
腾讯开源HunyuanVideo-I2V图生视频模型+LoRA训练脚本,社区部署、推理实战教程来啦!
继阿里的通义万相wan2.1模型之后,腾讯混元又出大招,重磅发布HunyuanVideo-I2V图生视频模型。
01.引言
继阿里的通义万相wan2.1模型之后,腾讯混元又出大招,重磅发布HunyuanVideo-I2V图生视频模型。该模型基于HunyuanVideo文生视频基础模型,利用基础模型先进的视频生成能力,将应用扩展到图像到视频的生成任务。混元研究团队还同步开源了LoRA训练代码,用于定制化特效生成,可创建更有趣的视频效果。
开源内容:
-
HunyuanVideo-I2V的推理代码
-
HunyuanVideo-I2V的模型权重
-
LoRA训练脚本
代码仓库:
https://github.com/Tencent/HunyuanVideo-I2V
模型地址:
https://modelscope.cn/models/AI-ModelScope/HunyuanVideo-i2v/
02.整体架构
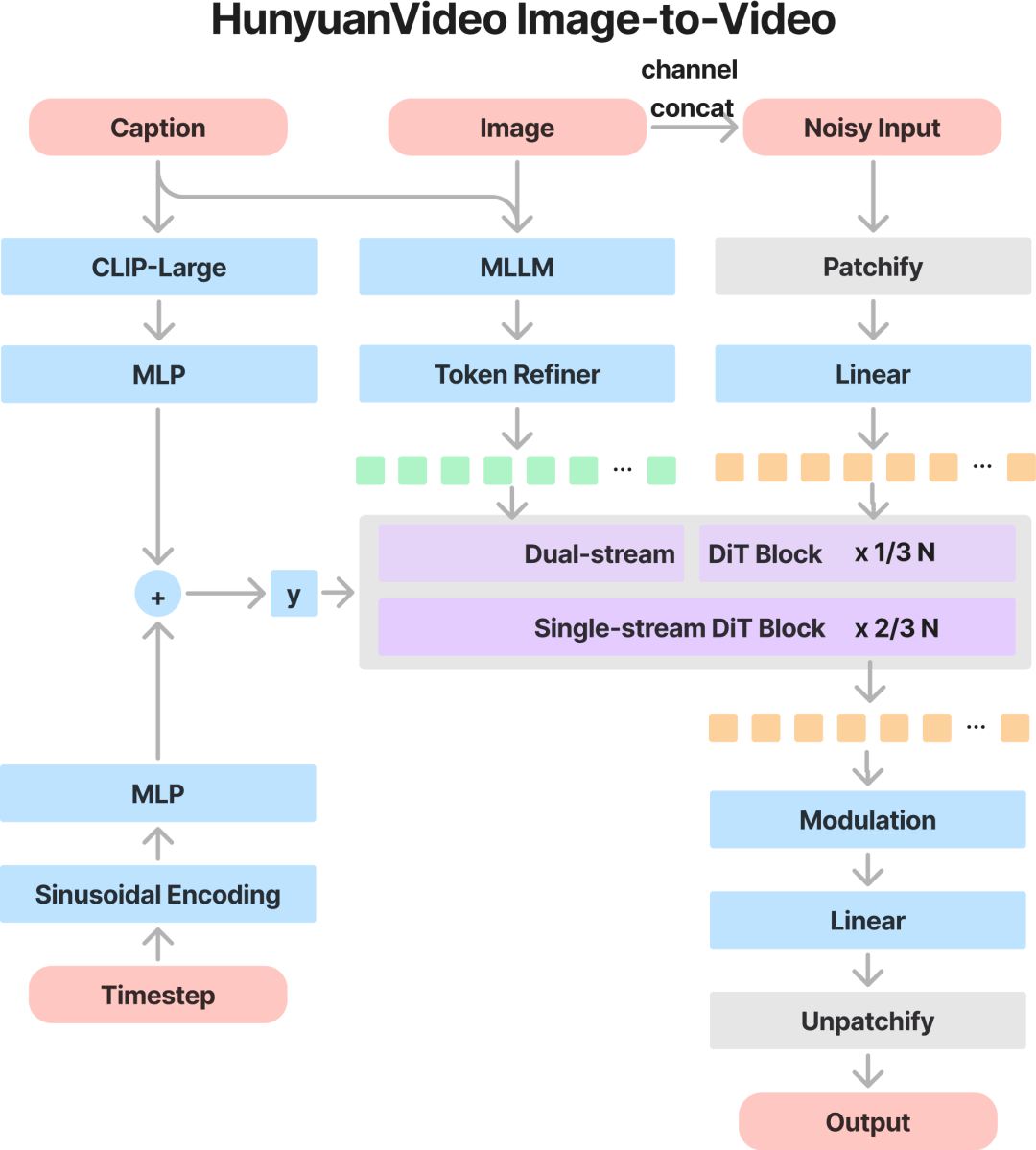
为利用HunyuanVideo强大的视频生成能力,研究团队采用图像潜在连接技术来有效地重建参考图像信息,并将其纳入视频生成过程。
由于使用预训练的Decoder-Only架构多模态大语言模型(MLLM)作为文本编码器,可用于显著增强模型对输入图像语义内容的理解能力,并实现图像与文本描述信息的深度融合。具体而言,输入图像经MLLM处理后生成语义图像tokens,这些tokens与视频隐空间tokens拼接,实现跨模态的全注意力计算。
整个系统架构旨在最大化图像与文本模态的协同效应,确保从静态图像生成连贯的视频内容。该集成不仅提升了生成视频的保真度,还增强了模型对复杂多模态输入的解析能力。整体架构如下图所示:
03.本地推理实践
运行要求
下表展示了运行HunyuanVideo-I2V模型(batch size=1)生成视频的硬件要求:
|
模型 |
分辨率 |
GPU显存峰值 |
|
HunyuanVideo-I2V |
720p |
60GB |
-
需配备支持CUDA的NVIDIA GPU
-
测试环境为单卡80G GPU
-
最低要求: 720p分辨率需至少60GB显存
-
推荐配置: 建议使用80GB显存GPU以获得更佳生成质量
-
测试操作系统:Linux
克隆代码
git clone https://github.com/tencent/HunyuanVideo-I2V
cd HunyuanVideo-I2V配置环境
pip install -r requirements.txt
pip install ninja
pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.6.3模型下载
混元图生视频包括三个模型,基础模型hunyuan-video-i2v-720p和两个文本编码器(text_encoder_i2v,text_encoder_2)。模型下载后默认放在HunyuanVideo-I2V/ckpts文件夹下,文件结构:
HunyuanVideo-I2V
├──ckpts
│ ├──README.md
│ ├──hunyuan-video-i2v-720p
│ │ ├──transformers
│ │ │ ├──mp_rank_00_model_states.pt
├ │ ├──vae
├ │ ├──lora
│ │ │ ├──embrace_kohaya_weights.safetensors
│ │ │ ├──hair_growth_kohaya_weights.safetensors
│ ├──text_encoder_i2v
│ ├──text_encoder_2
├──...魔搭平台上可以下载到这三个模型,下载命令如下:
cd HunyuanVideo-I2V
# 下载基础模型
modelscope download --model AI-ModelScope/HunyuanVideo-I2V --local_dir ./ckpts
# 下载文本编码器MLLM
modelscope download --model AI-ModelScope/llava-llama-3-8b-v1_1-transformers --local_dir ./ckpts/text_encoder_i2v
# 下载文本编码器CLIP
modelscope download --model AI-ModelScope/clip-vit-large-patch14 --local_dir ./ckpts/text_encoder_2推理代码
cd HunyuanVideo-I2V
python3 sample_image2video.py \
--model HYVideo-T/2 \
--prompt "A man with short gray hair plays a red electric guitar." \
--i2v-mode \
--i2v-image-path ./assets/demo/i2v/imgs/0.png \
--i2v-resolution 720p \
--video-length 129 \
--infer-steps 50 \
--flow-reverse \
--flow-shift 17.0 \
--seed 0 \
--use-cpu-offload \
--save-path ./results耗时:50步,生成1280*704分辨率5秒的视频,A100,大概需要50分钟
![]()
显存占用:约60G

测试case:
提示词:A man with short gray hair plays a red electric guitar.
输入的图片:

https://live.csdn.net/v/468004
💡写图生视频模型提示词(prompt)的建议:
-
使用简短的提示:为了有效地引导模型的生成,请保持提示简短且直截了当。
-
包含关键元素:一个结构良好的提示应包括:
-
主体:指定视频的主要焦点。
-
动作:描述正在发生的运动或活动。
-
背景(可选):设置视频的场景。
-
镜头(可选):指示视角或视点。
-
避免过于详细的提示:冗长或高度详细的提示可能会导致视频输出中出现不必要的转场。
04.ComfyUI推理实践
ComfyUI官方在第一时间支持了混元的图生视频模型,小编也带大家动手玩玩混元的图生视频工作流。
不久前通义万相Wan2.1发布时,魔搭社区出过一篇实战教程,如果你是小白同学,请先预习一下这一篇,其他同学请直接开始。《高效部署通义万相Wan2.1:ComfyUI文生/图生视频实战,工作流直取!》
更新ComfyUI、下载模型、打开ComfyUI服务后,拖入工作流就可以直接运行。
更新ComfyUI
cd ComfyUI
git pull
git status # 确认本地代码是否与master分支一致下载模型
魔搭平台上模型下载地址:https://modelscope.cn/models/Comfy-Org/HunyuanVideo_repackaged/files
模型下载命令
cd ComfyUI/models
modelscope download --model Comfy-Org/HunyuanVideo_repackaged --local_dir .模型下载好后分别把模型挪到ComfyUI的对应目录,文件结构如下:
├── clip_vision/
│ └── llava_llama3_vision.safetensors
├── text_encoders/
│ ├── clip_l.safetensors
│ ├── llava_llama3_fp16.safetensors
│ └── llava_llama3_fp8_scaled.safetensors
├── vae/
│ └── hunyuan_video_vae_bf16.safetensors
└── diffusion_models/
└── hunyuan_video_image_to_video_720p_bf16.safetensors
mv split_files/clip_vision/llava_llama3_vision.safetensors clip_vision/
mv split_files/text_encoders/* text_encoders/
mv split_files/vae/hunyuan_video_vae_bf16.safetensors vae/
mv split_files/diffusion_models/hunyuan_video_* diffusion_models/启动ComfyUI
cd ComfyUI
python main.py运行示例工作流
将示例robot工作流的json文件拖入ComfyUI,点击执行即可运行工作流
robot图生视频工作流文件:
https://modelscope.cn/notebook/share/ipynb/b8a3efeb/robot.ipynb
输入图片:


显存与耗时
测试了两种尺寸分辨率的显存占用与耗时数据,如下表:
|
分辨率 |
显存峰值 |
生成时间 |
|
512*512 |
42G |
~1min |
|
1024*1024 |
48G |
~5min |
如遇到显存不足可以把clip2切换为fp8版本。另外ComfyUI官方满血版视频生成速度比官方推理代码快太多了,强烈推荐直接使用ComfyUI进行推理!
相关链接:https://github.com/Tencent/HunyuanVideo-I2V/tree/main?tab=readme-ov-file
点击链接即可跳转模型链接~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献662条内容
已为社区贡献662条内容

所有评论(0)