
今日热门论文推荐:Seedream、LMM-R1、YuE、Gemini Embedding
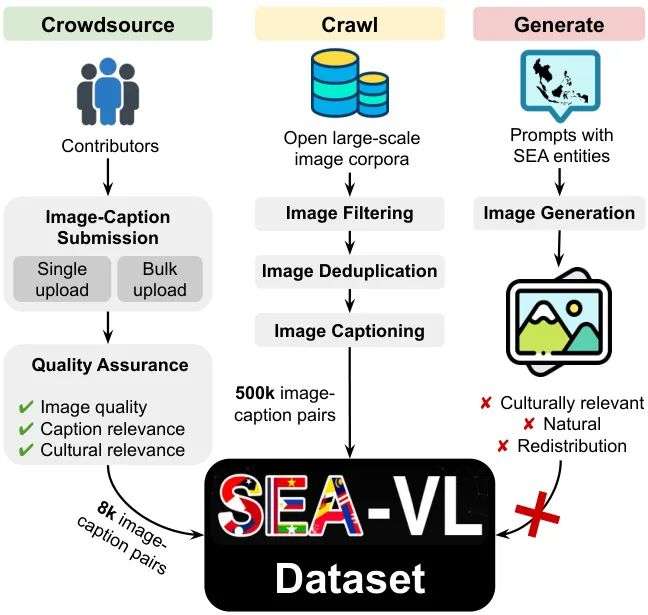
由Cohere、SEACrowd等机构联手打造,SEA-VL是一个面向东南亚地区的多文化视觉-语言数据集,填补了AI模型在该地区文化细微差别理解上的空白。该工作通过众包、爬取和生成三种方式收集了128
作者:InternLM、Qwen 等 LLM 每日一览热门论文版,顶会投稿选题不迷惘。快来看看由「机智流」和「ModelScope」社区推荐的今日热门论文吧!

Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
论文链接:https://modelscope.cn/papers/125634
简要介绍:由Cohere、SEACrowd等机构联手打造,SEA-VL是一个面向东南亚地区的多文化视觉-语言数据集,填补了AI模型在该地区文化细微差别理解上的空白。该工作通过众包、爬取和生成三种方式收集了128万张文化相关图像,结合本地贡献者确保数据的高质量和多样性,推动了更具包容性的AI发展。
核心图片:
添加图片注释,不超过 140 字(可选)
LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
论文链接:https://modelscope.cn/papers/125170
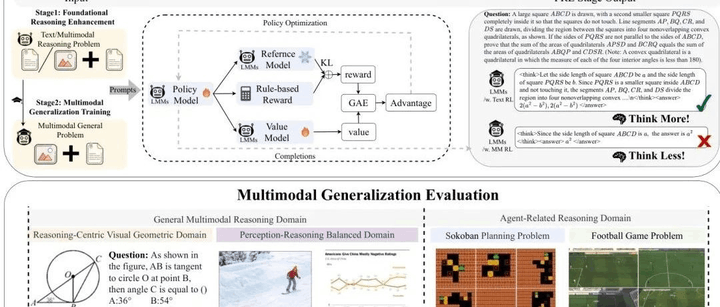
简要介绍:由东南大学等机构提出的LMM-R1,通过两阶段规则强化学习(RL)框架增强了3B参数多模态大模型的推理能力。该方法先通过文本数据强化基础推理,再推广至多模态任务,在Qwen2.5-VL-Instruct-3B上实现多模态和文本基准提升4.83%和4.5%,为数据高效的推理优化提供了新思路。
核心图片:
添加图片注释,不超过 140 字(可选)
YuE: Scaling Open Foundation Models for Long-Form Music Generation
论文链接:https://huggingface.co/papers/2503.08638
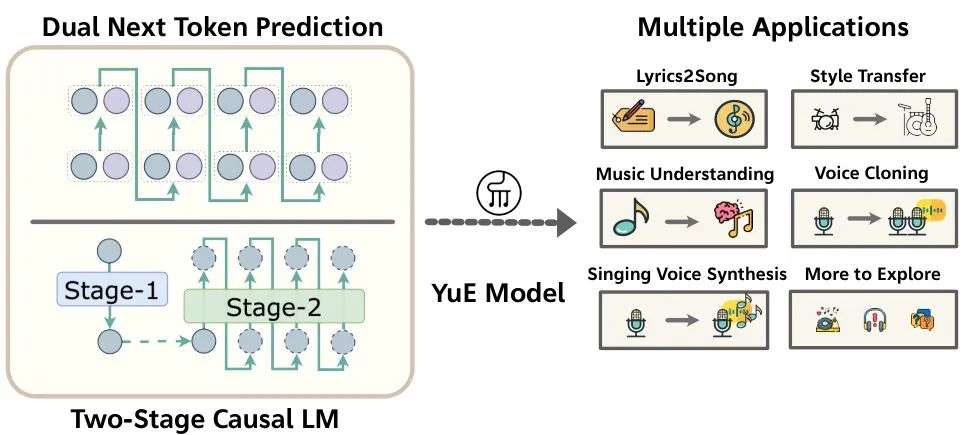
简要介绍:HKUST和MAP团队推出了YuE,一种基于LLaMA2架构的开源音乐生成模型,专注于长篇歌词到歌曲生成。YuE能生成长达5分钟的音乐,保持歌词对齐和音乐连贯性,支持风格迁移和多语言扩展,在音乐性和声乐敏捷性上媲美甚至超越部分专有系统。
核心图片:
添加图片注释,不超过 140 字(可选)
MagicInfinite: Generating Infinite Talking Videos with Your Words and Voice
论文链接:https://modelscope.cn/papers/124803
简要介绍:由Hedra Inc.和北京大学等合作开发的MagicInfinite,是一种基于扩散Transformer的框架,可生成无限长度的说话视频,支持多种角色风格和多模态控制。该工作通过3D全注意力机制和两阶段学习策略,实现高效推理和高保真动画,已公开上线供体验。
核心图片:

添加图片注释,不超过 140 字(可选)
UniF^2ace: Fine-grained Face Understanding and Generation with Unified Multimodal Models
论文链接:https://modelscope.cn/papers/125793
简要介绍:由北京大学等机构提出的UniF^2ace,是首个专为细粒度人脸理解和生成设计的统一多模态模型。基于自建的130K人脸数据集,该模型结合扩散技术和混合专家架构,在理解和生成任务中均超越现有模型,推动了人脸领域的AGI研究。
核心图片:

添加图片注释,不超过 140 字(可选)
Optimizing Test-Time Compute via Meta Reinforcement Fine-Tuning
论文链接:https://modelscope.cn/papers/125042
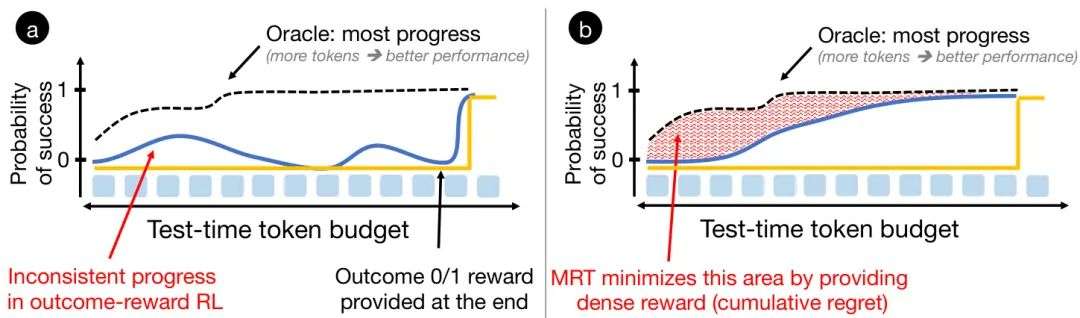
简要介绍:由CMU和Hugging Face团队开发的MRT(Meta Reinforcement Fine-Tuning),将测试时计算优化形式化为元强化学习问题,通过最小化累积遗憾提升LLM推理性能。在数学推理任务中,MRT比传统RL方法性能提升2-3倍,token效率提高1.5倍。
核心图片:
添加图片注释,不超过 140 字(可选)
Seedream 2.0: A Native Chinese-English Bilingual Image Generation Foundation Model
论文链接:https://modelscope.cn/papers/125511
简要介绍:字节跳动Seed Vision团队推出的Seedream 2.0,是一款中英双语图像生成模型,解决现有模型在中文文化理解和文本渲染上的不足。集成自研LLM和多阶段优化,该模型在提示跟随、美学和结构正确性上达到SOTA,已应用于多个平台。
核心图片:
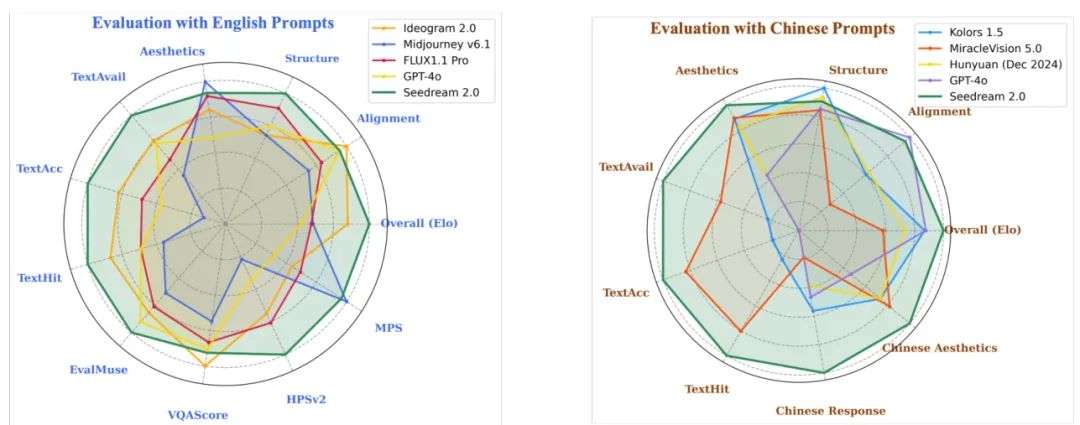
添加图片注释,不超过 140 字(可选)
SegAgent: Exploring Pixel Understanding Capabilities in MLLMs by Imitating Human Annotator Trajectories
论文链接:https://modelscope.cn/papers/125357
简要介绍:由浙江大学和蚂蚁集团合作的SegAgent,通过模仿人类标注轨迹探索MLLM的像素级理解能力。提出HLMAT任务,将分割建模为多步决策过程,SegAgent在无需额外解码器的情况下实现高精度分割,支持掩码精炼等扩展任务。
Gemini Embedding: Generalizable Embeddings from Gemini
论文链接:https://modelscope.cn/papers/125362
简要介绍:谷歌Gemini Embedding团队基于Gemini LLM开发了一种通用嵌入模型,支持多语言和代码任务。在MMTEB基准上,该模型大幅超越前SOTA,展示了对250+语言的强大适应性,适用于分类、检索等多种下游任务。
结语:今天的盘点涵盖了从文化数据集到多模态推理、音乐生成等多个领域的突破性研究,每篇论文都展现了AI技术的最新进展。你最看好哪篇?欢迎留言讨论!🌟 下期见!
-- 完 --
欢迎在「机智流」公众号后台回复「cc」,加入机智流大模型交流群,与我们一起探索 AI 与人类潜能的未来,一起共赴 AI 浪潮!

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献659条内容
已为社区贡献659条内容

所有评论(0)