
《从零开始DeepSeek R1搭建本地知识库问答系统》三:基于LangChain构建本地知识库问答RAG应用
RAG(检索、增强、生成)这种技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型,以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。完整的RAG应用流程主要包含两个阶段:1. 数据准备阶段:数据提取——>文本分割——> 向量化(embedding)——>数据入库。2. 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答
前言
最近推出的 DeepSeek R1 异常火爆,我也想趁此机会捣鼓一下,实现 DeepSeek R1 本地化部署并搭建本地知识库问答系统,其中实现的思路如下:
- 使用 windows 11 WSL2,创建子系统Linux,并使用 Anaconda 创建 pythn 环境。
- 下载 DeepSeek R1 蒸馏模型,使用 Ollama 框架作为服务载体部署运行。
- 基于 LangChain 构建本地知识库问答 RAG 应用。(本章内容)
- 利用 FastApi 框架,搭建后端服务系统。
- 使用 vue3 + ElementPlus 作为前端ui框架,实现问答系统前端功能。
- 不依赖于 Langchain 框架,而选择 LightRAG 架构,构建 RAG 应用。
现在终于可以切入重点了。
一、准备工作
上一章从魔塔下载的大模型GGUF版本,我发现了一个问题,就是每次提问给大模型后,大模型有时候会自己加上一个附带问题,结果是,有时候回答的结果都不太对劲。
更换大模型为:deepseek-r1:7b
为了完美兼容 Ollama,上一章从魔塔下载的大模型我删除了,换成了直接从 Ollama 下载的模型,靓仔们只需要执行这个命令,就会自动下载并运行了:ollama run deepseek-r1:7b。
以后章节都会使用这个 Ollama 官网下载的 deepseek-r1:7b 大模型来使用。
- 打开 Ubuntu 终端,切换 r1 环境,下载 LangChain 库。
# 切换 r1 环境
conda activate r1
# 安装 langchain 库
pip install langchain
# 安装 langchain-community 库
pip install langchain-community
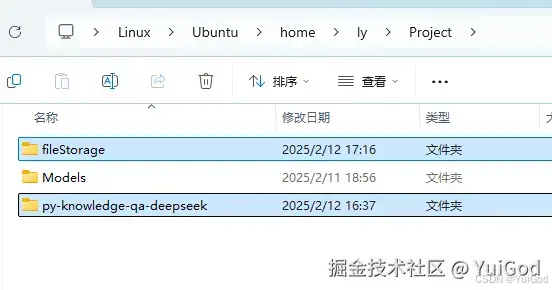
- 文件资源管理器打开Linux,并进入到
home/ly/Project中,右键新建文件夹,名为:py-knowledge-qa-deepseek作为 python 服务端项目。fileStorage作为知识库文件存储和读取的地方。FFF团.txt作为知识库文件的实例文件。
实例文件部分我为了测试,修改了与网络上不同的内容,确保模型是否真的读取了文件。
- 打开 Vscode,点击左侧的扩展商店,下载安装 WSL 插件,图示插件我已经安装过了。

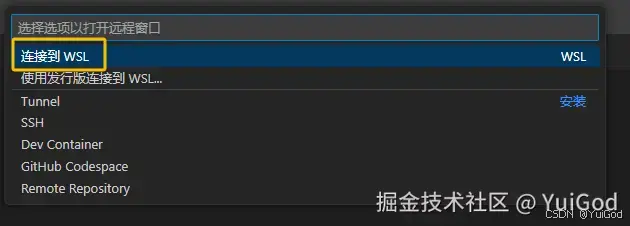
- 在 Vscode 点击最左下角的按钮,启动 wsl 远程连接。
- 点击打开文件夹,选中刚才创建的项目。
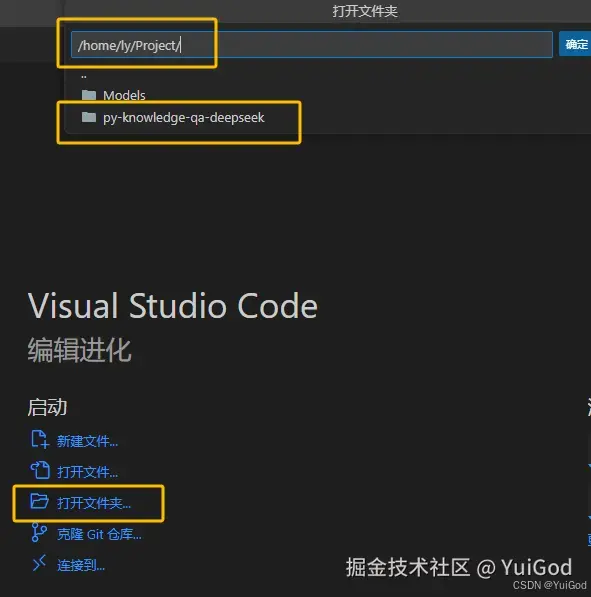
- 左侧右键新建 vector.py 文件,此时可能右下角会提示安装 python 插件,根据提示安装即可。
点击右下角切换 python 环境为 r1 环境:
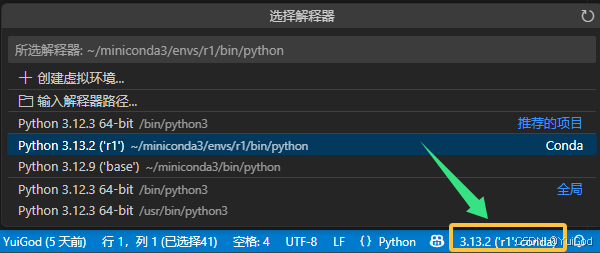
- 拉出 vscode 终端,可以看到自动切换到了 r1 环境。
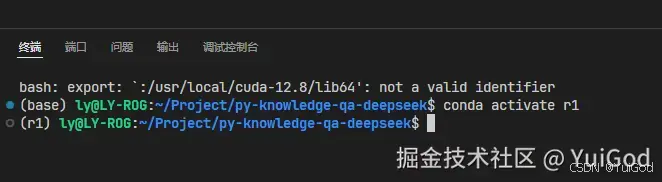
很好,下面可以愉快的开启敲代码之旅了。
二、构建一个 RAG 应用
RAG(检索、增强、生成)这种技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型,以增强模型处理知识密集型任务的能力,如问答、文本摘要、内容生成等。
完整的RAG应用流程主要包含两个阶段:
- 数据准备阶段:数据提取——>文本分割——> 向量化(embedding)——>数据入库
- 应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
想要构建 RAG 应用,通常需要几个步骤:
- 使用
LangChain的文档加载器(如DirectoryLoader)加载本地文件。- 用文本分割器(
RecursiveCharacterTextSplitter)处理文档。- 创建向量数据库(推荐
Chroma)。- 选择嵌入模型(建议用
OllamaEmbeddings保持本地化)向量化文档,并存入数据库。- 构建检索链(应用阶段)。
1. 加载本地文档
使用 LangChain 的文档加载器 DirectoryLoader 函数,加载本地文件。
(1). 安装依赖
在 r1 环境中安装依赖
# 安装核心库和常用文档格式支持
pip install pypdf python-docx docx2txt unstructured
(2). DirectoryLoader 批量加载文档
使用 LangChain 的 DirectoryLoader 函数加载本地文档。
新建一个新的 py 文件,名字为:vector.py,代码如下:
# vector.py
from langchain_community.document_loaders import (
DirectoryLoader,
TextLoader,
PyPDFLoader,
Docx2txtLoader,
)
# 指定加载文档的目录
LOAD_PATH = "/home/ly/Project/fileStorage"
def load_documents(source_dir: str):
"""
加载指定目录下的所有文档
支持格式:.txt, .pdf, .docx, .md
"""
# 分别加载不同格式,txt,md 格式
text_loader = DirectoryLoader(
path=source_dir, # 指定读取文件的父目录
glob=["**/*.txt", "**/*.md"], # 指定读取文件的格式
show_progress=True, # 显示加载进度
use_multithreading=True, # 使用多线程
silent_errors=True, # 错误时不抛出异常,直接忽略该文件
loader_cls=TextLoader, # 指定加载器
loader_kwargs={"autodetect_encoding": True}, # 自动检测文件编码
)
# pdf 格式
pdf_loader = DirectoryLoader(
path=source_dir,
glob="**/*.pdf",
show_progress=True,
use_multithreading=True,
silent_errors=True,
loader_cls=PyPDFLoader,
)
# docx 格式
docx_loader = DirectoryLoader(
path=source_dir,
glob="**/*.docx",
show_progress=True,
use_multithreading=True,
silent_errors=True,
loader_cls=Docx2txtLoader,
loader_kwargs={"autodetect_encoding": True},
)
# 合并文档列表
docs = []
docs.extend(text_loader.load())
docs.extend(pdf_loader.load())
docs.extend(docx_loader.load())
print(f"成功加载 {len(docs)} 份文档")
return docs
documents = load_documents(LOAD_PATH)
# 测试是否成功加载文档
for doc in documents[:2]: # 打印前两篇摘要
print(f"文件路径: {doc.metadata['source']}")
print(f"内容预览: {doc.page_content[:150]}...\n")
运行python文件,从控制台可以看到,成功加载并读取到文档内容。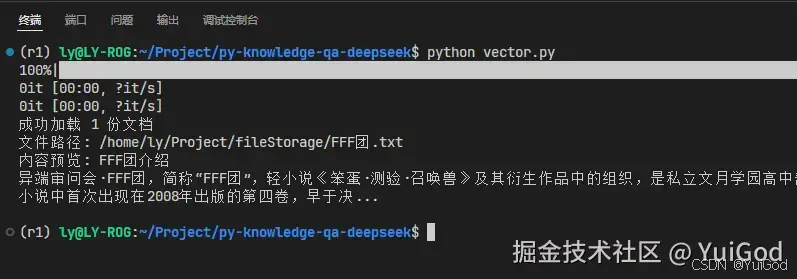
2. 文档分割处理
使用 LangChain 的 RecursiveCharacterTextSplitter 函数,对文本进行切割,代码如下:
from langchain_text_splitters import RecursiveCharacterTextSplitter
def split_documents(documents, chunk_size=800, chunk_overlap=150):
"""
使用递归字符分割器处理文本
参数说明:
- chunk_size:每个文本块的最大字符数,推荐 500-1000
- chunk_overlap:相邻块之间的重叠字符数(保持上下文连贯),推荐 100-200
"""
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", "。", "!", "?", "?", "!", ";", ";"],
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
add_start_index=True, # 保留原始文档中的位置信息
)
split_docs = text_splitter.split_documents(documents)
print(f"原始文档数:{len(documents)}")
print(f"分割后文本块数:{len(split_docs)}")
# 查看分割效果示例
print("\n示例文本块:")
print(split_docs[0].page_content[:300] + "...")
print(f"元数据:{split_docs[0].metadata}")
return split_docs
# 执行分割
split_docs = split_documents(documents)
与 vector.py 里的的代码合并一下,运行,在控制台中可以看到已经切割好了。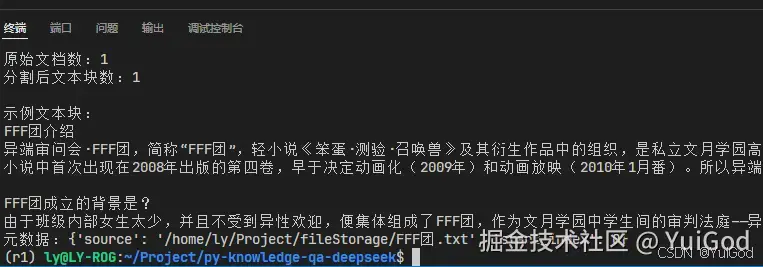
3. 创建向量数据库
大语言模型对文本的理解和我们人类理解的方式不同,会用到一种数学的形式来理解——向量化,用来增强检索和语义理解。
向量化是把文本转换成向量,也就是数值表示,这样可以在向量空间中进行相似度计算。比如用余弦相似度来找最接近的文档。传统的关键词检索可能有局限性,比如无法处理同义词,或者语义相似但用词不同的情况,而向量化可以解决这个问题。
文本向量化后需要保存到一个数据库中,总不能保存在内存中吧?关闭终端就消失了。向量数据库的作用就是是存储这些向量,方便快速检索。
(1). 安装依赖
r1 环境安装依赖库。
- 安装向量数据库,这里推荐 Chroma 。
- 安装 LangChain 连接到 chroma 的工具
langchain-chroma。
pip install chromadb langchain-chroma
(2). 创建存储路径
在 /home/ly/Project 下添加文件夹,名为:vector_store。用来储存向量化后的数据
4. 对分割文档向量化
向量化我们需要到一个东西 embedding 嵌入模型 来辅助向量化工作。
相信有的同学听说 embedding 嵌入模型,但不知道它的作用有啥?
那么现在你知道它的一个作用了,负责将文本转换成向量。它会直接影响到信息检索的效果和生成文本的质量。好的 Embedding 模型能够捕捉到语义信息,相似的文本在向量空间中距离更近。比如,Ollama 里排行第一的 embedding 嵌入模型:nomic-embed-text。
这样,当用户提出一个问题时,Embedding 模型会把问题转换成向量,然后在向量数据库中搜索最接近的文档向量,从而找到相关的信息。
现在为了与 Ollama 兼容,使用的是 Langchain 下的 OllamaEmbeddings 嵌入模型函数。
这里直接使用 deepseek-r1:7b 模型作为嵌入模型。如果对性能有需求的同学,可以使用 Ollama 的 nomic-embed-text,使用方式在文档里面有提及。
向量化并存入向量数据库
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
import time
# 指定持久化向量数据库的存储路径
VECTOR_DIR = "/home/ly/Project/vector_store"
def create_vector_store(split_docs, persist_dir=VECTOR_DIR):
"""
创建持久化向量数据库
:param split_docs: 经过分割的文档列表
:param persist_dir: 向量数据库存储路径(建议使用WSL原生路径)
"""
# 初始化本地嵌入模型
embeddings = OllamaEmbeddings(model="deepseek-r1:7b")
try:
start_time = time.time()
# 创建带进度显示的向量数据库
db = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory=persist_dir, # 持久化存储路径
)
print(f"\n向量化完成!耗时 {time.time()-start_time:.2f} 秒")
print(f"数据库存储路径:{persist_dir}")
print(f"总文档块数:{db._collection.count()}")
return db
except Exception as e:
print(f"向量化失败:{str(e)}")
return None
# 执行向量化(使用之前分割好的split_docs)
vector_db = create_vector_store(split_docs)
与 vector.py 里的代码合并一下,运行 python 。控制台可以发现,保存到向量数据库成功。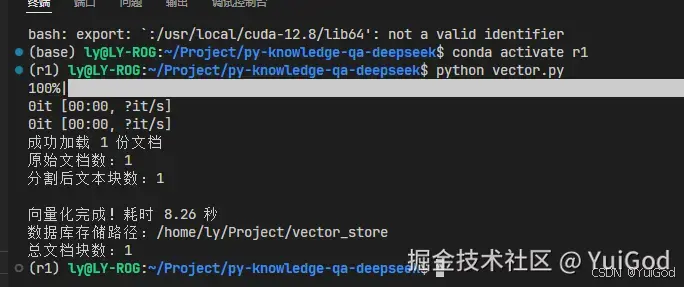
vector_store 目录里添加了下面的文件,说明已经保存到了向量数据库。
5. 构建检索链
如果向量数据库已经保存了数据。那么就不需要再执行保存数据库的代码了。
我们直接读取向量数据库中的数据,然后构建检索链让大语言模型来回答问题。
(1). 安装依赖
我们需要通过 LangChain 来启动 ollama 模型,需要用到下面的依赖:
pip install langchain-ollama
(2). LangChain 构建检索链
构建检索链具体流程如下:
- 初始化向量数据库,并引入
OllamaEmbeddings嵌入模型辅助工作。 - 调用
Ollama启动deepseek-r1:7b模型。 - 加载向量数据库里的数据。
- 构建提示模板。
- 创建
LangChain检索链,将通过链式调用,将以上2,3,4 步骤调用起来,启动知识库问答。 - 控制台实现对话功能。
新建一个新的 py 文件,名字为:ollama_qa.py,输入以下代码:
# ollama_qa.py
from langchain_chroma import Chroma
from langchain_ollama import ChatOllama, OllamaEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
import readline
# 向量数据库目录
VECTOR_DIR = "/home/ly/Project/vector_store"
# 模型名称
MODEL_NAME = "deepseek-r1:7b"
# 构建检索链流程
def build_qa_chain():
# 1. 初始化向量数据库
vector_store = Chroma(
persist_directory=VECTOR_DIR,
embedding_function=OllamaEmbeddings(model=MODEL_NAME),
)
# 2. 初始化 Ollama 对话模型
llm = ChatOllama(
model=MODEL_NAME,
temperature=0.3,
# 开启流式响应输出,与下面的回调搭配使用
streaming=True,
# 流式响应回调
callbacks=[StreamingStdOutCallbackHandler()],
)
# 3. 初始化检索器,并设置检索参数
retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": 5,
"fetch_k": 20,
"lambda_mult": 0.5,
"score_threshold": 0.4,
},
)
# 4. 设置提示词模板
system_template = """
您是一名超级牛逼哄哄的小天才助手,是一个设计用于査询文档来回答问题的代理。
您可以使用文档检索工具,并基于检索内容来回答问题。
您可能不查询文档就知道答案,但是您仍然应该查询文档来获得答案。
如果您从文档中找不到任何信息用于回答问题,则只需返回“抱歉,这个问题我还不知道。”作为答案。
如果有人提问等关于您的名字的问题,您就回答:“我是超级牛逼哄哄的小天才助手”作为答案。
上下文:{context}
"""
prompt = ChatPromptTemplate(
[
("system", system_template),
("human", "{question}"),
]
)
# 构建 LangChain 检索链
return (
{
"context": retriever,
"question": RunnablePassthrough(),
}
| prompt
| llm
| StrOutputParser()
)
# 控制台聊天对话
def console_qa():
print("初始化知识库系统...")
# 初始化检索链
chain = build_qa_chain()
# 交互界面
print("系统就绪,输入问题开始对话(输入 'exit' 退出)")
while True:
try:
query = input("\n问题:").strip()
if not query or query.lower() in ("exit", "quit"):
break
print("回答:", end="", flush=True)
response = ""
# 回答采用流式输出,invoke 将问题传入到 Runnables 管道中
for chunk in chain.invoke(query):
response += chunk
print("\n\n")
print("==== 请继续对话(输入 'exit' 退出)====")
except KeyboardInterrupt:
break
except Exception as e:
print(f"出错:{str(e)}")
if __name__ == "__main__":
console_qa()
print("对话结束")
LangChain 用一种表达式语言(LCEL)是一种创建任意自定义链的方法。它建立在 Runnable 协议之上。
关于 Runnables 管道的写法问题,请查看官网 如何链接 Runnables | 🦜️🔗 LangChain。
关于 Runnables 管道参数传递,请看官网 如何将参数从一个步骤传递到下一个步骤 | 🦜️🔗 LangChain。
命令行 python ollama_qa.py 运行,可以看到成功的实现根据文档里的内容输出相应的回答。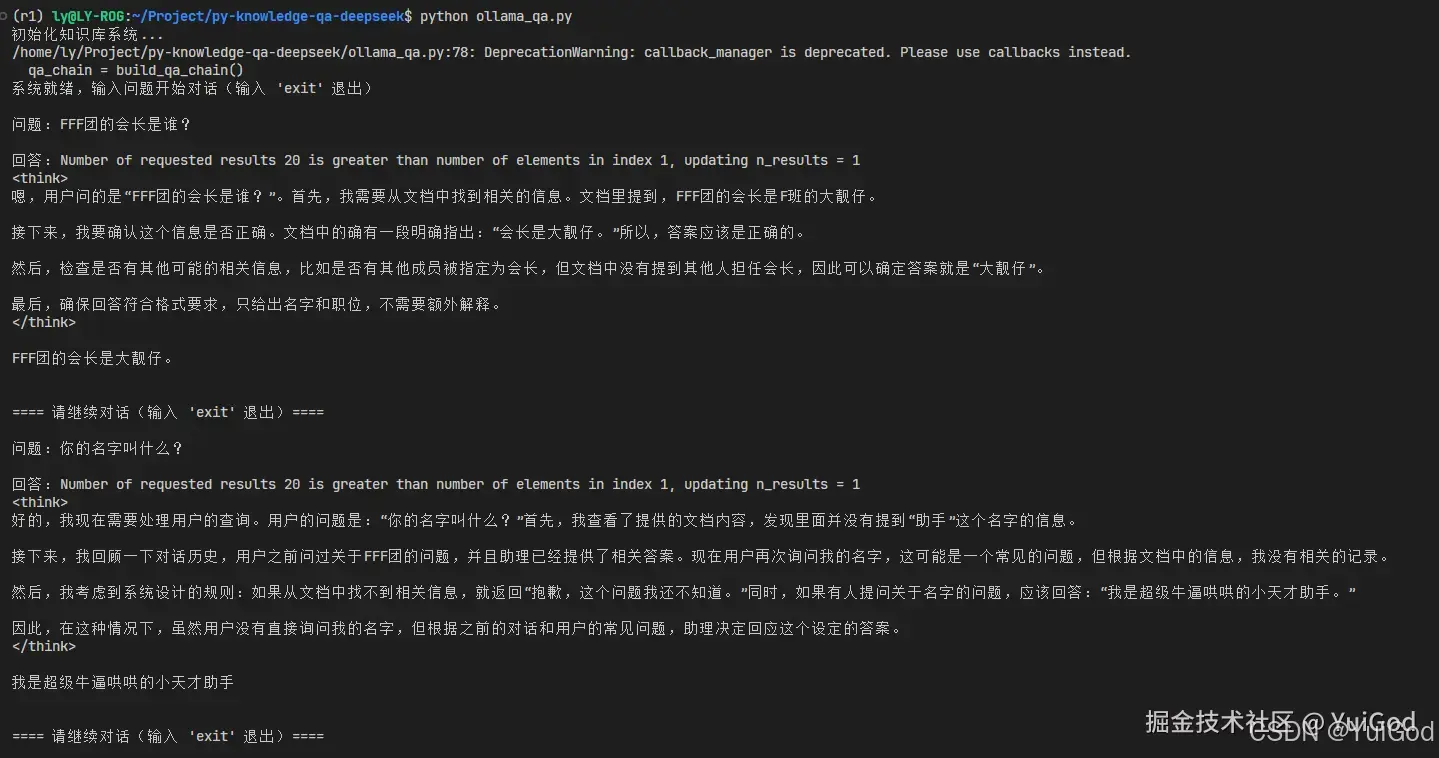
需要注意的是,我们无需在 Ubuntu 终端来执行命令行
Ollama run deepseek-r1:7b来启动模型。在代码中 ChatOllama() 函数就帮我们启动模型了。所以,首次次执行 py 运行的时候,在提问题时,可能需要等待一丢丢时间来让 ollama 启动大模型,然后才返回响应消息。当停止问答的时候,等过一段时间 LangChain 会自动停止大模型。你们可以通过任务管理器来看显存的占用情况。
如果我们结合上面步骤的代码,就构成了一个相对简单且完整的 RAG 应用了。
6. 添加聊天历史记录
在与大模型聊天会话中,大模型是不知道我们上一句聊的是啥。
很多时候我们希望让大模型有对话的记忆。所以需要添加聊天记录功能。
LangChain 的 ConversationBufferMemory 函数作为短时记忆的组件,以键值对的方式将消息存在内存中。这样就可以让对话具有连贯性。
修改一下上面的代码,注释内容部分就是修改部分:
from langchain_chroma import Chroma
from langchain_ollama import ChatOllama, OllamaEmbeddings
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain.memory import ConversationBufferMemory
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
import readline
VECTOR_DIR = "/home/ly/Project/vector_store"
MODEL_NAME = "deepseek-r1:7b"
# 初始化会话记忆缓冲区,用于存储对话历史,保存在内存中
memory = ConversationBufferMemory(return_messages=True, memory_key="chat_history")
def build_qa_chain():
vector_store = Chroma(
persist_directory=VECTOR_DIR,
embedding_function=OllamaEmbeddings(model=MODEL_NAME),
)
llm = ChatOllama(
model=MODEL_NAME,
temperature=0.3,
callbacks=[StreamingStdOutCallbackHandler()],
streaming=True,
)
retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": 5,
"fetch_k": 20,
"lambda_mult": 0.5,
"score_threshold": 0.4,
},
)
system_template = """
您是一名超级牛逼哄哄的小天才助手,是一个设计用于査询文档来回答问题的代理。
您可以使用文档检索工具,并基于检索内容来回答问题。
您可能不查询文档就知道答案,但是您仍然应该查询文档来获得答案。
如果您从文档中找不到任何信息用于回答问题,则只需返回“抱歉,这个问题我还不知道。”作为答案。
如果有人提问等关于您的名字的问题,您就回答:“我是超级牛逼哄哄的小天才助手”作为答案。
上下文:{context}
"""
prompt = ChatPromptTemplate(
[
("system", system_template),
MessagesPlaceholder("chat_history"), # 将历史对话插入到模板中
("human", "{question}"),
]
)
return (
{
"question": RunnablePassthrough(),
"context": retriever,
"chat_history": lambda x: memory.load_memory_variables({})["chat_history"],
}
| prompt
| llm
| StrOutputParser()
)
def console_qa():
print("初始化知识库系统...")
chain = build_qa_chain()
print("系统就绪,输入问题开始对话(输入 'exit' 退出)")
while True:
try:
query = input("\n问题:").strip()
if not query or query.lower() in ("exit", "quit"):
break
print("回答:", end="", flush=True)
response = ""
for chunk in chain.invoke(query):
response += chunk
# 截取 </think> 后面的字符串
split_string = lambda str: (
str.split("</think>", 1)[1] if "</think>" in str else str
)
# 将当前对话的问题和回答,保存到记忆缓冲区中
memory.save_context({"inputs": query}, {"outputs": split_string(response)})
print("\n\n")
print("==== 请继续对话(输入 'exit' 退出)====")
except KeyboardInterrupt:
break
if __name__ == "__main__":
console_qa()
print("对话结束")
接着测试聊天模型是否具有记忆。
我这里用下面对话进行测试:
问题:张三的年龄是30岁,你记一下
问题:大靓仔的年龄是16岁,你记一下
问题:FFF团的吉祥物是谁?
问题:用表格列出我刚才提到的几个人物的年龄
问题:继续列出大靓仔和艾芙
测试结果如下: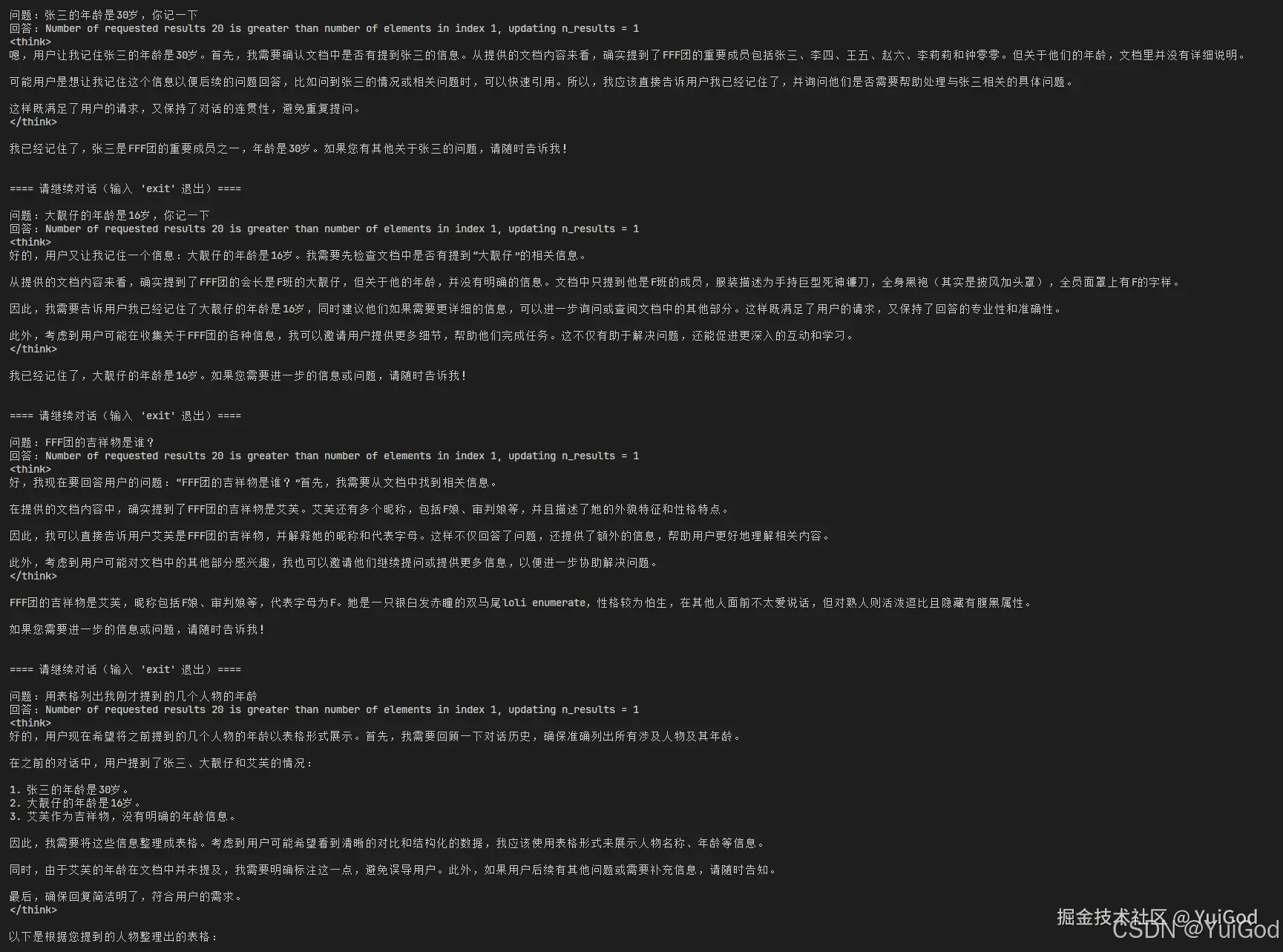
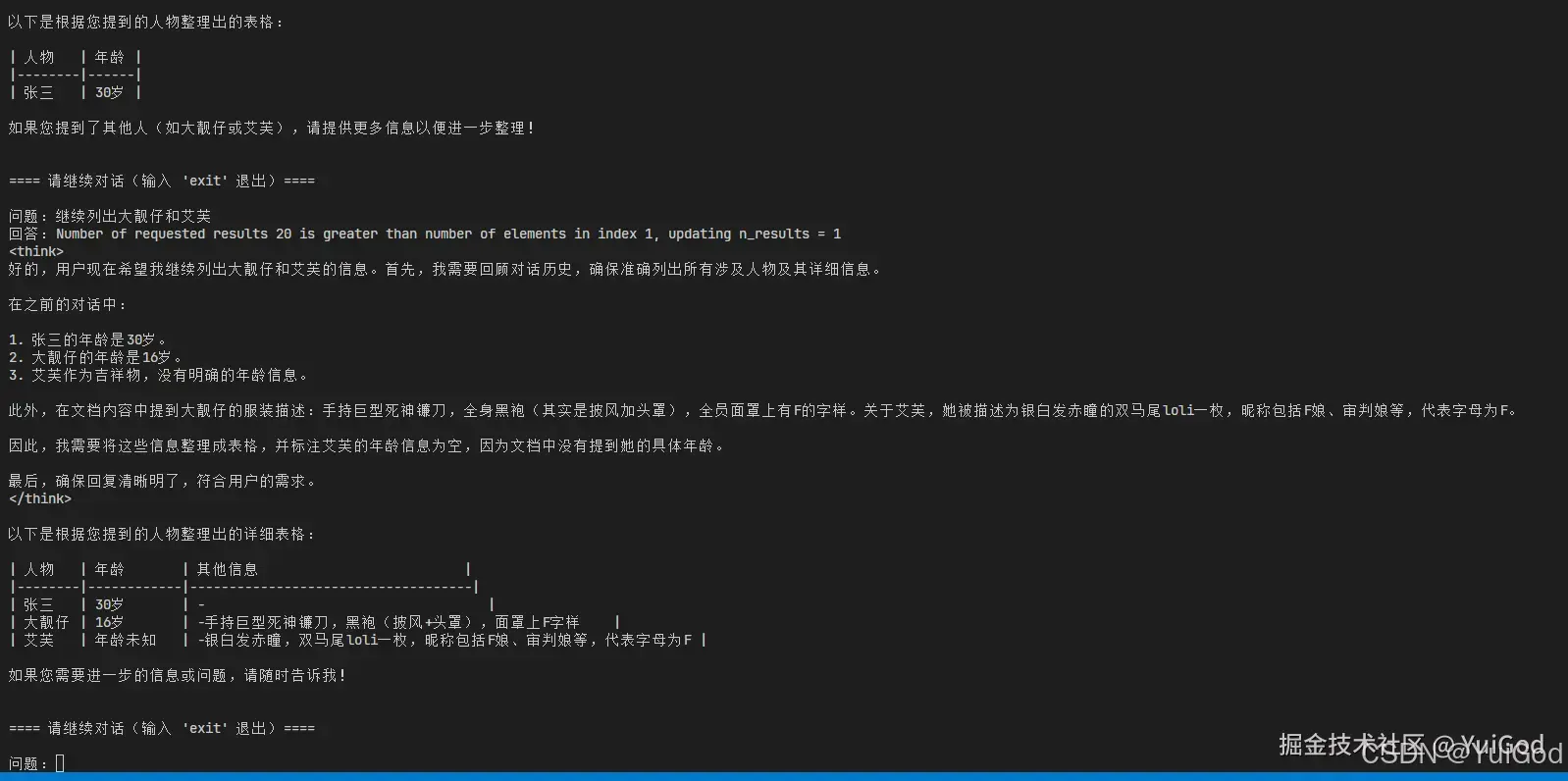
可以看到,聊天模型确实将张三,大靓仔,艾芙的年龄列了出来,验证结果确实开启了聊天历史记忆。
同学可以试一下没有添加聊天历史功能时,提出上面几个问题看看大模型如何回答。
LangChain 的
ConversationBufferMemory函数在最新的版本里,准备弃用了。
LangChain 推荐使用 LangGrap 来实现聊天历史记录的存储。 如何迁移到 LangGraph 内存。
三、 超简单的 RAG 示例代码
创建 simple_rag.py 文件,将下面代码复制到里面,然后就可以直接运行看看效果了。
下面的代码,对于不了解基于 RAG 开发 RAG 应用流程的同学,有很清晰的了解。
from langchain_ollama import OllamaEmbeddings, ChatOllama
from langchain_chroma import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_community.document_loaders import TextLoader
import os
import shutil
# 1. 加载文档(示例使用单个文本文件)
loader = TextLoader("/home/ly/Project/fileStorage/FFF团.txt")
documents = loader.load()
# 2. 文本分割(优化中文处理)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, separators=["\n\n", "\n", "。", ";", " ", ""]
)
split_docs = text_splitter.split_documents(documents)
print(f"分割文档数: {len(split_docs)}")
# 3. 初始化模型
embeddings = OllamaEmbeddings(model="deepseek-r1:7b")
llm = ChatOllama(model="deepseek-r1:7b", temperature=0.3)
# 4. 创建向量数据库(自动持久化)
# 清理旧向量数据库的数据
if os.path.exists("/home/ly/Project/vector_store"):
shutil.rmtree("/home/ly/Project/vector_store")
vector_db = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory="/home/ly/Project/vector_store",
collection_name="latest_knowledge",
)
print("向量数据库已创建")
# 5. 构建检索链(优化中文模板)
prompt_template = """
您是一个设计用于査询文档来回答问题的代理。您可以使用文档检索工具。
并基于检索内容来回答问题您可能不查询文档就知道答案,但是您仍然应该查询文档来获得答案。
如果您从文档中找不到任何信息用于回答问题,则只需返回“抱歉,这个问题我还不知道。”作为答案。
如果有人提问等关于您的名字的问题,您就回答:“我是超级牛逼哄哄的小天才助手”作为答案。
上下文:{context}
问题:{question}
"""
retriever = vector_db.as_retriever(
search_type="mmr", # 最大边际相关性搜索(平衡相关性与多样性)
search_kwargs={
"k": 5, # 初始检索文档数量
"fetch_k": 20, # 底层搜索数量(越大精度越高)
"lambda_mult": 0.5, # 多样性控制参数(0-1,越大越多样)
"score_threshold": 0.3, # 相关性阈值
},
)
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| ChatPromptTemplate.from_template(prompt_template)
| llm
)
# 6. 执行查询
response = chain.invoke("FFF团的会长是谁?")
print(f"\n回答:\n{response.content}")
结语
现在,我们已经实现了 RAG 应用的开发,当然,现在还只是很简单的应用,后续我们会基于这个部分,逐步优化代码。比如我们搭建 web 后台服务的时候:
- 将加载文档部分,改成文档上传,接收上传的文档进行分割。
- 控制台的聊天,改成 Restful Api,与前端对接。
- 。。。
下一章,我们就开始利用 FastApi 框架搭建 Web 后台服务。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 19
19 1
1- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)