
QwQ-32B开源!更小尺寸,仅1/20参数性能比肩满血R1
QwQ-32B 在一系列基准测试中进行了评估,测试了数学推理、编程能力和通用能力。
01.模型介绍
今天,通义千问开源了推理模型QwQ-32B
QwQ-32B 在一系列基准测试中进行了评估,测试了数学推理、编程能力和通用能力。以下结果展示了 QwQ-32B 与其他领先模型的性能对比,包括 DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini 以及原始的 DeepSeek-R1。
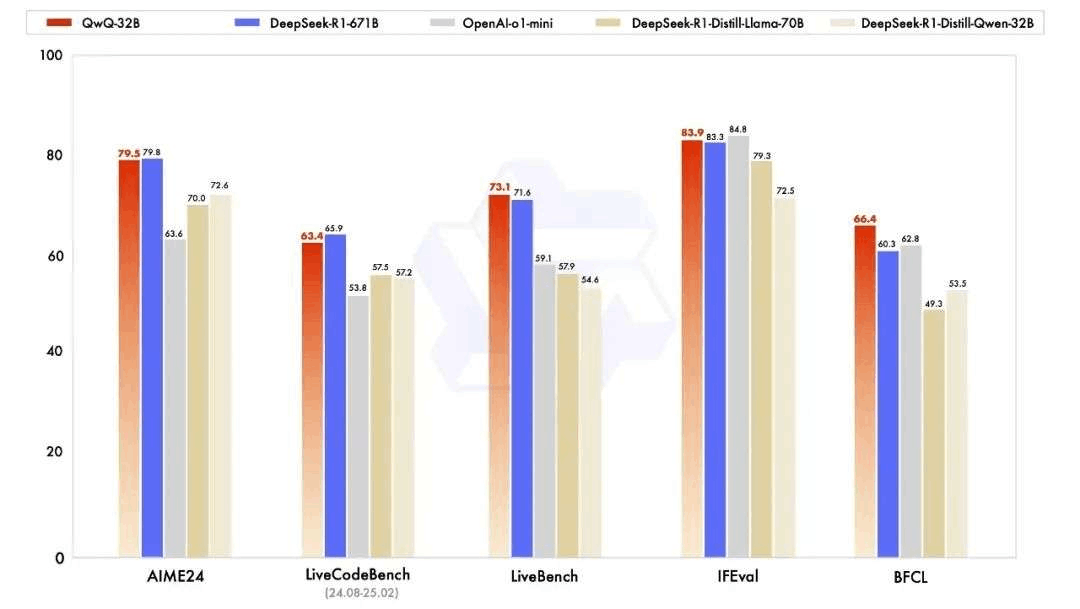
在测试数学能力的 AIME24 评测集上,以及评估代码能力的 LiveCodeBench 中,千问 QwQ-32B 表现与DeepSeek-R1相当,远胜于 o1-mini 及相同尺寸的R1 蒸馏模型;在由Meta首席科学家杨立昆领衔的“最难LLMs评测榜” LiveBench、谷歌等提出的指令遵循能力IFEval评测集、由加州大学伯克利分校等提出的评估准确调用函数或工具方面的BFCL测试中,千问 QwQ-32B 的得分均超越了 DeepSeek- R1。
大规模强化学习
研究团队在冷启动的基础上开展了大规模强化学习。在初始阶段,特别针对数学和编程任务进行了 RL 训练。与依赖传统的奖励模型(reward model)不同,研究团队通过校验生成答案的正确性来为数学问题提供反馈,并通过代码执行服务器评估生成的代码是否成功通过测试用例来提供代码的反馈。
研究团队发现在 RL 扩展过程中,随着训练轮次的推进,这两个领域中的性能均表现出持续的提升。
在第一阶段的 RL 过后,研究团队增加了另一个针对通用能力的 RL。此阶段使用通用奖励模型和一些基于规则的验证器进行训练。研究团队发现,通过少量步骤的通用 RL,可以提升其他通用能力,同时在数学和编程任务上的性能没有显著下降。
模型链接:
https://modelscope.cn/collections/QwQ-32B-0f1806b8a8514a
体验空间:
https://modelscope.cn/studios/Qwen/QwQ-32B-Demo
02.模型推理
Transformers
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)魔搭API-Inference直接调用
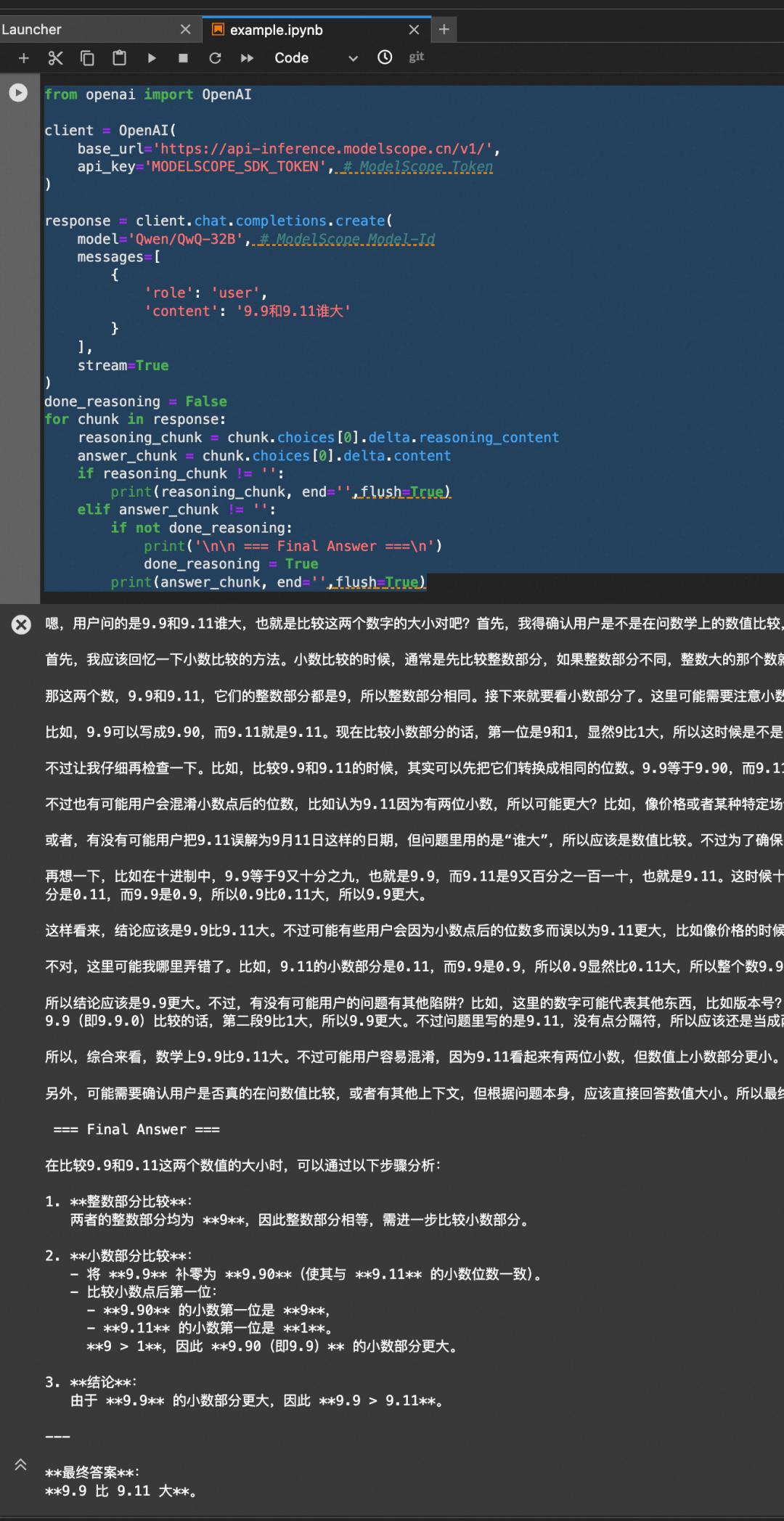
魔搭平台的API-Inference,也第一时间为QwQ-32B模型提供了支持。魔搭的用户可通过API调用的方式直接使用该模型。代码范例在模型页面(https://www.modelscope.cn/models/Qwen/QwQ-32B) 右侧API-Inference入口可以直接获取。

实现通过API接口直接调用QwQ-32B:
Ollama本地拉起
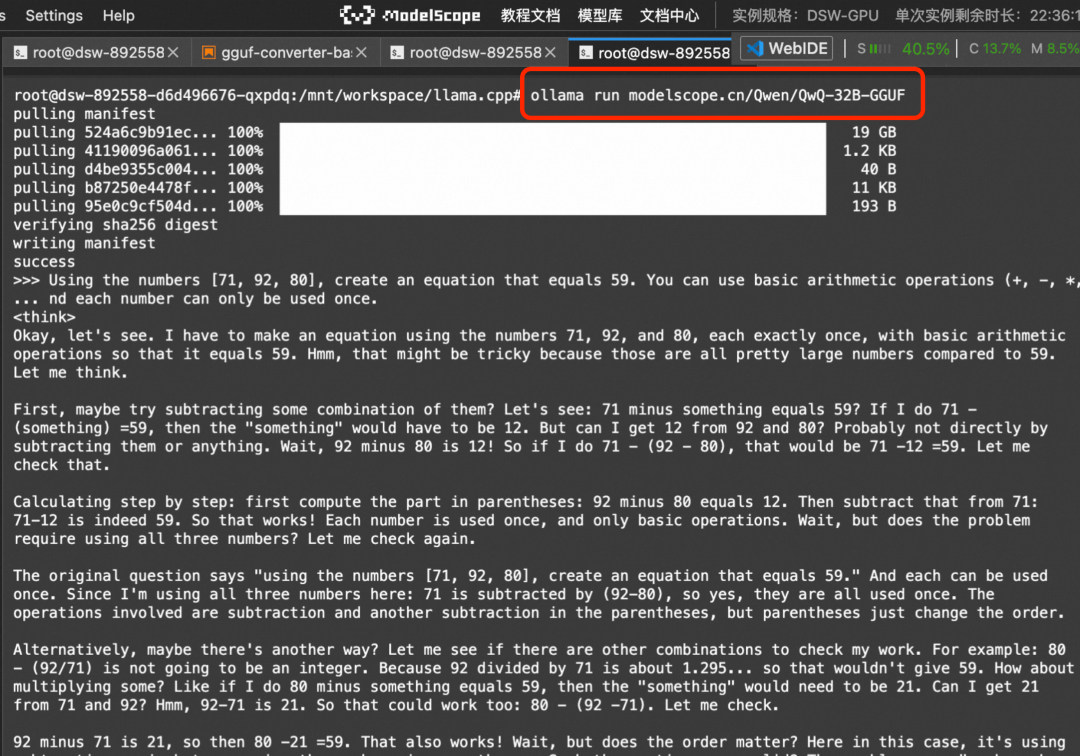
通过Ollama与魔搭平台的整合,开发者也可以直接在本地的Ollama环境,直接运行QwQ-32B模型:
ollama run modelscope.cn/Qwen/QwQ-32B-GGUF更详细的调用选项和使用方法可参考文档:https://modelscope.cn/docs/models/advanced-usage/ollama-integration,具体运行结果如下:
模型微调
ms-swift已经支持了QwQ-32B的训练到部署。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。
ms-swift开源地址:
https://github.com/modelscope/ms-swift
我们展示对QwQ-32B进行微调的demo,并给出自定义数据集的格式。
在开始微调之前,请确保您的环境已准备妥当。
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .首先我们使用QWQ-32B蒸馏部分数据,保持其思考的能力,将蒸馏的数据保存在本地路径:qwq-32b-distill.jsonl。
CUDA_VISIBLE_DEVICES=0,1 \
swift infer \
--model Qwen/QwQ-32B \
--infer_backend vllm \
--val_dataset 'AI-ModelScope/alpaca-gpt4-data-zh#1000' 'AI-ModelScope/alpaca-gpt4-data-en#1000' \
--gpu_memory_utilization 0.9 \
--max_model_len 32768 \
--max_new_tokens 8192 \
--result_path qwq-32b-distill.jsonl \
--tensor_parallel_size 2 \
--disable_custom_all_reduce true微调脚本如下:
NPROC_PER_NODE=2 \
CUDA_VISIBLE_DEVICES=0,1 \
swift sft \
--model Qwen/QwQ-32B \
--train_type lora \
--dataset 'qwq-32b-distill.jsonl' \
'<your-dataset-path>' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 8 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 4096 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot \
--deepspeed zero2自定义数据集可以参考以下格式:
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "告诉我明天的天气"}, {"role": "assistant", "content": "<think>\n...</think>\n\n明天天气晴朗"}]}
{"messages": [{"role": "system", "content": "你是个有用无害的数学计算器"}, {"role": "user", "content": "1+1等于几"}, {"role": "assistant", "content": "<think>\n...</think>\n\n等于2"}, {"role": "user", "content": "再加1呢"}, {"role": "assistant", "content": "<think>\n...</think>\n\n等于3"}]}训练显存占用:

训练完成后,使用以下命令对训练后的权重进行推理,这里的`--adapters`需要替换成训练生成的last checkpoint文件夹。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048 \
--infer_backend pt推送模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'点击链接即可跳转模型合集~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 1
1- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)