
DeepSeek大模型全编译器接入指南:从VS Code到PyCharm的保姆级教程
作为国产大模型的“黑马”,凭借媲美GPT-4的性能和超低推理成本,已成为开发者提升效率的利器。本文为你揭秘,涵盖配置步骤、实战技巧与避坑指南,助你10分钟解锁AI编程超能力!
·
作为国产大模型的“黑马”,DeepSeek凭借媲美GPT-4的性能和超低推理成本,已成为开发者提升效率的利器。本文为你揭秘主流代码编译器接入DeepSeek的终极方案,涵盖配置步骤、实战技巧与避坑指南,助你10分钟解锁AI编程超能力!
一、主流编译器接入教程(附链接)
1️⃣ Cursor编辑器:AI优先的智能编程环境
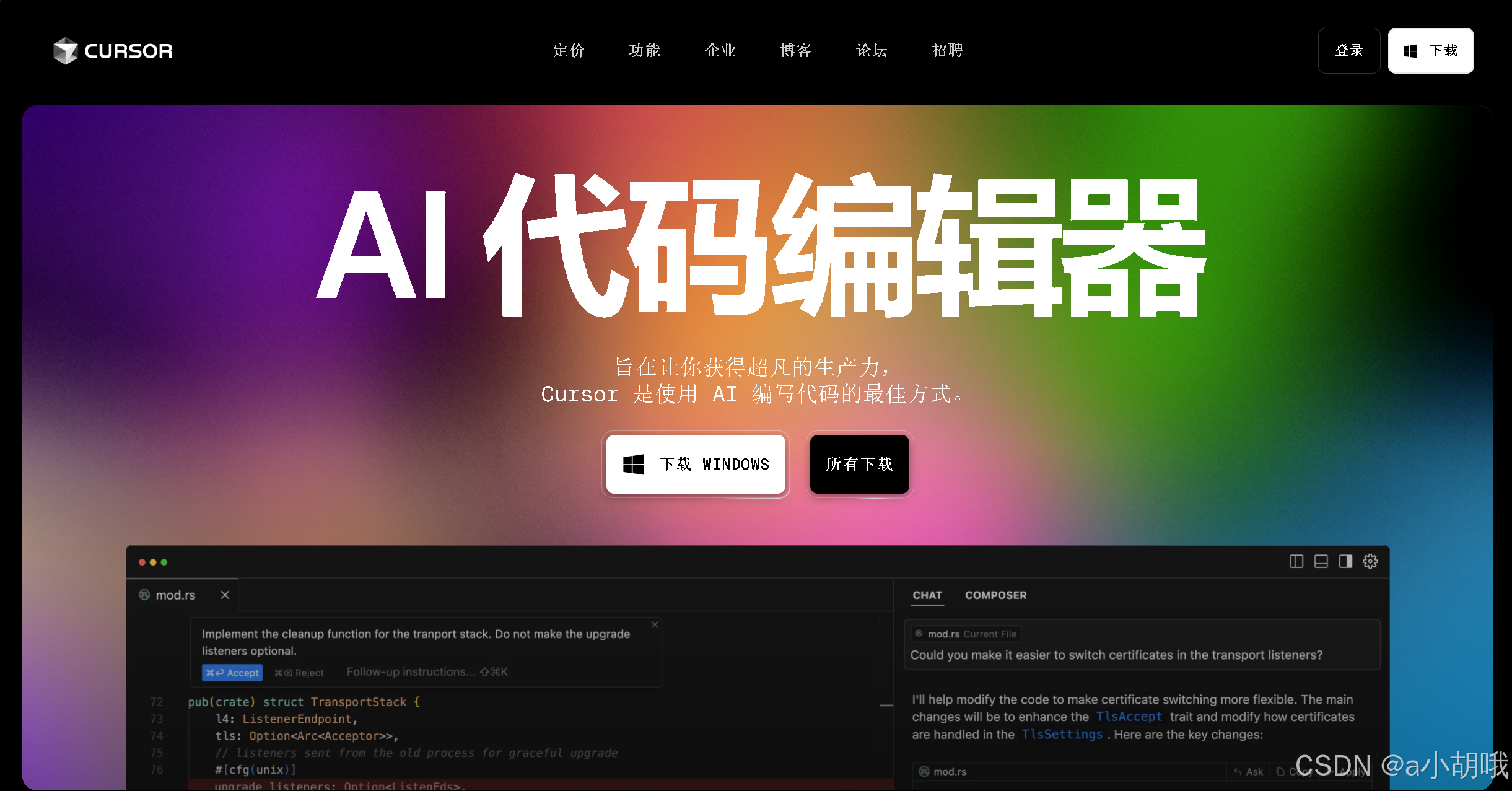
- 接入步骤:
- 下载Cursor:官网直达Cursor - The AI Code Editor
- 注册SiliconFlow账号并获取API Key:注册入口
- 配置模型:
File → Preference → Models → 添加模型名称:deepseek-chat Base URL:https://api.siliconflow.cn/v1 填入API Key后验证
- 核心优势:
- 智能代码补全、跨文件引用分析
- 支持深度思考模式(R1),解决复杂逻辑问题
2️⃣ Visual Studio Code:插件生态全覆盖
下载链接:Visual Studio Code - Code Editing. Redefined
- 推荐插件:
- DeepSeek Code Companion:实时生成代码注释与单元测试
- Comment2GPT:通过注释直接调用AI重构代码
- 配置技巧:
json
// settings.json "deepseek.apiKey": "your_key_here", "deepseek.model": "deepseek-coder-v2"
3️⃣ PyCharm/IntelliJ IDEA:本地部署+云端调用双方案
- 本地部署(适合隐私敏感场景):
- 安装Ollama:下载地址Download Ollama on Windows
- 运行命令:
ollama run deepseek-r1:1.5b - 安装CodeGPT插件 → 选择本地模型
- 云端调用(推荐新手):
使用OfficeAI插件 → 输入API Key即可
4️⃣ Neovim/Vim:极客专属配置
- 安装插件:llm.nvim--huggingface/llm.nvim: LLM powered development for Neovim
- 配置文件示例:
lua
require('llm').setup({ api_key = "your_key", model = "deepseek-r1", max_tokens = 2048 }) ```[9](@ref)
二、5大实战技巧提升效率300%
1️⃣ 精准提问法
- 错误示范❌:
帮我写个爬虫 - 正确姿势✅:
markdown
【语言】Python 【功能】爬取豆瓣电影TOP250数据 【要求】使用requests+BeautifulSoup,存储为CSV 【补充】需要处理反爬机制,每页间隔2秒 ```[16](@ref)
2️⃣ 代码分步调试
- 使用
/步骤指令分解复杂任务:markdown
1. 生成数据爬取框架 2. 添加异常处理逻辑 3. 优化XPath选择器 ```[16](@ref)
3️⃣ 模板化工作流
- 保存常用提示词为代码片段:
python
# deepseek_模板.py PROMPT_TEMPLATE = """ 你是一位资深{语言}开发者,请以{架构风格}风格编写代码: {功能描述} 要求:{具体要求} """
4️⃣ 本地部署避坑指南
- 最低配置:
- GPU:NVIDIA RTX 3060(12GB显存)
- 内存:32GB DDR4
- 推荐使用Ollama量化版模型
5️⃣ 隐私与安全策略
- 敏感数据:优先选择本地部署方案
- API密钥管理:
bash
# 环境变量设置 export DEEPSEEK_API_KEY='your_key' ```[10](@ref)
三、资源合集(建议收藏⭐)
- 🔗 DeepSeek官方API文档DeepSeek 开放平台
- 🔗 deepseek-ai/awesome-deepseek-integration
- 🔗 魔塔社区模型库 模型库首页 · 魔搭社区
🚀现在就去配置你的编译器吧!遇到问题欢迎在评论区留言,如果对你有帮助,记得点赞关注哦

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)