

今日论文推荐:MAPS、RoboFactory、OpenVLThinker等
由 AIRI 和 MIPT 等机构提出的这项工作,聚焦于视觉编码器生成的大量视觉 token 如何在保持高质量表征的同时减少计算成本。他们提出了一种自适应 token 削减方法,通过结合自编码器和 G


作者:InternLM、Qwen 等 LLM每日一览热门论文版,顶会投稿选题不迷惘。快来看看由「机智流」和「ModelScope」社区推荐的今日论文吧。
When Less is Enough: Adaptive Token Reduction for Efficient Image Representation
论文链接:
https://modelscope.cn/papers/2503.16660
简要介绍:
由 AIRI 和 MIPT 等机构提出的这项工作,聚焦于视觉编码器生成的大量视觉 token 如何在保持高质量表征的同时减少计算成本。他们提出了一种自适应 token 削减方法,通过结合自编码器和 Gumbel-Softmax 选择机制,筛选出最具信息量的 token。实验表明,在 OCR 任务中可削减超 50% 的视觉上下文而不损失性能,为高效多模态推理开辟了新方向。
核心图片:


MAPS: A Multi-Agent Framework Based on Big Seven Personality and Socratic Guidance for Multimodal Scientific Problem Solving
论文链接:
https://modelscope.cn/papers/2503.16905
简要介绍:
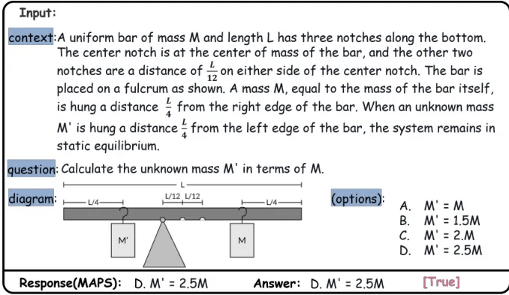
来自西安交通大学、新加坡国立大学等机构的团队推出了 MAPS 框架,基于“大七人格理论”和苏格拉底引导法,解决多模态科学问题(MSPs)。通过七个功能独特的代理和四阶段解题策略,外加“批判者”代理的反思机制,该方法在 EMMA、Olympiad 等数据集上超越 SOTA 模型 15.84%,展现了强大的跨模态推理能力。
核心图片:
MARS: A Multi-Agent Framework Incorporating Socratic Guidance for Automated Prompt Optimization
论文链接:
https://modelscope.cn/papers/2503.16874
简要介绍:
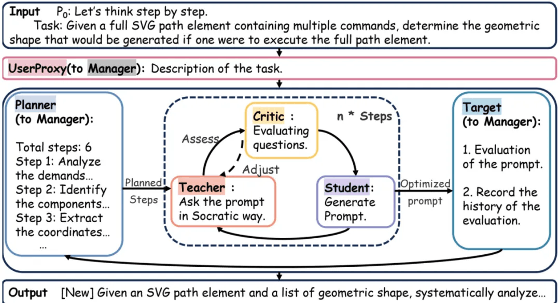
由西安交通大学、南洋理工大学等团队打造的 MARS 框架,针对自动提示优化(APO)的灵活性和搜索效率问题,提出了多代理融合技术。通过七个代理协作和“教师-批判者-学生”的苏格拉底对话模式,逐步优化提示,在多个数据集上验证了其高效性和可解释性。
核心图片:

RoboFactory: Exploring Embodied Agent Collaboration with Compositional Constraints
论文链接:
https://modelscope.cn/papers/2503.16408
简要介绍:
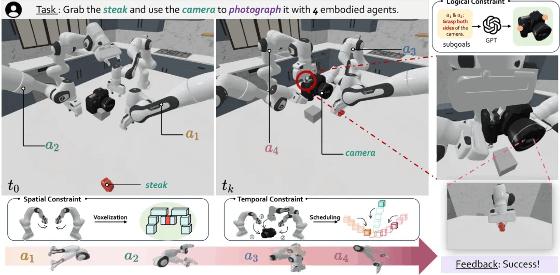
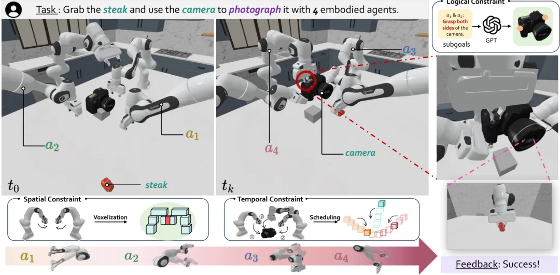
香港中文大学(深圳)、上海人工智能实验室等机构提出了 RoboFactory,探索多代理协作中的具身智能。通过引入“组合约束”(逻辑、空间、时间),设计了自动数据收集框架并推出首个多代理操作基准。基于模仿学习的测试表明,该方法在安全性与效率上表现优异。
核心图片:
Bridging Continuous and Discrete Tokens for Autoregressive Visual Generation
论文链接:
https://modelscope.cn/papers/2503.16430
简要介绍:
香港大学、字节跳动等团队提出了 TokenBridge,解决自回归视觉生成中离散与连续 token 的两难问题。通过训练后量化和维度级预测策略,该方法保留了连续 token 的表征能力,同时保持离散 token 的建模简洁性,在 ImageNet 上实现了高质量生成。
核心图片:


OpenVLThinker: An Early Exploration to Complex Vision-Language Reasoning via Iterative Self-Improvement
论文链接:
https://modelscope.cn/papers/2503.17352
简要介绍:
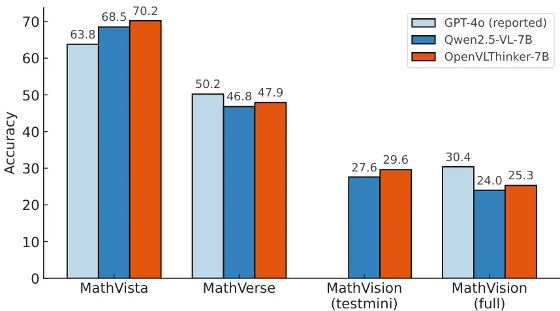
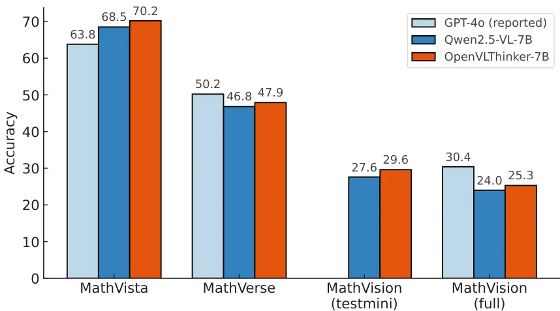
加州大学洛杉矶分校团队推出了 OpenVLThinker,通过迭代自改进增强大型视觉-语言模型的复杂推理能力。结合监督微调和强化学习,该模型在 MathVista 等基准上表现持续提升,展示了从文本到多模态推理的潜力。
核心图片:
Modifying Large Language Model Post-Training for Diverse Creative Writing
论文链接:
https://modelscope.cn/papers/2503.17126
简要介绍:
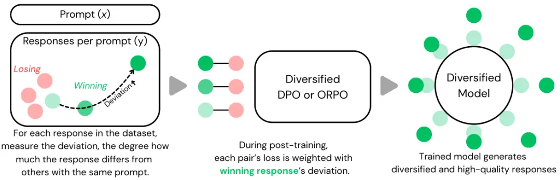
Midjourney 和纽约大学团队研究了如何在后训练中提升 LLM 的创意写作多样性。他们通过引入“偏差”到训练目标(如 DPO 和 ORPO),在保持高质量输出的同时显著提升多样性,最佳模型媲美 GPT-4o 和 DeepSeek-R1。
核心图片:

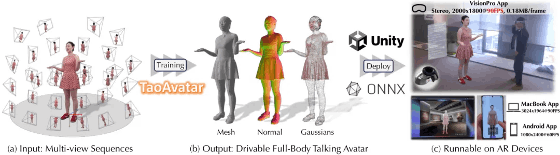
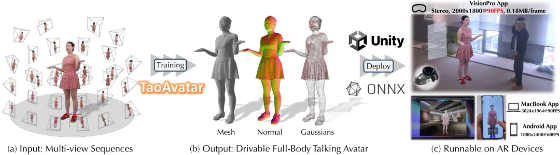
TaoAvatar: Real-Time Lifelike Full-Body Talking Avatars for Augmented Reality via 3D Gaussian Splatting
论文链接:
https://modelscope.cn/papers/2503.17032
简要介绍:
阿里巴巴团队提出了 TaoAvatar,利用 3D 高斯 splatting 技术打造实时全息说话头像。通过轻量化 MLP 网络和混合形状补偿,该方法在 AR 设备上实现 90 FPS 的高质量渲染,适用于电商直播等场景。
核心图片:
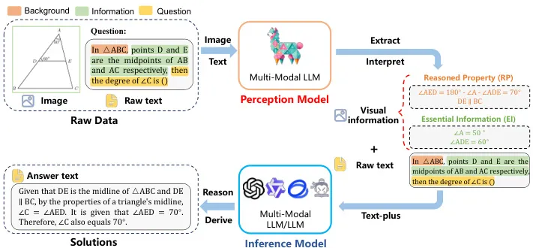
MathFlow: Enhancing the Perceptual Flow of MLLMs for Visual Mathematical Problems
论文链接:
https://modelscope.cn/papers/2503.16549
简要介绍:
浙江大学、清华大学等团队推出了 MathFlow,针对多模态 LLM 在视觉数学问题中的感知瓶颈,提出了解耦感知与推理的管道。训练的 MathFlow-P-7B 模型显著提升了信息提取能力,与多种推理模型兼容表现出色。
核心图片:

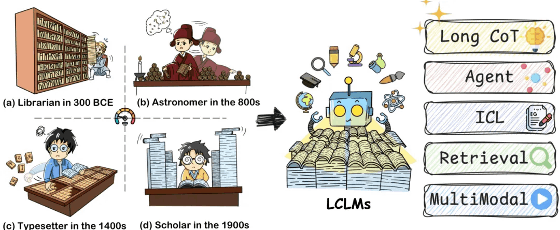
A Comprehensive Survey on Long Context Language Modeling
论文链接:
https://modelscope.cn/papers/2503.17407
简要介绍:
南京大学、北京大学等机构联合撰写的综述,全面回顾了长上下文语言模型(LCLMs)的最新进展。从数据策略到架构设计,再到训练部署与评估,为研究者和工程师提供了宝贵资源。
核心图片:

今天的论文盘点是不是让你脑洞大开?从高效 token 削减到多代理协作,再到实时 AR 头像,每篇研究都在推动 AI 的边界。别忘了点赞收藏,明天还有更多前沿技术等你探索!🚀✨
-- 完 --

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献565条内容
已为社区贡献565条内容

所有评论(0)