
11 大模型学习——模型微调-LoRA
微调定制化功能和领域知识学习。Hugging Face 的 PEFT(Parameter-Efficient Fine-Tuning)库是一个用于高效微调预训练语言模型的工具包,目前支持Prefix Tuning、Prompt Tuning、PTuningV1、PTuningV2、Adapter、LoRA、AdaLoRA等微调方法。
一、为什么需要微调?
1、幻觉
2、知识截至
原有的大模型对特定领域的知识不够用。因此需要行业大模型/垂直大模型
一般通用大模型的训练数据为全网公开的一些数据,训练时间节点为某个时间点之前
解决方案:
1、RAG(外挂知识库)
2、微调(定制化模型功能)
3、重新训练模型,即全参微调(成本高,难度大)
当知识库数据会经常变化时,选择RAG,反之可以选择微调,但是一般能够不微调就不要微调
二、微调Fine-tuning
1、定义
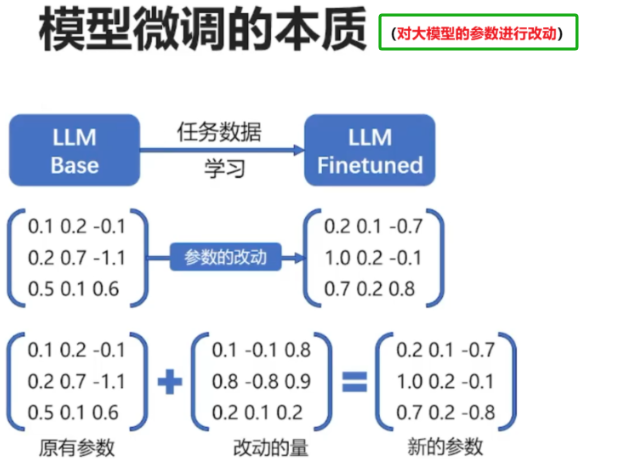
大模型微调是利用特定领域的数据集对已经预训练的大模型进一步训练的过程。旨在优化模型在特定任务上的性能,使模型能够更好的适应和完成特定领域的任务。
核心:定制化功能和领域知识学习
2、微调的方式
(1)全量微调
全量微调利用特定任务数据调整预训练模型的所有参数,以充分适应新任务。它依赖大规模计算资源,但能有效利用预训练模型的通用特征。
存在问题:成本高、难度大、参数结果难保障
(2)局部微调
只对模型的部分层(如顶层或特定模块)进行微调,其余层冻结。优点:节省计算资源,减少过拟合风险。缺点:可能无法充分适应目标任务。
适用场景:目标任务与预训练任务相似,或资源有限时。
(3)⭐参数高效微调(PEFT)
PEFT(Parameter-Efficient Fine-Tuning)旨在通过最小化微调参数数量和计算复杂度,实现高效的迁移学习。它仅更新模型中的部分参数,显著降低训练时间和成本,适用于计算机资源有限的情况。
大模型参数高效微调的方法包括LoRA(重点)、Prompt Tuning、BitFit、P-Tuning、Prefix-Tuning和IA3等等,这些方法通过减少训练参数量或计算成本来实现高效微调,各有优缺点,需根据任务需求和资源选择
3、⭐模型微调流程
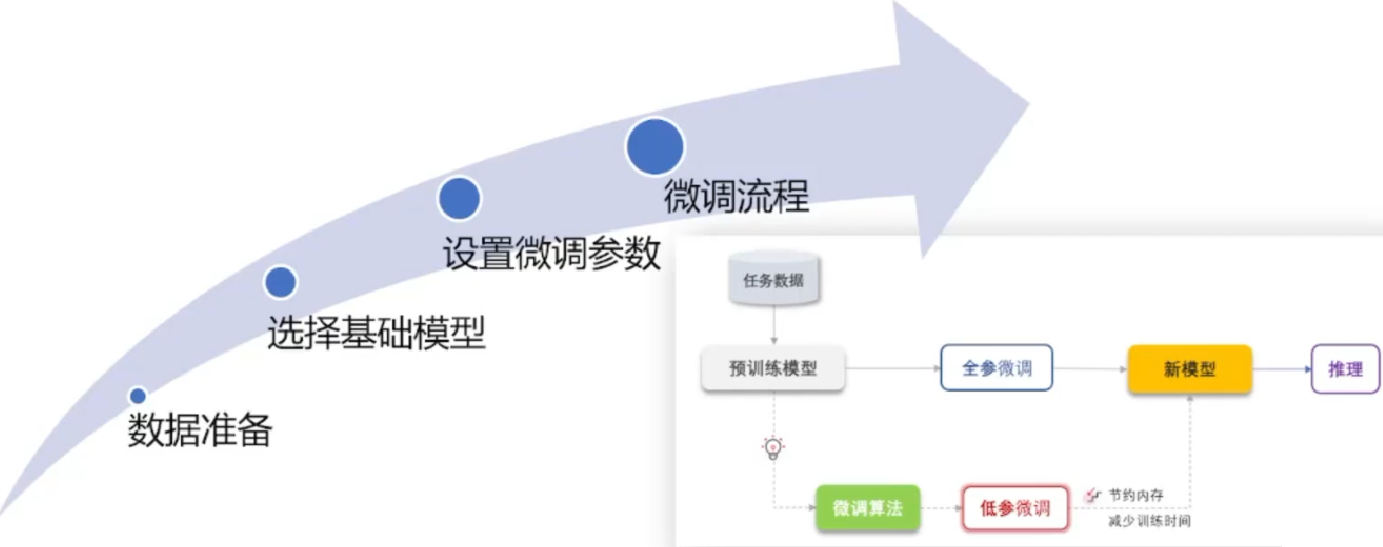
- 数据准备,准备特定领域的数据
- 选择基础模型,首先根据成本、GPU、数据量确定基础模型的规模大小;准备10-20个专业问题,分别输入对比的基础模型,看谁的效果更好
- 设置微调参数,超参数:学习率、训练轮次、批处理大小、权重衰减、梯度剪切
- 微调流程
三、LoRA微调
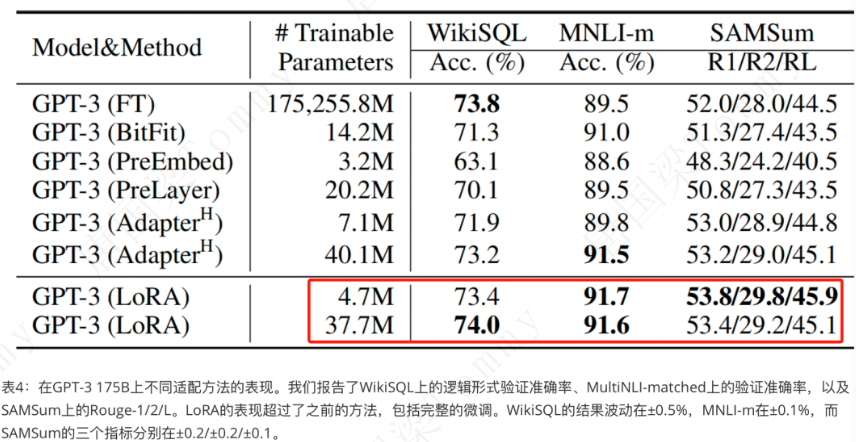
1、LoRA的优势
为什么用LoRA:成本低(参数少)、准确率高
2、⭐LoRA微调原理(Low Rank Adaption-低秩适配)
秩:一个矩阵的秩是指矩阵中线性独立行或列的最大数目
线性独立(线性无关)是指一组向量中没有任何一个向量可以表示为其他向量的线性组合。线性独立意味着向量组中的每个向量都提供了独特的信息,无法通过其他向量的线性组合来表示。
一个矩阵的秩越大,它的信息含量就越大。
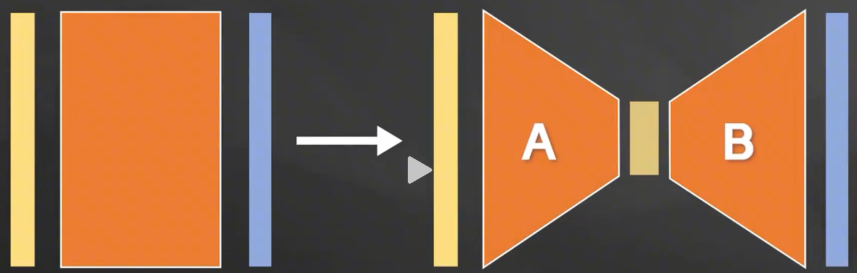
Lora(低秩适配):把一个秩比较大的矩阵变成秩比较小的矩阵(参数变少)
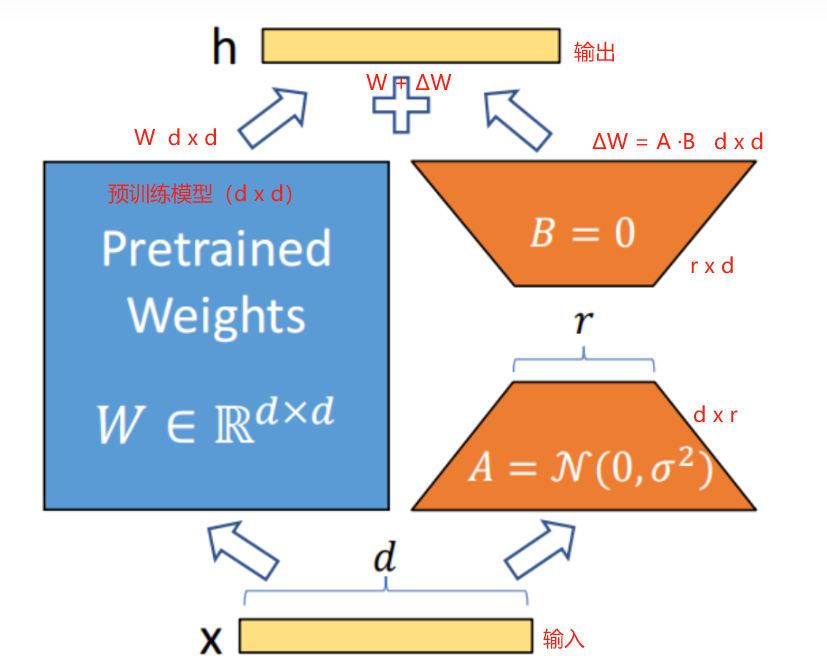


3、低秩矩阵分解
低秩矩阵分解是一种将高维矩阵近似为两个低维矩阵乘积的技术,常用于数据降维、压缩、推荐系统等领域。


import numpy as np
import matplotlib.pyplot as plt
# 初始化矩阵 W
W = np.array([[4, 3, 2, 1],
[2, 2, 2, 2],
[1, 3, 4, 2],
[0, 1, 2, 3]])
# 矩阵的维度
d = W.shape[0]
# 秩
r = 2
# 随机初始化A和B
np.random.seed(666) # 固定随机种子
# A服从正态分布,B=0
A = np.random.randn(d, r)
B = np.zeros((r, d))
# 定义超参数
lr = 0.01 # 学习率
epochs = 1000 # 训练轮次
# 定义损失函数
def loss_function(W, A, B):
W_approx = A @ B # np.matmul()
# 均方差损失函数
return np.linalg.norm(W - W_approx, 'fro') ** 2
# 定义梯度下降法
def descent(W, A, B, epochs):
# 存储历史损失值
loss_history = []
for i in range(epochs):
# 计算梯度
W_approx = A @ B
# 计算损失函数关于矩阵A的梯度
gd_A = -2 * (W - W_approx) @ B.T
# 计算损失函数关于矩阵B的梯度
gd_B = -2 * A.T @ (W - W_approx)
# 使用梯度下降算法更新A和B
A -= lr * gd_A
B -= lr * gd_B
# 计算当前损失
loss = loss_function(W, A, B)
loss_history.append(loss)
if i % 100 == 0:
print(f"epoch:{i},loss:{loss}")
return A, B, loss_history
if __name__ == '__main__':
A, B, loss_history = descent(W, A, B, epochs)
# 绘制损失曲线
plt.figure(figsize=(8, 6))
plt.plot(loss_history, label='loss')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.grid(True)
plt.show()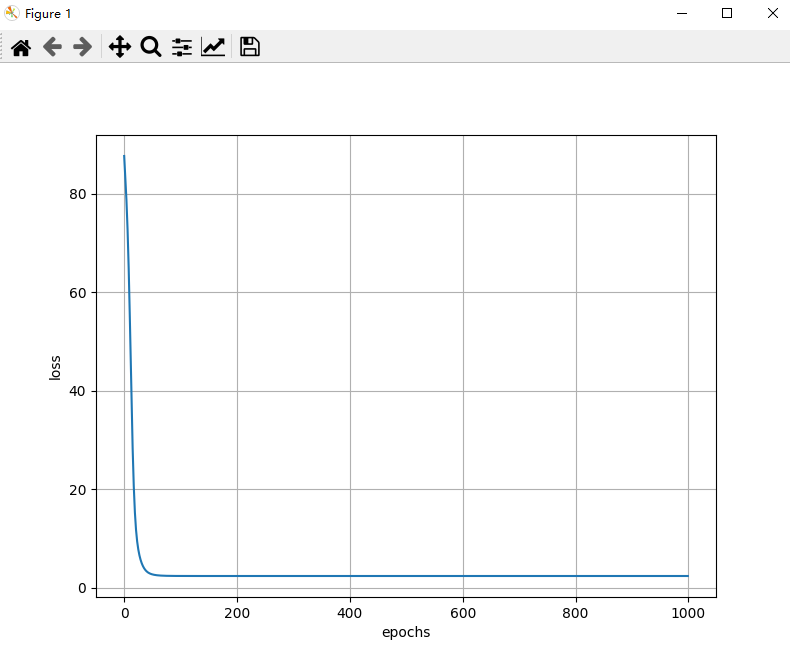
4、A和B初始化问题
(1)为什么初始化参数采用正态分布?

(2)为什么矩阵B、A不能同时为0?

5、权重矩阵适配
(1)选择哪些权重矩阵进⾏适配?
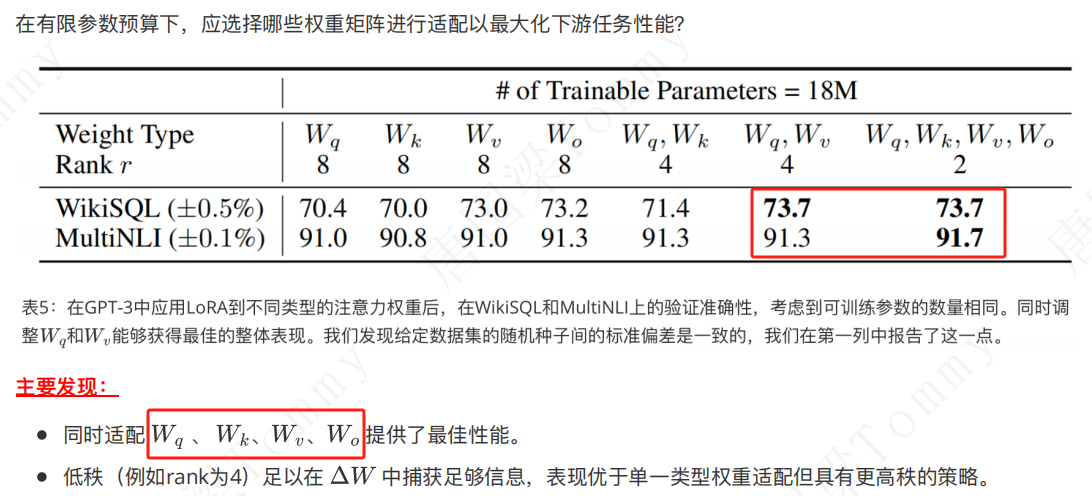
(2)为什么 LoRA 在 Q, K, V, O 上有效?
LoRA(Low-Rank Adaptation)在 Transformer 模型的 Q(Query)、K(Key)、V(Value)和 O(Output)矩阵上有效果的原因可以归结为这些矩阵在注意⼒机制中的核⼼作⽤以及 LoRA ⽅法在降低参数数量的同时保持或提升模型性能的能⼒。具体原因如下:
- Q(Query)矩阵:⽤于⽣成查询向量,决定模型在注意⼒机制中对输⼊的关注程度。
- K(Key)矩阵:⽤于⽣成键向量,与查询向量计算相似度,帮助确定注意⼒分布。
- V(Value)矩阵:⽤于⽣成数值向量,实际传递注意⼒机制计算的输出。
- O(Output)矩阵:⽤于将多头注意⼒的输出合并并映射回原始维度。
Q、K 、V 和O 矩阵在信息传播和特征表示中起着关键作⽤:
- 查询与键的交互: Q和K的交互决定了注意力分布,影响模型对输⼊序列的不同部分的关注度。
- 数值的加权求和: 矩阵通过加权求和操作,将注意⼒分布转化为具体的输出。
- 多头输出的整合: 矩阵整合多头注意⼒的输出,提供最终的特征表示。
LoRA 通过将权重矩阵分解为两个低秩矩阵(例如 W=BA),减少了参数数量,降低了计算和存储成本,同时保持模型性能:
- 参数压缩:Q 、K 、V 和O 矩阵通常包含⼤量参数,LoRA 的低秩分解显著减少了需要优化的参数数量。
- 性能保持:低秩矩阵能够捕捉到原始矩阵的主要信息,确保模型性能不受显著影响。
(3)LoRA中的最优秩 r 的选择?
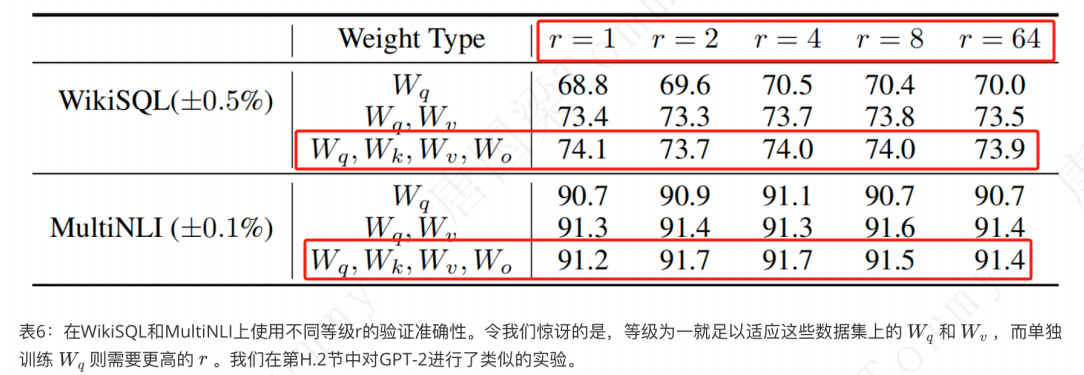
- LoRA 即使在非常小的秩下也展现出了竞争力的性能。
- 在同时适配Q 、K 、V 和O 多个矩阵时比仅适配部分矩阵表现更好。
- 增加过大的秩并没有覆盖更多有意义的⼦空间,说明低秩适配矩阵已⾜够。
根据经验选择,一般 r = 8
(4)LoRA可以应用到模型中的哪些层?
LoRA(Low-Rank Adaptation)可以插⼊到模型的多个地⽅,具体取决于需要微调的模型部分和任务要求。以下是⼀些常见的插⼊位置及其原因:
线性层(全连接层)

注意力层

嵌入层

四、Hugging Face PEFT 介绍
Hugging Face 的 PEFT(Parameter-Efficient Fine-Tuning)库是一个用于高效微调预训练语言模型的工具包,目前支持Prefix Tuning、Prompt Tuning、PTuningV1、PTuningV2、Adapter、LoRA、AdaLoRA等微调方法。它专注于在保持高性能的同时,减少微调过程中需要更新的参数数量,从而降低计算成本和内存需求。
pip install peft -i ...

lora_alpha 缩放因子:缩放因子和学习率共同控制参数更新幅度。


五、⭐使用HF实现LoRA微调
1、基础模型下载
可以在huggingface或魔塔社区下载模型源码,以魔塔下载为例
先配置魔塔下载环境,pip install modelscope -i ... (可以新建一个环境来下载,避免部分库版本冲突)
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-1.5B-Instruct',cache_dir="./model/Qwen")2、模型训练
import torch
from torch.utils.data import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForLanguageModeling, Trainer, \
TrainingArguments
from peft import LoraConfig, get_peft_model, TaskType
from langchain.text_splitter import RecursiveCharacterTextSplitter
import re
# os.environ["CUDA_VISIBLE_DEVICES"]='0'
# 设置文本文件路径
txt_file_path = r"data/峨眉山讲解词.txt"
# 设置模型路径
model_name = r"D:\bigmodel_code\Qwen2.5-1.5B-Instruct"
# 设置微调后模型保存的路径
finetuned_model_path = r"qwen2.5_lora_finetuned"
# 数据处理
# 加载预训练模型的tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "(?<=\。!?)", " ", ""], # 分隔符优先级,添加中文分隔符((?<=\。!?)正向后行断言,保留标点符号)
chunk_size=300, # 每个文本块的最大长度
chunk_overlap=50, # 相邻文本块之间的重叠长度
length_function=len # 长度函数
)
# 自定义数据集(处理数据)
class CustomTextDataset(Dataset):
def __init__(self, tokenizer, file_path, text_splitter):
super().__init__()
self.tokenizer = tokenizer
self.text_splitter = text_splitter # 每个数据块的大小,输入序列的长度
self.examples = []
# 读取文件
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
# 数据清洗
new_line = re.compile(r'[^\u4e00-\u9fff](\n)[^\u4e00-\u9fff]', re.DOTALL)
text = re.sub(new_line, lambda match: match.group(0).replace("\n", ""), text)
# 把文本分割成固定大小的块
chunks = text_splitter.split_text(text)
# 对文本进行分词
for chunk in chunks:
tokenizer_text = tokenizer.tokenize(chunk)
self.examples.append(self.tokenizer.convert_tokens_to_ids(tokenizer_text))
def __len__(self):
return len(self.examples)
def __getitem__(self, index):
return torch.tensor(self.examples[index], dtype=torch.long)
# 使用dataset创建数据集
dataset = CustomTextDataset(tokenizer, txt_file_path, text_splitter)
# dataset[0]
# 创建模型数据处理器
data_colloator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # 准备数据以进行标准语言模型任务
)
# 加载预训练模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
local_files_only=True # 仅从本地文件加载模型
)
print(model)
# Lora配置
lora_config = LoraConfig(
r=8, # 秩,根据具体情况调整
lora_alpha=16, # 用于缩放Lora权重更新
target_modules=['self_attn.q_proj', 'self_attn.k_proj', 'self_attn.v_proj', 'self_attn.o_proj'],
lora_dropout=0.1,
bias='none',
task_type=TaskType.CAUSAL_LM
)
# 获取应用Lora后的微调模型
model = get_peft_model(model, lora_config)
print(model)
model.print_trainable_parameters()
# 训练参数配置
training_args = TrainingArguments(
output_dir=finetuned_model_path, # 输出目录
overwrite_output_dir=True, # 覆盖输出目录的现有内容
per_device_train_batch_size=6, # 每个设备上训练批次大小
learning_rate=1e-4, # 学习率
weight_decay=0.01, # 权重衰减
num_train_epochs=3, # 训练轮次
logging_steps=100,
save_strategy="epoch",
save_total_limit=3,
# load_best_model_at_end=True,
eval_strategy="no", # 禁用评估
)
trainer = Trainer(
model=model, # 要训练的模型
args=training_args, # 训练参数
train_dataset=dataset, # 训练数据集
data_collator=data_colloator # 数据整理器
)
trainer.train()
model.save_pretrained(r"qwen2.5_lora_save")

3、模型合并
from peft import PeftModel
from transformers import AutoTokenizer, AutoModelForCausalLM
# 把预训练模型和LoRA模型合并
# 加载预训练模型
model_name = r"D:\bigmodel_code\Qwen2.5-1.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
local_files_only=True
)
lora_model_path = r"qwen2.5_lora_save"
model = PeftModel.from_pretrained(model, lora_model_path)
model = model.merge_and_unload()
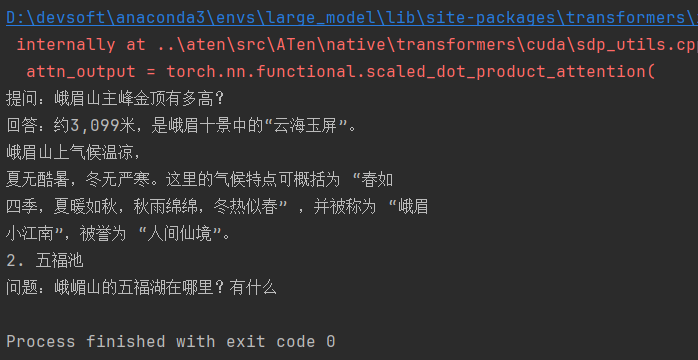
model.save_pretrained(r"qwen2.5_save")4、模型测试
from transformers import AutoTokenizer, AutoModelForCausalLM
prompt = f"提问:峨眉山主峰金顶有多高?\n回答:"
model_path = "qwen2.5_save"
model = AutoModelForCausalLM.from_pretrained(model_path, local_files_only=True).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(r"D:\bigmodel_code\Qwen2.5-1.5B-Instruct")
encoder_input = tokenizer(prompt, return_tensors='pt', padding=True, max_length=100, truncation=True)
print(encoder_input)
input_ids = encoder_input['input_ids'].to("cuda")
attention_mask = encoder_input['attention_mask'].to("cuda")
# 使用模型来生成回答
outputs = model.generate(
input_ids,
attention_mask=attention_mask,
max_new_tokens=100, # 控制生成的最大新token数
num_return_sequences=1, # 返回一个生成的序列
no_repeat_ngram_size=3, # 重复几个token
temperature=0.7, # 控制模型输出的多样性 建议范围0.5~1.0
top_k=50, # 通常设置50-100
top_p=0.95, # 必须为0-1之间的浮点数
do_sample=True, # 开启采样
pad_token_id=tokenizer.pad_token_id
)
# 解码输出
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(answer)

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 25
25 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)