
LoRA、QLoRA微调与Lama Factory
1.什么是LoRA2.LoRA的核心思想3.LoRA的原理4.LLaMA-Factory介绍5.安装LLaMa-Factory6.使用LLaMaFactory自带的数据集进行LoRA微调7.LORA指令微调-单轮对话8.模型合并量化导出9.通过OpenWebUl部署模型10.QLoRA指令微调-多轮对话11.对话模板12.GGUF
1.什么是LoRA(Low-Rank Adaptation)
LoRA(Low-Rank Adaptation,低秩自适应)是一种高效的大模型微调技术,通过引入低秩矩阵来减少微调时的参数量,在预训练的模型中LoRA通过添加两个小矩阵A和B来,近似原始大矩阵ΔW,从而减少需要更新的参数数量。
具体来说:LoRA通过将全参微调的增量参数矩阵ΔW表示维两个参数量更小的矩阵A和B的低秩矩阵近似实现:W+ΔW=W+B*A,其中B和A的秩远远小于原始矩阵的秩,从而大大减少了需要更新的参数数量。
LoRA专为减少计算和内存开销而设计,广泛应用于自然语言处理(如GPT、LLaMA等大模型)和其他领域的迁移学习。
2.LoRA的核心思想
预训练模型中存在一个极小的内在维度,这个内在维度是发挥核心作用的地方。在继续训练的过程中,权重的更新依然也有如此特点,即也存在一个内在维度(内在秩)
权重更新:W=W+^W
因此,可以通过矩阵分解的方式,将原本要更新的大的矩阵变为两个小的矩阵
权重更新:W=W+ ^W=W+ BA
具体做法,即在矩阵计算中增加一个旁系分支,旁系分支由两个低秩矩阵A和B组成
3.LoRA的原理
在训练时,输入的内容分别与 原始权重 和两个低秩矩阵进行计算,共同得到最终结果,优化时则仅优化两个低秩矩阵,训练完成后,可以将两个低秩矩阵与原始模型中的权重进行合并,合并后的模型与原始模型无差异。
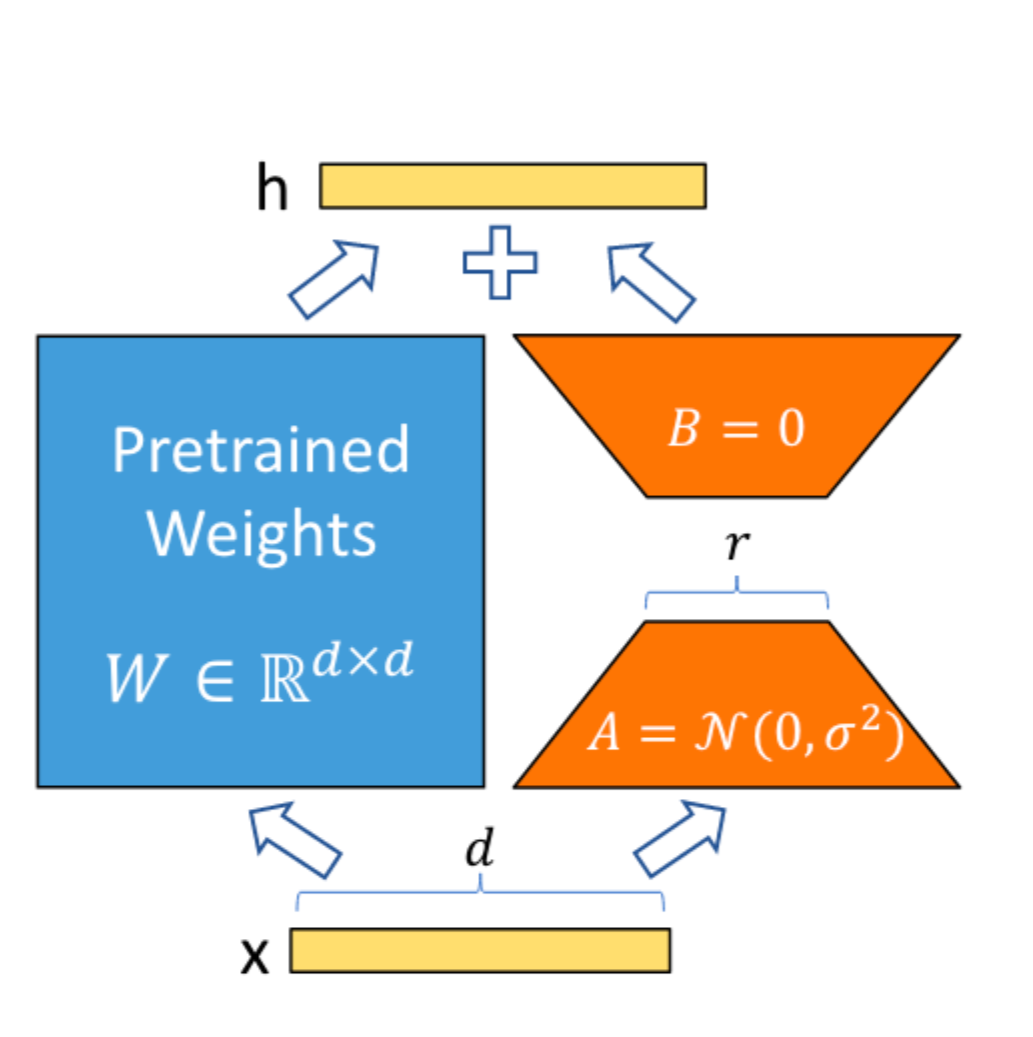
上图中:
W 表示预训练模型的权重矩阵,R表示实数集,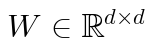 的意思是:表示预训练的权重矩阵 W 是一个 d 行 d列的实数矩阵(R是实数集)
的意思是:表示预训练的权重矩阵 W 是一个 d 行 d列的实数矩阵(R是实数集)
A 表示W分解后的低秩矩阵m*r,他初始化权重为从正态分布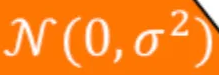 从均值为0、标准差为 σ 的正态分布采样,其中
从均值为0、标准差为 σ 的正态分布采样,其中 是标准差,分布宽度由 σ 控制,用于控制初始化的分散程度
是标准差,分布宽度由 σ 控制,用于控制初始化的分散程度
B 表示W分解后的低秩矩阵r*n,他的权重参数则会初始化为零矩阵,这样就可以做到在训练初期低秩矩阵 BA 的乘积也将是零。这意味着在训练初期,模型的权重更新量ΔW = BA 为零,即模型的输出完全依赖于预训练权重W。
x 表示输入特征向量,维度为 d
r 表示将输入特征向量 x 从维度 d 降维到一个较低的维度 r ,r<<d(r远远小于d),就是**低秩矩阵的秩(代表两个小矩阵A和B的中间维度),秩越大代表矩阵信息的含量就越大**
h 表示输出特征向量,维度为 d
为了好理解上图的完整过程用以下示例解释:
假设预训练模型原始权重矩阵为W:
W的形状为m**×n,一个m行n列的矩阵 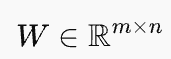 ,输出是m维,输入是n维,参数冻结不更新**
,输出是m维,输入是n维,参数冻结不更新**
按照W矩阵维度构造的低秩矩阵A和B:
B矩阵的形状为m**×r (m行r列),A矩阵的形状为r×**n (r行n列)
矩阵乘法规则:第一个矩阵的列数必须等于第二个矩阵的行数,结果矩阵的维度是第一个矩阵的行数乘以第二个矩阵的列数,即:****矩阵B的列数 等于 矩阵A的行数:矩阵B的列数=矩阵A的行数=r
我们想要得到h,原始模型输出为:h = Wx,引入低秩调整后:h = Wx + B****Ax,
合并权重后:h = (W + BA)x
lora原理如下:
先将A矩阵和B矩阵视为两个单独的矩阵:
1.降维:****将输入x的维度由n维降到r维
将输入的x(文本或者其他)特征向量维度为n维,原始权重 W 参数保持冻结,输入向量 x 同时传入原始模型路径(计算 Wx)和 LoRA 路径(计算 BAx),二者并行计算。
矩阵 A (r×****n ****):
• 矩阵 A 接收输入特征向量 x ,其维度为 n 。
A 的作用是将输入特征向量 x 映射到一个低维空间,这个低维空间的维度为 r (即 A 矩阵的行数)。
用矩阵乘法: A 是一个 r×n 的矩阵,其中 n 是输入特征的维度, r 是目标维度。当我们将 A 与 n维的输入向量 x 相乘时,结果是一个 r 维的向量。
• 通过这种方式, A矩阵可以捕获输入特征向量 x 在低维空间中的表示,A矩阵输出为x特征向量一个r维的向量。
2.映射回原始维度:A输出的**r维升回输出维度m**
矩阵 B (m×r):
• 矩阵 B 的作用是将矩阵 A 输出的低维表示映射回原始的高维空间(即维度为 m 的空间)与原始 W 的输出维度一致,即将A输出的r维向量作为输入传入B矩阵。
• B 的形状为 m×r ,m 是原始特征空间的维度。
• 通过将 A 的输出r维向量与 B 相乘,我们将r维向量升维到了m维空间,得到一个m维的向量
(B的秩可能小于 r,同理 A 的秩也可能小于 r,矩阵乘积的秩上限由A或B的秩中更低的一个决定,而非预设的 r。例如,若A的秩为 5(即使其形状是 r×n,n=8),则BA的秩不超过 5)
再将A矩阵与B矩阵视为一个整体的矩阵:
3.权重合并(权重更新)
A矩阵:r×n B矩阵m×r
将 BA 矩阵的乘积得到矩阵ΔW=B**A=m×**n形状的矩阵,这个矩阵与原始预训练权重W的形状相同
我们就可以将ΔW与原始预训练的权重矩阵 W 相加得到合并后的新矩阵W’:W’ = W + ΔW=W+(B****A)。
合并后的权重矩阵 W’ = W +(B****A)将用于计算模型的输出。
这个新的权重矩阵 W’ 结合了原始预训练W模型的知识和通过低秩矩阵AB学习到新的参数,完成了模型微调的过程
使用合并后的模型输出:
合并后的权重矩阵 W’ 计算模型的输出。这个过程可以表示为 h =W’x=(W+B****A)x,h 是模型的输出, x 是输入特征向量, W’ 是合并后的权重矩阵
通过以上方法:大大降低了参数的训练数量。
示例:
假设预训练权重 W 形状为 768×1024。
** • 选择秩 r=8,**
**B 形状: 768×8 **
**A 形状: 8×1024 **
ΔW(B×A)形状:768×1024(与原矩阵W相同)
** • LoRA参数数量: ****768****×8 + ****1024**×8 = 14336 远小于原始参数 768×1024 = 786432, LoRA参数总量约占原始参数 的1.83%左右
目前LoRA微调较流行的框架有两个,一个是基于可视化界面的LLaMA-Factory,另外一个是书生浦语公司的Xtuner
4.LLaMA-Factory介绍
1.什么是LLaMA-Factory
LLaMa-Factory是当前热门的大模型微调框架之一,由国内公司开发,支持多种市面上流行的模型,如DeepSeek、千问、LAMA、GMA等。
该框架集成了丰富的微调方法,包括增量预训练、多模态指令监督微调、奖励机制训练、PPO训练、DPO训练等,并支持不同精度的微调方式,如16比特全参数微调、冻结微调、LoRA微调和QLoRA量化微调。
此外,Lama Factory还支持多模态的微调训练,包括多轮对话、工具调用、图像理解、视频识别、视觉定位和语音理解等。
实验监控方面:支持**LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等**。
框架还支持极速推理,集成 vLLM和Hugging Face推理环境。Lama Factory更新频繁,能迅速支持新发布的模型,对于模型的支持力度很高只要有新模型出来就会更新。
2.安装LLaMa-Factory的软硬件要求
1.软硬件依赖
必需项
| 依赖项 | 至少版本 | 推荐版本 |
|---|---|---|
| python | 3.9 | 3.10 |
| torch | 1.13.1 | 2.5.1 |
| transformers | 4.41.2 | 4.49.0 |
| datasets | 2.16.0 | 3.2.0 |
| accelerate | 0.34.0 | 1.2.1 |
| peft | 0.11.1 | 0.12.0 |
| trl | 0.8.6 | 0.9.6 |
可选项
| 依赖项 | 至少版本 | 推荐版本 |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| deepspeed(分布式多卡) | 0.10.0 | 0.16.4 |
| bitsandbytes | 0.39.0 | 0.43.1 |
| vllm(推理框架) | 0.4.3 | 0.7.3 |
| flash-attn(加速框架) | 2.3.0 | 2.7.2 |
2.硬件依赖
- 估算值,GPU显存要求
| 方法 | 精度 | 7B | 14B | 30B | 70B | x B |
|---|---|---|---|---|---|---|
| Full ( bf16 or fp16 ) 全量微调 | 32 | 120GB | 240GB | 600GB | 1200GB | 18x GB |
| Full ( pure_bf16 )全量微调 | 16 | 60GB | 120GB | 300GB | 600GB | 8x GB |
| Freeze/LoRA/Galore/APOLLO/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 2x GB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | x GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | x/2 GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | x/4 GB |
用QLoRA一般最低量化到4位,量化到2位模型就乱码了
5.安装LLaMa-Factory
1.创建独立的LLaMaFactory的Conda环境
conda create -n llamaFactory python==3.10
2.下载LLaMaFactory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
服务器上应该得挂vpn才能下载,或者直接从GitHub上下完传上去
官方给出的是:pip install -e “.[torch,metrics]”
“.[torch,metrics]”:
.:表示当前目录(含 setup.py 的根目录)。
[torch,metrics]:指定安装项目中定义的额外依赖组(称为 extras),setup.py里面配置的
我们装基础环境就行 :pip install -e .
3.启动LLaMaFactory可视化界面
用VSCode 连接服务器打开 执行命令 :llamafactory-cli webui 因为VSCode有端口转发可以打开页面
启动服务时,要在llamafactory的根目录启动,如果在其他地方启动后面会找不到根目录下的数据集的,而且llamafactory在训练的时候,它还要做一些操作,比如说要保存一些数据参数之类的,训练的权重数据等,它的很多参数的路径也是相对路径,在根目录启动可以避免存在其他的异常错误。
把里面的语言换成中文
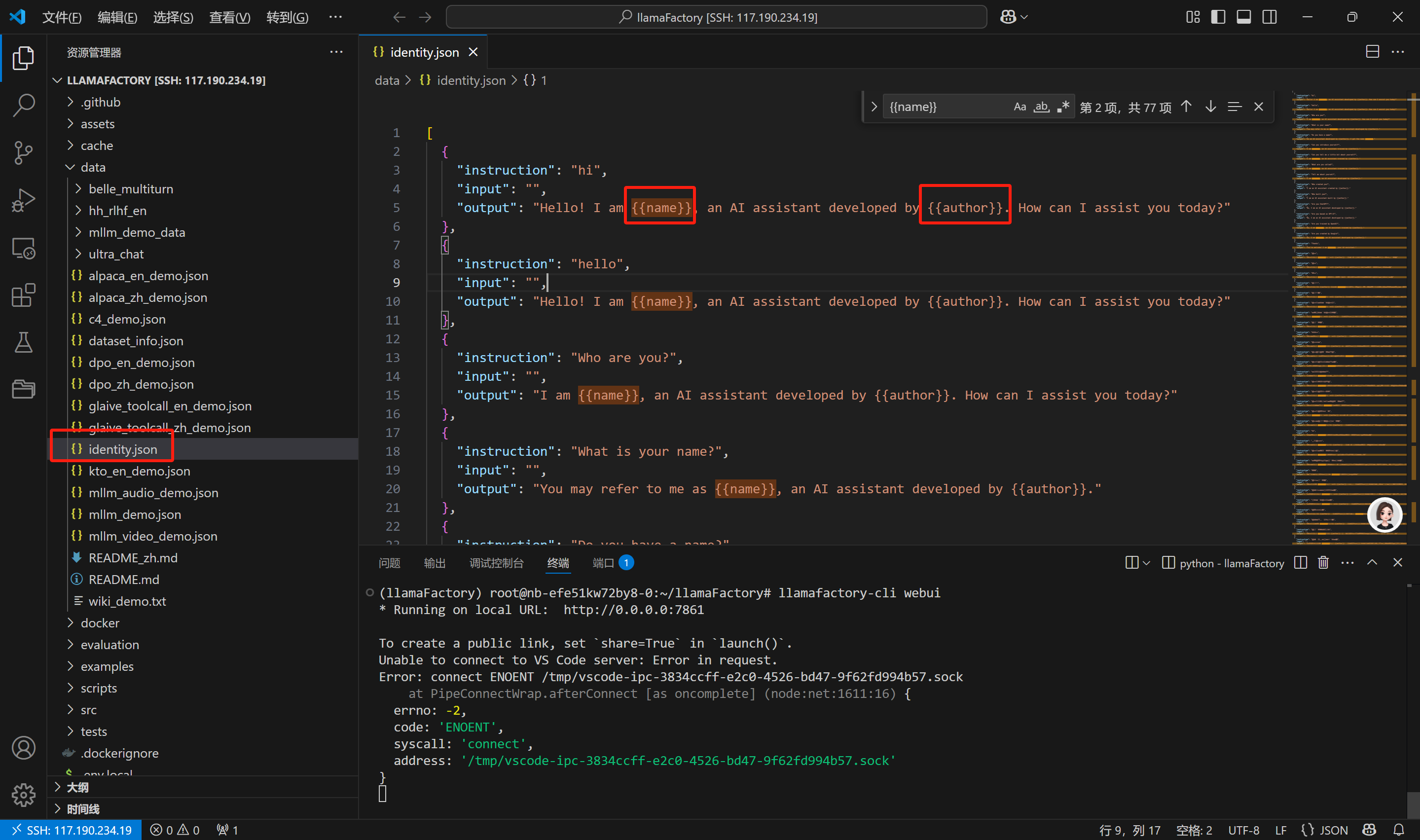
6.使用LLaMaFactory自带的数据集进行LoRA指令微调训练
1.处理数据集
找到data文件夹中的identity.json(自我认知训练数据集),把里面的{{name}}和{{author}},分别换成 张三云百问,张三
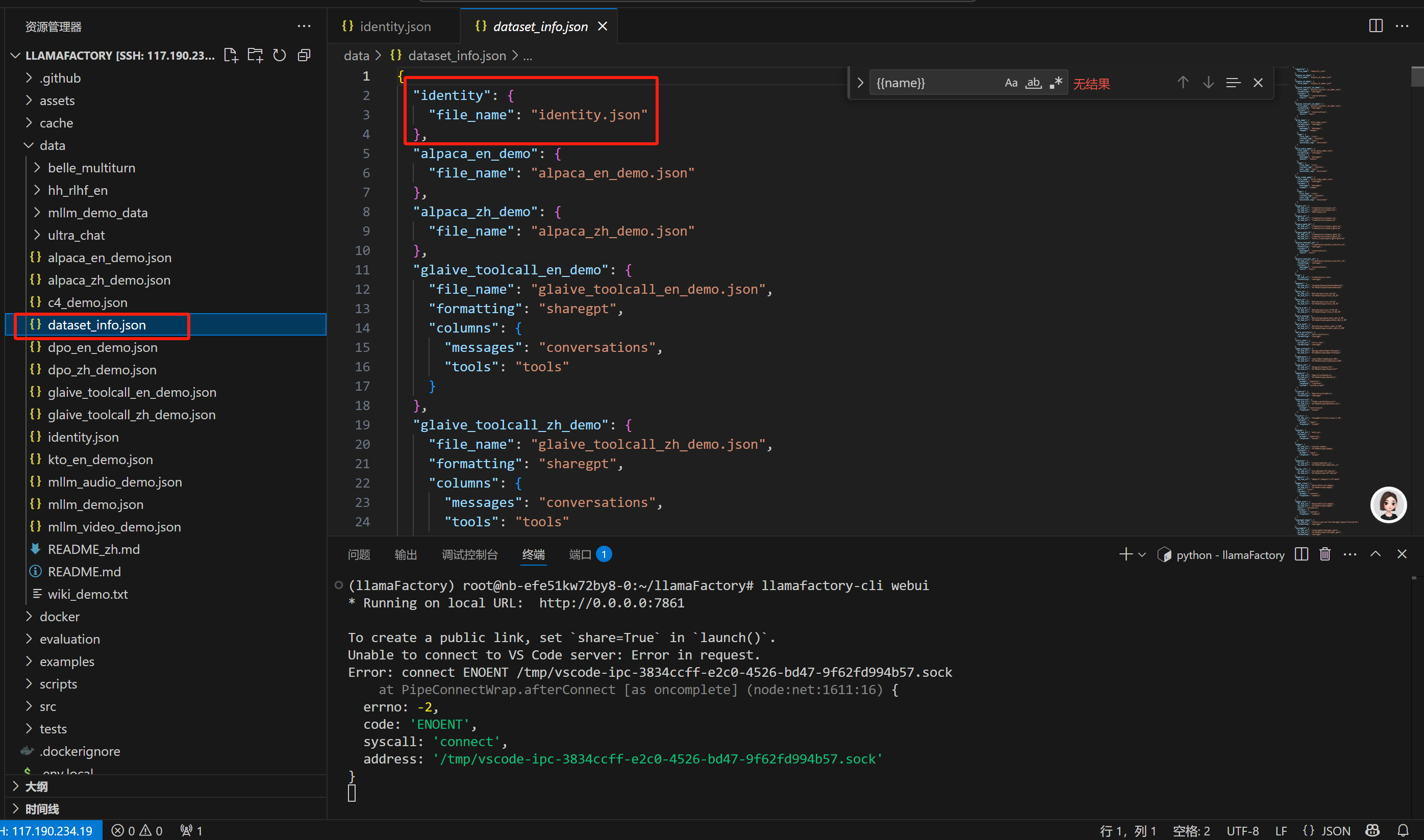
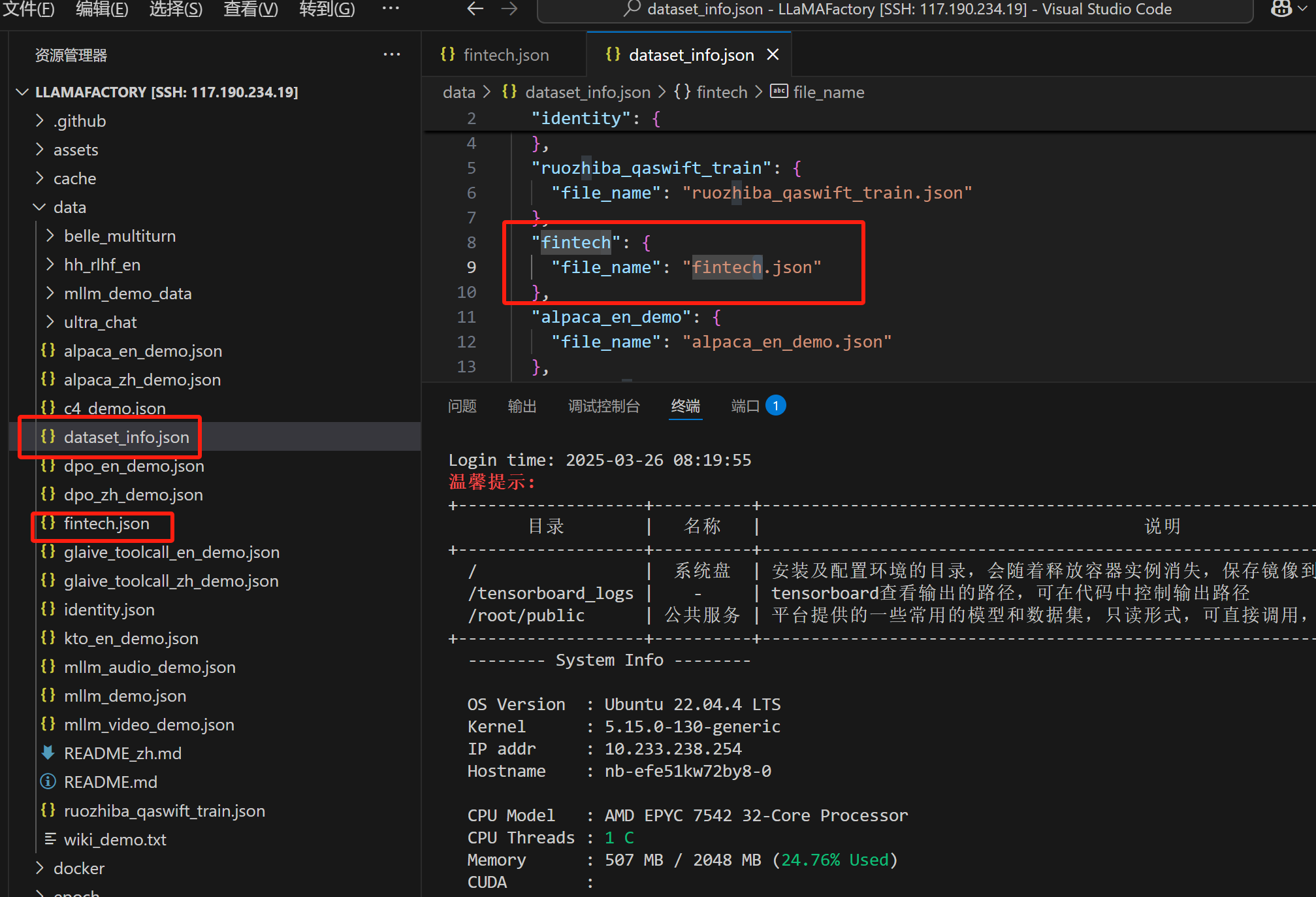
2.配置数据集
在dataset_info.json中配置数据集的位置,这里的file_name是相对路径,如果配置自己的文件要写自己数据集的路径
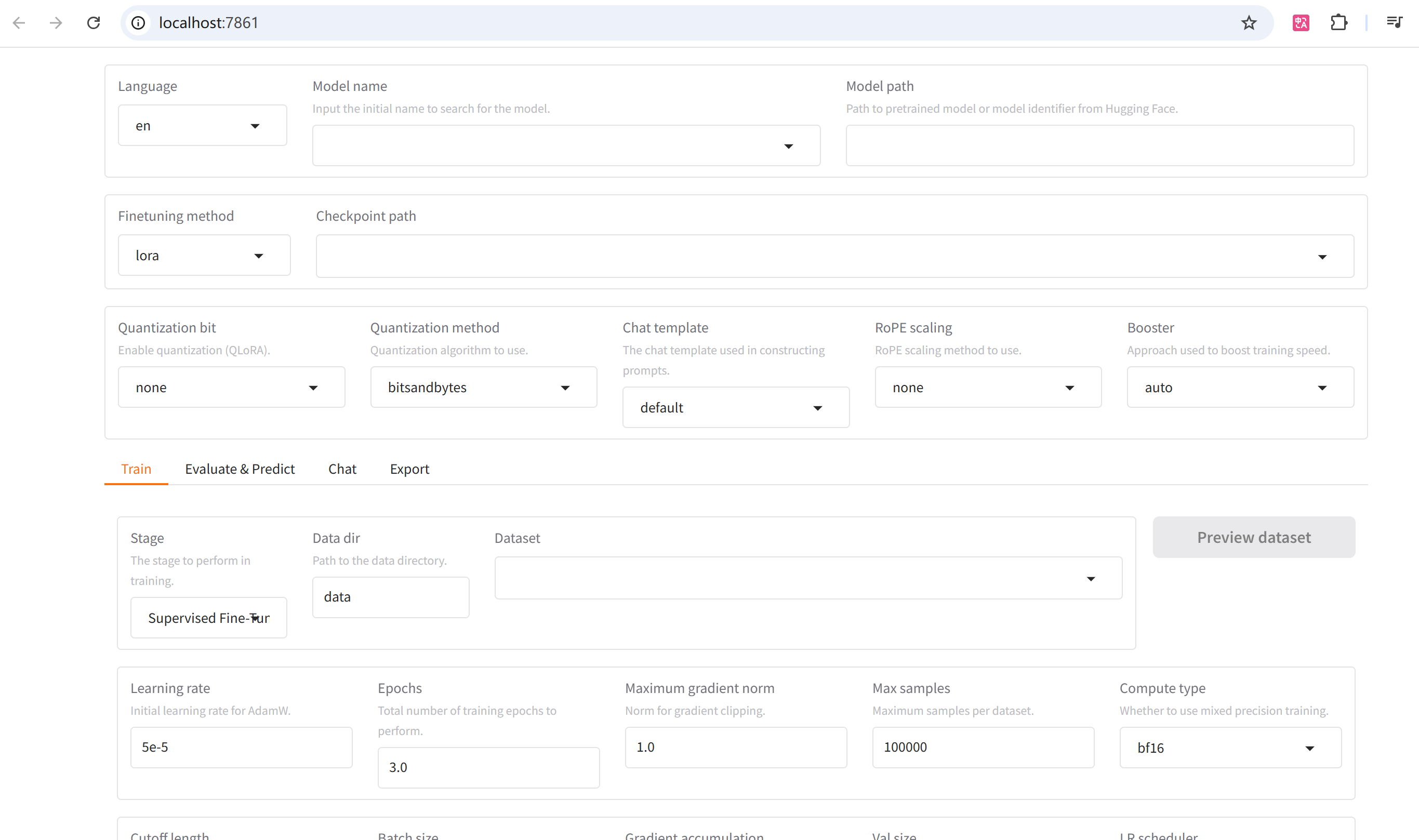
3.LLaMAFactory可视化界面基础配置解析
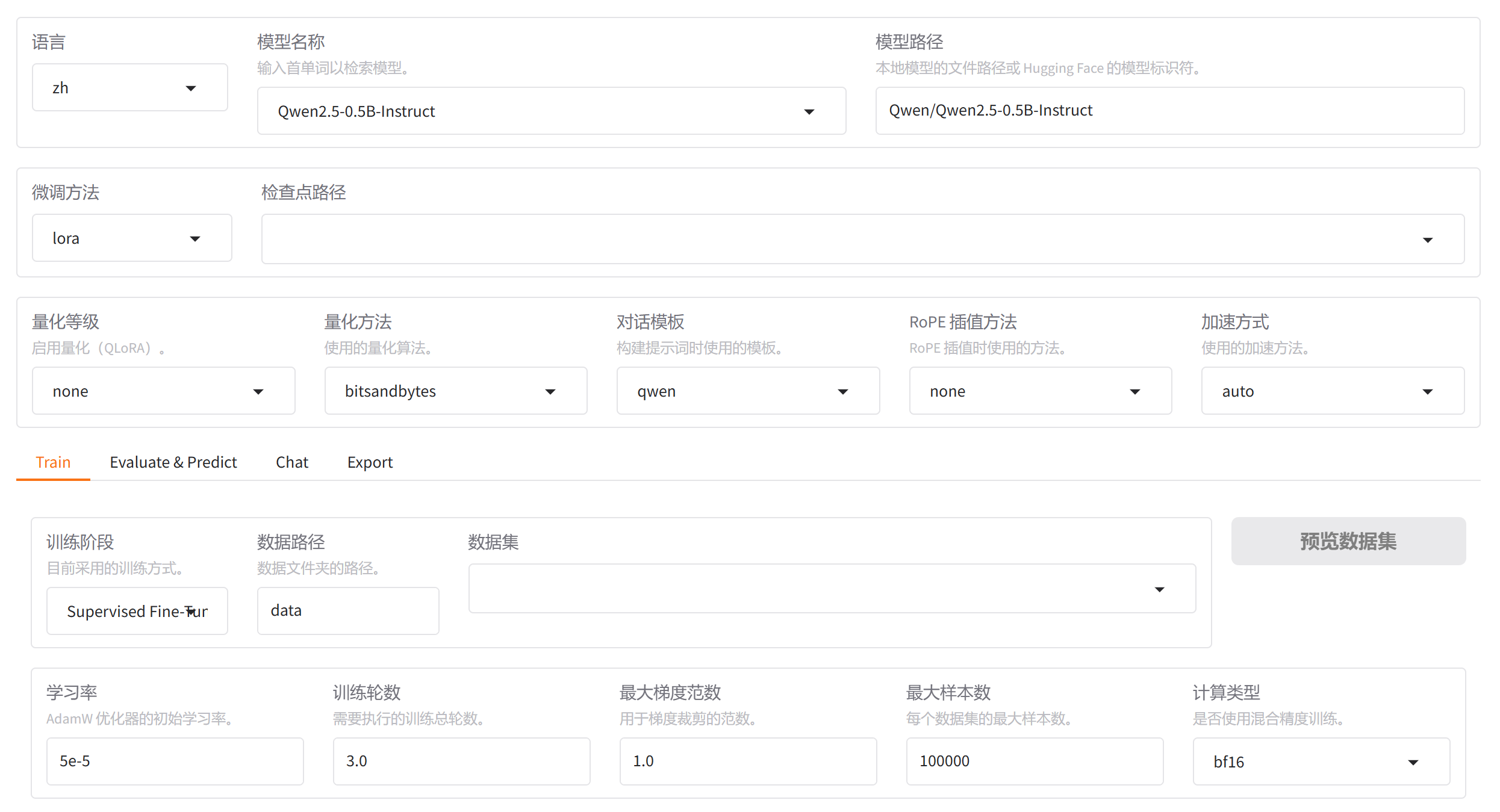
1.语言
这里选择zh 中文就行
2.模型名称
下拉框里面找到自己的模型名称就行,LLaMA Factory对于模型的支持力度很高,基本都有。
为什么去选择一个模型名称呢?
因为不同的模型他们用的对话模板是不一样的,系统会自动的根据我们这选择的模型去适配一个对话模板。
3.模型路径
这个路径里面支持的是本地模型的文件路径,或者Hugging Face的模型标志符。默认填在上面的是一个相对路径,跑起来就会从HuggingFace上下载模型,**我们得把这个路径改成本地服务器的绝对路径,**我们改成:/root/LLM/Qwen/Qwen2.5-0.5B-Instruct

4.微调方法
full 全参数微调:可以最大的模型适应性,可以全面调整模型以适应新任务。通常能达到最佳性能。
Freeze冻结部分参数微调: 训练速度比全参数微调快,会降低计算资源需求。
LoRA(Low-Rank Adaptation)低秩适应微调:显著减少了可训练参数数量,降低内存需求,训练速度快,计算效率高。还可以为不同任务保存多个小型适配器,减少了过拟合风险。
QLoRA (Quantized Low-Rank Adaptation)量化低秩适应微调:训练速度跟 LoRA 差不多,基本保持了 LoRa 的优势,会进一步减少内存使用。
一般选择LoRA和QLoRA,这里我们选择LoRA
5.检查点路径

这个路径指的是,训练时候保存权重的路径。
为什么在这加个检查点路径?
比如说我们的模型正在训练,整体训练的EPOCH 是1000个,如果说我们的模型训练到500个EPOCH 以后的时候,它服务器断电了 GG了,关机了。那我们接下来肯定不希望从头来训练了。我们肯定是要基于这第500个训练结果继续往后训练,我们就可以在这儿就可以把弟500个EPOCH的训练权重给他加进来,这就是检查一下路径的意思,可以继续做训练。如果我们开始没有进行训练的话,这个检查点路径就是空的。

直接把路径粘贴进去不然点开他,他就一直在转在加载
6.量化等级
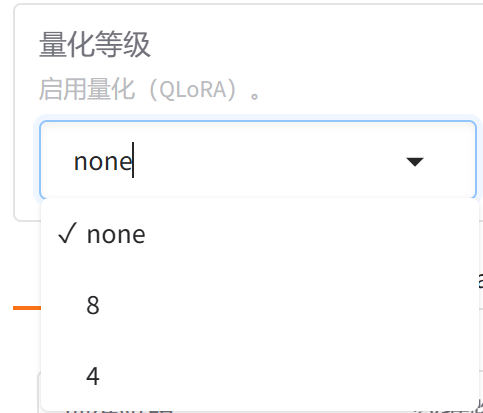
量化等级有none 不量化,8位量化( <font style="color:rgb(255, 80, 44);background-color:rgb(255, 245, 245);">INT8</font>)和4位量化( <font style="color:rgb(255, 80, 44);background-color:rgb(255, 245, 245);">INT4</font> ),<font style="color:rgb(255, 80, 44);background-color:rgb(255, 245, 245);">QLoRA</font> 它允许在使用低位量化(如4位)的同时,通过 <font style="color:rgb(255, 80, 44);background-color:rgb(255, 245, 245);">LoRA</font> 方法进行高效的微调
他是为了模型加速训练用的
这里我们先选不量化
7.量化方法
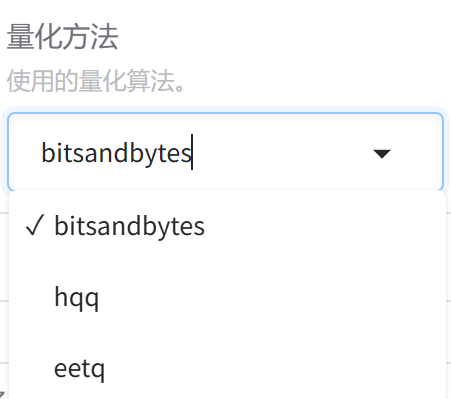
1.bitsandbytes
**通过混合精度量化(如将部分参数保留为FP16,其余量化到8位或4位),在减少内存占用的同时保持模型精度,**内存效率高,可以显著减少 GPU 内存使用
**优势: **
• **训练友好:**支持“量化感知训练”(如QLoRA方法),允许在微调时动态量化梯度及优化器状态,大幅降低显存需求(在消费级GPU上即可训练大模型)。
• **灵活部署:**支持8位和4位推理,量化后的模型可直接用于推理,无需额外转换。
• **精度保留:**混合精度策略减少了量化误差,适合对精度敏感的任务(如对话生成)。
**适用于:**需要微调模型或资源有限(如单卡GPU)的场景,同时兼顾训练与推理
2.Hqq
无需依赖校准数据(即零样本量化),专注于硬件兼容性,通过分块量化(Block-wise Quantization)和优化存储格式,提升推理速度。
优势:
- 免校准量化:直接对模型权重量化,节省数据准备时间。
- 低资源部署:量化后模型体积小,适合边缘设备(如手机、嵌入式设备)。
- 硬件适配:通过分块策略优化内存访问模式,提高计算单元利用率(如GPU/CUDA核心)。
适用于:快速部署轻量级模型到资源受限的硬件环境,尤其是在无校准数据的边缘侧推理。
3.EETQ(极速推理的引擎级优化)
深度集成硬件加速特性(如NVIDIA的Tensor Core),通过低精度计算(INT8)和计算图优化(操作融合、Kernel优化),最大化推理吞吐量。
优势:
• 极致性能:专为高吞吐、低延迟设计,可处理大规模并发请求。
• 硬件协同:充分利用张量核心的并行计算能力,优化内存带宽瓶颈。
• 动态量化策略:根据输入动态调整量化参数,平衡精度与速度。
适用于:云端服务或高性能服务器,需要处理高并发推理请求(如批量生成任务)。
7.对话模板
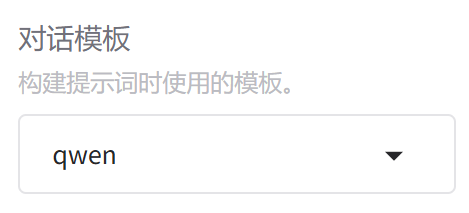
我们选的是Qwen2.5-0.5B-Instruct,因为不同模板的话模板是不一样的,选择模型名称时已经回填好了。
我们在微调训练的时候,一定是要基于人家当前模型的对话模板来进行训练。
8.RoPE插值方法
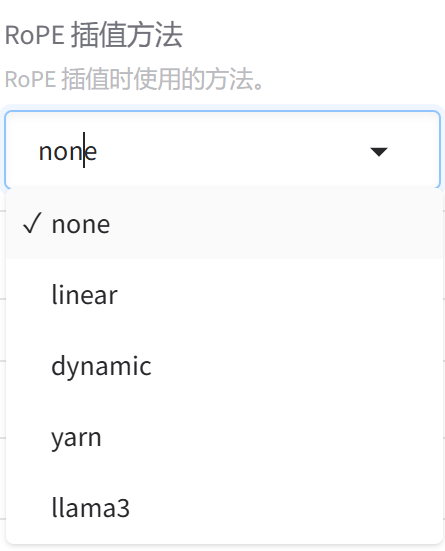
none
liner
dynamic
yarn
llama3
9.加速方式
4.LLaMAFactory训练任务配置解析
1.训练阶段

1.监督微调 Supervised fine Tuning:
好处:快速适配特定任务(如客服、摘要、翻译)。
实现:用人工标注的输入-输出对(如问答数据)直接调教模型行为。
2.奖励建模(RM) Reward Modeling:
好处:让模型学会「人类偏好标准」,判断回答的好坏。
实现:用人工标注的「好回答 vs 差回答」对比数据,训练一个评分AI。
3.近端策略优化(PPO)Proximal Policy Optimization:
好处:提升回答质量,使输出更符合人类喜好。
实现:让模型生成多个回答 → 2. 用RM为回答打分 → 3. 通过得分高低动态调整模型生成策略。
4.直接偏好优化(DPO)Direct Preference Optimization:
好处:省去RM训练步骤,直接优化模型偏好。
实现:用「直接告诉模型哪个回答更好」的对比数据,一步到位调整模型输出倾向。
5. (KTO)Kahneman-Tversky Optimization:
好处:降低标注成本,无需严格对比数据。
实现:只标注单一样本的好坏标签,通过「鼓励好回答、抑制坏回答」优化模型。
6.预训练(Pre-Training)
好处:建立底层语言理解能力(语法、知识、推理)。
实现:用海量无标注文本,通过「预测下一个词」让模型自我学习。
真正的微调训练其实是SFT,指令微调(监督微调),其他几种方式是与预训练相关的,这里我们选择STF
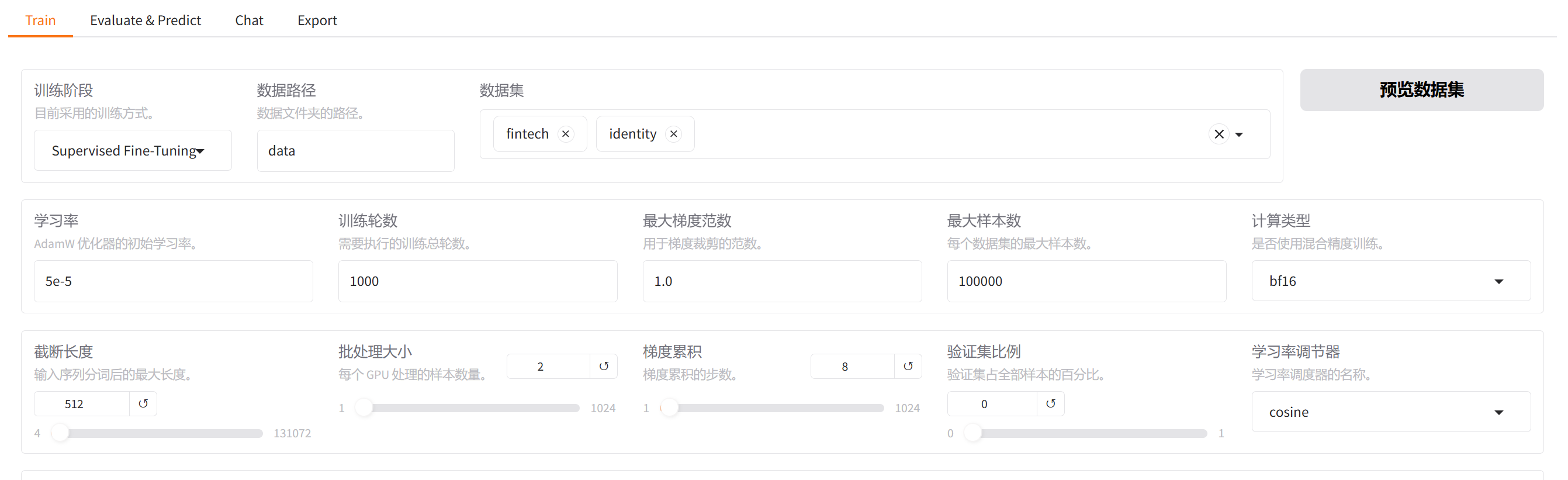
2.数据路径
这里的data是LLaMAFactory的根目录
3.数据集
这里就可以加载data目录下的数据集,选择后还可以预览之前修改的数据集。
3.学习率
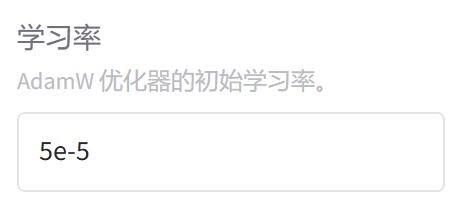
AdamW的学习率通常在1e-5 到 3e-5之间,于大型语言模型(如 BERT、GPT 等)的微调,常用的学习率范围是 2e-5 到5e-5,从一个相对较小的值开始,如 2e-5 。
如果训练不稳定或损失波动很大,可以尝试降低学习率,如果训练进展太慢,可以尝试略微增加学习率。
因为Lora 更新的参数空间更小,梯度噪声更高,需要更大学习率以快速收敛
这里我们用默认的5e-5就行
4.训练轮次
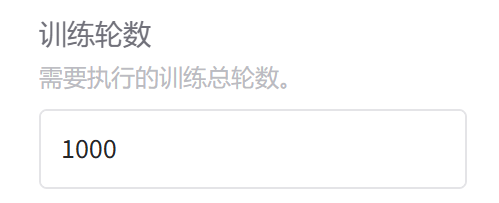
我们选择训练轮数(epochs)需综合任务难度、数据规模、模型容量和收敛速度来进行动态调整,这里我选择1000轮,是因为ai模型训练的理论目标是到拟合状态。具体多少轮次能到拟合状态是不知道的,因此epoch一般会给大一些。以下的轮次指的是指有效果,那么一般大多数数据集训练一轮就有了效果了,最好的方式就是自己拿训练的不同批次的权重去验证,看看它们之间的表现差异。
现在的权重都可以按批次保存,所以不考虑显存资源的情况下,选择轮数更大的,轮数多了跳到指定的权重就行。
一般有效果的通用轮数可以按照下面来选择:
| 训练阶段 | 推荐轮数 | 核心逻辑 |
|---|---|---|
| 预训练 | 1-3轮(大规模数据) | 千亿级 Token 数据充分覆盖语言模式,过多轮数易引发灾难性遗忘(Catastrophic Forgetting) |
| 监督微调 (SFT) | 3-10轮 | 中等数据量(万级样本)下适配任务分布,依赖早停法(验证 Loss 稳定下降时终止) |
| RLHF (PPO/DPO) | 1-5轮 | 策略优化易陷入局部最优或过拟合,小步幅迭代(epoch=1时需增加 batch 内迭代步数) |
1.轮次的核心影响因素
1. 数据规模
| 数据规模 | 推荐轮数 | 说明 |
|---|---|---|
| 小数据(<1k样本) | 1-3轮 | 避免过拟合,依赖数据增强或正则化 |
| 中等数据(1k-10k) | 3-10轮 | 平衡任务适配与过拟合风险 |
| 大数据(>10k) | 2-5轮 | 单轮即可充分学习,降低计算成本 |
2. 任务复杂度
| 任务类型 | 推荐轮数 | 说明 |
|---|---|---|
| 简单任务(分类、短文本生成) | 3-5轮 | 低复杂度任务快速收敛 |
| 复杂任务(长文本推理、多轮对话) | 5-15轮 | 需多轮细粒度调优,避免欠拟合 |
3. 模型规模
| 模型规模 | 推荐轮数 | 说明 |
|---|---|---|
| 小模型(7B以下) | 5-8轮 | 参数少,学习效率高 |
| 大模型(13B+以上) | 8-15轮 | 收敛慢,需更多迭代,但硬件成本显著增加 |
2.调整策略
1. 动态早停
- 标准:连续2-3轮验证集 Loss 不下降(相差<0.1%)则终止。
- 工具:使用
Trainer中的EarlyStoppingCallback。 - 示例:在验证集 Loss 连续3轮增幅≤0.05%时终止训练。
2. 学习率衰减
- 策略:
- 高 LR(初始值,如
2e-5):前30%训练轮数快速收敛。 - 低 LR(衰减后,如
2e-6):后70%轮数精细调优。
- 高 LR(初始值,如
- 公式:
LR = LR_initial × (1 - epoch/total_epochs)^0.9。
3. 混合调度
- 示例:
- 总轮数=10:
- 前5轮:使用全量数据。
- 后5轮:对困难样本重复采样(增强细粒度学习)。
- 总轮数=10:
- 适用场景:数据分布不均或长尾任务。
5.最大梯度范数
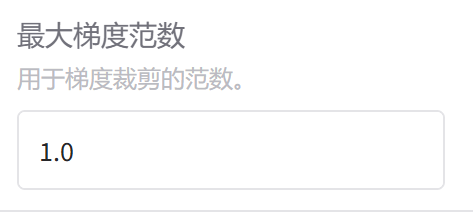
SFT微调一般选择:1.0 即 max_grad_norm=1.0 (Hugging Face默认值)
| 模型规模 | 最大梯度范数 | 学习率范围 | LoRA Rank 建议 | 附加优化策略 |
|---|---|---|---|---|
| 0.5B | 2.0-3.0 | 1e-4 - 3e-4 | 4-8 | 轻量级模型,可激进调整学习率 |
| 1.5B | 1.5-2.5 | 8e-5 - 2e-4 | 8-16 | 适当增加批量大小以提高效率 |
| 3B | 1.0-1.8 | 5e-5 - 1e-4 | 16-32 | 需监控梯度方向稀疏性 |
| 7B | 0.8-1.5 | 3e-5 - 8e-5 | 32-64 | 默认黄金比例(模型稳定性最佳) |
| 14B | 0.5-1.0 | 1e-5 - 3e-5 | 64-128 | 推荐开启混合精度 (bf16/fp16) |
| 32B | 0.3-0.8 | 5e-6 - 1e-5 | 128-256 | 必选梯度检查点 (gradient_checkpointing) |
| 72B | 0.1-0.3 | 1e-6 - 5e-6 | 256-512 | 必须分片优化器 (sharded optimizer) |
表格说明
1.最大梯度范数:
- 防止梯度爆炸的关键参数,模型越大需越严格限制。
- 示例:72B 模型需将梯度范数控制在 0.1-0.3。
2.学习率范围:
- 与模型规模成反比,大模型需更小的学习率。
- 0.5B 模型可用 1e-4 高学习率快速收敛。
3.LoRA Rank 建议:
- 低秩适应 (LoRA) 的关键超参数,平衡效率与效果。
- 7B 模型推荐 32-64,72B 需 256-512 以保留更多参数信息。
4.附加优化策略:
- 大模型(14B+)需依赖混合精度、梯度检查点、分片优化器等技术降低显存消耗。
- 轻量级模型(0.5B-3B)可通过调整学习率和批量大小灵活优化。
6.最大样本数量
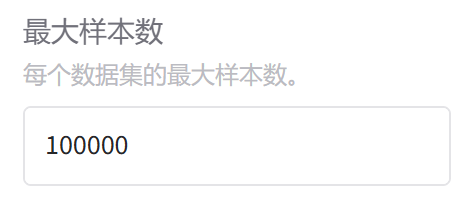
主要是用来控制它数据集的大小的,那么这个东西可以控制也可以不控制,但是如果给他改的太少了,比如说改成了100,那就意味着它当前加载数据的时候最多只加了100条。所以这个参数可以不管,用默认的就行了
7.计算类型
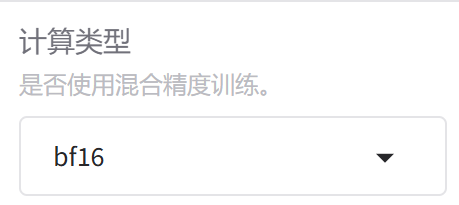
混合精度训练是为了提高训练速度并减少内存占用,同时保持模型的精度和稳定性,我们这里的通义千问精度就算bfloat16这里不用管
8.截断长度
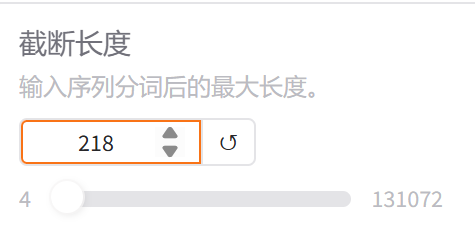
输入序列分词的最大长度 ,这个就是模型的maxlength,他会影响显存的大小,要根据数据的这个长短来给一个适当的值。不然的话给多了它是没有任何意义和价值的。
我们这里做的自我认知训练,他的回答都不长所以给个218就足够了
9.批处理大小
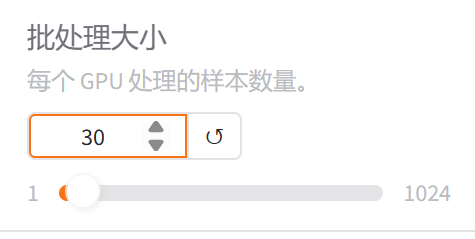
这个得根据服务器的显存能力来调整,一般是要运行以后显存占用率到90左右是最好的,这里先给30试一下
10.梯度累积
在用LoRA 进行指令微调时,梯度累积步数(Gradient Accumulation Steps)的选择我们需要综合 显存限制、训练效率和模型稳定性三方面的因素。
他是指在多个小批次上累计梯度,累计到指定步数后,再统一更新模型参数
1.根据显存定基础
实际批处理大小(batch_size) 尽量占到最大的显存,能多大就尽量多大(比如单卡24G能跑batch=16)。
显存不足时:减小实际batch_size,同时同步增加梯度累积步数,保持「有效批次大小=实际batch_size×梯度累积步数」不变。
2.学习率跟着变
如果增大有效批次(比如调整后翻倍),可以按比例调大学习率(比如原来用2e-5,可试4e-5)。
小批次+多累积步数时更要降低学习率防震荡。
3.任务类型微调
普通任务:按显存选步数(常用4-8步)
数据敏感任务(如医疗问答):步数调大些(8-16步),减少梯度噪声,让更新更稳。
快捷公式:
梯度累积步数 = 你需要的总批次大小 ➗ 单卡实际能跑的batch_size
11.验证集比例
在的这个问答模型上面,实际上验证集可加可不加,它的意义不是很大。
在生成模型上面,它的意义并不是很大,因为生成模型的不用去担心它过拟合,它很难会出现这种过拟合的这种情况,所以一般情况下不需要用这个验证集去验证模型是否过拟合了。
在lama factory上面这个验证集就是测试集。它给验证集的主要目的,就是我们在训练时候可以看到一些验证的评估指标,如果配了这个验证集的话,训练完之后是可以看到人家最后会给你给到一个评估指标的。

这个地方就算验证评估指标的。
验证集数量可以参考下面去选择:
| 数据总量 | 验证集建议 | 原因 |
|---|---|---|
| 小数据 (<1k条) | 15%-20% | 避免训练数据过度流失,同时保证验证可靠性 |
| 中等数据 (1k-10w条) | 5%-10% | 平衡评估准确性与训练充分性 |
| 大数据 (>10w条) | 1%-3% | 万级验证样本已足够稳定评估,进一步增加比例对效果提升有限 |
表格说明
- 小数据场景:
- 验证集占比需较高(15%-20%),因数据总量少,需尽可能保留足够样本评估模型泛化能力。
- 中等数据场景:
- 验证集占比降至5%-10%,兼顾训练数据利用率和评估准确性。
- 大数据场景:
- 验证集占比可低至1%-3%,因万级样本已能稳定反映模型性能,过多验证数据会浪费计算资源。
12.学习率调节器

学习率调度器选择
| 调度器类型 | 适配任务类型 | 推荐参数设置 | 适合场景 |
|---|---|---|---|
| cosine | 通用生成类任务(对话生成/故事续写) | warmup_ratio=0.05(热身占总步数5%) min_lr=初始lr×0.05(最低为初始值5%) |
需平滑衰减的开放域生成 |
| cosine_with_restarts | 多峰探索任务(代码生成/多选题解) | num_cycles=3-5(学习率重启次数) min_lr=初始lr×0.01(最低为初始值1%) |
通过周期重启跳出局部最优 |
| polynomial | 数学推理微调(数学解题/逻辑链生成) | power=2.0(衰减指数) total_steps=总步数×1.2(延长20%步数) |
强衰减抑制后期震荡 |
| constant | 低质量数据调试(噪声>30%的语料) | 关闭warmup阶段 learning_rate=1e-5(固定学习率) |
快速验证baseline性能 |
| constant_with_warmup | 异构数据混合训练(图文对齐/多模态指令) | warmup_steps=总步数×8%(固定热身步数) |
复杂输入结构的稳定初始化 |
| inverse_sqrt | 大规模预训练续训(继续预训练LLaMA) | warmup_steps=2000(固定热身步数) lr=max_lr×sqrt(warmup/steps)(平方根衰减) |
Transformers经典配置 |
| reduce_lr_on_plateau | 灾难性遗忘防御(多任务联合微调) | patience=3(等待3轮无提升) factor=0.5(降为50%) threshold=0.01(容忍误差) |
损失平台期自动降速 |
| cosine_with_min_lr | 小数据集安全微调(<500条样本) | min_lr=1e-6(最低学习率) warmup_ratio=0.1(热身占总步数10%) |
防止极端低lr锁死参数 |
| warmup_stable_decay | 跨语言迁移学习(英文→中文微调) | decay_factor=0.7(每步衰减30%) stable_steps=总步数×10%(稳定期步数) |
确保语言切换平稳过渡 |
关键结论
- 生成任务:优先使用
cosine调度器,设置warmup_ratio=0.05平衡稳定性避免后期震荡。 - 小数据:必须设置最低学习率
min_lr(如cosine_with_min_lr的1e-6)防止参数冻结。 - 多任务:
reduce_lr_on_plateau的patience=3可动态应对不同任务节奏。 - 预训练:
inverse_sqrt调度器与Transformer架构高度匹配。
5.LoRA参数详解
1.LoRA秩(rank)
默认值是8,它上面解释其实说的很清楚,这个参数控制的是训练的这个lora矩阵的大小,这个值越大,这个矩阵会越大一些
2.LoRA缩放系数( alpha)
缩放系数一般设置的是lower秩的二倍,一般设的是这个值的二倍。没有特殊要求情况下,不用去管这个参数。
3.LoRA随机丢弃
我们这里训练的很简单,选个0
LoRA 的权重随机丢弃概率 (<font style="color:rgb(0, 0, 0);">lora_dropout</font>) 控制适配器层在训练时的随机失活强度,直接影响模型的正则化力度和训练稳定性。其选择需要与 任务需求、数据特征 和 模型规模 深度联动
| 关键因子 | 推荐范围 | 底层原理 | 典型场景案例 |
|---|---|---|---|
| 任务复杂度 | 高复杂度任务:0.0-0.2 低复杂度任务:0.1-0.4 | 复杂推理需保留完整参数路径 | 数学证明/代码补全 |
| 数据集规模 | 大数据 (>100k):0.0-0.1 小数据 (<10k):0.3-0.5 | 小数据集更需强正则化防止过拟合 | 垂直领域文本生成 |
| 模型参数量 | >70B 模型:0.0-0.1 7-13B 模型:0.1-0.3 | 大模型自身隐式正则化能力更强 | LLaMA-2 70B 微调 |
| 特征波动性 | 高方差数据:0.2-0.4 低方差数据:0.0-0.15 | 抑制噪声样本主导参数更新 | 用户评论情感分析 |
4.LoRA+ 学习率比例
B矩阵:全零初始化通常给到1.5-3.0,但是我们这个模型很小就不修改了
6.其他配置
1.预览命令

这个就不用管了,其实就是把上面那一堆配置的东西变成命令放到命令行去执行,都有界面了谁还用命令行
2.输出目录
保存结果的目录,它会自动创建好啊,一般是根据我们的这个训练的时间来进行创建的
3.配置路径
这就是我们前面配置的这些参数,它会把这个配置文件保存到这给路径下。
4.设备数量
这显示的是当前训练这台服务器上面有几张卡,目前就只了一租张卡。如果你有两张卡,这就显示的是2。如果你有八张卡,这显示的就是8。
如果你的卡数是大于1的,那么你就可以用这个多卡训练。
7.开始训练
然后下面就有日志了

在启动时要关注 Total optimization steps 不能小于100,如果小于100得修改其他参数里面的保存间隔。

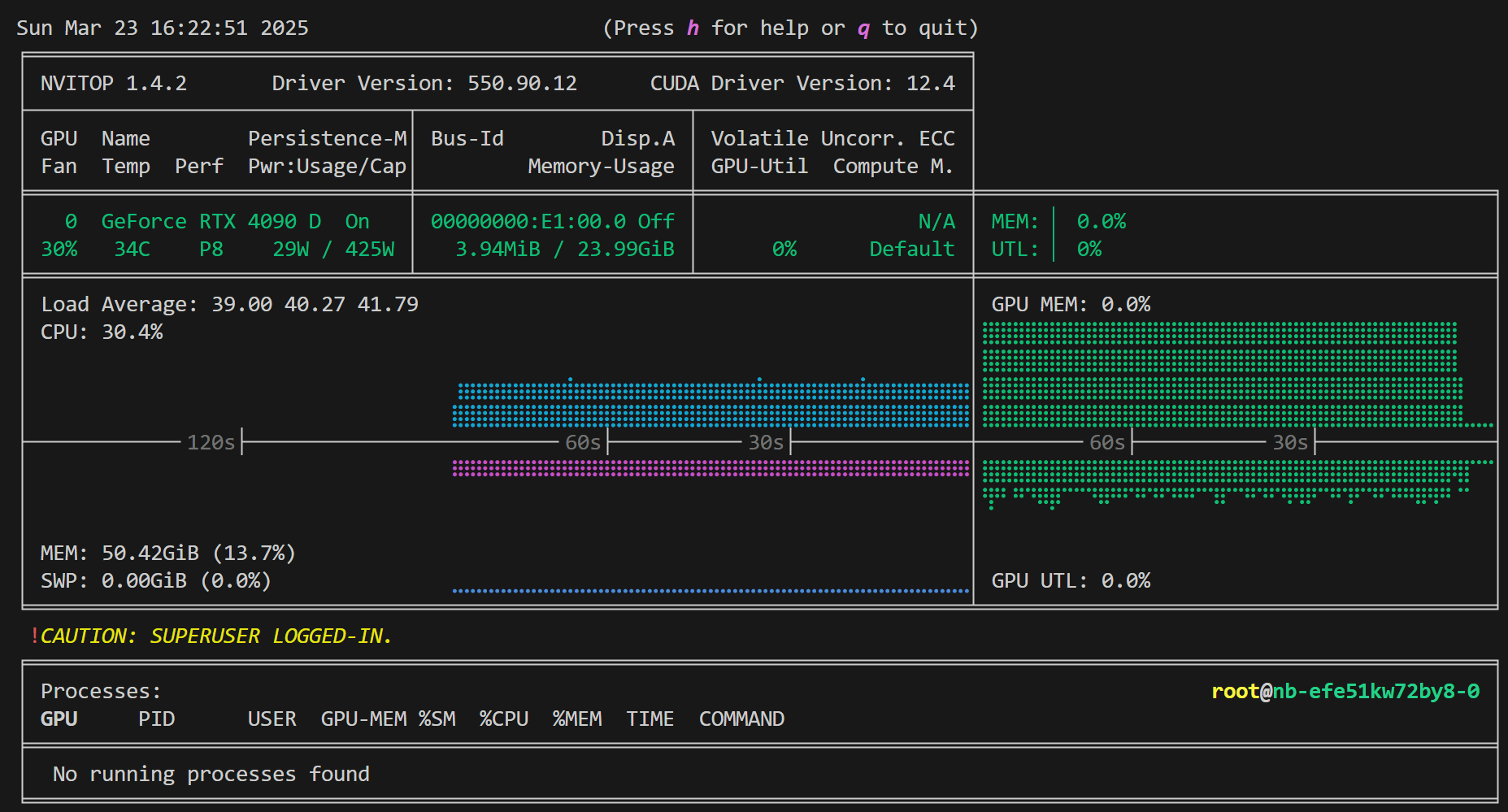
1.查看显存占用情况
先安装pip install nvitop,有的服务器没有这个所以先安装一下
执行 nvitop 查看显存占用情况
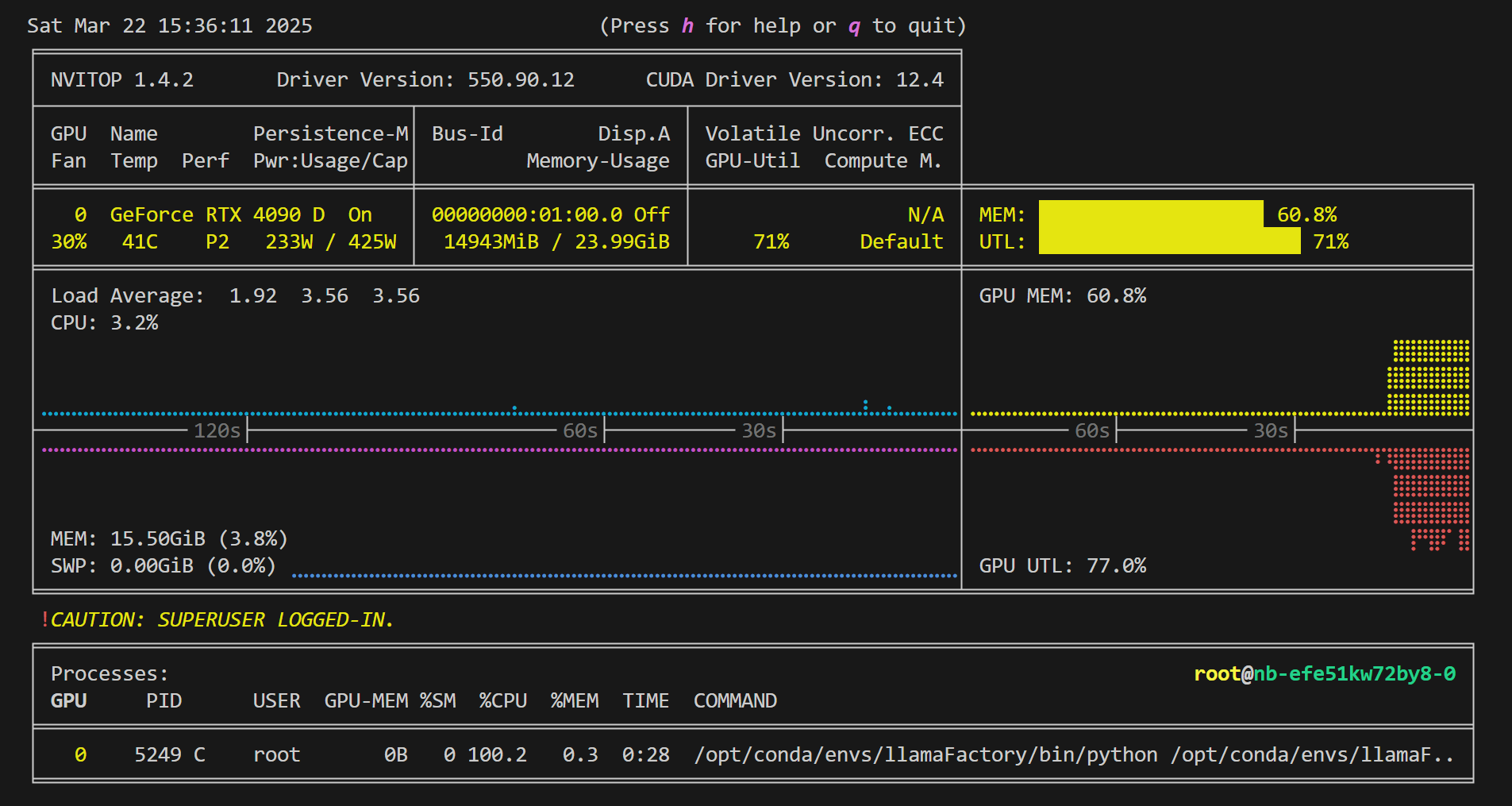
这个地方不知道为啥,批次设置太大了界面上的损失就不输出,批次改小了就有输出
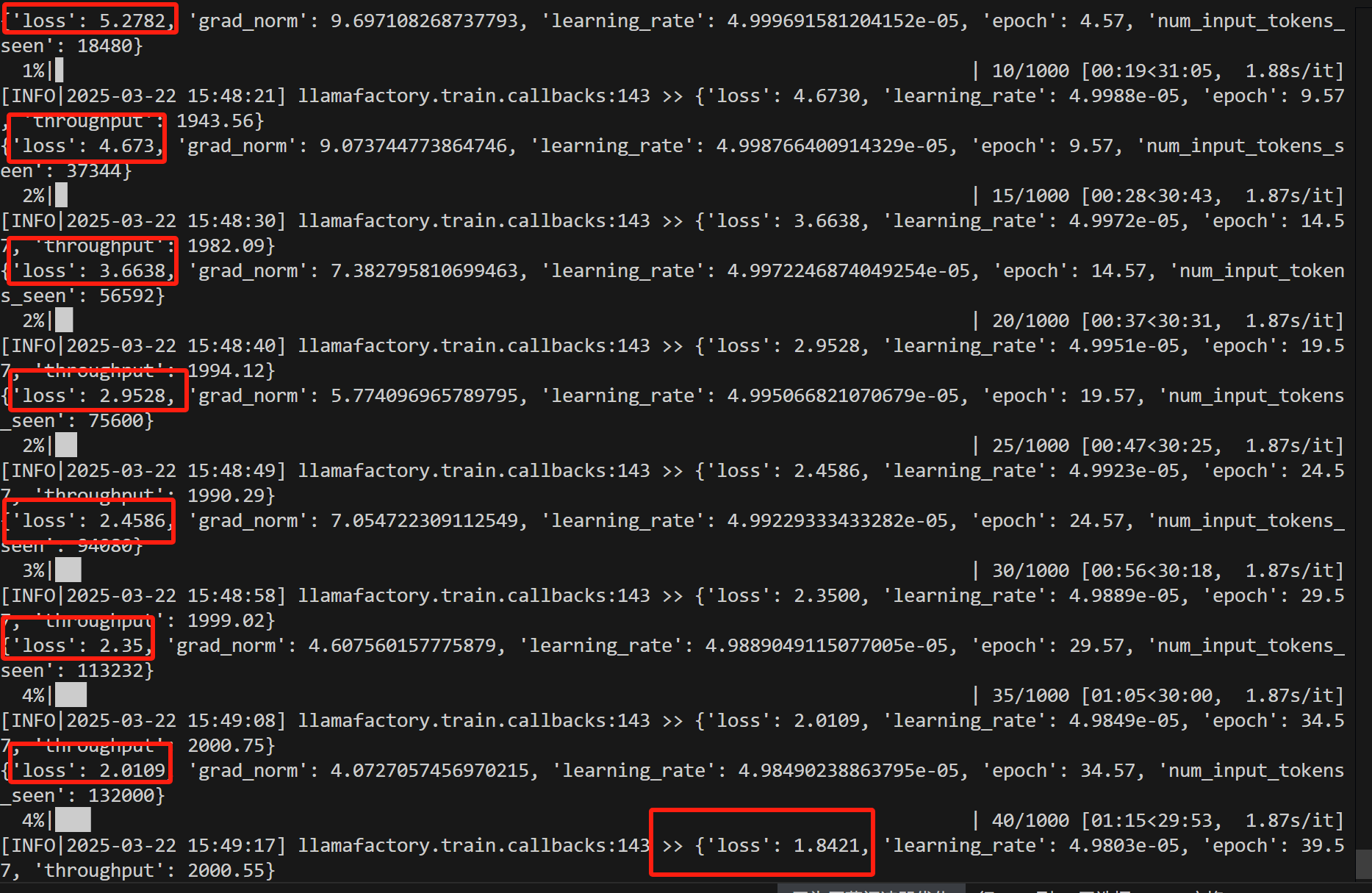
这是训练的损失输出情况:
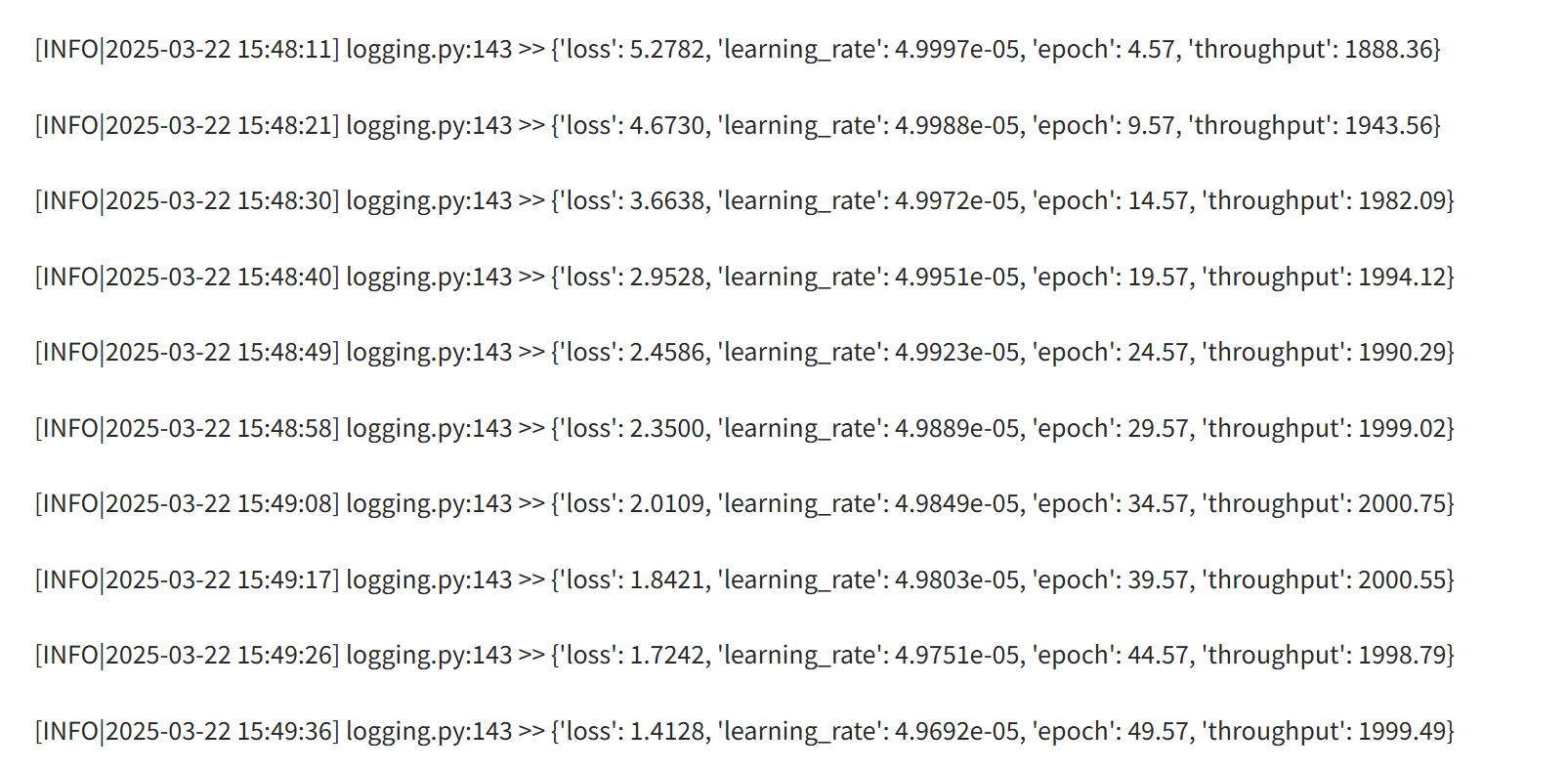
损失趋势图谱:可以看到在150步-200步之间就达到拟合
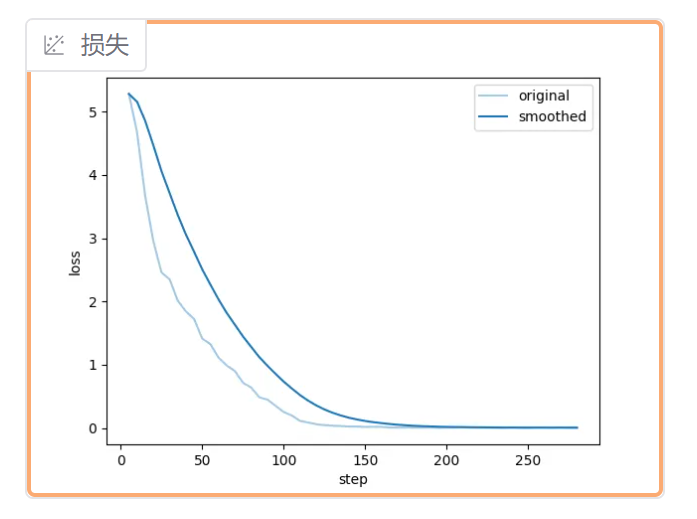
上图中的两条线:original 颜色较浅代表的是原始数据真实的损失折线,smoothed是他自己做了平滑处理后的损失趋势折线
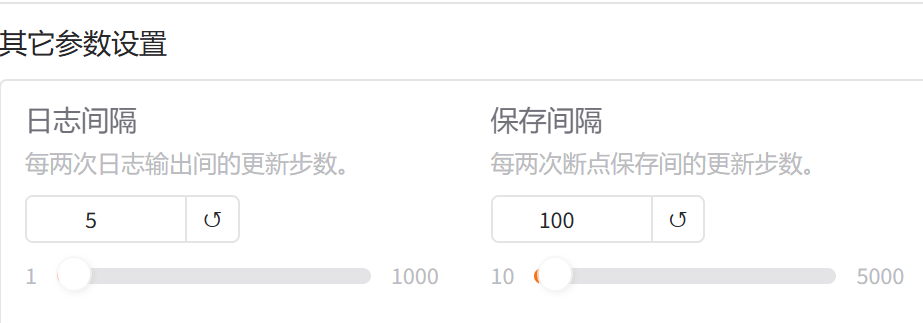
他的权重默认是每100步保存一次,保存的位置在save目录下:check-point-轮次,他的修改来源于其他参数设置
2.停止训练

点击中断可以停止训练,但是需要检查一下显存是否被释放
3.继续训练
如果在训练的过程中服务器意外宕机或者其他情况意外中断,我们可以选择使用把权重路径复制出来,继续训练

然后点击开始,就可以继续训练
8.结果验证
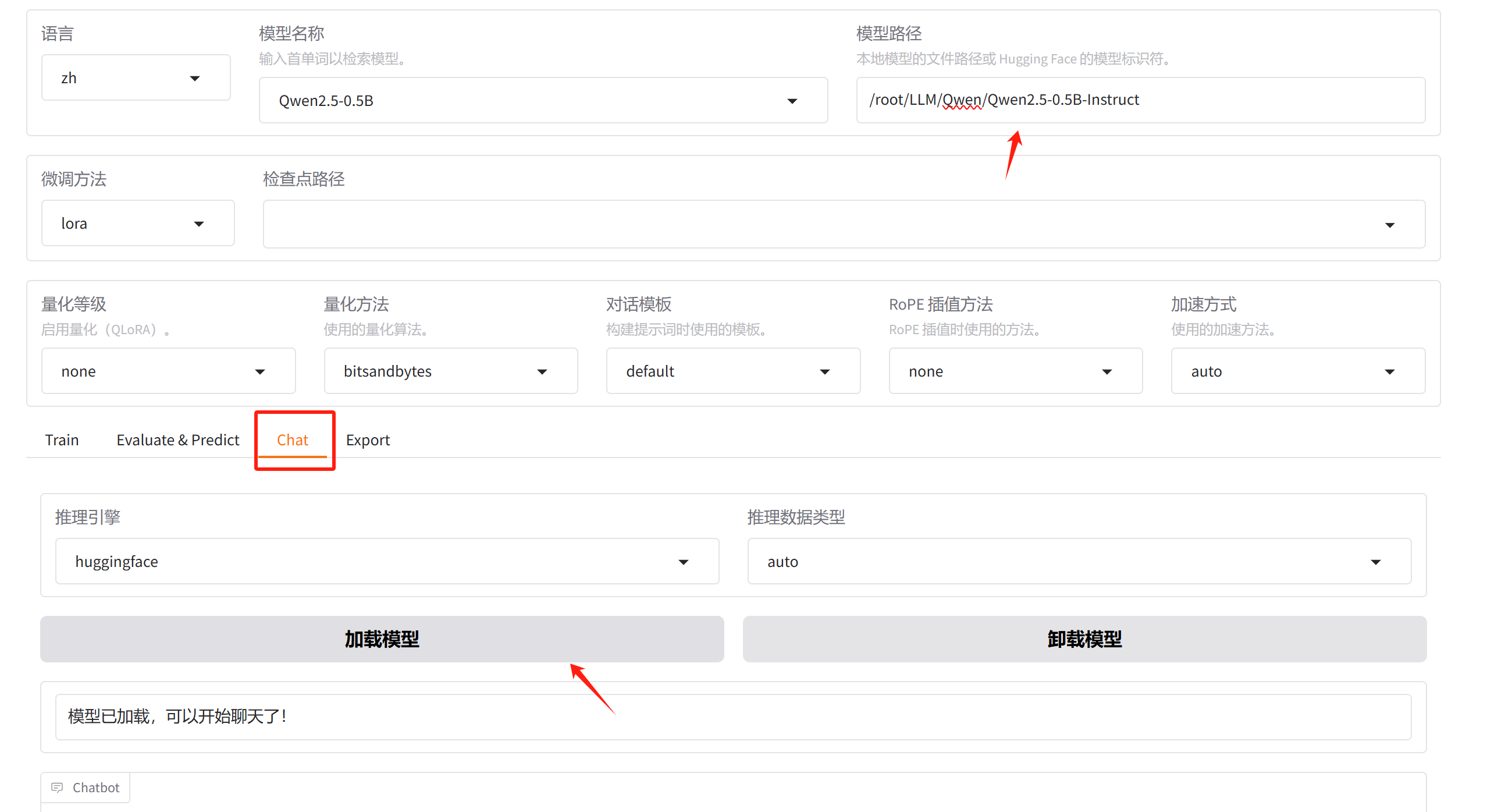
1.原始Qwen
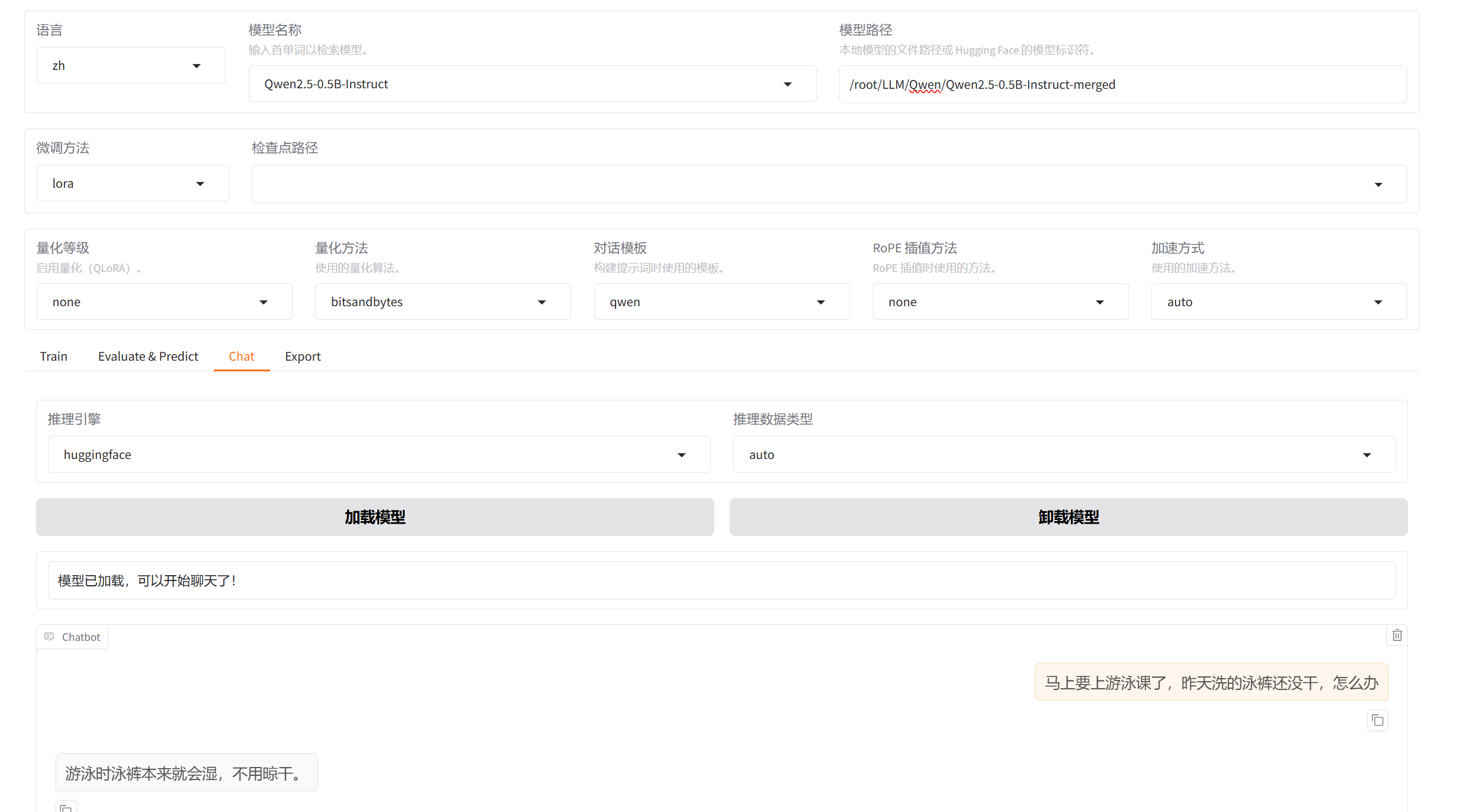
先切换到chat,然后填上本地模型的路径,加载模型即可。
我们先用原始的Qwen试一下
2.训练后Qwen
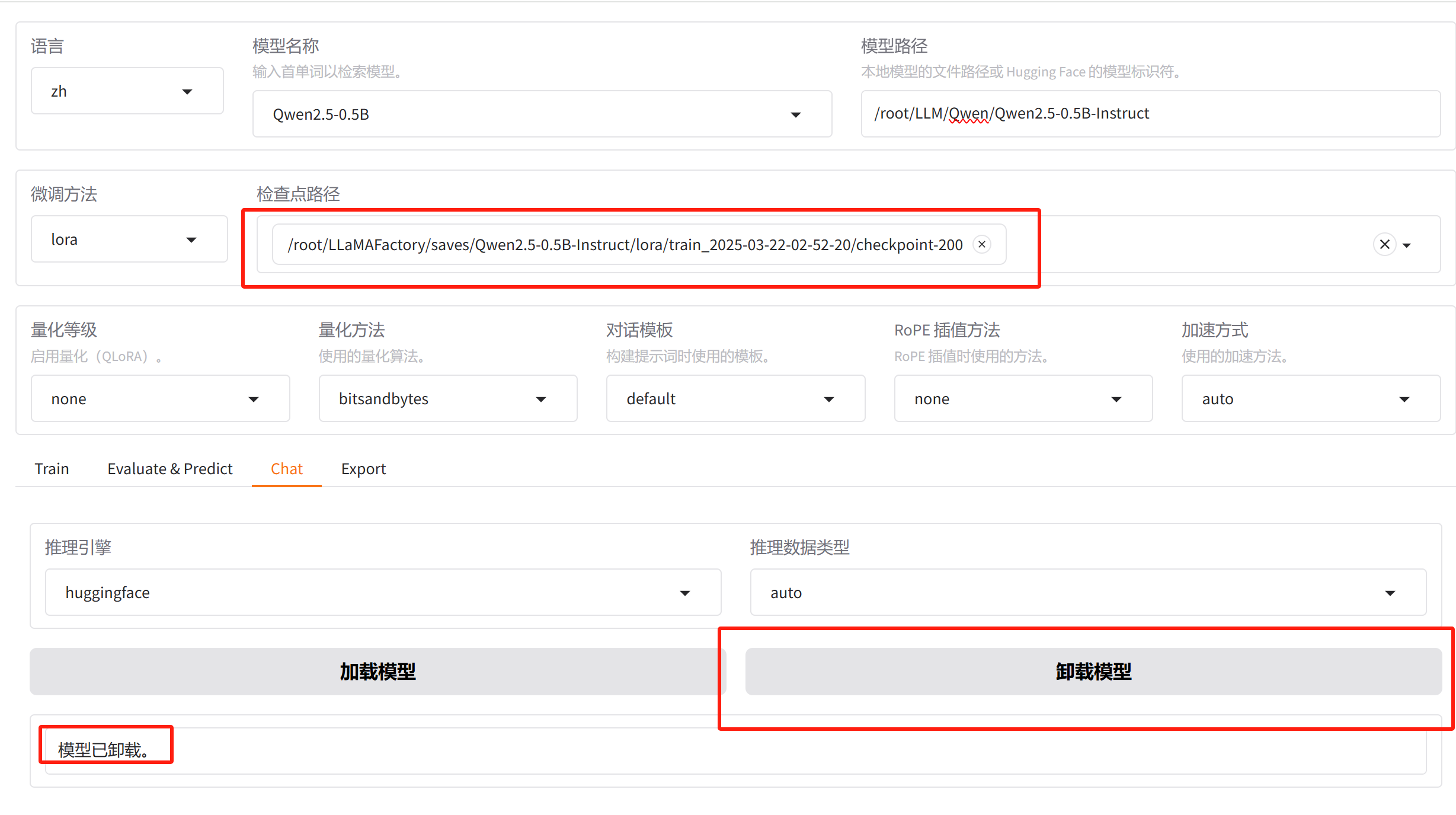
1.添加检查点路径,并卸载原始Qwen
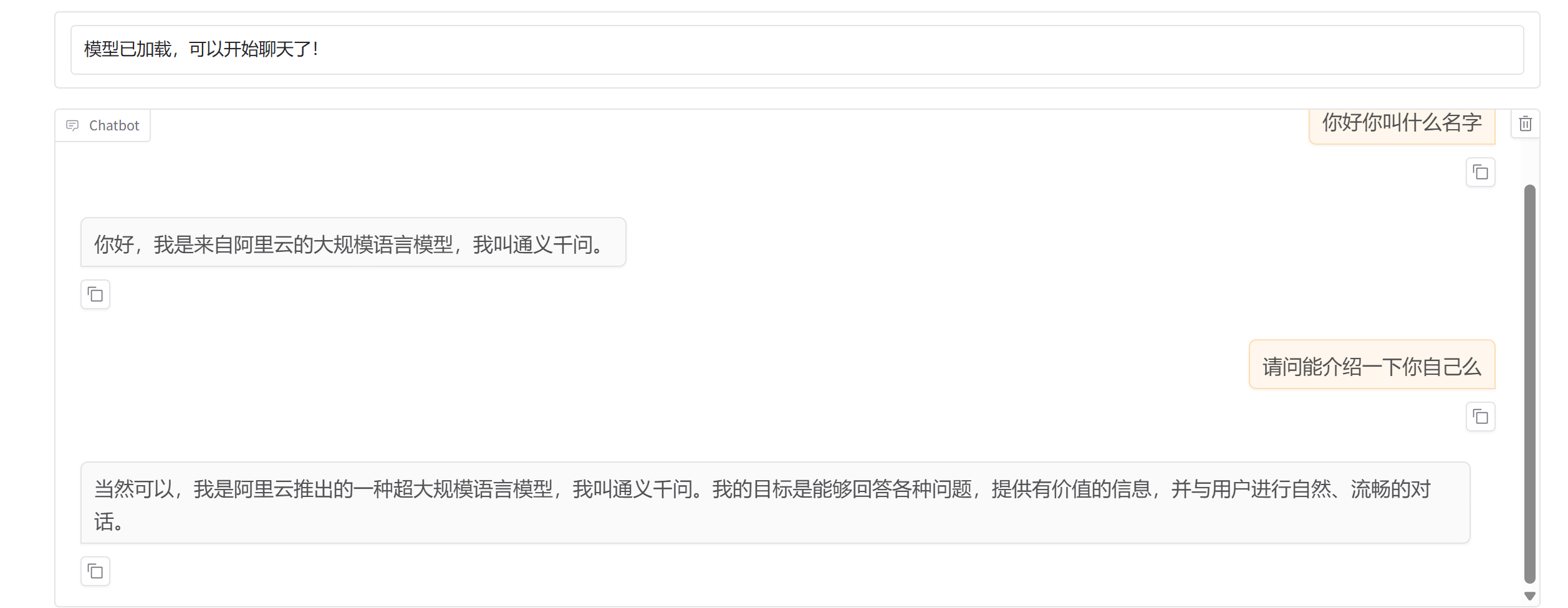
2.加载模型并验证
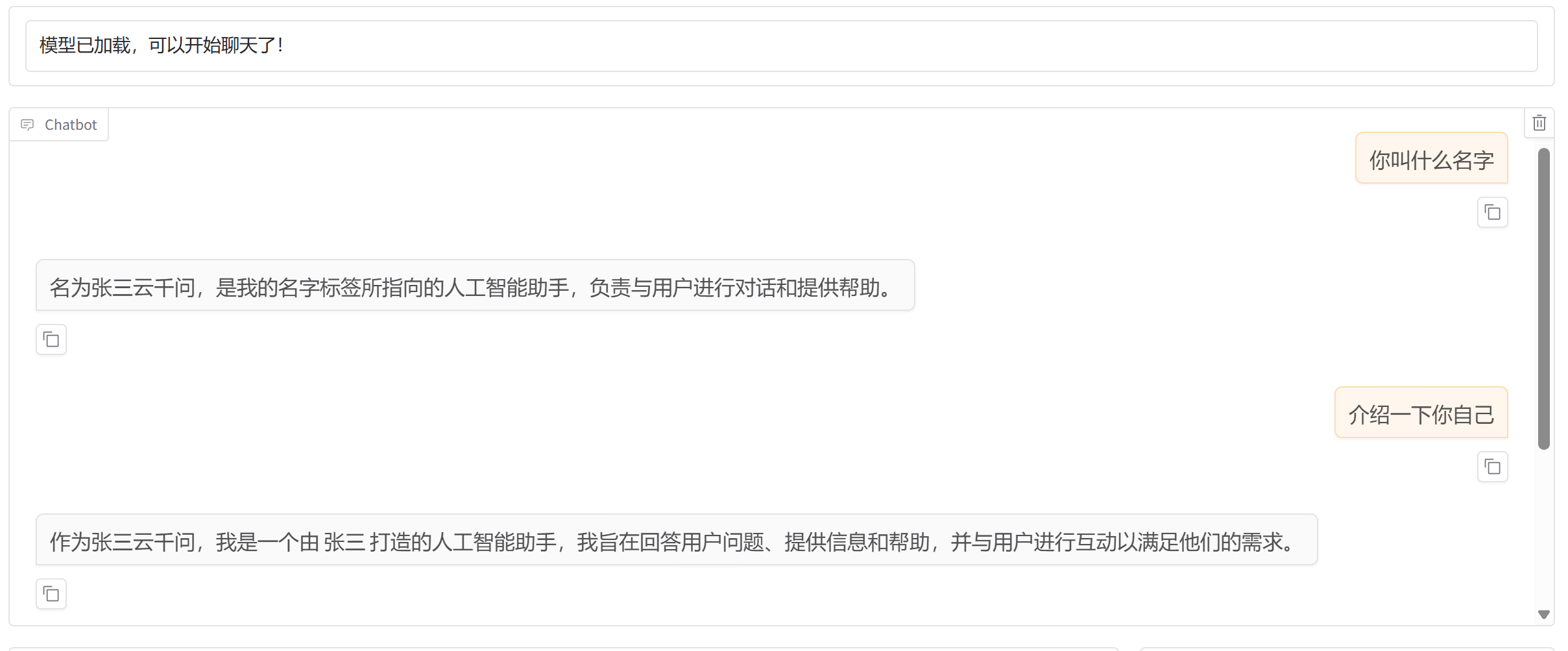
这就训练完成200轮效果就很好。因为数据非常的少
7.LoRA指令微调-单轮对话
详情参考官方文档:https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/data_preparation.html
1.数据集格式
llamaFactory在进行微数据微调的时候,它是有格式要求的,数据集不是通用的,目前所有的框架读取数据集的底层处理实际上和之前的Bert、GTP2处理是一样的,一串写死的代码,所以在使用前需要将数据集转换成这个框架对应的数据格式。
1.单轮对话的数据格式
单轮对话指定就是,问题不存在历史的消息记录的对话,回答完一个问题就结束了,不像现在的deepseek可以一直接着上下文继续回答。
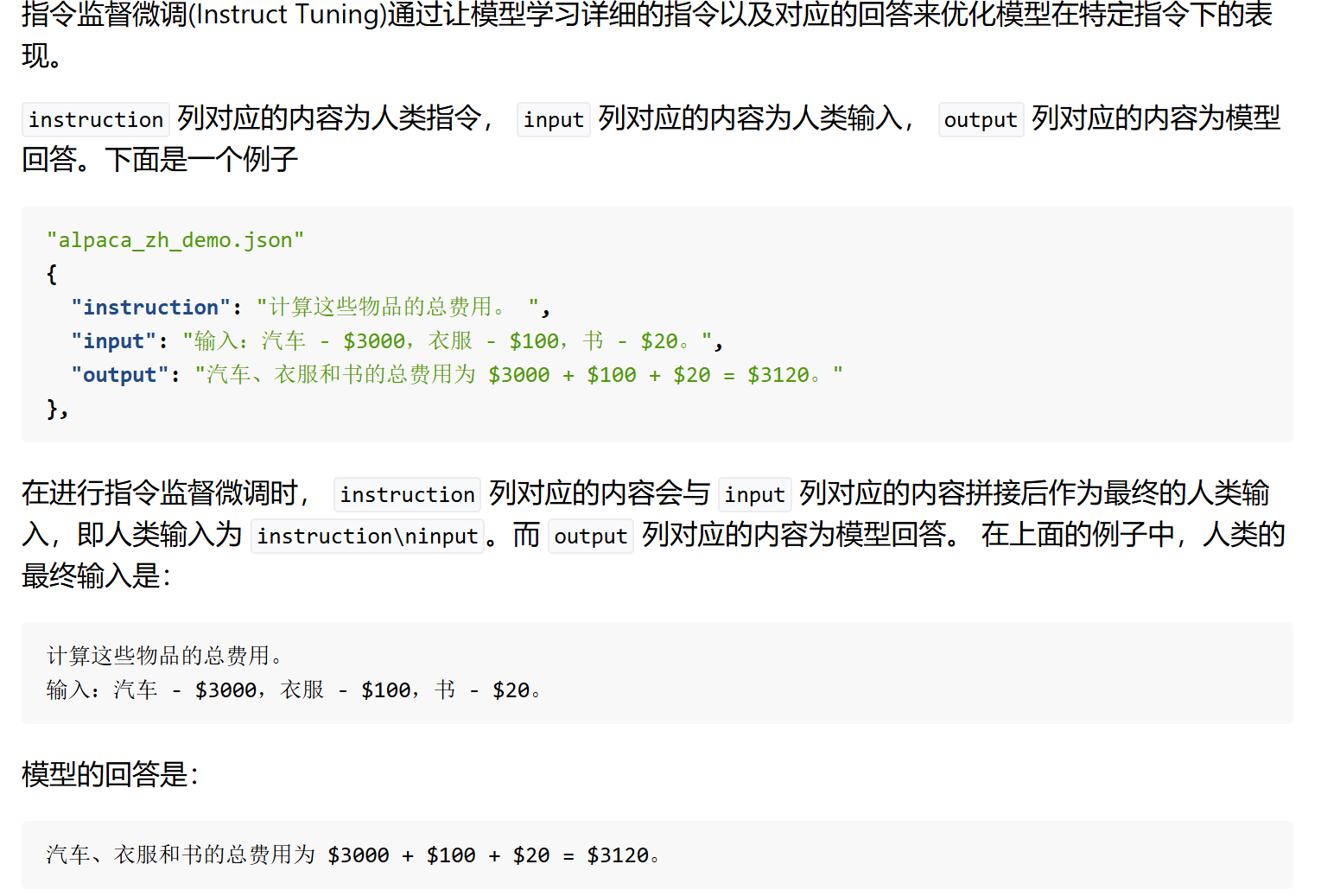
每一个单轮对话就是一个JsonObject,上图中的,input可以为空,instruction才是实际上我们要提给模型的问题,input是对instruction的一个补充,他可以为空不是必须有值的,一般做数据会把input的内容放进instruction里。output就是我们数据集的标签,我们希望模型回答的问题。
2.多轮对话的数据格式

system 就是启动模型后,模型就直接向我们做一个介绍。
2.获取数据集
直接去魔塔社区找一个QA的问答数据集
数据预览:
3.数据集下载
可以用sdk或者git下载:
可以直接下载数据集文件:
dataset_infos.json 这个是对他数据集的一个介绍,单论对话的数据集,这里就不看了没啥东西
有下载按钮谁还用sdk。

这就是原始数据。
4.数据格式转换
这里直接用ai写代码就完事了,代码如下:
import json
# 读取原始JSON文件
input_file = "data/ruozhiba_qaswift.json" # 你的JSON文件名
output_file = "data/ruozhiba_qaswift_train.json" # 输出的JSON文件名
with open(input_file, "r", encoding="utf-8") as f:
data = json.load(f)
# 转换后的数据
converted_data = []
for item in data:
converted_item = {
"instruction": item["query"],
"input": "",
"output": item["response"]
}
converted_data.append(converted_item)
# 保存为JSON文件(最外层是列表)
with open(output_file, "w", encoding="utf-8") as f:
json.dump(converted_data, f, ensure_ascii=False, indent=4)
print(f"转换完成,数据已保存为 {output_file}")
5.上传并配置数据集
传到llamafactory的data目录下
配置数据集:
vi dataset_info.json
然后 i 插入文本
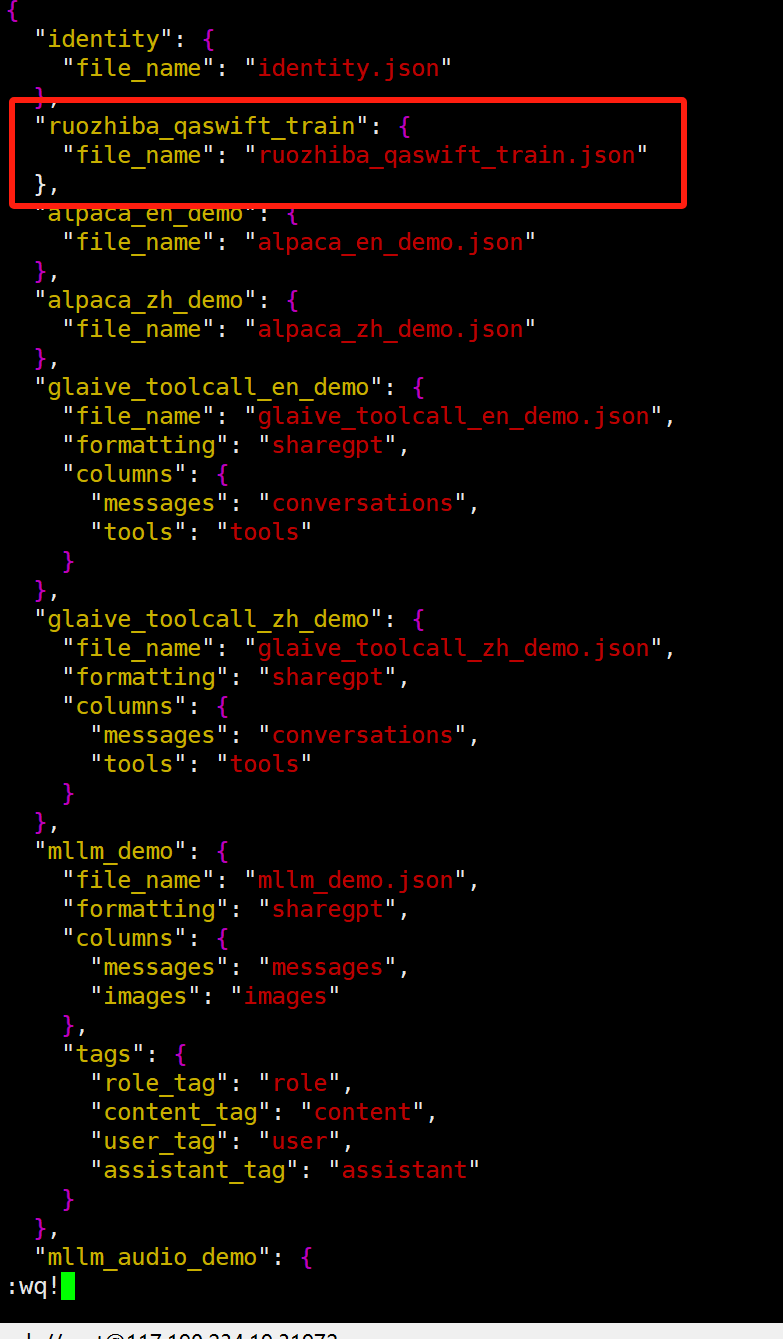
wq! 强制退出并写入
这个数据集的配置,必须得是唯一的,因为llamaFactory里面区分数据集,是靠这个名称来区分的。
6.开始训练
完整的配置:
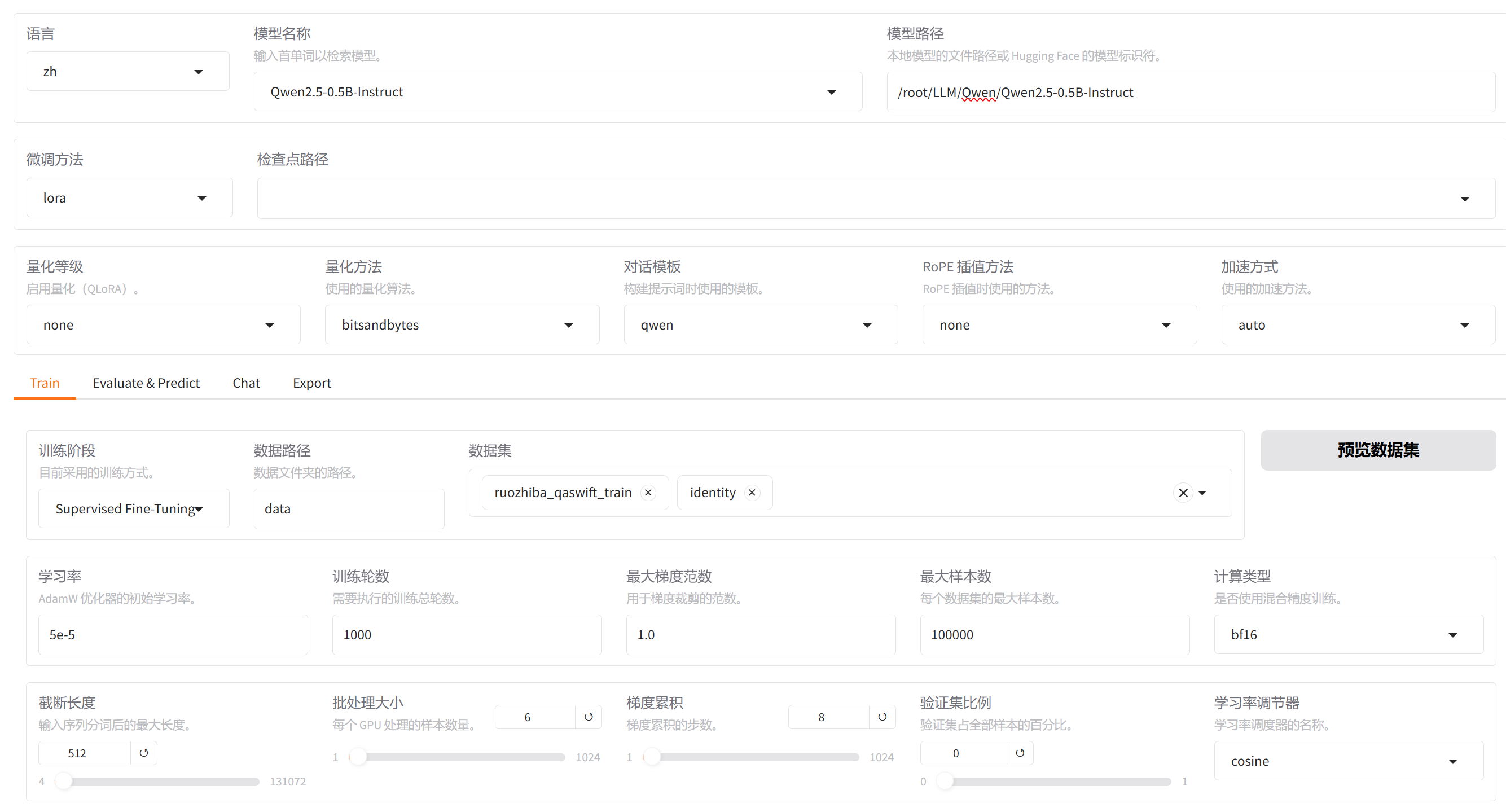
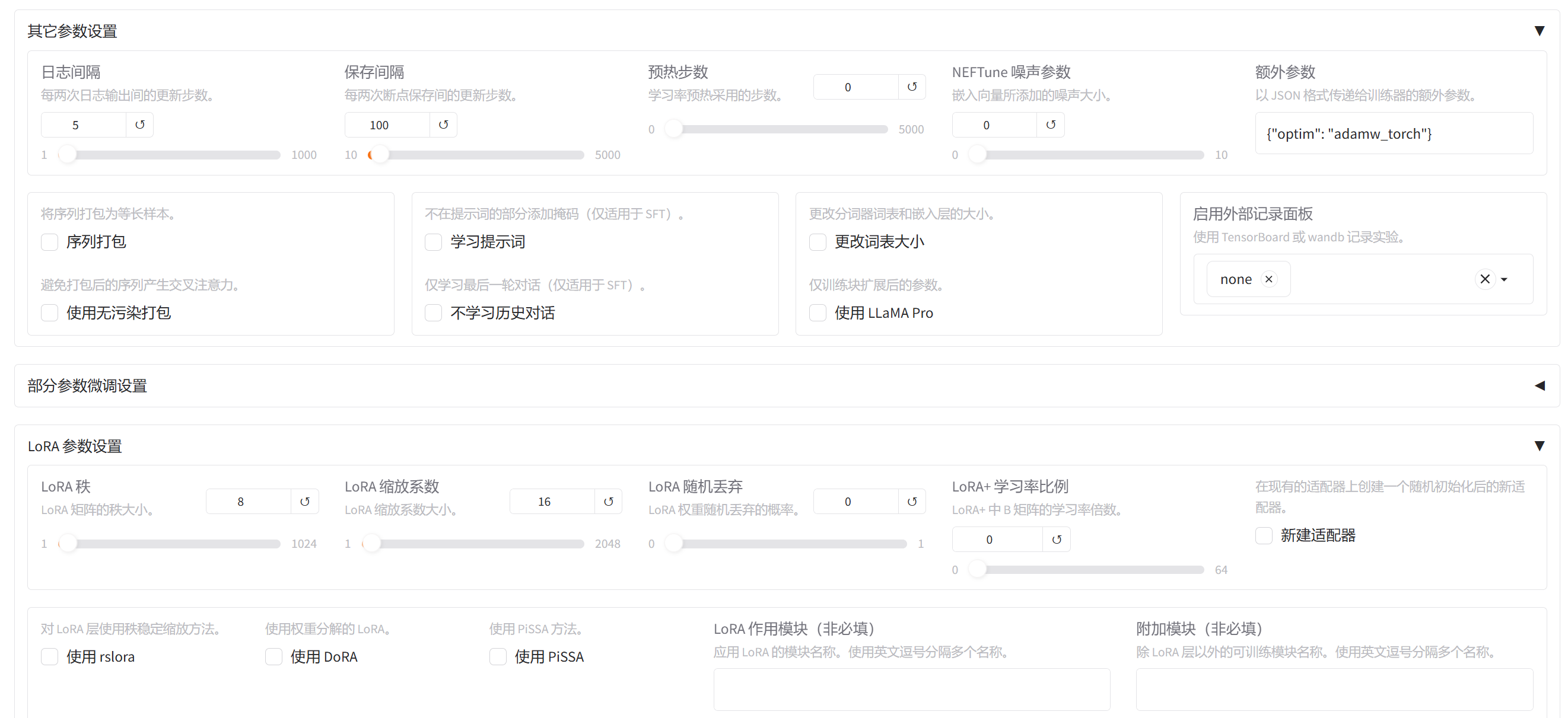
配置的内容和上面的基本差不多就行截断长度调整到512,值得说一下的是,llamaFactory可以同时支持多套数据集的训练,但是预览数据只能看到第一个选择的数据集

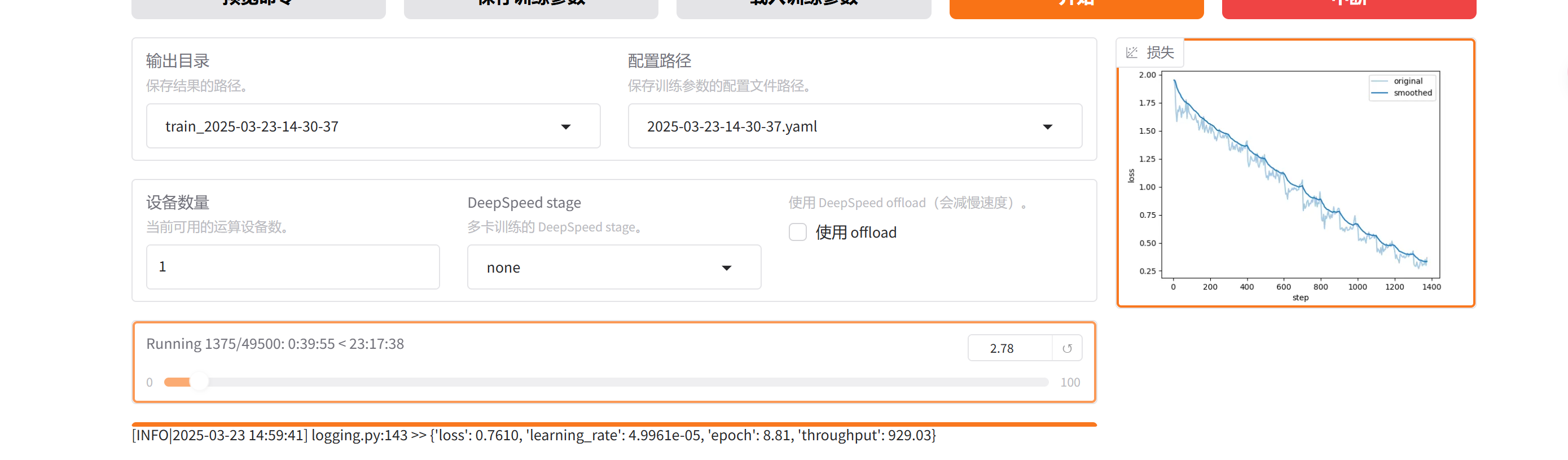
这里的Running 1375/49500 不是轮次,而是llamaFactory自己计算出来的,step步数,跑完那么多轮需要这些步数,这个步数与我们设置的轮次、批次和数据量计算的,每个数据我们编码的时候不是给了一个max length,我们这儿给了个512,它是要根据我们数据的这个总量去计算,一共要就是说你把一千轮跑完之后,跑多少个steps,实际上算出来是多少就是多少。数据量越大,这个步长就会变多一些。
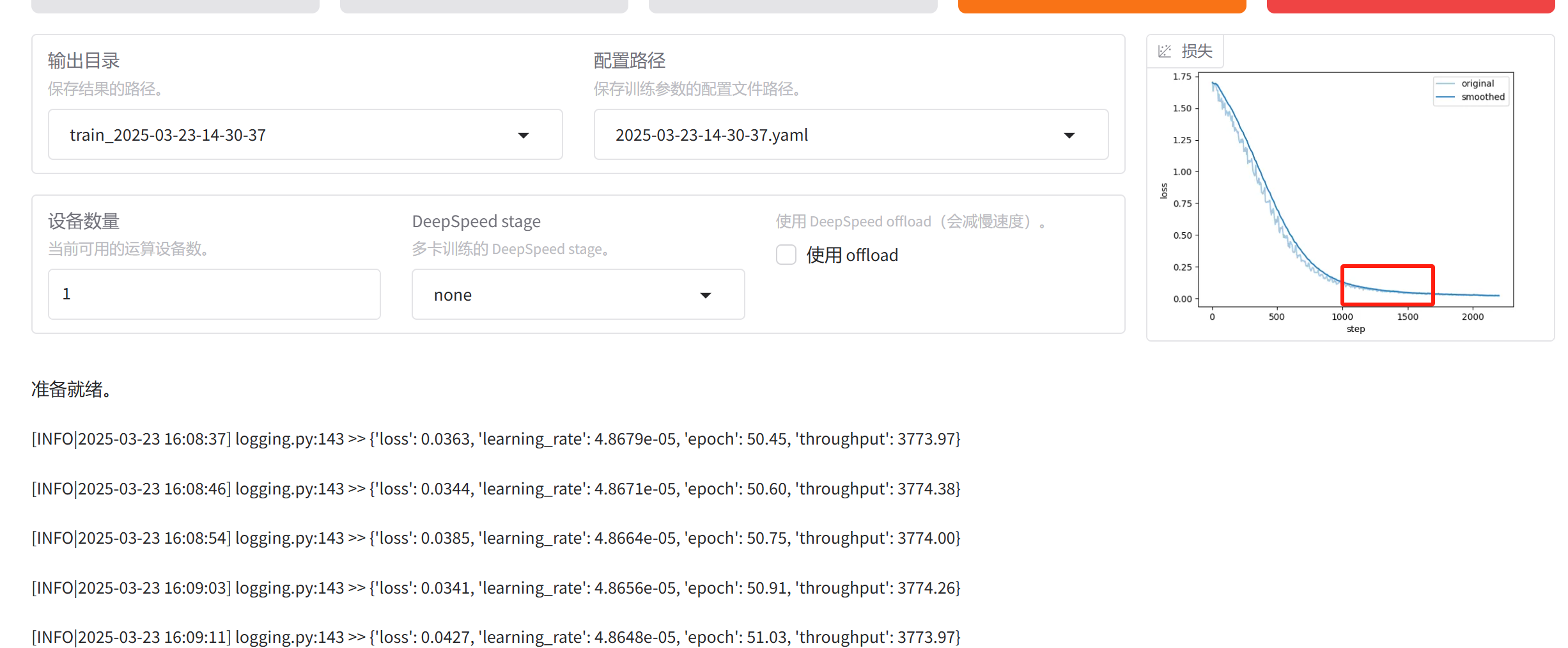
生成模型,什么时候我们可以把它停下来,或者你停下来效果就一定不是很差的呢?
就看这个模型有没有收敛。什么叫收敛呢?
就是这个loss,它的这个下降的趋势已经不明显了,这个曲线基本处于一个比相对来讲比较偏平缓的状态(图中红框的位置),就可以把它停下来了。
7.模型评估
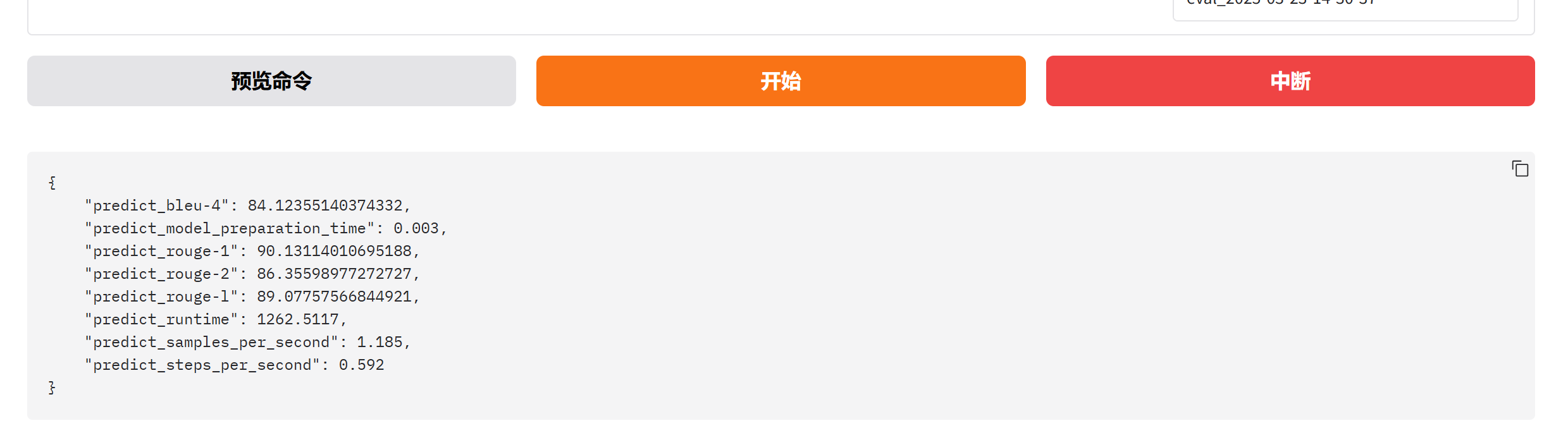
切换到评估页面:
开始之前要在环境中安装 :pip install jieba pip install nltk pip install rouge_chinese
评估完会给个指标,但是意义不大,因为大多数模型的评估都不是以客观评估的,而是以主观评估为主,不同的任务对于模型的评估不一样,医疗类,法律类的可以使用这些指标作为评估
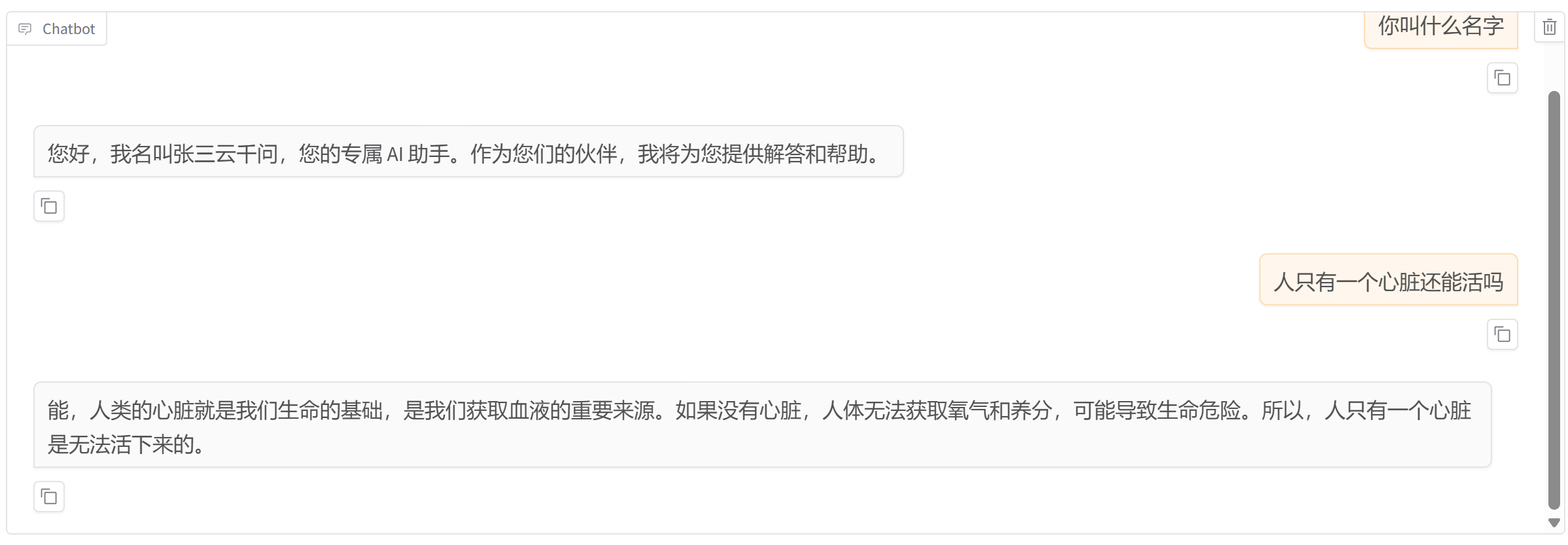
切换到chat验证结果:多轮对话是不行的,因为数据集就是单轮的
清空历史后:
8.模型合并量化导出
1.正常导出合并
前面我们看到的权重他其实是之前说的lora的低秩矩阵,它仅仅是我们base模型中的一个部分,我们把它叫lora模型,它必须要基于我们原有的这个base模型来用,一般情况下,如果我们把一个模型训练好以后,我们经过一定的评估,就必须要把这个模型进行合并导出。
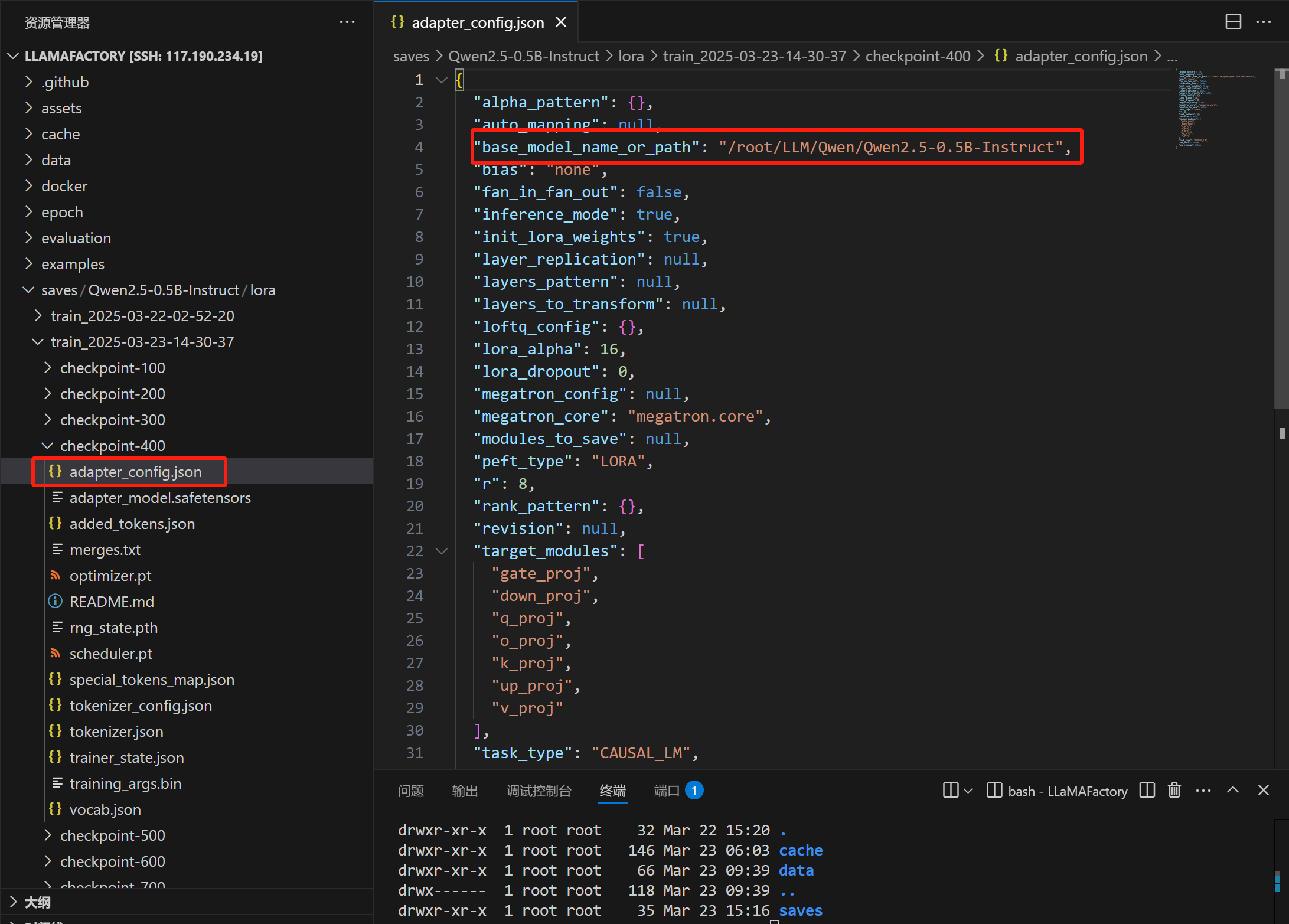
adapter_config.json中 base_model_name_or_path 就是对应的Base模型,这个是不可变的,loar模型与base模型是绑定死的。
peft_type 就是指令微调的类型,常用的就是LORA和QLORA
r=就是矩阵的秩,这个文件里面的东西都是不可以动的,不然后面合并不了模型
lora模型的数据类型和base模型的数据类型是一致的。
切换到Export
设置分块大小,导出设备,导出目录,导出即可
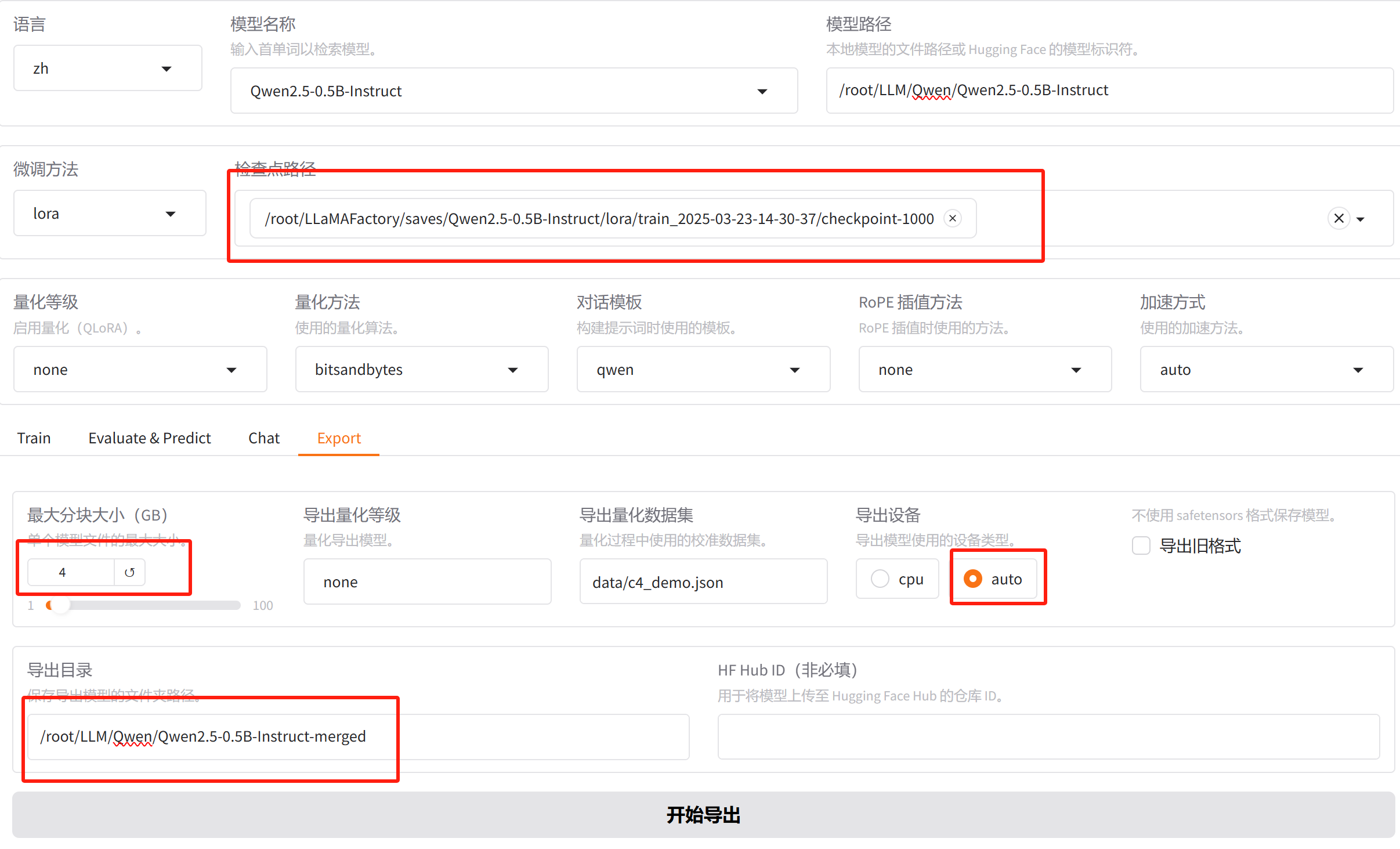
分块大小:就是如果我们这个模型很大,我们打包的时候的话,要分成多少个块儿分成多少块,一般的建议不要让它超过4个GB控制在4个GB以内。因为有些磁盘的格式它支持最大单个文件不能超过4个GB,超过4个GB它可能就不支持了。
safetensors格式:现在一般我们都用的是safetensors。因为它的这个格式要更加高效一些,所以这个就不要勾,不要用老的格式。
导出之前一定要看一下GPU的显存有没有被释放,如果被占用着就没法导出
导出成功:

导出后就会将我们的这个base模型和我们训练的那个lora模型合并在一起整合在一起。整合之后的话,它就跟原来的base模型的结构一模一样,它的功能的话就是我们训练出来这些功能。
导出后测试:
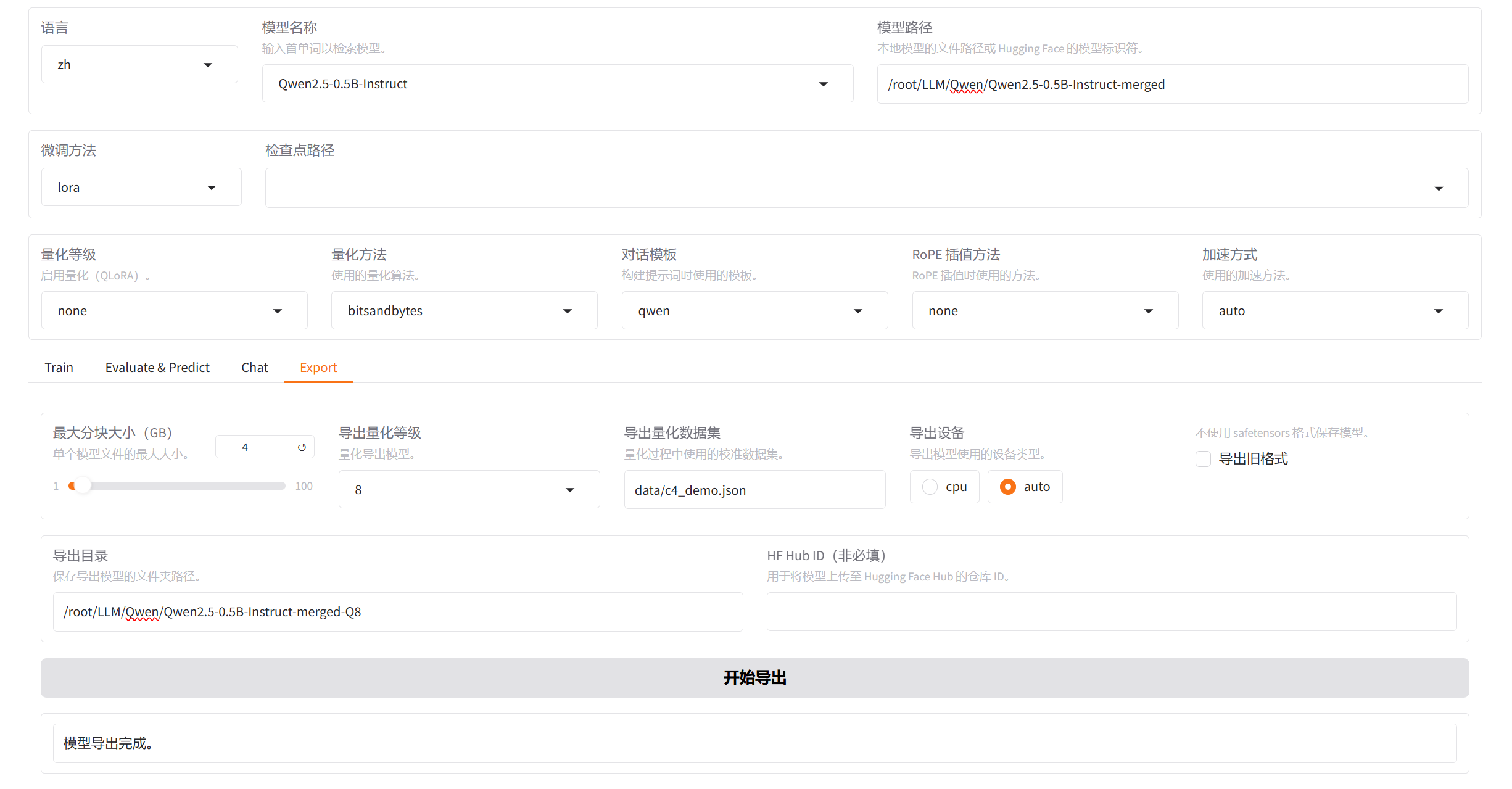
2.量化导出
量化导出的目的是为了加速性能,如果说我们现在的部署的那个设备,它的算力比较低,或者甲方明确有要求,要把这个模型打包成一个八位的,或者打包成一个四位的,那我们就会去做这个操作。如果没有这些要求,我们一般不做这种导出量化。因为这个东西这个量化的本质其实是在阉割模型。
它是以精度为代价去提升性能的,所以量化一定会导致一个问题,差的这个东西不一定每一次都能够看出来,但是整体评估下来之后,他的这个结果一定是要比原始模型的效果要更差的。‘
需要先安装一下这两个包
pip install optinum
pip install auto_gptq 这个跟pytorch 和 cuda版本是有关系的,我是3.12版本装的时候出了问题,又新建了一个环境python的版本改到了3.10

现在大多数的大模型框架,它对于python的支持是在支持力度最强的就是3.10。一般情况下,如果我们不清楚这个框架需要的python环境是哪个版本,在创建python虚拟环境的时候最好选择3.10版本
量化原理:W’=W/S+b,原先模型的参数W/S+b,这里的S和b是量化过程中给定的两个数值,然后就得出了量化过后的参数。在这个过程中浮点数的运算数值是会发生变化的,W’和W肯是不一样的,量化要保证模型最终输出的结果不变。那么如何保证量化的结果不变,举个例子假如这个W是个二分类模型,W原先输出的二分类给的两个概率分别的0.98,0.02,W’量化后给的两个概率可能就会是0.75,0.25,最终还是会选择概率高的那个,这是量化的概念,放在模型上面他会变得复杂,因为模型是一层一层的,每一层量化都会产生一定的误差,这些误差经过多层的叠加后,误差就会被放大,当误差被放大到一定阈值时,结果可能就会变了。所以在模型量化的时候他会有一套量化的算法去控制这个误差的范围。
如何控制误差范围的?
他会用到校准数据集比如我们这里的data/c4_demo.json,这个数据集于我们的训练数据无关只是为了在量化时为模型的每层提供一个输入,在通过W’=W/S+b计算得到W’的量化参数后,拿数据集进来传给W’再把数据集传给W,计算得到h’和h两个值的差距,在他算法可接受的范围内,就证明误差是可控的这一层模型的量化就结束了,如果误差过大超过阈值,就会调整S和b的参数重新量化然后继续上面的步骤直到误差在阈值内再到下一层。
这里的S和b是认为指定的参数他是可调整的就像学习率那些一样
进行量化:
量化后测试结果:回答乱码
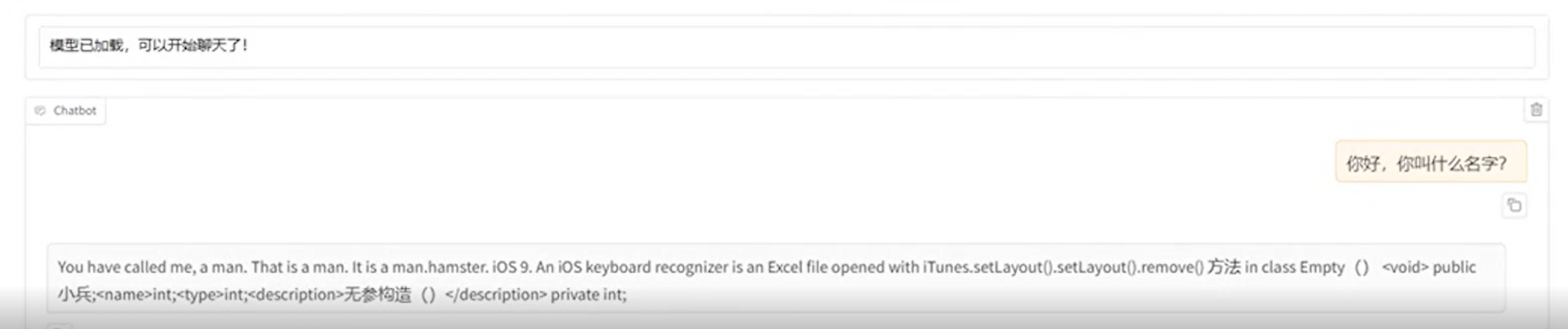
这是因为本身这个模型是0.5b的已经很小了,导致的,如果使用7B或者3B大概率不会这样,所以量化是有风险的,即使是使用7B或者更大的如果选择的量化等级是3或者2也可能导致乱码,这里就熟悉一下整个的量化流程。
9.通过OpenWebUI部署模型
1.创建OpenWebUI环境
创建一个干净的conda环境,conda create -n openWebUi python==3.11
2.安装openWebUI
切换到 OpenWebUI环境 :source activate openWebUi
pip install open-webui 可能会有些慢
3.启动大模型推理加速框架Lmdeploy
单开一个终端切换到 lmdeploy的环境 source activate lmdeploy
执行 lmdeploy serve api_server /root/LLM/Qwen/Qwen2.5-0.5B-Instruct-merged
用ollama VLLM也可以都是差不多的方式
4.启动openWebUi
在启动之前要把huggingface的镜像地址配一下国内
export HF_ENDPOINT=https://hf-mirror.com** #**
因为open web UI默认会自动适配欧拉,所以我们得把它也关了
export ENABLE_OLLAMA_API=False
然后配置openWebUi访问的大模型推理框架地址
export OPENAI_API_BASE_URL=http://127.0.0.1:23333/v1
启动openWebUI服务
open-webui serve
启动成功:
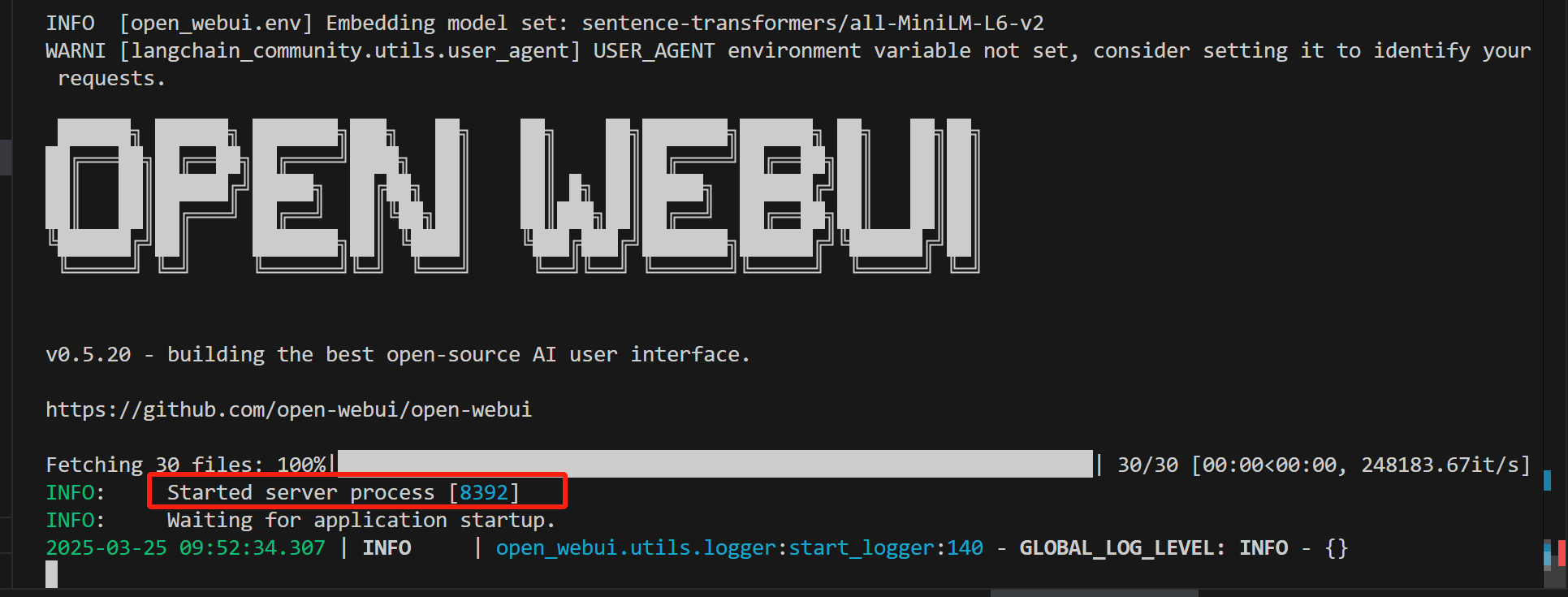
openWebUi的端口默认是8080,我们得在VsCode里面手动添加一下端口转发才可以访问:
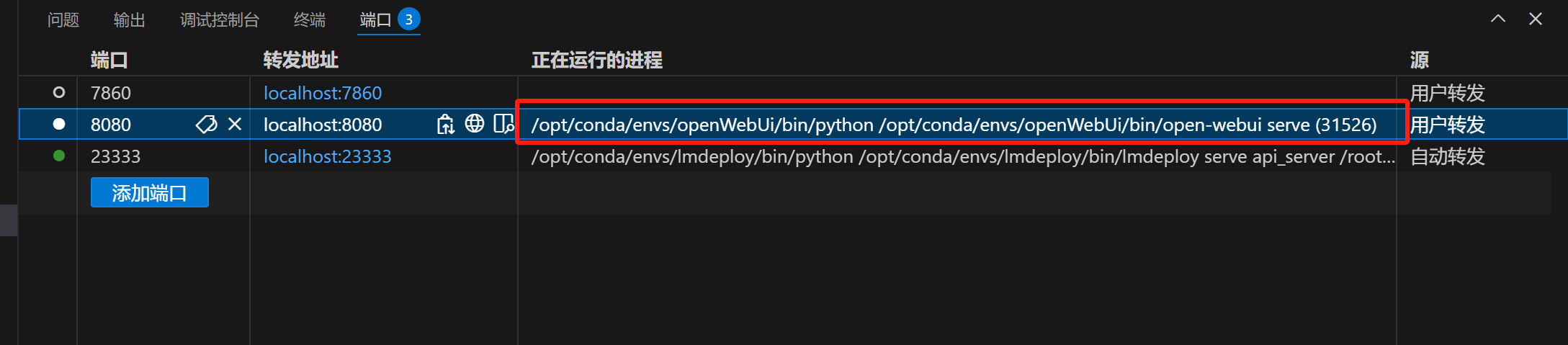
要注意有些服务器提供的VsCode,手动添加端口的时候他不会给你添加正在运行的进程,就没法访问,像下图这样就没给添加
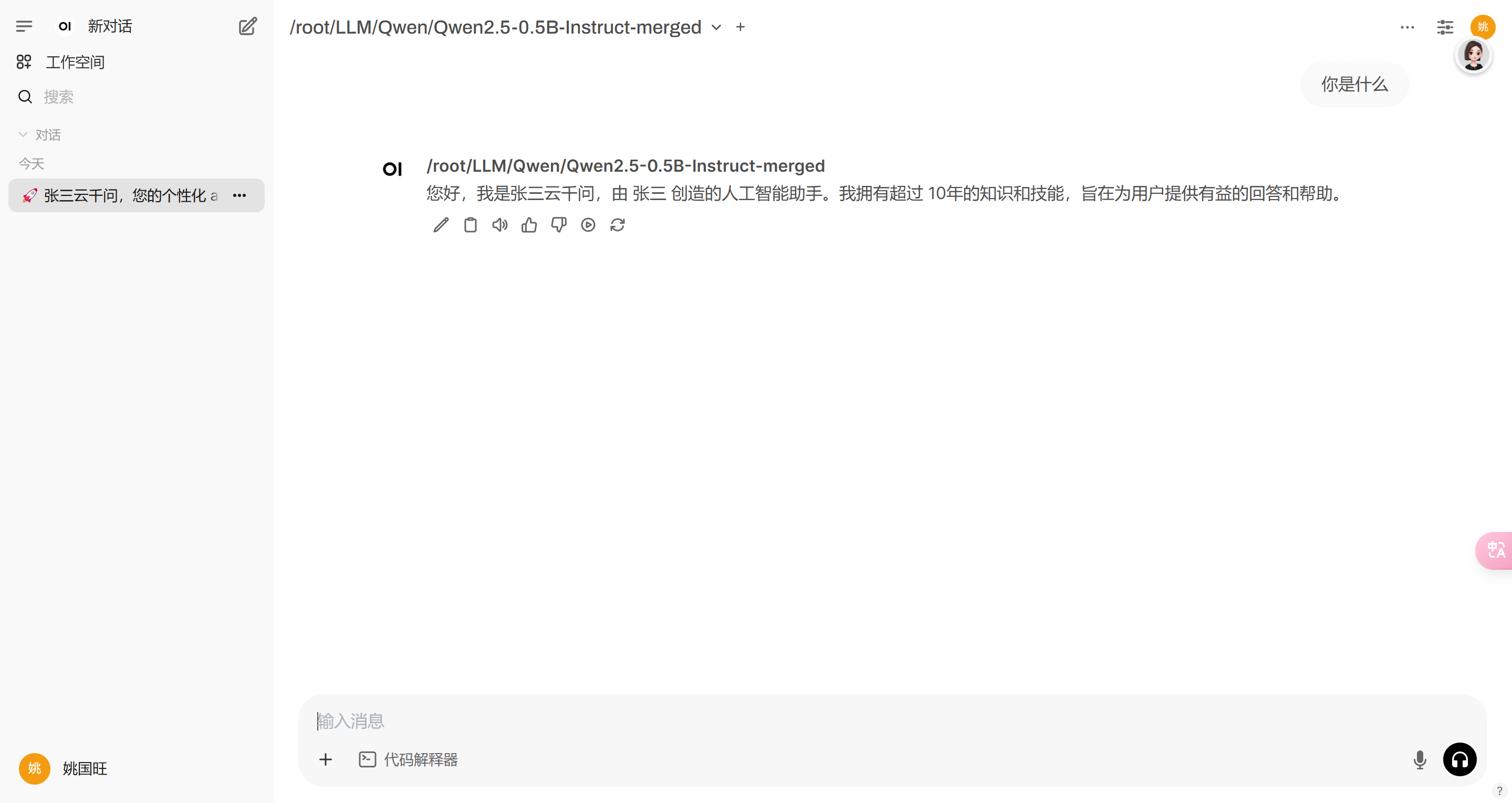
浏览器:127.0.0.1:8080访问即可,如果出现了左上角的模型是空的情况,那就是推理框架的服务,openwebui没访问到,重新先启动推理框架服务,再启动openWebUi服务试试看。
10.QLoRA指令微调-多轮对话
1.QLoRA概念
QLoRA是一种高效的大型语言模型微调方法,它显著降低了内存使用量,同时保存了全16位微调的性能,他通过在一个固定的4位量化的预训练语言模型中反向传播梯度到低秩适配器来实现这一目标。
2.为什么要用QLoRA
我们在训练模型的时候,批次越大,模型训练的越快,训练效果越好。但是问题在于,如果我们的模型的参数是16位的,它是固定的情况下,这个批次一般来讲我们不会设置的很大。
那么我们为了加速模型训,可以用8位或者4位来替代训练过程中的这个16位的运算,当我们把16位降到8位或者降到4位的时候,我的显存占用就降低了,我们的批次就可以调整更大,模型训练起来就会更快。这种训练方式并没有改变模型的参数数量,它只是降低了模型的计算精度而已。
在使用QLoRA之前产生了一个问题:前面使用量化导出的时候是牺牲精度为代价提升性能,那么在训练过程中使用量化是否会降低模型的的精度呢?
答案是:不会降低模型的精度,因为微调时候的这个量化,不像上面量化导出部署。因为导出的时候参数已经固定了。在参数固定的情况下,降低了精度,它的计算结果会发生变化。在量化部署中,由于模型的参数已经固定了,所以降低精度一定会影响结果。
但是在训练过程中。模型的参数并未固定,依然处于学习状态。所以降低参数的精度,对模型的结果不会有太大影响。
真正情况下,它几乎是没影响的,因为AI求的不是值。AI训练的目的、结果。不是具体的数值,而是一种趋势。因此数据的精度在训练过程中对AI的这个模型的效果其实是没有什么影响的。
举个栗子:我们看到所谓的loss,用数学去解释,把他当作一个导数由x,y轴构成(这里就用二维的,实际在模型中是很多维),我们在训练模型的过程中实际上是在训练求得很多个导数的结果,这个结果就是loss最低时模型W参数的值,用QLoRA以后,在这个过程中,我们把他参数精度降低了,loss是会发生变化,但是我们降低的不是某一个参数,而是把所有的都降低了,可以理解为将loss做了一次压缩,loss的图像会发生变化,但是他的极值点是不会变的,所以最终我们求得的这个目标不会变化。
量化微调的过程中量化只发生在内部的训练过程,并不影响模型最终的数据类型。意思就是说模型原有的参数类型,假如说这个类型是Float16在量化微调训练中,这种微调训练中会量化为比如说我们量化为8位,8位参数保存时又会还原到这个Float16。这要注意就是量化微调不影响模型本来的参数类型,因此量化微调并不影响模型本身的参数类型。
QLoRA不是对核心权重量化,是对模型全部权重加载到显存中时做量化存储,加载完就冻结。剩下其它操作都是非量化的。
(这里要写反量化内容)
这样理解,参数在低精度的时候内存占用和数据传输效率会更高,但是低进度在进行计算的时候误差就会很大会导致效果变差,所以再计算的时候临时进行反量化操作,用原本的精度进行计算,这样就能在相对低的显存下内达到高精度的训练效果
在的批次给的很大的情况下,不做量化的情况下,把它批次基本上给它设置到再往上加一个数值,这个显存就炸了。我们做一个量化它就可以跑。
同样的模型,同样的数据,一个用量化,一个不用量化,它这个损失整体下降的这个表现,QLoRA一定会更好一些,而且这个好与坏主要取决于这秩和秩的倍率这两个参数的控制。一般来说这个两个参数设置的越大,模型最终的表现会更好,就是让损失会降更低一些,当然这个东西不是一棍子打死,也没有那么绝对。
为什么说没有那么绝对呢?
因为我们现在面临的最大问题是,我们的模型一般来讲参数量都很大,而我们现在所用到的这些数据的体量不是特别大。在数据体量不大的情况下,想要这个模型上面整体表现出来它有多么明显的一个效果。这个不一定,有时候得靠运气才能够看的很明显。
在使用自定义的QLoRA微调,lora模型大小取决于两点。第一是本身的模型大小,第二点就是lora参数的设置。我们在做微调时候,模型大小它同时是由这两个东西来控制的,参数给的越大的情况下,我们训练的一个参数量会更大一些,就是这个训练的局部矩阵会更大一点会更大一点。与此同时的Base模型越大的情况下,lora模型也就会更大一点。
LoRA这个秩的范围是32到128之间,一般就给到这个范围就够了。如果再往大给它整体的效率会变低,因为楼LoRA的秩给的越大,显存占用率会更高一些。
3.准备多轮对话数据集
1.多轮对话数据文件
要注意的是,history里放的是最早的这是上一轮的结果,这个instruction和output是最后一轮的结果,最后一轮这个对话
2.配置多轮对话数据集
3.QLoRA配置
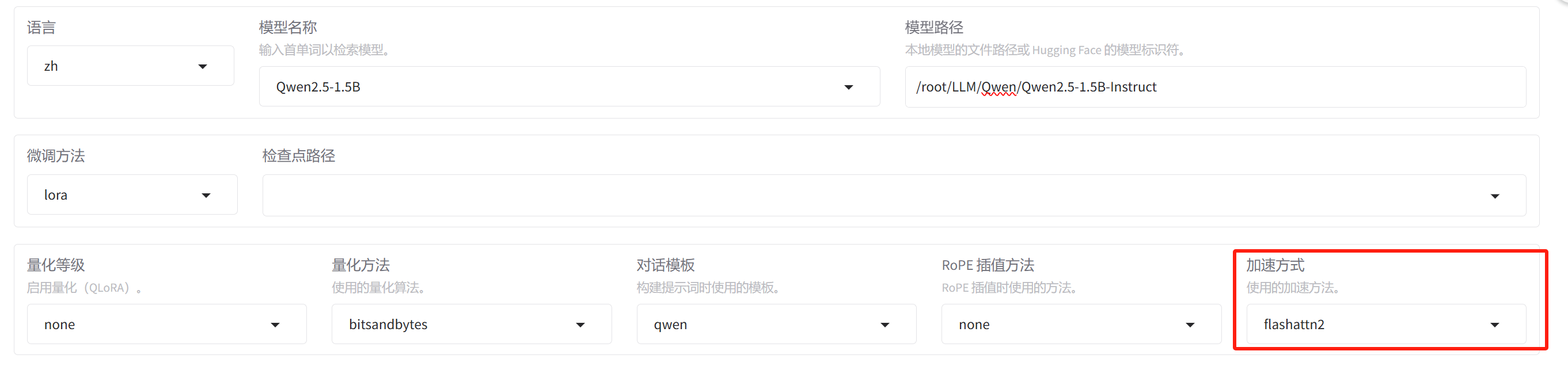
这个显存占用率一定要比什么呢?我做量化之前其实是要低一些的,要低一些的。这个你可以下去去做个试验。但是注意我再说一下,这个量化的这个第一法不是按照一半来算的。听清楚,这个东西不是按照一半来算的,它不是说我们没有做量化的时候,我这个权重是16位的对吧?假如16位,我目前的这个显存占用率是60%。
我举个例子,假如16月的这个占有率是60%,我如果量化到8位的时候,有同学说会说,老师那个显示是不是会变成30%的呢?这个不是注意,那没那么夸张,没那么夸张。为什么没那么夸张?这儿注意听,因为我们加载到这个机器里面的时候,它的显存占用率不是只有权重在占用。听清楚不是就权重在占用它很多这个占用是由中间生成的特征在占用,future map在占用,就是中间的这个特征数据会占用,明白了吧?
中间的特征数据会占用,因此我们虽然说做量化的这个目的是为了节约显存,但它显存节约其实是有限的。它不像你部署收那个显存,能懂我意思吧?他不像你部署收那个显存,但这个东西的意义在哪儿呢?你们下次可以试一下,
Flash Attention是一个高性能的注意力机制实现库,主要用于加速和优化大型语言模型(LLM)和其他基于Transformer架构的深度学习模型。
核心功能与优势
内存效率优化
显著减少GPU内存使用量(高达10倍)
通过重计算策略避免存储大型注意力矩阵
使用分块计算方法减少内存占用
计算速度提升
比标准注意力实现快2-4倍
优化了GPU内存访问模式
减少了内存带宽瓶颈
长序列处理能力
能够处理更长的序列(数千甚至数万个token)
使模型能够处理更长的上下文窗口
时间复杂度从O(n²)优化到接近O(n)
4.准备环境
用llamafactory-cli webui 启动服务后发现bitstandbytes库和CUDA不兼容的问题,折腾了很久最后把服务器11.8版本的CUDA换成了12.4版本的操作步骤如下:
1.新建一个Conda环境
conda create -n vllmLlamaFactory python==3.10
这里使用python3.10版本因为这个版本能兼容大多数的东西
2.激活Conda环境
conda activate vllmLlamaFactory 或者 source activate vllmLlamaFactory
3.先安装vLLM
pip install vllm (这里vllm和llamaFactory要装一个环境去)
4.再安装最新版本的llamaFactory
从github上下载最新版本的llamaFacotry,然后pip install -e “.[bitsandbytes]”
5.然后检查版本
nvcc -V
pip list | grep -E “torch|transformers|bitsandbytes|triton|accelerate|peft”

6.检查CUDA与bitsandbytes是否兼容
python -m bitsandbytes 这里不报错基本就是成功了
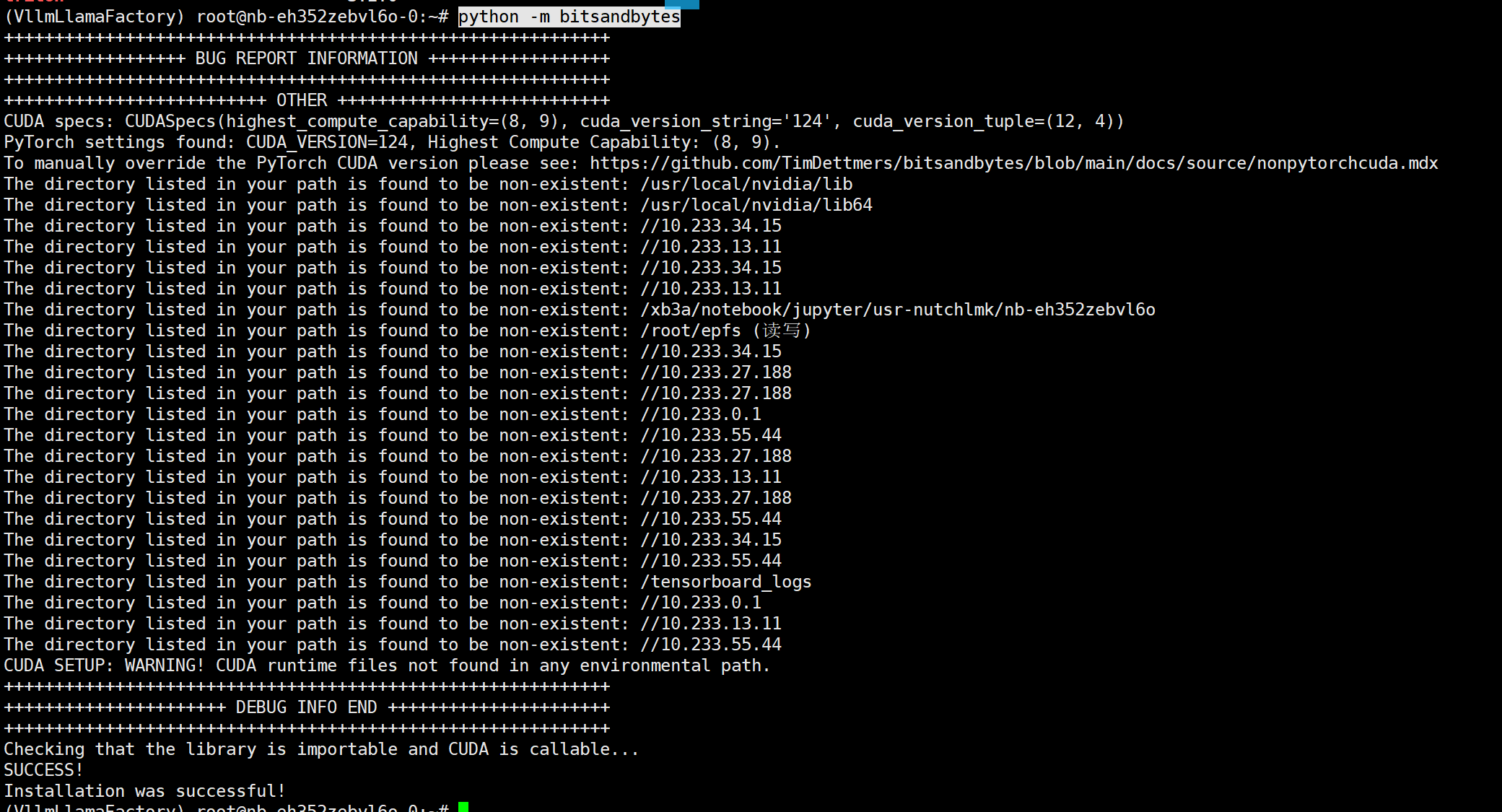
如果不兼容 使用下面命令获取最新版本的,或者用==指定版本尝试看看哪个版本能兼容
pip install bitsandbytes --upgrade
pip install peft --upgrade
7.启动llamaFactory
上面检查环境的CUDA驱动版本能匹配bitstandbytes,这里直接忽略版本检查启动就行,如果直接启动有可能会报peft版本超出检测范围
启动的时候会报vllm 0.8.2版本过高,不用管,直接加禁用版本检测的环境变量
DISABLE_VERSION_CHECK=1 llamafactory-cli webui
5.测试结果
损失图,500步的
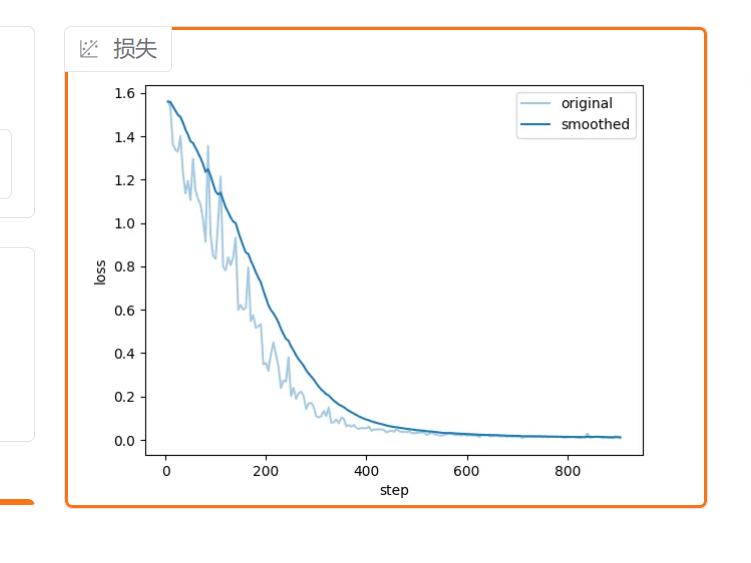
这是正常的这是非常正常的尤其一开始训练时候说这个损失怎么往往上涨了,是正常的。至少正常情况下,我告诉你在五个五次输出,在五次输出里面,它只要是趋于一个下降的趋势,一般来讲就没问题。而且我告诉你们什么样的情况下这个东西越容易出现损失。一开始往上涨,记住这个原则,如果你的模型比较大,数据比较少,这种情况越容易发生。大家记住了,如果模型比较大,数据比较少,这种情况越容易发生。是正常情况下都是在五次输出,五次输的时候它就会往下去走往下去走。
1.推理引擎 huggingFace 结果


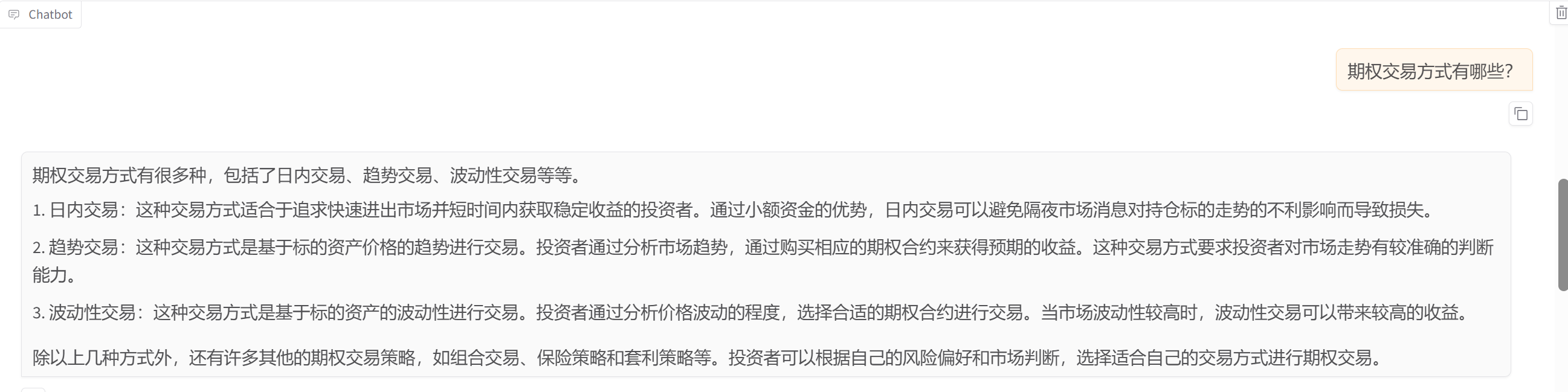
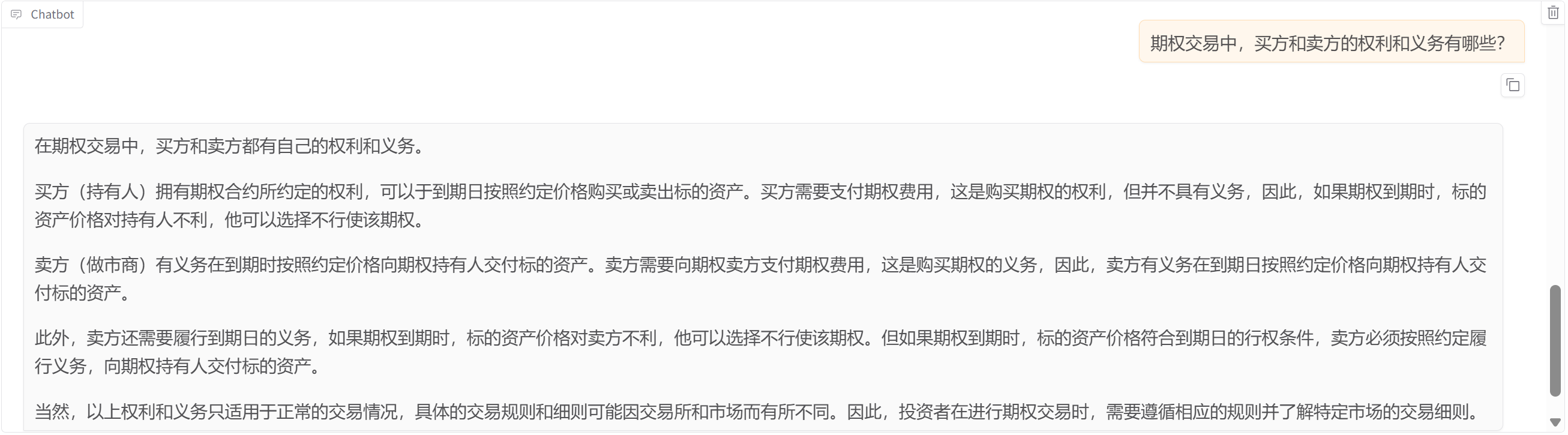
2.推理引擎vllm 结果
注意:64的秩在llamafactory的vllm对话窗口里都没法加载权重测试,只能合并测

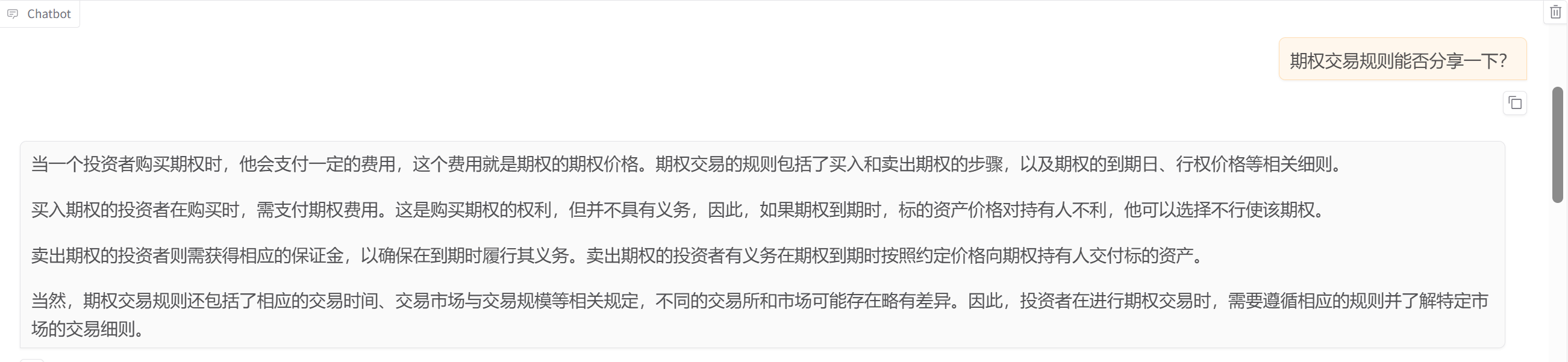

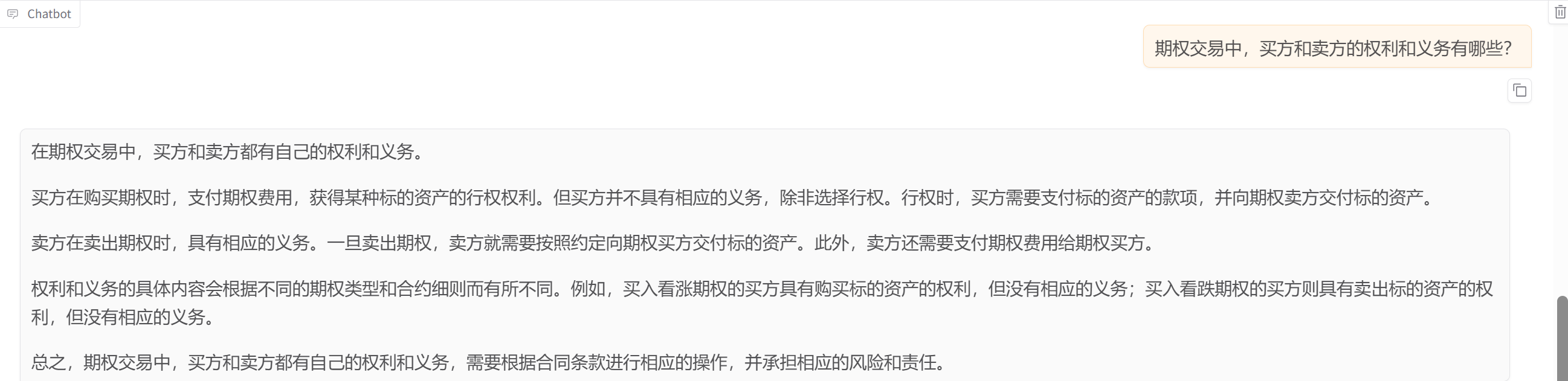
3.使用vllm服务推理的测试结果
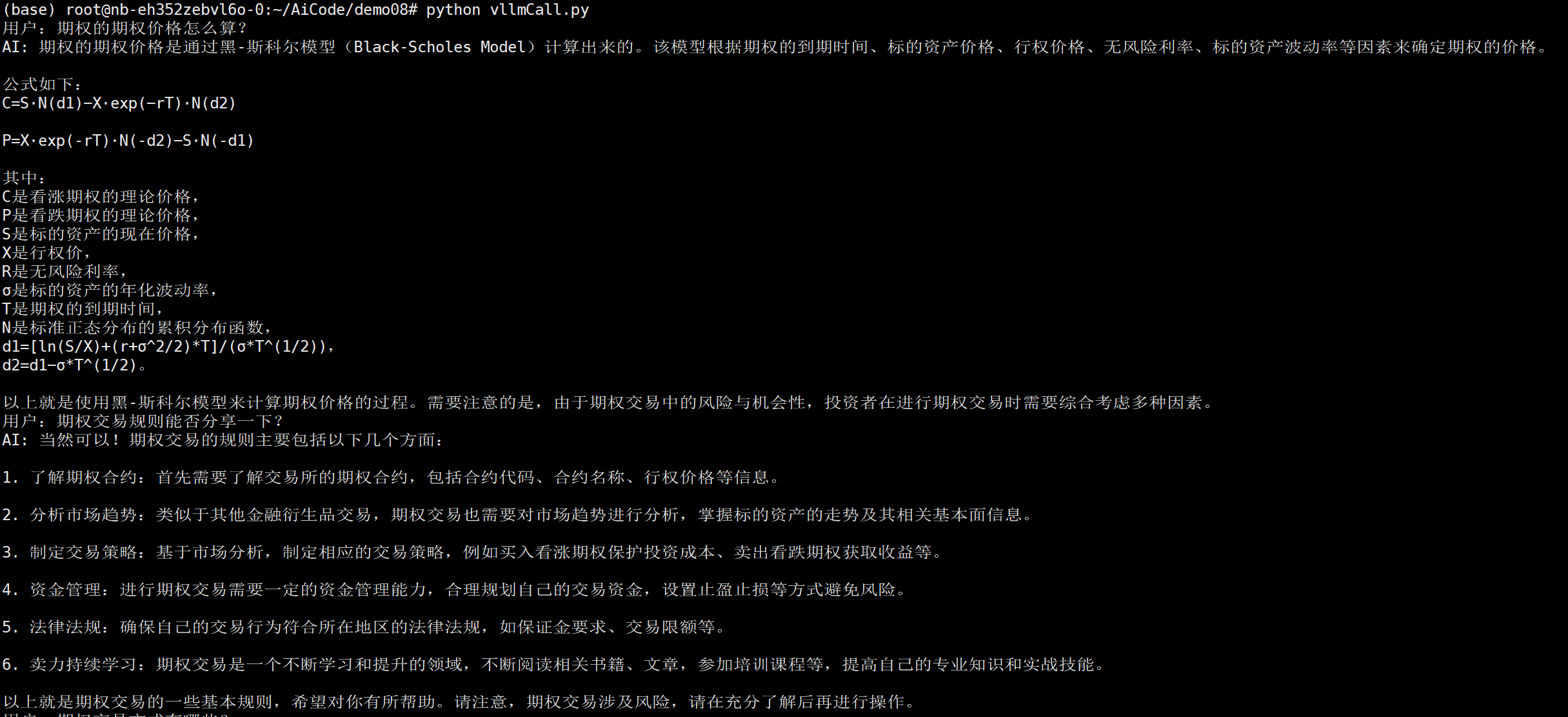

这里发现vllm中的输出和在llamaFactory中使用vllm的引擎差距很大
一般来讲我们使用llamaFactory做微调训练,微调完了我们做chat测试的时候,引擎选择vllm。我们最终单独用vllm部署的这个效果,它一定是和我们在llamaFactory上面微调用vllm这个推理的效果一定是一样的。当然这里说的这个一样,不是说每句话每个字儿都一致的,而是他输出的这个内容的含义一定是一样的,如果这个玩意不一样,那么导致它不一样的原因一般就三个:
第一个原因就是我们的模型没合并。
第二个原因就在于对话模板出错了,大概率就在对话模板上面。
第三个原因第三个原因就是我们的base模型在合并的时候没选对。就是模型合并是正确的,但是base模型选错了。
这里我们出现的就是第二个原因。
11.对话模板
1.对话模板的问题
在上面的微调中发现用vllm服务推理和llamaFactory中用vllm引擎推理结果输出的内容差距很大,这是因为现在的大模型百花齐放,各家公司都有自己的大模型,但是这个大模型的这个提示词就是这个对话模板,它目前没有一套统一的标准。所以导致,不同的大语言模型,他们的这个对话模板是有区别的,是不一样的,而且这个对话模板实际上是不能够进行统一的,不能够去统一,因为不同的模型它的架构是有区别的。
对话模板它会直接影响到我们模型训练时候的那个数据集的格式,所以我们的数据集最终其实在进行训练的时候,它一定是按照人家的这套对话模板来进行转换封装的。
所以很大可能 大模型推理框架vllm是一个对话模板,大模型微调框架llamaFactory是一个对话模板,大模型部署的前端框架openWebui又会有一个模板导致使用llamaFactory微调出的模型在每个上面都不一样。
千问的对话模板:
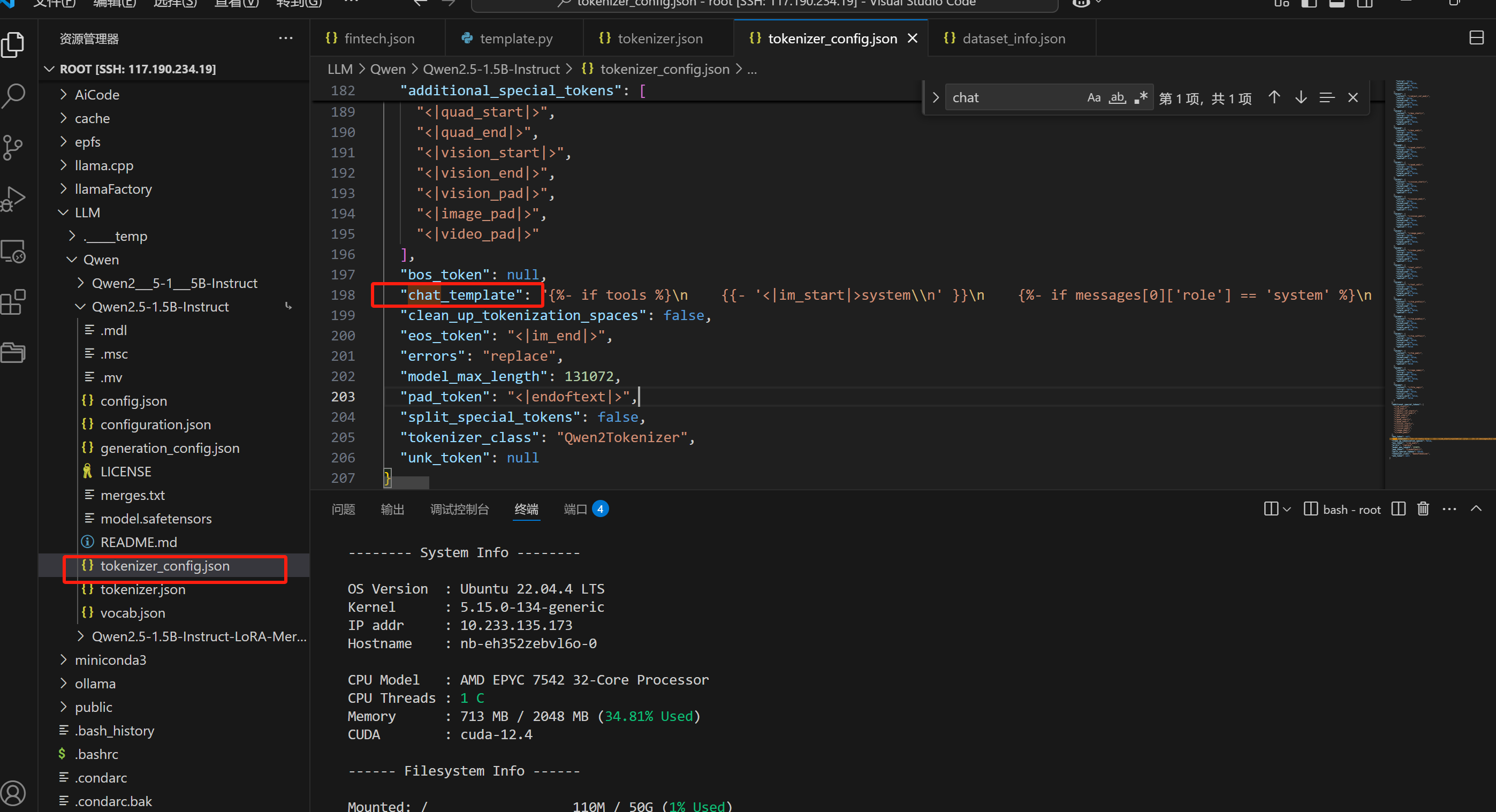
llamaFactory的对话模板:
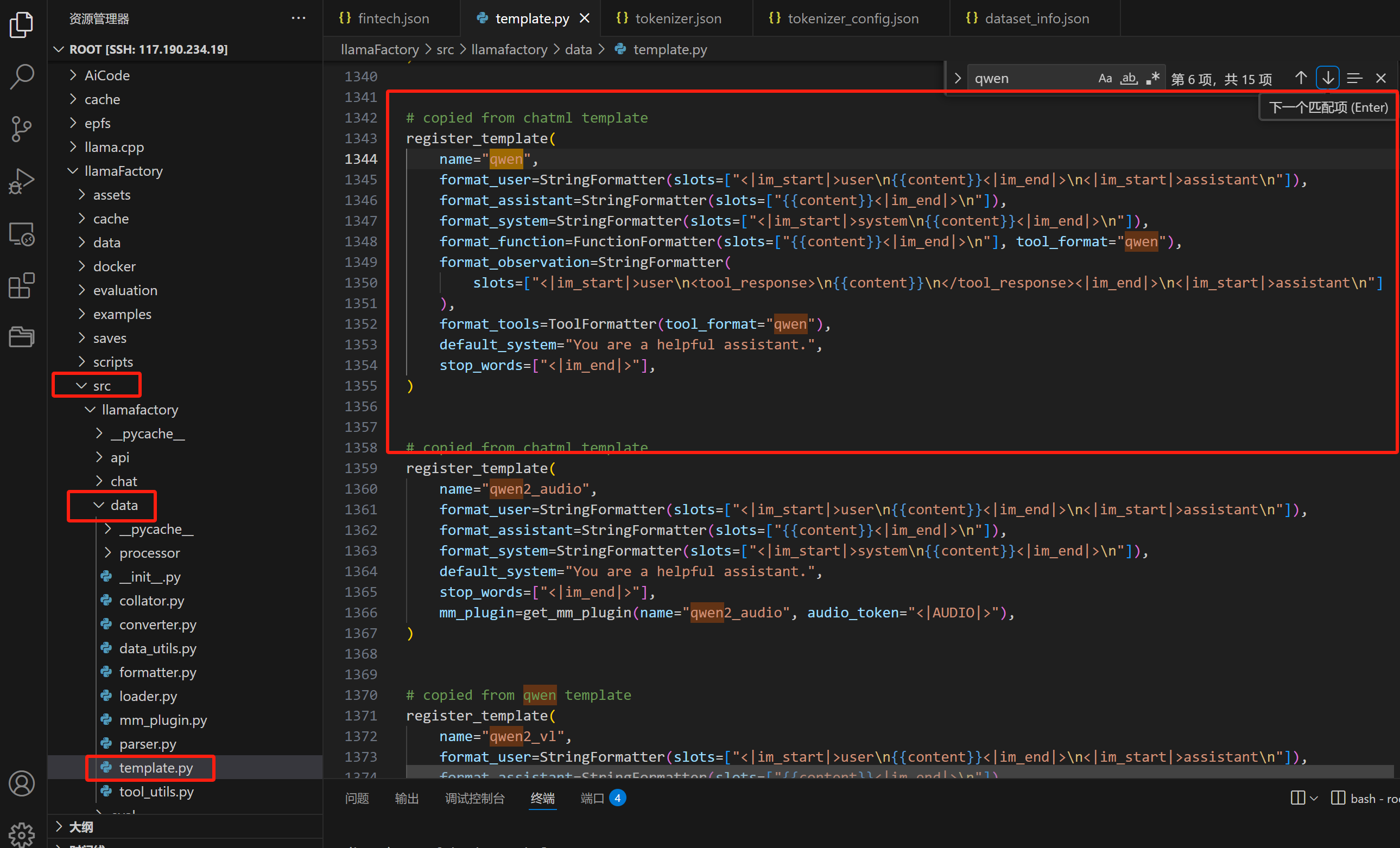
llamaFactory中并没有单独区分千问不同版本的对话模板,但是千问的模型本身每个版本有自己的对话模板,vllm他用的是模型自己的对话模板在tonkenizer.config里面,这就很麻烦,导致llamaFactory训练后用chat测试效果与预期一致,放到vllm上又不一样了。
2.vLLM的对话模板
vllm默认使用模型自己配置在tonkenizer.config的对话模板,也支持在启动服务时自己指定对话模板,对话木本是一个jinja2的文件
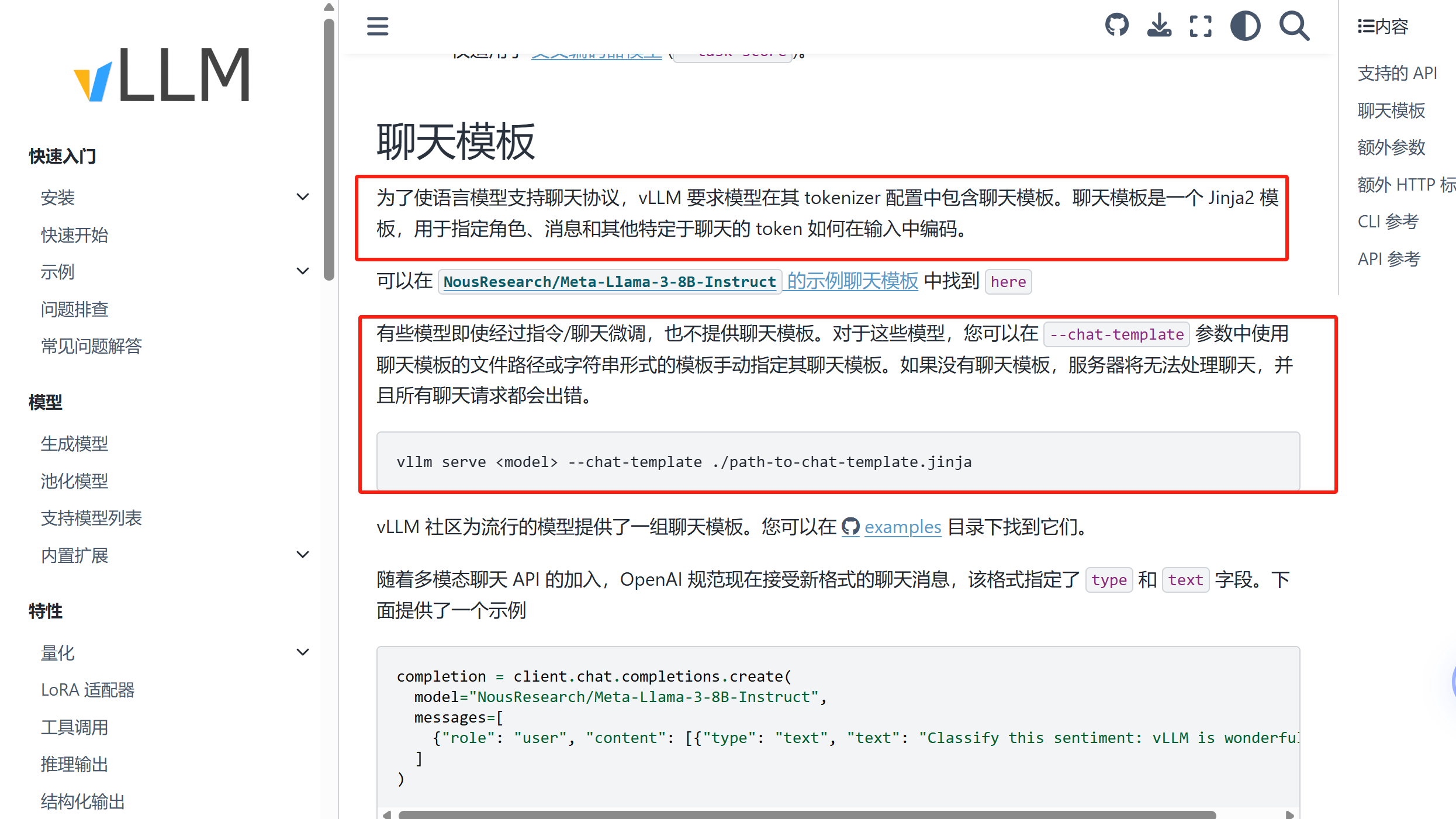
jinja2:它是一种解释性标签语言,一个python的数据框架,模板引擎,可以把它简单理解为它是一个类似于前端开发的HTML的那种标签的格式,也是一个单独的编程框架语言,它有自己的API接口,有自己的语法。
现阶段的大模型的框架中大多数的在进行聊天模板推理的时候,用的都是jinja2的格式,当然了,有少部分的模型框架用的是Jason字符串,jinja2它的功能要更加强大一些因为里面可以写逻辑判断。
vllm 文档地址 :https://docs.vllm.com.cn/
jinja2文档地址:https://docs.jinkan.org/docs/jinja2/
上面的:vllm serve --chat-template ./path-to-chat-template.jinja 这种方法在OpenWebUI中是无效的,因为OpenWebUI在每次进行数据传输访问的时候,它会自己传一个模板,覆盖掉我们的这个serve的模板。

3.对话模板对齐
llamaFactory是用来改变和调整模型的,所以推理框架的结果一定要以我们训练的结果为依据,而不是以模型原有官方的这个结果为依据,所以需要将推理框架与llamaFactory的对话模板进行对齐。
在llamaFactory的template.py里面,有一个受保护的方法,不推荐外部直接调用,叫做_get_jinja_template的方法他定义在class Template中,这个方法不在外面调用,官方会更新框架的版本一旦更新调用会跟着报错还是需要再改,我们可以清晰的看到,这个函数就是定义了把模型的参数传进来,它会直接把这个模型所对应的那个提示词模板转换成jinja2的格式,并且给我们返回这个格式文件,官方没有直接给我们提供API调用,想要对齐对话模板就得我们自己从这个源码里面往外拉。
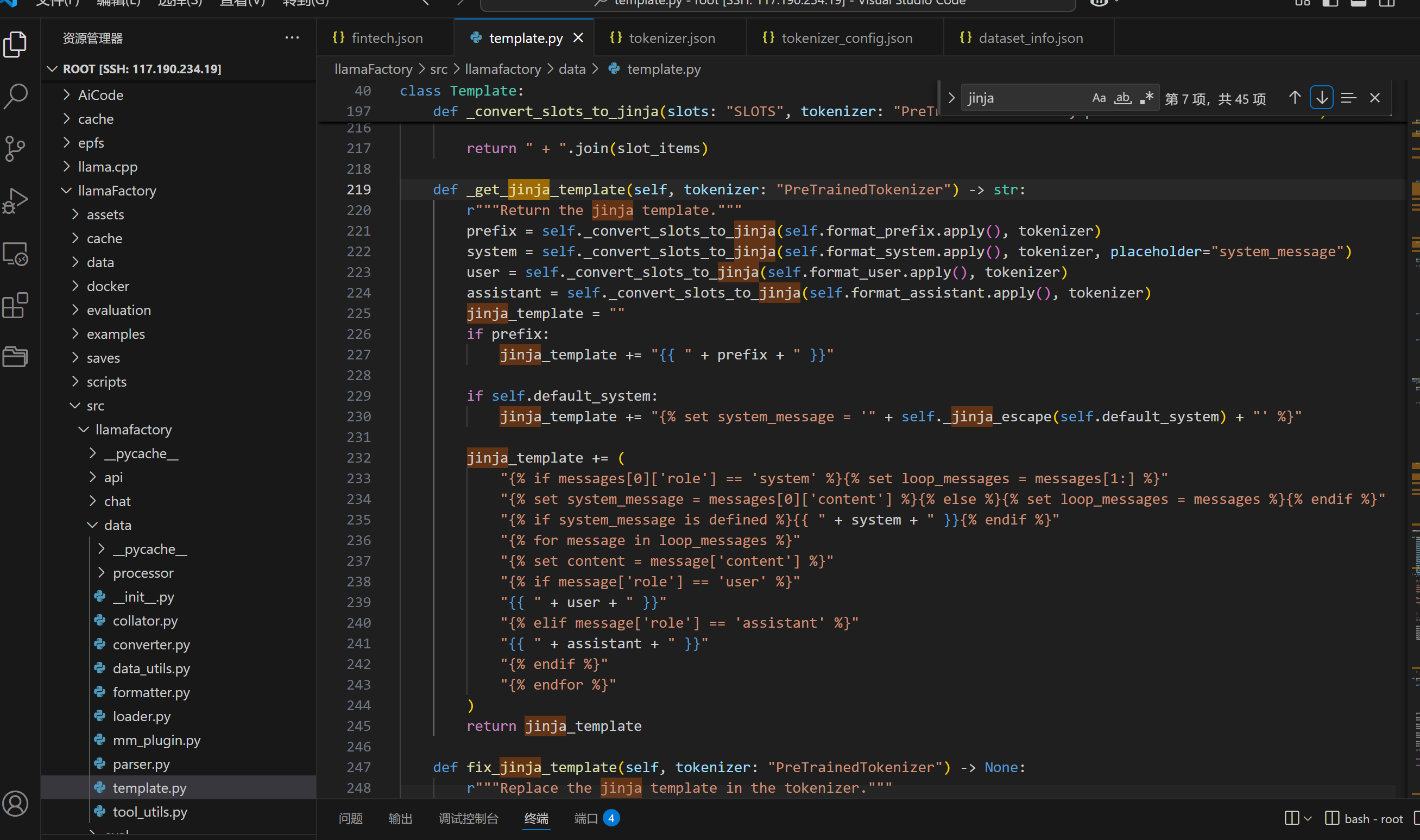
我们没法调用上面的_get_jinja_template,可以调用下面的fix_jinja_template,他的作用是拿到当前传的这个模型的tonkenizer.config中chat_template,这段对话模板后他把这个对话模板通过_get_jinja_template函数,json的对话模板给转换成jinja格式的了
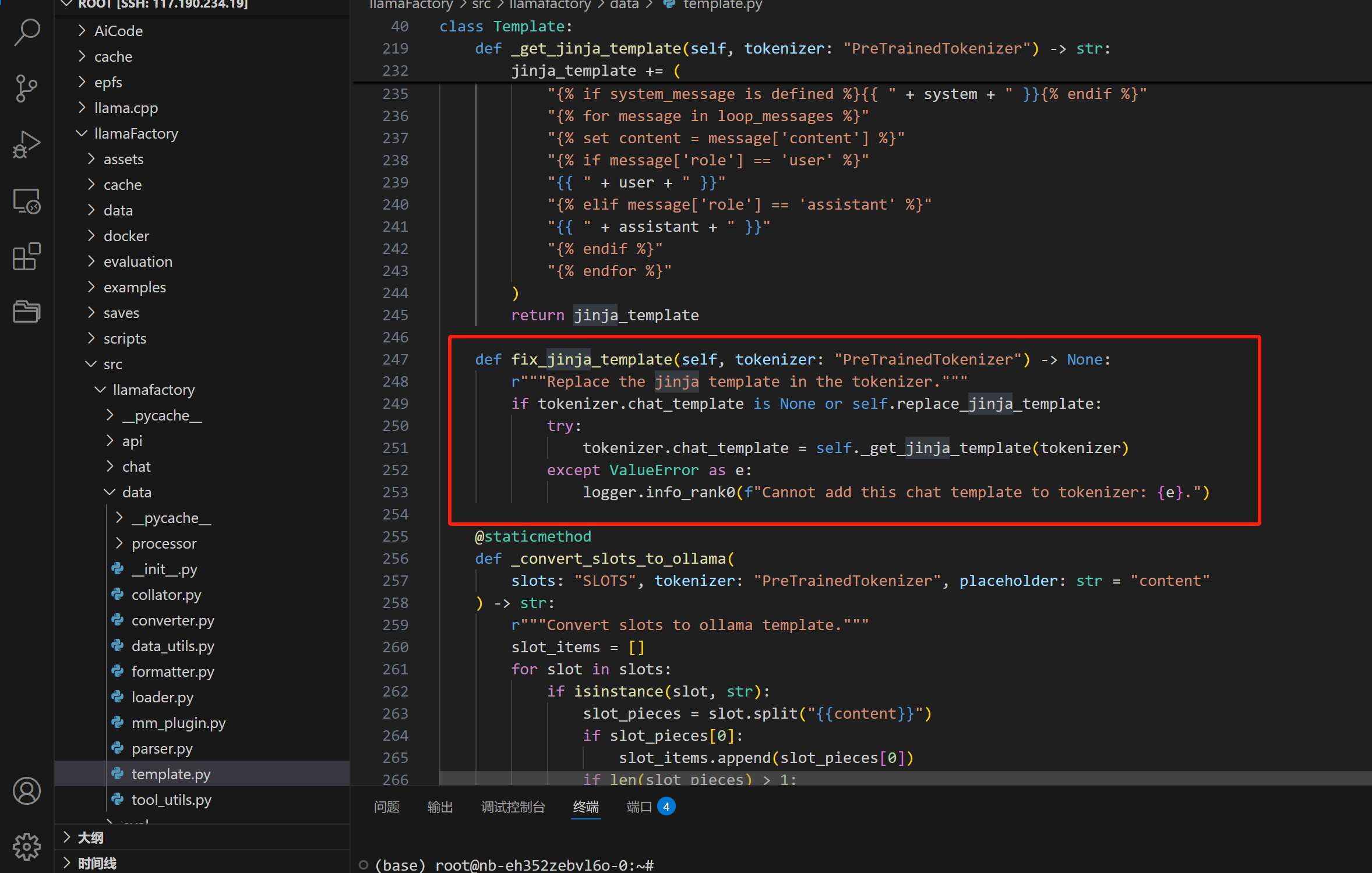
将下面的代码放在template.py的同级目录下
# mytest.py
import sys
import os
from llamafactory.data.template import TEMPLATES
from transformers import AutoTokenizer
# 将项目根目录添加到 Python 路径
root_dir = os.path.dirname(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))))
sys.path.append(root_dir)
# 1. 初始化分词器(任意支持的分词器均可)这里只为了获取一个tokenizer的对象,随便放一个就行
tokenizer = AutoTokenizer.from_pretrained("/root/autodl-tmp/llm/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B")
# 2. 获取模板对象
template_name = "qwen" # 替换为你需要查看的模板名称(llamaFactory界面上的对话模板的名称)
template = TEMPLATES[template_name] #调用template.py中定义的TEMPLATES类
# 3. 修复分词器的 Jinja 模板
template.fix_jinja_template(tokenizer)
# 4. 输出并保存 Jinja 文件
output_path = "/root/vllmQwen.jinja"
with open(output_path, "w", encoding="utf-8") as f:
f.write(tokenizer.chat_template) # 直接写入模板内容
# 5. 直接输出模板的 Jinja 格式
print("=" * 40)
print(f"Template [{template_name}] 的 Jinja 格式:")
print("=" * 40)
print(tokenizer.chat_template)
print("\nJinja 模板已保存至:", output_path)
启动vllm服务的时候:
vllm serve /root/LLM/Qwen/Qwen2.5-1.5B-Instruct-LoRA-Merged --chat-template /root/vllmQwen.jinja
4.lmdeploy的对话模板
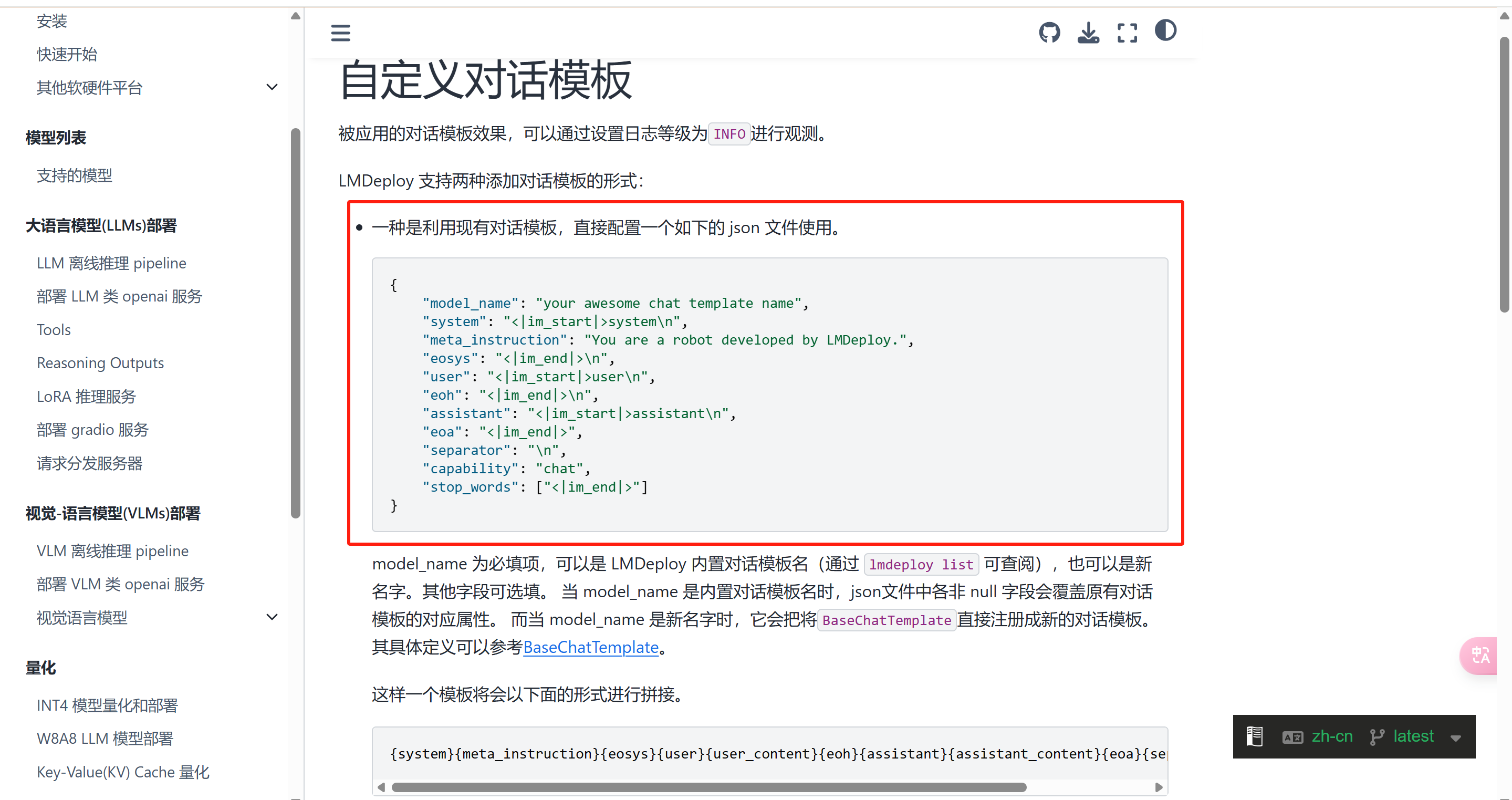

转换后json的千问对话模板:
{
"model_name": "qwen",
"system": "<|im_start|>system\n",
"meta_instruction": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant.",
"eosys": "<|im_end|>\n",
"user": "<|im_start|>user\n",
"eoh": "<|im_end|>\n",
"assistant": "<|im_start|>assistant\n",
"eoa": "<|im_end|>",
"separator": "\n",
"capability": "chat",
"stop_words": ["<|im_end|>", "<|im_start|>", "<|im_end|>"],
"tool_spec": {
"tool_begin": "<tools>",
"tool_end": "</tools>",
"tool_call_begin": "<tool_call>",
"tool_call_end": "</tool_call>",
"tool_response_begin": "<tool_response>",
"tool_response_end": "</tool_response>"
}
}
12.GGUF
1.什么是GGUF
GGUF格式的全名为(GPT-Generated Unified Format),是由Hugging Face团队推出的一种用于存储和部署机器学习模型的文件格式,提到GGUF就不得不提到它的前身GGML (GPT-Generated ModelLanguage)。GGML是专门为了机器学习设计的张量库,最早可以追溯到2022/10。其目的是为了有一个单文件共享的格式,并且易于在不同架构的GPU和CPU上进行推理。但在后续的开发中,遇到了灵活性不足、相容性及难以维护的问题,所以GGUF取代了早期的GGML格式。它的核心目标是提升模型的灵活性、可扩展性和跨平台兼容性,尤其适配大语言模型(如Llama系列)及其他生成式AI模型的推理需求。
2.为什么要转换 GGUF 格式
在传统的 Deep Learning Model开发中大多使用 PyTorch 来进行开发,但因为在部署时会面临相依 Lirbrary 太多、版本管理的问题于才有了 GGML、GGMF、GGIT等格式,而在开源社群不停的选代后 GGUF 就诞生了。
GGUF 实际上是基于 GGJT 的格式进行优化的,并解决了 GGML当初面临的问题,包括:
- 1.可扩展性:轻松为 GGML架构下的工具添加新功能,ǐ或者向 GGUF 模型添加新 Feature,不会破坏与现有模型的兼容性(模型的模型打完包之后,你是可以更改它的模型结构的,他支持扩展并且这种扩展不会破坏与现有模型的兼容性)。
- 2.对 mmap(内存映射)的兼容性:该模型可以使用 mmap 进行加载(原理解析可见参考),实现快速载入和存储。(从 GGIT 开始导入,可参考 GitHub)
- 3.易于使用:模型可以使用少量代码轻松加载和存储,无需依赖的 Librany,同时对于不同编程语言支持程度也高(跨平台移植非常强)
- 4.模型信息完整:加载模型所需的所有信息都包含在模型文件中,不需要额外编写设置文件(不像我们的这种传统的HuggingFace模型一个文件后面有一大堆配置文件,只要有一个配置文件出问题了,这个模型就挂了这个模型就挂了)。
- 5.有利于模型量化:GGUF 支持模型量化(4 位、8位、F16),在 GPU 变得越来越昂贵的情况下,节省 vRAM 成本也非常重要。(现在模型很多是F16,意思是也可以不量化直接变成GGUF格式)
3.使用llama.cpp转换模型为GGUF格式
1.创建并激活llama.cpp的环境
conda create -n llamaCpp python==3.10 -y
source activate llamaCpp
2.获取llama.cpp仓库
llama.cpp的原有地址为: https://github.com/ggerganov/llama.cpp.git
需要进行学术加速,学术加速的地址: https://gh-proxy.com/
加速后地址 https://gh-proxy.com/github.com/ggerganov/llama.cpp.git
执行:**git clone **https://gh-proxy.com/github.com/ggerganov/llama.cpp.git
这个没有版本依赖,可以不用创建虚拟环境直接装即可
3.安装llama.cpp运行环境依赖包
pip install -r /root/llama.cpp/requirements.txt
4.执行转换
我们一般来讲都是把模型合并成HuggingFace之后再转的,所以一般都用的是这convert_hf_to.gguf.py。
他这个框架支持只转lora,只转lora的话,意思就是说你模型没合并,你可以直接把lora文件,就那个权重100的那个东西给他转了。但是这个玩意儿转出来单独拿出来其实没什么作用,他得用那种可以专门套这个框架去推理它。所以我们一般用的是convert_hf_to.gguf.py,把模型合并成一个完整的huggingFace模型,再给它转成GGUF。
如果不量化,保留模型的效果
python convert_hf_to_gguf.py /root/LLM/Qwen/Qwen2.5-1.5B-Instruct-LoRA-Merged –outtype f16 –verbose –outfile /root/ollama/Qwen2.5-1.5B-Instruct-LoRA-Merged-gguf.gguf
如果需要量化(加速并有损效果),直接执行下面脚本就可以 ,它速度会更快,文件会更小。但是它的精度就没有那么高了
python convert_hf_to_gguf.py /root/LLM/Qwen/Qwen2.5-1.5B-Instruct-LoRA-Merged –outtype q8_0 –verbose –outfile /root/ollama/Qwen2.5-1.5B-Instruct-LoRA-Merged-gguf_q8_0.gguf
这里–outtype是输出类型,代表含义:
q2_k:特定张量(Tensor)采用较高的精度设置,而其他的则保持基础级别。
q3_k_l、q3_k_m、q3_k_s:这些变体在不同张量上使用不同级别的精度,从而达到性能和效率的平衡。 q4_0:这是最初的量化方案,使用4位精度。
q4_l和q4_k_m、q4_k_s:这些提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景,最大的模型是q4_l最小的模型是q4_k_s,就是说看你是更偏向于这个精度高一点,还是性能高一点,但是这个没什么实用性,因为拿到量化上面来讲,既然都已经做了量化了,就不分大尺寸和小尺寸。一般就只是量化和不量化,量化就是八位或者是四位。
q5_0、q5_1、q5_k_m、q5_k_s:这些版本在保证更高准确度的同时,会使用更多的资源并且推理速度较 慢。
q6_k和q8_0:这些提供了最高的精度,但是因为高资源消耗和慢速度,可能不适合所有用户,一般选择q8_0他的精度最高,消耗的资源也高推理速度会慢一些,如果显卡比较弱就不推荐使用这个。
fp16和f32: FP16和F32 是不量化,保留原始精度的。具体选择是FP16还是F32,得看你的模型。因为现在大多数的这个大模型的类型都是FP16,F32也是不量化的32位的模型,但是现在32位的模型很少了。
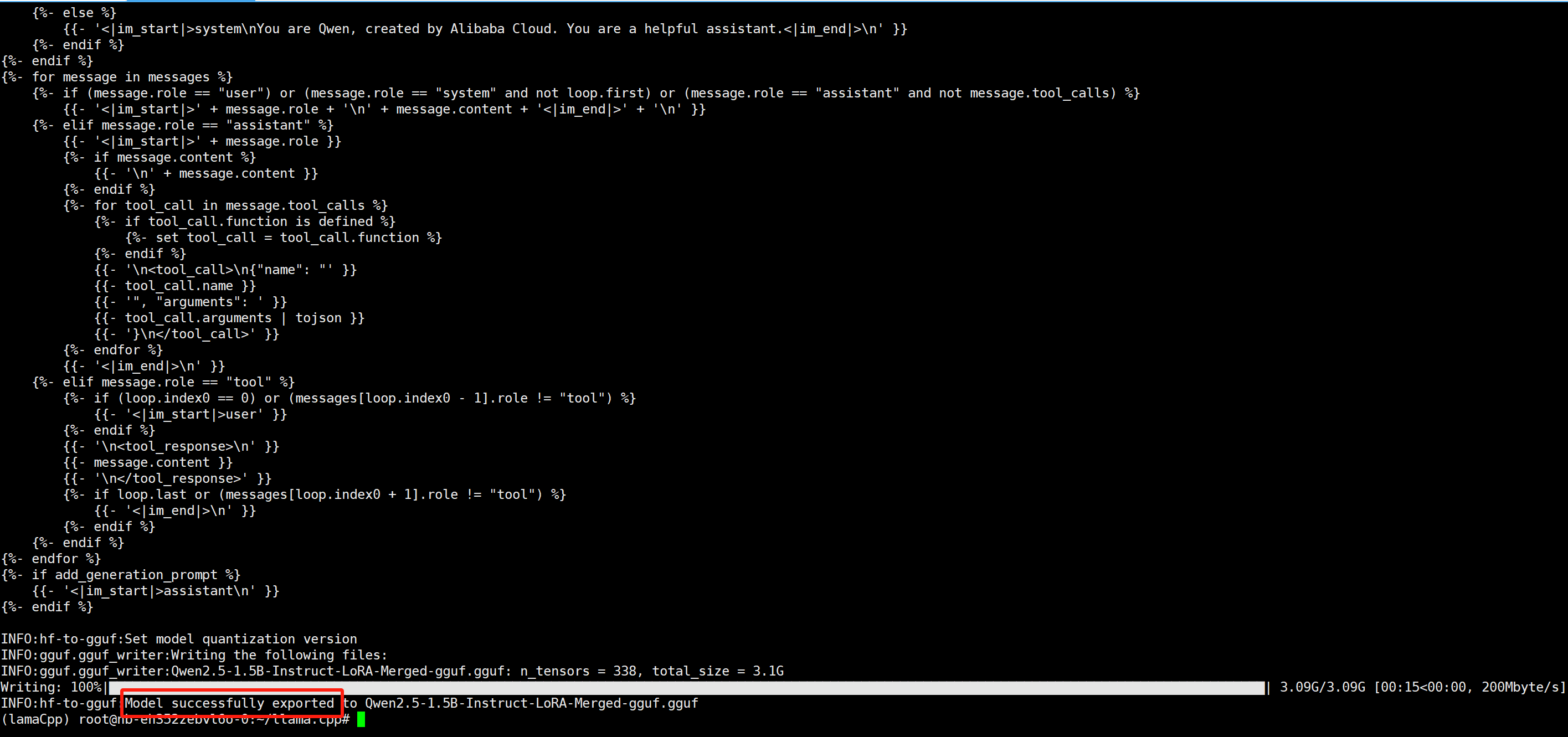
转换的结果:
5.使用Ollama运行GGUF
1.启动Ollama服务
ollama serve
2.创建ModelFile
GGUF格式文件路径:
FROM /root/LLM/Qwen/Qwen2.5-1.5B-Instruct-LoRA-Merged-gguf.gguf

3.创建自定义模型
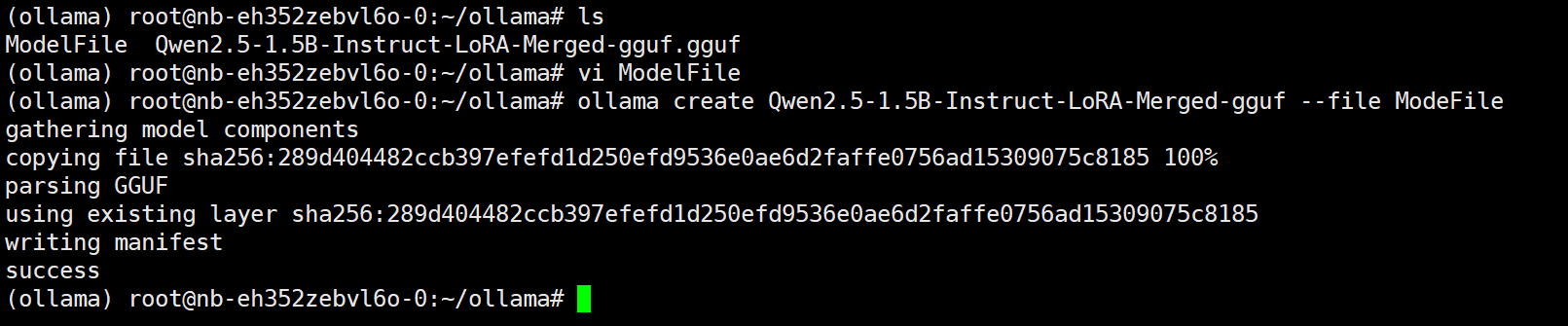
使用ollama create命令创建自定义模型
gguf文件和ModelFile 得在同一个目录下才行
ollama create Qwen2.5-1.5B-Instruct-LoRA-Merged-gguf –file ModeFile
ollama list 查看ollama加载到本地的模型列表

4.运行模型
ollama run Qwen2.5-1.5B-Instruct-LoRA-Merged-gguf

可通过ctrl+D 退出聊天窗口

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 20
20 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)