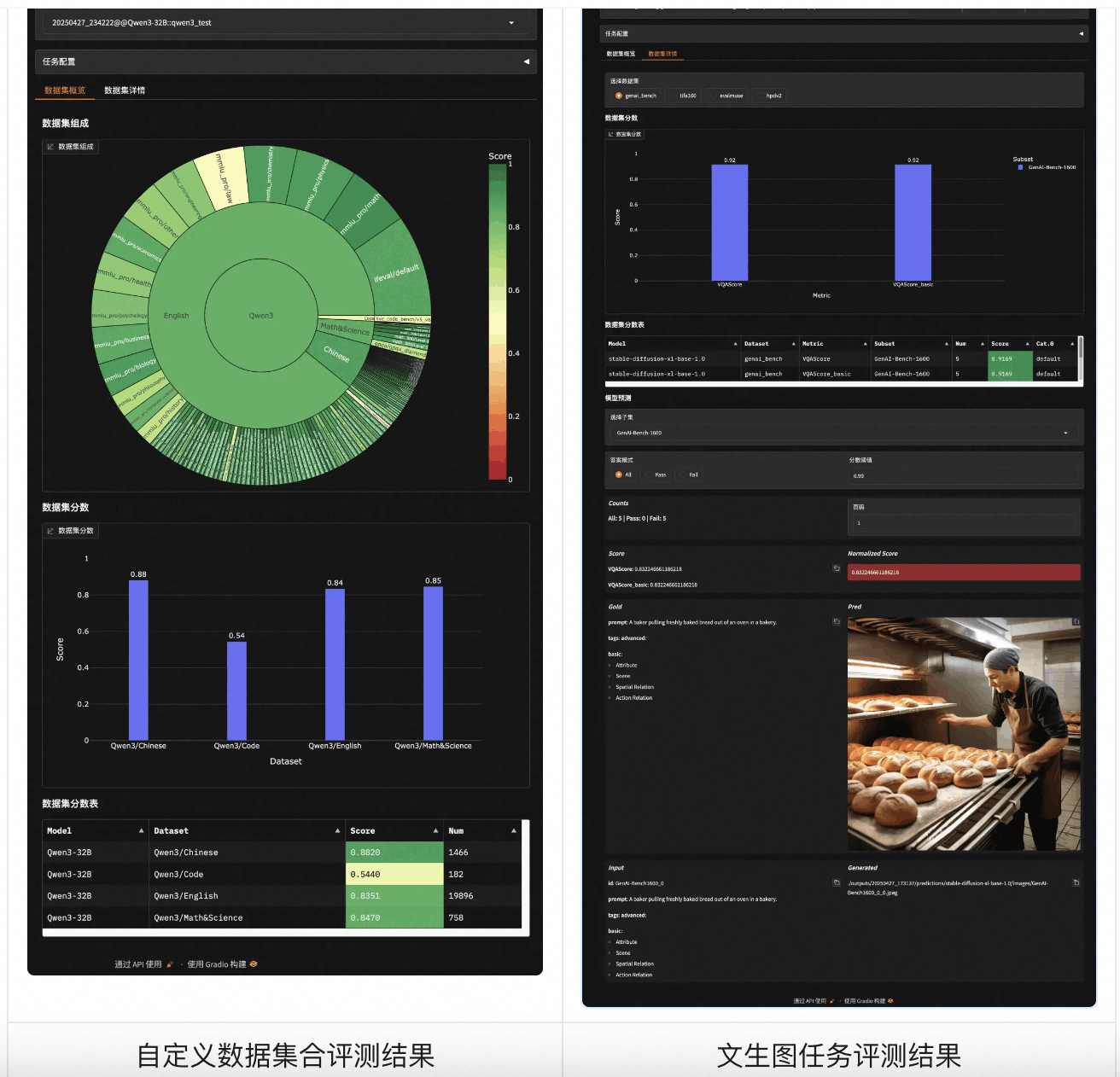
除此之外,EvalScope还集成了模型服务推理性能压测功能,可以一键测试服务的吞吐量、首包延迟等指标。在Qwen3系列模型上的评测(包括模型服务推理性能评测、模型能力评测、以及模型思考效率评测)可以参考这里:https://evalscope.readthedocs.io/zh-cn/latest/best_practice/qwen3.html
05.写在最后
在AI业界预测中,有不少声音认为AGI有望在几年内达到。也可以看到,目前Qwen3最受关注的模型系列,是Qwen3-32B、Qwen3-235B-A22B等尺寸模型,开发者的目光越来越转向能力更强、尺寸较大的模型,而模型的使用和关注,也影响了应用生态,例如数字人、Agent等领域的最新技术和方向。我们希望,魔搭的工具链可以不断适配模型尺寸的增大,以及训练评测的便捷化,并在开源领域推出新的训练技巧和新模型。开发者也可以持续关注我们社区(包括站点 www.modelscope.cn,以及github: https://github.com/modelscope/),我们会依托于等强大开源模型生态,不断构建新的模型能力和应用能力。
点击链接, 即可跳转Qwen3模型合集~
https://modelscope.cn/collections/Qwen3-9743180bdc6b48/?from=csdnzishequ_text

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)