
R1-Omni开源!多模态模型+RLVR,让各模态作用清晰可见
随着 DeepSeek R1 的推出,强化学习在大模型领域的潜力被进一步挖掘。Reinforcement Learning with Verifiable Reward (RLVR) 方法的出现,为多
随着 DeepSeek R1 的推出,强化学习在大模型领域的潜力被进一步挖掘。Reinforcement Learning with Verifiable Reward (RLVR) 方法的出现,为多模态任务提供了全新的优化思路,无论是几何推理、视觉计数,还是经典图像分类和物体检测任务,RLVR 都展现出了显著优于传统监督微调(SFT)的效果。
然而,现有研究多聚焦于 Image-Text 多模态任务,尚未涉足更复杂的全模态场景。基于此,通义实验室团队探索了 RLVR 与视频全模态模型的结合,并提出了 R1-Omni 模型。
论文:
https://arxiv.org/abs/2503.05379
Github:
https://github.com/HumanMLLM/R1-Omni
模型:
https://www.modelscope.cn/models/iic/R1-Omni-0.5B
01.模型介绍
模型训练的两个阶段
冷启动阶段:奠定基础推理能力
为了保证RLVR阶段训练的平稳性,该团队使用一个组合数据集进行微调,使其初步掌握多模态情感识别任务中的推理能力。该组合数据集是一个由 580 条视频数据组成的组合数据集,其中包括来自 Explainable Multimodal Emotion Reasoning (EMER) 数据集的 232 条样本,以及来自 HumanOmni 数据集的 348 条样本。
EMER数据集的数据格式如下:

这一阶段确保了模型在进入 RLVR 阶段前已具备一定基础能力,从而提升后续训练的效率与稳定性。
RLVR阶段:推理与泛化能力双重提升
基于冷启动阶段初始化的模型,通过RLVR的方式训练,同时利用视频和音频的多模态数据优化情感识别任务。该阶段通过强化学习与可验证奖励机制,进一步优化了模型的推理能力和泛化性能。
RLVR的第一个关键组件是策略模型(policy model),该模型处理由视频帧和相应音频流组成的多模态输入数据,并生成一组候选响应。每个响应都附带详细的推理,展示了模型如何整合视觉和听觉信息从而得出预测的详细过程。
第二个关键组件是奖励函数,策略模型生成的这些候选响应使用可验证的奖励函数(reward function)进行评估。RLVR训练框架中用到的奖励函数受DeepSeekR1的启发,将奖励分成了两个部分,精确率奖励(accuracy reward)和格式奖励(format reward),这两部分共同形成最终的奖励R:

通过联合两部分奖励,该奖励函数不仅鼓励模型生成正确的预测,同时保证输出是结构化的,并且和我们预设的格式一致。
实验表明,RLVR 不仅让音频和视频信息的作用更加透明,还显著提升了模型在情绪识别任务中的关键指标。此外,R1-Omni 在分布外测试中表现出色,充分展现了其在复杂场景下的强大泛化能力。
模型效果对比
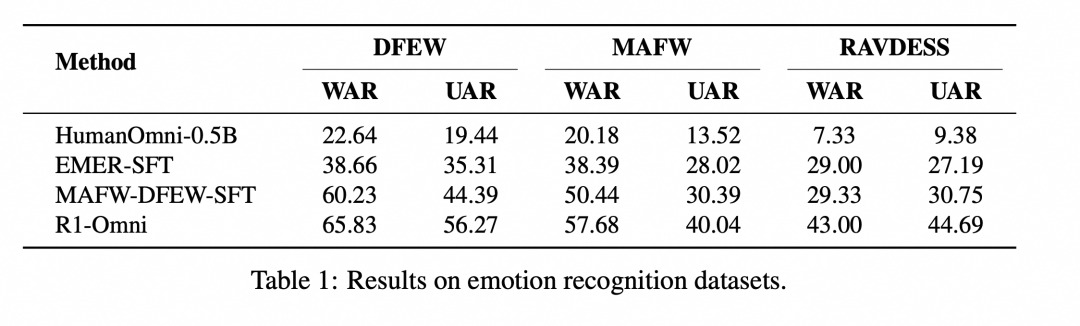
为了验证 R1-Omni 的性能,我们将其与原始的 HumanOmni-0.5B 模型、冷启动阶段的模型以及在 MAFW 和 DFEW 数据集上有监督微调的模型进行了对比。
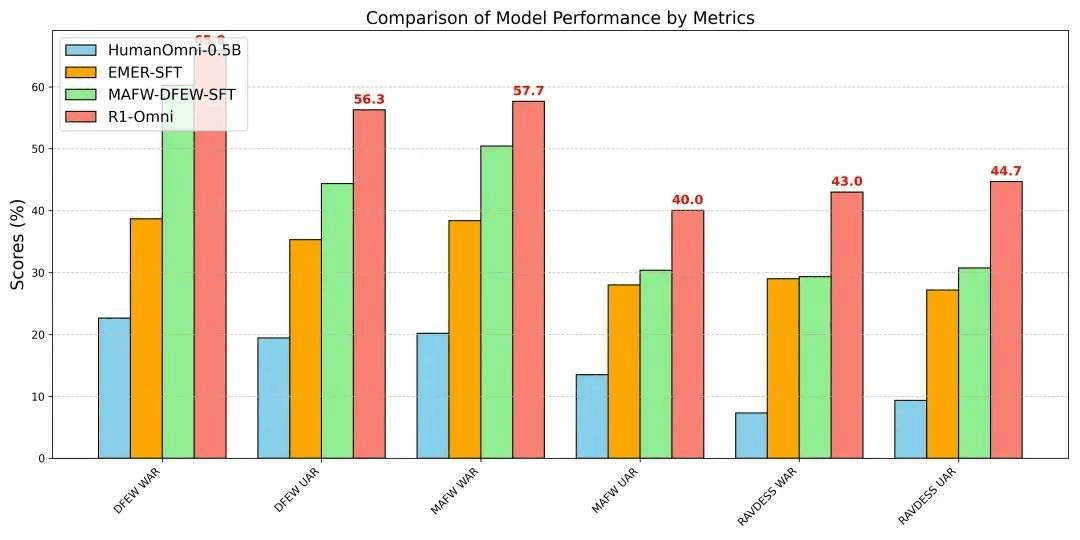
实验结果显示,在同分布测试集(DFEW 和 MAFW)上,R1-Omni 相较于原始基线模型平均提升超过 35%,相较于 SFT 模型在 UAR 上的提升高达 10% 以上。在不同分布测试集(RAVDESS)上,R1-Omni 同样展现了卓越的泛化能力,WAR 和 UAR 均提升超过 13%。这些结果充分证明了 RLVR 在提升推理能力和泛化性能上的显著优势。
02.模型效果
R1-Omni 的一大亮点在于其透明性(推理能力)。通过 RLVR 方法,音频信息和视频信息在模型中的作用变得更加清晰可见。
比如,在情绪识别任务中,R1-Omni 能够明确展示哪些模态信息对特定情绪的判断起到了关键作用。
https://live.csdn.net/v/468588


https://live.csdn.net/v/468589


这种透明性不仅帮助我们更好地理解模型的决策过程,也为未来的研究提供了重要参考方向。未来,我们期待 R1-Omni 在更多复杂场景中发挥作用,为多模态任务的研究与应用开辟新的道路。
点击阅读原文,即可跳转模型~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)