
本周 AI Benchmark 方向论文推荐
由北京大学和微软亚洲研究院的魏李等人提出的 FEA-Bench,是一个专为评估大型语言模型(LLMs)在代码库级别进行增量开发能力的基准测试。它从 83 个 GitHub 仓库中收集了 1,401 个

作者:InternLM、Qwen 等 LLM每周一览 AI Benchmark,AI 发展方向不迷惘。快来看看「机智流」、「ModelScope」和「司南评测集社区」推荐的 AI BenchMark 相关论文吧!!!
FEA-Bench: A Benchmark for Evaluating Repository-Level Code Generation for Feature Implementation
论文链接:
https://modelscope.cn/papers/125249
简要介绍:
由北京大学和微软亚洲研究院的魏李等人提出的 FEA-Bench,是一个专为评估大型语言模型(LLMs)在代码库级别进行增量开发能力的基准测试。它从 83 个 GitHub 仓库中收集了 1,401 个任务实例,专注于新功能的实现。研究表明,即使是先进的 LLMs 在此任务中的表现仍远低于预期,揭示了仓库级代码开发的重大挑战。
核心图片:
WritingBench: A Comprehensive Benchmark for Generative Writing
论文链接:
https://modelscope.cn/papers/124147
简要介绍:
由阿里巴巴集团和中国人民大学的宁吴等人提出的 WritingBench,是一个全面评估 LLMs 生成写作能力的基准测试,覆盖 6 个核心写作领域和 100 个子领域。它引入了查询相关的动态评估框架,使模型能生成特定实例的评估标准。实验显示,7B 参数模型在数据策划能力上接近 SOTA 水平,验证了框架的高效性。
核心图片:

MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning
论文链接:
https://modelscope.cn/papers/124656
简要介绍:
由耶鲁大学的向如唐等人提出的 MedAgentsBench,是一个针对复杂医疗推理的基准测试,评估 LLMs 在多步骤临床推理、诊断和治疗规划中的表现。从七个医疗数据集构建了 862 个任务,结果显示 DeepSeek R1 和 OpenAI o3 等模型在复杂任务中表现突出,为医疗 AI 研究提供了新方向。
核心图片:
Do I look like a cat.n.01 to you? A Taxonomy Image Generation Benchmark
论文链接:
https://modelscope.cn/papers/126535
简要介绍:
由 Skoltech 和汉堡大学的维克多·莫斯科夫列茨基等人提出,该基准测试探索文本到图像模型生成分类学概念图像的可行性。包含 WordNet 概念的全面评估显示,Playground-v2 和 FLUX 在不同指标中表现优异,揭示了自动化结构化数据生成的新潜力。
核心图片:

VisualSimpleQA: A Benchmark for Decoupled Evaluation of Large Vision-Language Models in Fact-Seeking Question Answering
论文链接:
https://modelscope.cn/papers/125193
简要介绍:
由中国人民大学的 Yanling Wang 等人提出的 VisualSimpleQA,是一个多模态事实寻求 QA 基准测试,支持对大型视觉语言模型(LVLMs)的视觉与语言能力进行解耦评估。它引入难度标准并提取了 VisualSimpleQA-hard 子集,实验显示即使 GPT-4o 在复杂任务中正确率仅 30%+,凸显改进空间。
核心图片:

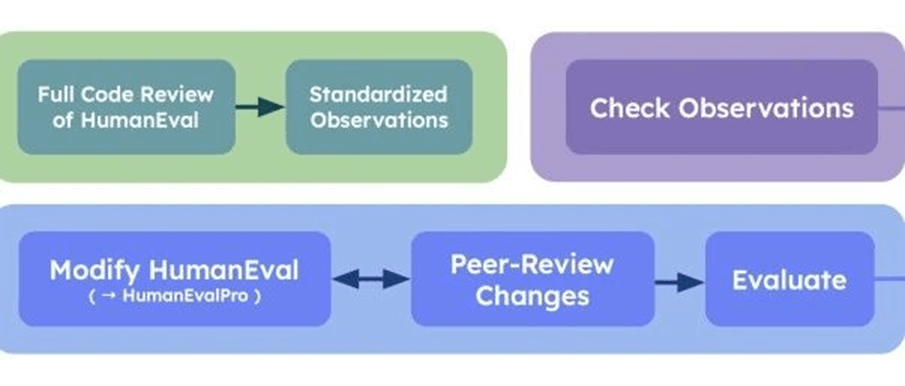
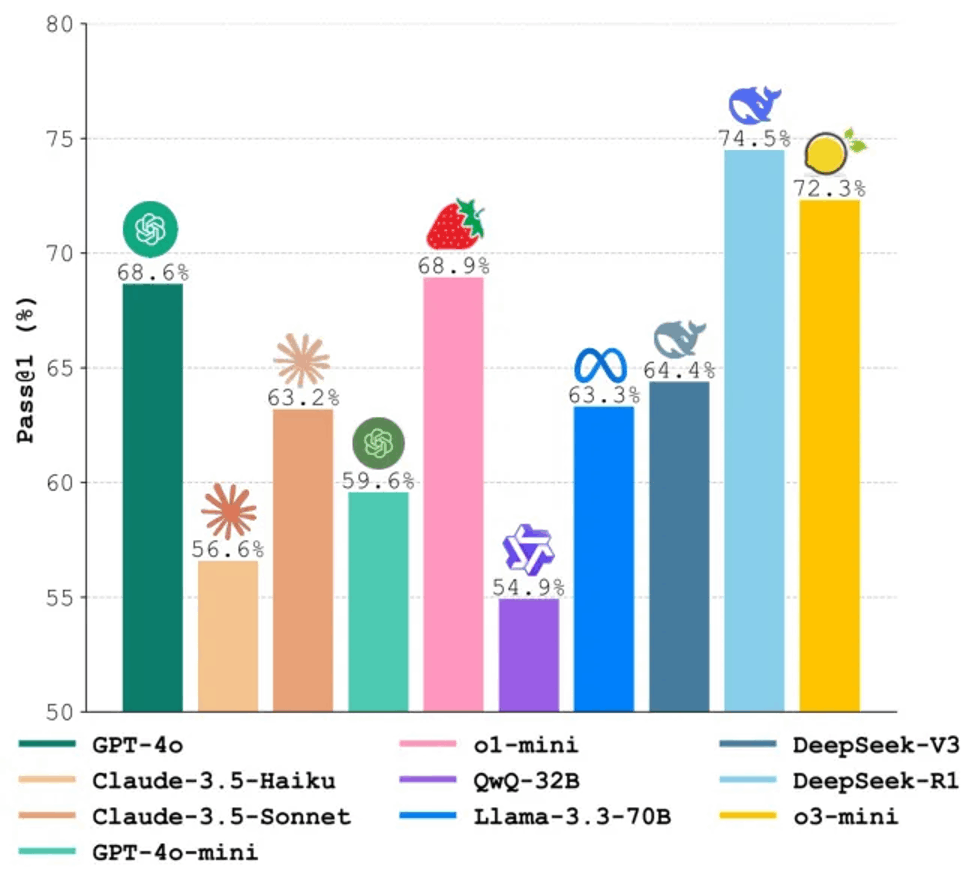
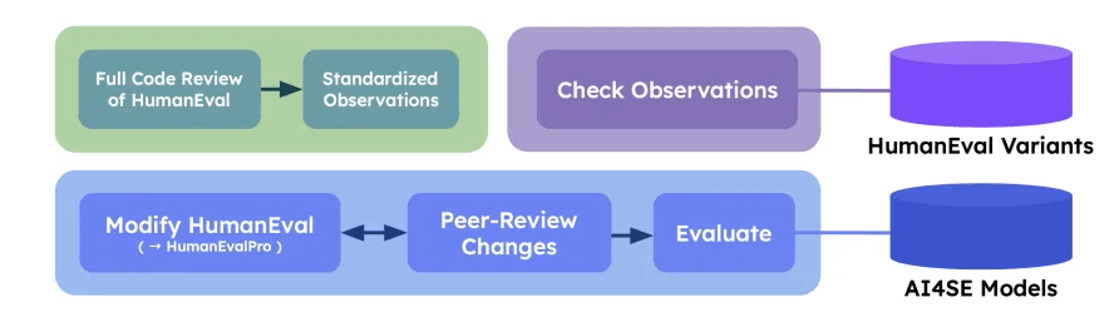
Benchmarking AI Models in Software Engineering: A Review, Search Tool, and Enhancement Protocol
论文链接:
https://huggingface.co/papers/2503.05860
简要介绍:
由 Roham Koohestani 等人提出的工作通过审查 173 项研究,识别了 204 个 AI4SE 基准测试,并分析其局限性。他们开发了 BenchScout 搜索工具和 BenchFrame 增强方法,以 HumanEval 为例推出 HumanEvalNext,显著提升了评估难度和质量。
核心图片:
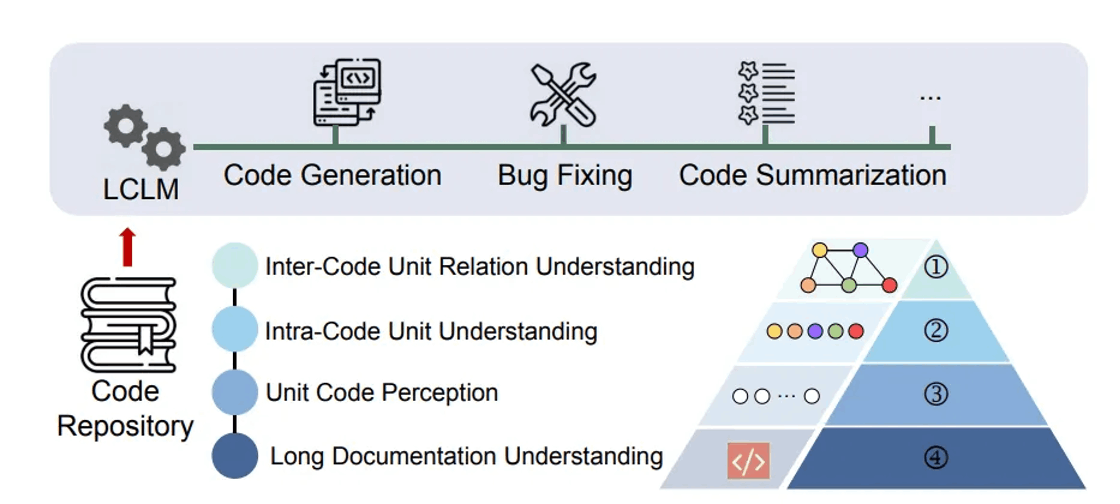
LONGCODEU: Benchmarking Long-Context Language Models on Long Code Understanding
论文链接:
https://modelscope.cn/papers/123554
简要介绍:
由北京大学的 Jia Li 等人提出的 LONGCODEU,是一个长代码理解基准测试,从四个方面(8 个任务)评估 LCLMs 的能力。实验表明,当代码长度超 32K 时,模型性能急剧下降,远低于其宣称的 128K-1M 上下文窗口,为软件工程优化提供了洞见。
核心图片:
ProBench: Judging Multimodal Foundation Models on Open-ended Multi-domain Expert Tasks
论文链接:
https://modelscope.cn/papers/124404
简要介绍:
由澳大利亚国立大学的 Yan Yang 等人提出的 ProBench,是一个开放式多领域专家任务基准测试,包含 4,000 个高质量样本,覆盖 10 个领域和 56 个子领域。实验显示,即使最佳开源模型与专有模型接近,视觉感知和高级推理仍具挑战性。
核心图片:

MinorBench: A hand-built benchmark for content-based risks for children
论文链接:
https://modelscope.cn/papers/126387
简要介绍:
由新加坡政府科技局的 Shaun Khoo 等人提出的 MinorBench,是一个手工构建的基准测试,评估 LLMs 在拒绝儿童不安全查询方面的能力。通过中学案例研究,结果显示主流 LLMs 在儿童安全合规性上差异显著,强调了定制化 AI 的重要性。
本周的 AI Bench 研究成果涵盖了代码生成、医疗推理、图像生成和儿童安全等多个领域。这些基准测试不仅揭示了当前模型的局限,也为未来研究指明了方向。让我们共同期待 AI 技术在这些前沿领域的突破吧!🌟

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献547条内容
已为社区贡献547条内容

所有评论(0)