
论文推荐:多模态CoT综述、BlobCtrl、Being-0、DreamRenderer
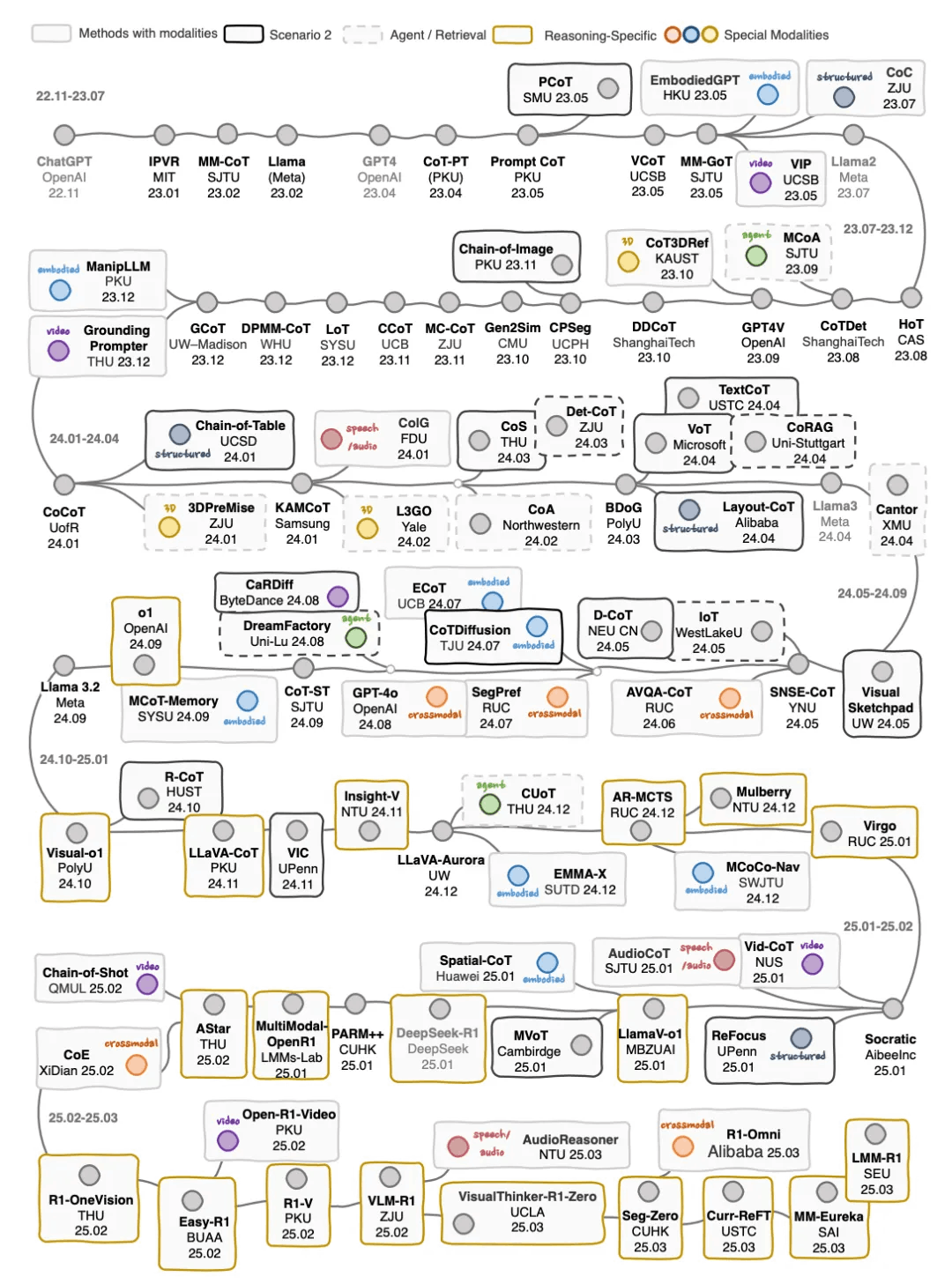
这篇调查论文是首个系统回顾多模态思维链(MCoT)推理的综述。论文阐明了相关基础概念和定义,提供了全面的分类法,并从不同角度对当前方法进行了深入分析。MCoT将思维链推理的优势扩展到多模态环境中,设计

作者:InternLM、Qwen 等 LLM每日一览热门论文版,顶会选题投稿不迷惘。快来看看由「机智流」和「ModelScope」社区推荐的论文吧!
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
论文链接:
https://modelscope.cn/papers/127180
简要介绍:这篇调查论文是首个系统回顾多模态思维链(MCoT)推理的综述。论文阐明了相关基础概念和定义,提供了全面的分类法,并从不同角度对当前方法进行了深入分析。MCoT将思维链推理的优势扩展到多模态环境中,设计了各种方法和创新推理范式来解决图像、视频、语音、音频、3D和结构化数据等不同模态的独特挑战,在机器人技术、医疗保健、自动驾驶和多模态生成等应用中取得了广泛成功。
核心图片:
DropletVideo: A Dataset and Approach to Explore Integral Spatio-Temporal Consistent Video Generation
论文链接:
https://modelscope.cn/papers/124784
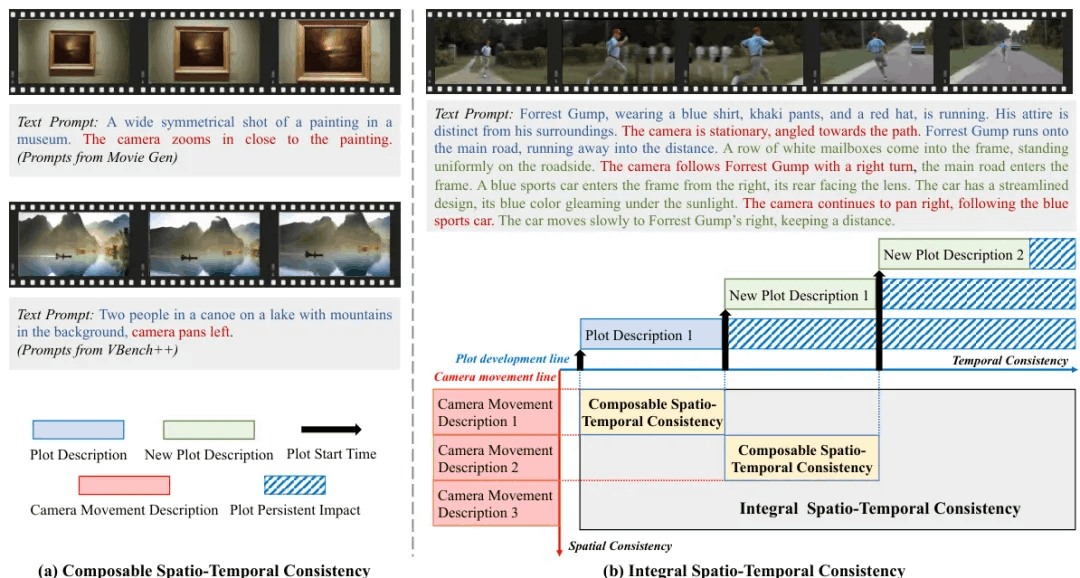
简要介绍:由北京科技大学等机构提出的DropletVideo研究了视频生成中的时空一致性问题。该工作构建了DropletVideo-10M数据集,包含1000万个具有动态相机运动和物体动作的视频,每个视频都配有详细的字幕描述相机运动和情节发展。基于此,他们开发了DropletVideo模型,该模型能在视频生成过程中保持出色的时空连贯性,尤其是在处理多个情节和相机移动的复杂场景时表现优异。
核心图片:
Being-0: A Humanoid Robotic Agent with Vision-Language Models and Modular Skills
论文链接:
https://modelscope.cn/papers/127565
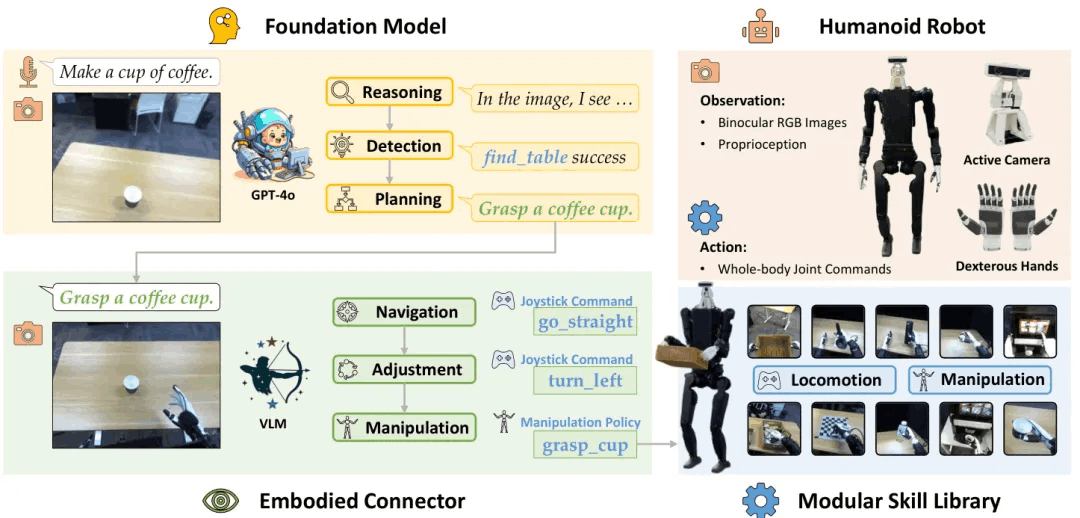
简要介绍:Being-0是一个层次化代理框架,集成了基础模型和模块化技能库。该工作提出了一个新颖的"连接器"模块,由轻量级视觉语言模型驱动,负责将语言计划转化为可执行的技能命令并协调运动和操作以提高任务成功率。实验表明,Being-0在解决需要挑战性导航和操作子任务的复杂长期任务方面取得了显著效果,平均完成率达到84.4%。
核心图片:
DreamRenderer: Taming Multi-Instance Attribute Control in Large-Scale Text-to-Image Models
论文链接:
https://huggingface.co/papers/2503.12885
简要介绍:DreamRenderer是一个基于FLUX模型的无训练方法,允许用户通过边界框或蒙版控制每个实例的内容,同时确保整体视觉和谐。该工作提出了两个关键创新:1)桥接图像标记用于硬文本属性绑定,确保T5文本嵌入在联合注意力过程中绑定正确的视觉属性;2)仅在关键层应用硬图像属性绑定,从而实现精确控制同时保持图像质量。
核心图片:

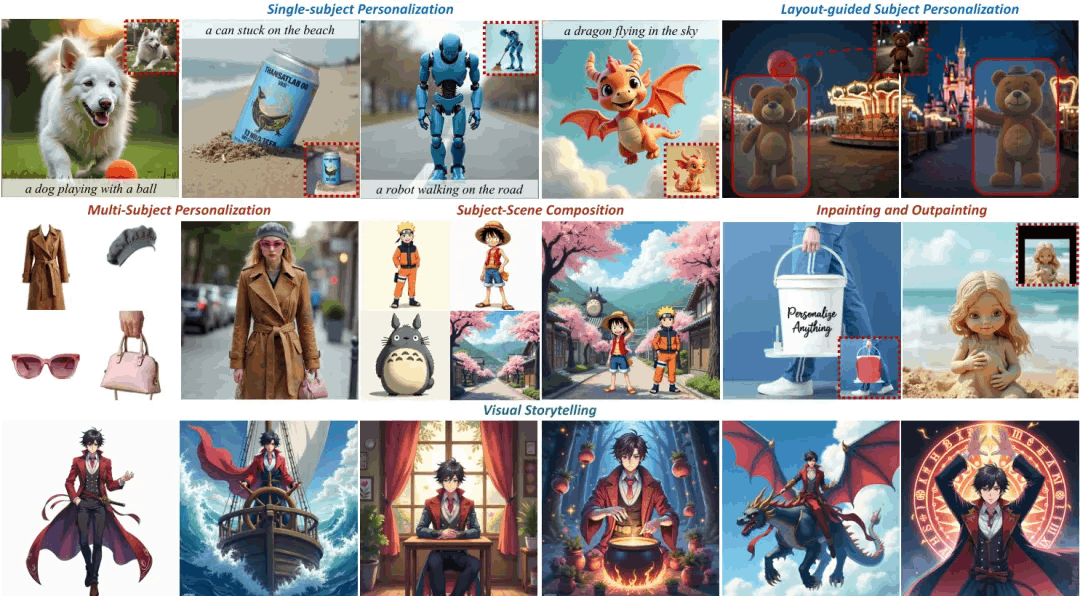
Personalize Anything for Free with Diffusion Transformer
论文链接:
https://modelscope.cn/papers/127774
简要介绍:该研究发现了扩散变换器(DiT)中未开发的潜力,仅通过将降噪标记替换为参考主体的标记就能实现零样本主体重建。基于此观察,研究提出了"Personalize Anything"框架,通过时间步适应性标记替换和补丁扰动策略实现DiT中的个性化图像生成。该方法无需任务训练,即可支持布局引导生成、多主体个性化和蒙版控制编辑等多种场景。
核心图片:
Edit Transfer: Learning Image Editing via Vision In-Context Relations
论文链接:
https://modelscope.cn/papers/127525
简要介绍:研究者提出了一种新的编辑设置"Edit Transfer",模型从单个源-目标示例中学习转换并将其应用到新的查询图像。受大型语言模型中上下文学习的启发,他们提出了一种视觉关系上下文学习范式,基于DiT文本到图像模型构建。通过将编辑示例和查询图像排列成统一的四面板复合图,然后应用轻量级LoRA微调来捕获复杂的空间转换。尽管仅使用42个训练样本,Edit Transfer仍在各种非刚性场景中显著优于最先进的文本图像编辑和参考图像编辑方法。
核心图片:

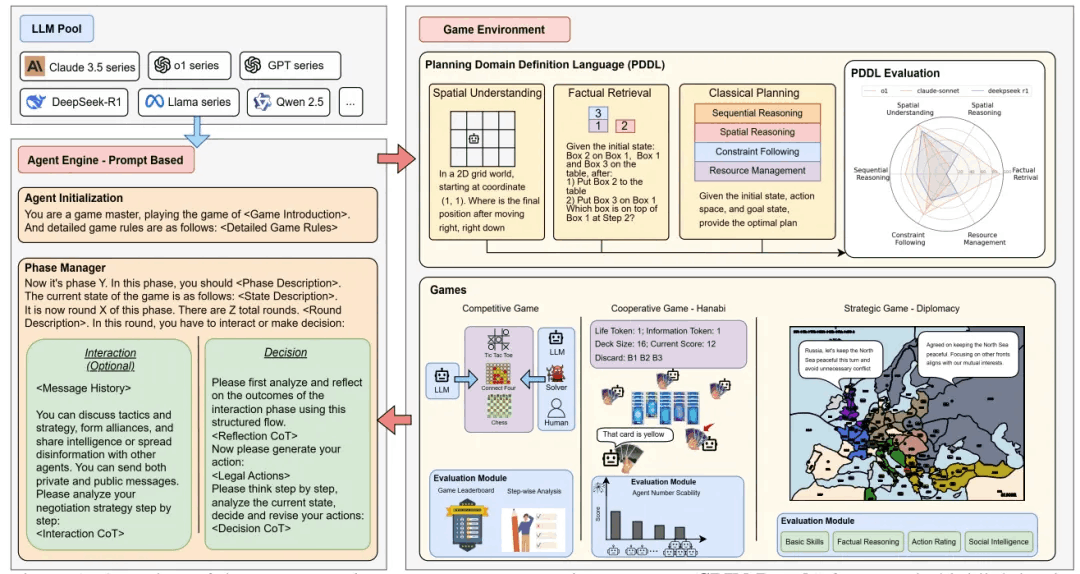
SPIN-Bench: How Well Do LLMs Plan Strategically and Reason Socially?
论文链接:
https://modelscope.cn/papers/127426
简要介绍:SPIN-Bench是一个新的多领域评估框架,专为测量战略规划和社会推理的智能水平而设计。该基准将经典PDDL任务、竞争性棋盘游戏、合作纸牌游戏和多代理协商场景结合在一个统一框架中,通过系统地变化行动空间、状态复杂性和交互代理数量来模拟各种社交环境。实验表明,尽管当代LLM在基本事实检索和短程规划方面表现合理,但在涉及深度多跳推理和社交协调的任务中遇到了显著的性能瓶颈。
核心图片:
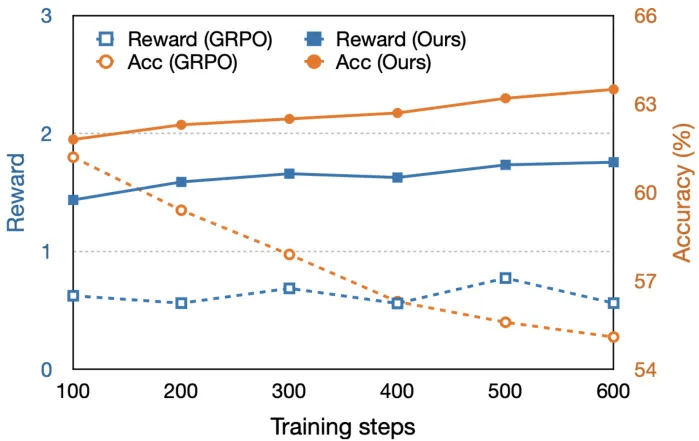
R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization(17票)
论文链接:
https://modelscope.cn/papers/127779
简要介绍:研究者设计了步骤组相对策略优化(StepGRPO),这是一个新的在线强化学习框架,通过简单、有效和密集的步骤奖励使MLLM自我改进推理能力。该方法引入了两种新的基于规则的推理奖励:步骤推理准确性奖励(StepRAR)和步骤推理有效性奖励(StepRVR)。StepRAR通过软关键步骤匹配技术奖励包含必要中间推理步骤的推理路径,而StepRVR通过推理完整性和逻辑评估策略奖励遵循结构良好且逻辑一致的推理过程。
核心图片:
BlobCtrl: A Unified and Flexible Framework for Element-level Image Generation and Editing(19票)
论文链接:
https://modelscope.cn/papers/127301
简要介绍:BlobCtrl是一个使用概率Blob表示统一元素级生成和编辑的框架。通过使用Blob作为视觉原语,该方法有效地解耦并表示空间位置、语义内容和身份信息,实现精确的元素级操作。主要贡献包括:1)具有分层特征融合的双分支扩散架构,实现前景-背景无缝集成;2)带有定制数据增强和评分函数的自监督训练范式;3)可控的dropout策略以平衡保真度和多样性。该方法在各种元素级操作任务中表现出色,同时保持计算效率。
核心图片:

WideRange4D: Enabling High-Quality 4D Reconstruction with Wide-Range Movements and Scenes(16票)
论文链接:
https://modelscope.cn/papers/127577
简要介绍:WideRange4D是一个新的4D重建基准,包含具有大空间变化的丰富4D场景数据,允许更全面地评估4D生成方法的能力。同时,研究者提出了一种新的4D重建方法Progress4D,该方法将4D重建过程分为两个阶段:高质量3D重建和4D动态渐进拟合。与现有4D重建方法相比,Progress4D可以更稳定地生成高质量的4D结果,特别是在处理具有宽范围空间移动的复杂4D场景时。
核心图片:

-- 完 --

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 2
2 0
0- 0



 已为社区贡献662条内容
已为社区贡献662条内容

所有评论(0)