
高效部署通义万相Wan2.1:ComfyUI文生/图生视频实战,工作流直取!
通义万相Wan2.1开源不到一周,已登顶HuggingFace Model 和 Space 榜双榜首,在HuggingFace和ModelScope平台的累计下载量突破100万次,社区热度持续攀升!为
通义万相Wan2.1开源不到一周,已登顶HuggingFace Model 和 Space 榜双榜首,在HuggingFace和ModelScope平台的累计下载量突破100万次,社区热度持续攀升!为响应小伙伴们对ComfyUI工作流运行Wan2.1的强烈需求,社区开发者整理了实战教程👇
本文将手把手教你分别在魔搭免费GPU算力环境、本地环境部署运行ComfyUI工作流,玩转Wan2.1文生视频、图生视频案例实践。
01.魔搭Notebook运行ComfyUI文生视频工作流
step1 如何在魔搭中启动Notebook
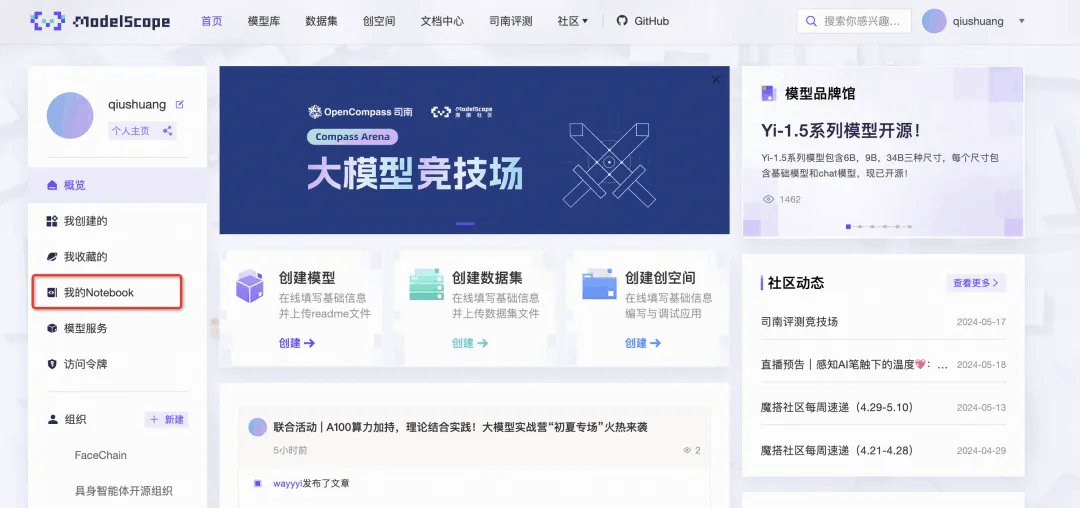
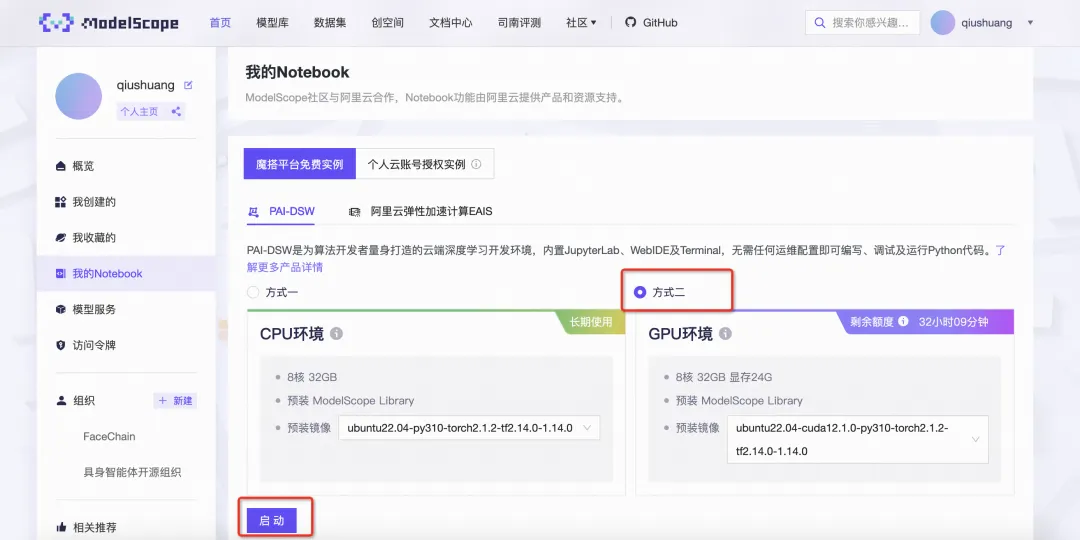
1、打开ModelScope 魔搭社区首页,点击我的Notebook
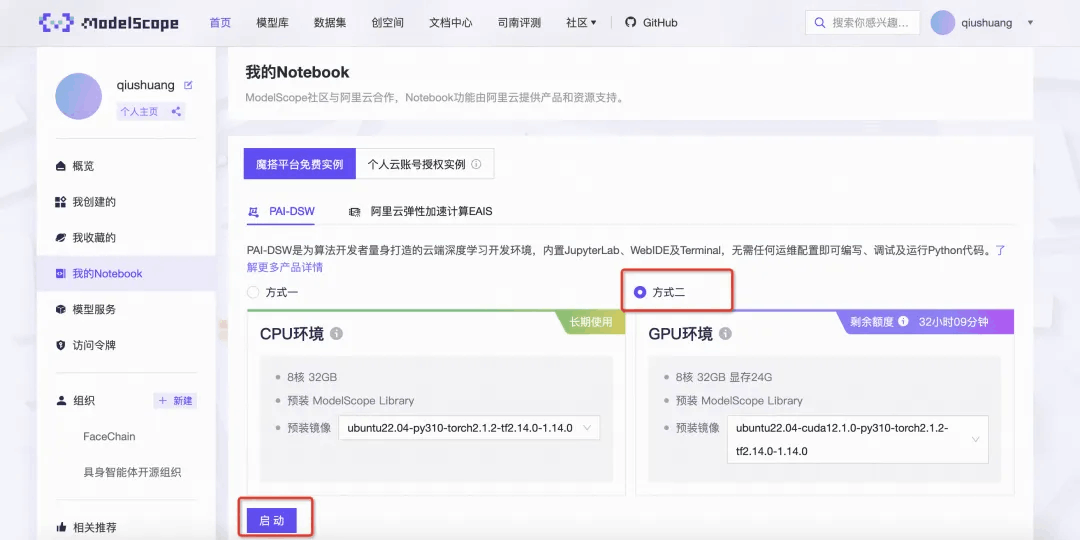
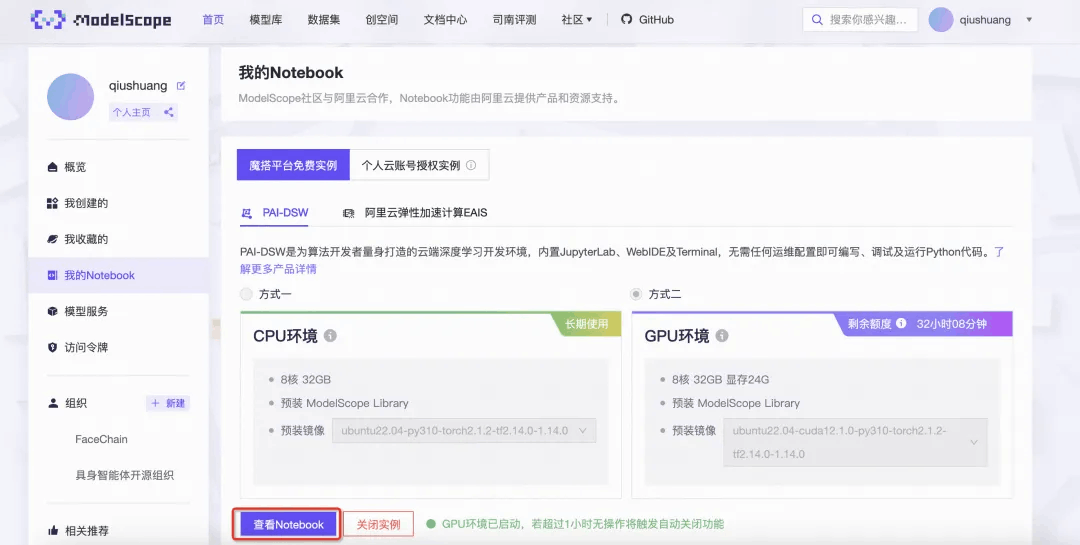
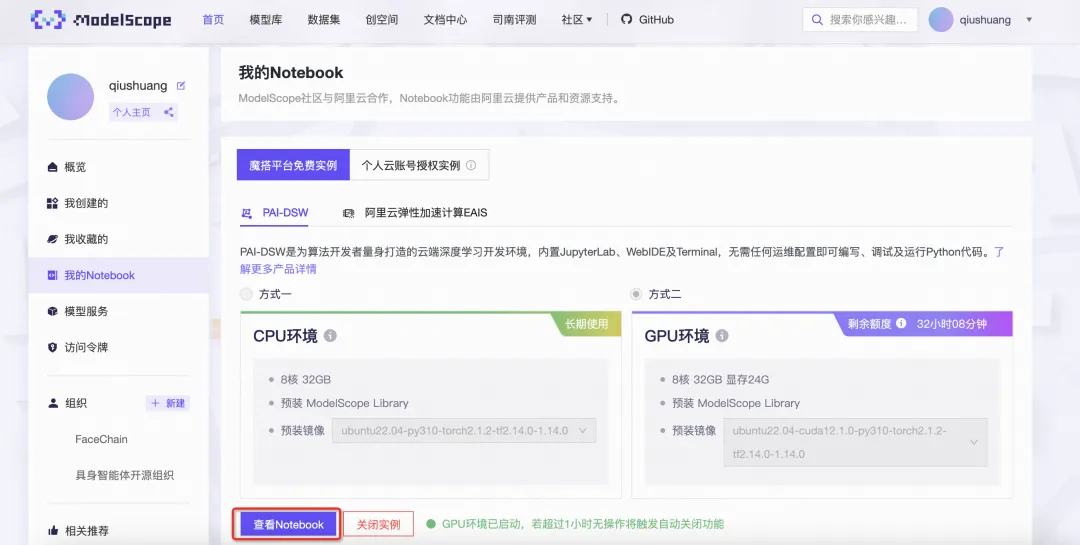
2、魔搭社区免费提供的GPU免费算力上体验,选择方式二启动后点击查看Notebook
step2 安装ComfyUI及其依赖
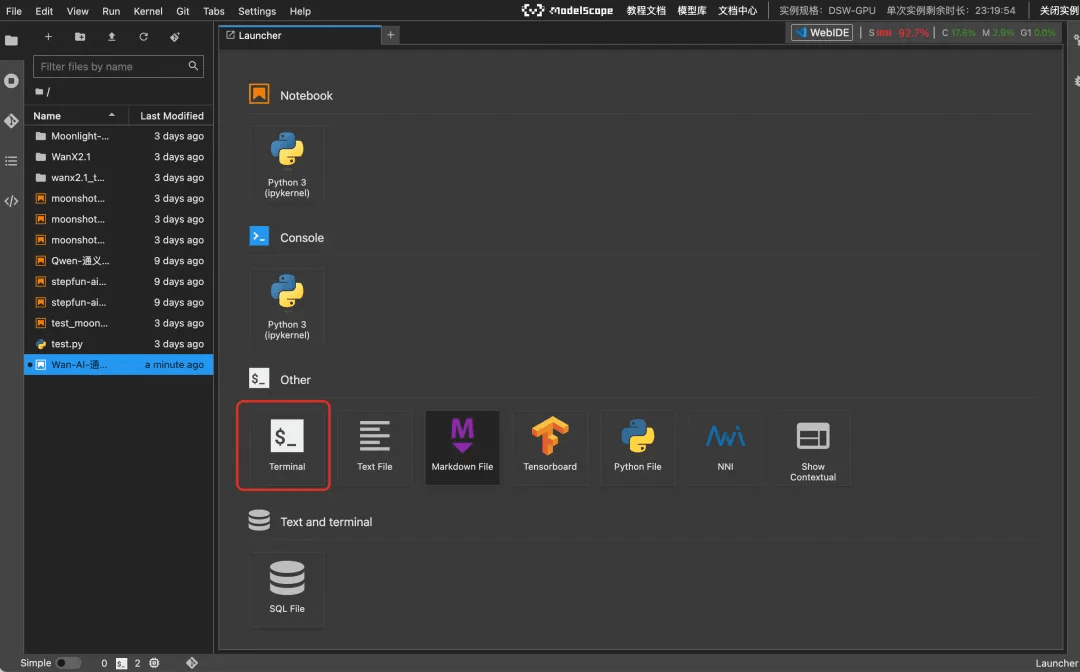
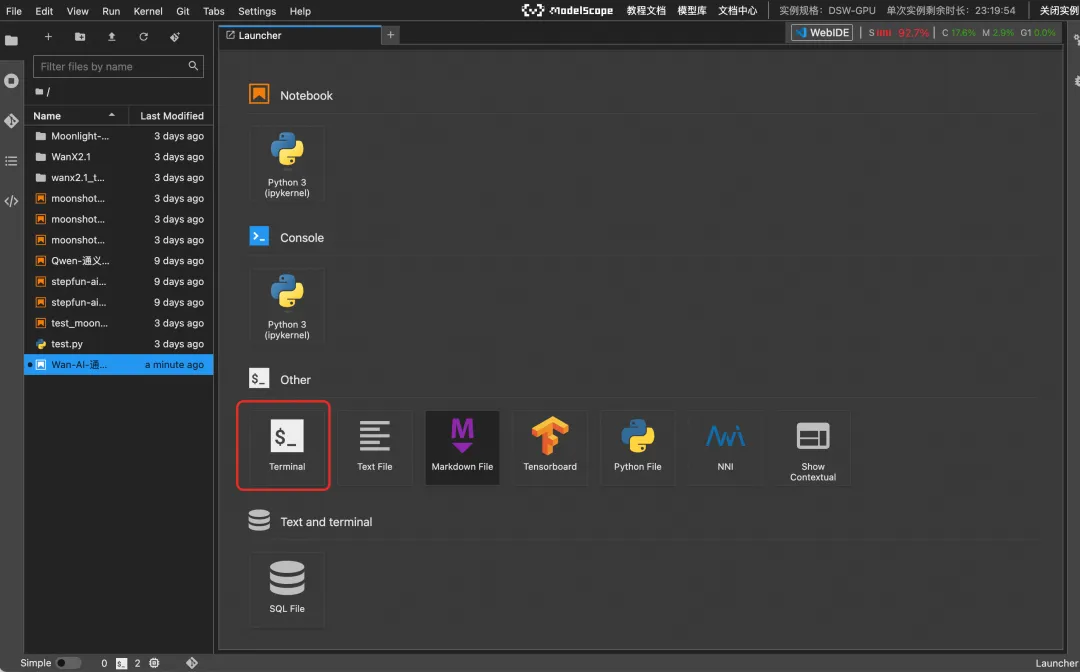
1、打开Notebook终端
在页面中选择Terminal
2、克隆ComfyUI仓库
在Notebook终端中运行如下命令,将官方的ComfyUI的仓库克隆下来:
git clone https://github.com/comfyanonymous/ComfyUI.git

克隆过程中可能遇到这个报错,提示“RPC失败”:


这是因为http协议版本的问题导致网络连接失败,版本降低至1.1即可解决。命令如下:
git config --global http.version HTTP/1.1
git clone https://github.com/comfyanonymous/ComfyUI.git
git config --global http.version HTTP/2
完成的界面像这样:


3、安装依赖
使用pip安装运行ComfyUI服务所需的环境依赖:
cd ComfyUI
pip install -r requirements.txt
4、验证安装
运行以下命令启动ComfyUI服务,测试是否成功安装。
python main.py
如果服务成功启动,将在终端中看到http://127.0.0.1:8188的提示
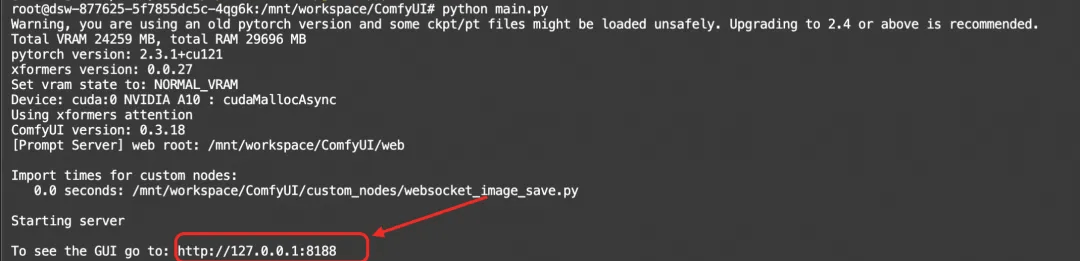
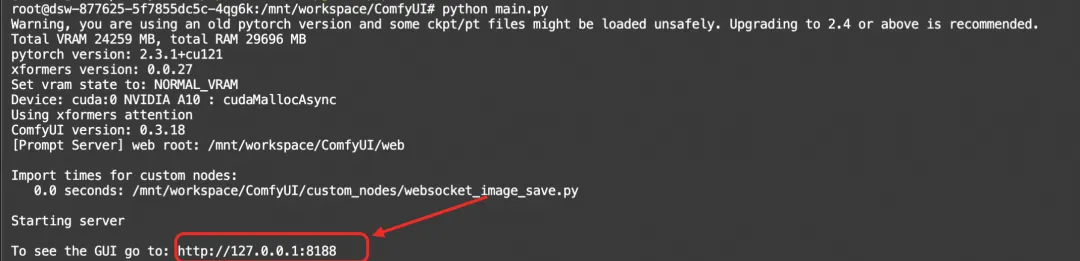
点击这个链接就可以进入comfyui的界面啦!
step3 文生视频工作流
以通义万相wan2.1-t2v-1.3b文生视频模型为例,演示如何运行工作流。
1、下载模型
wan2.1-t2v-1.3b文生视频模型包含3个组件,文本编码器、扩散模型和视频解码器。我们需要从魔搭模型库中下载3个组件对应的模型文件,并将这些模型文件放置到对应文件夹:
-
文本编码器:
-
split_files/text_encoders/umt5_xxl_fp16.safetensors →ComfyUI/models/text_encoders
-
-
扩散模型
-
split_files/diffusion_models/wan2.1_t2v_1.3B_bf16.safetensors → ComfyUI/models/diffusion_models
-
-
视频解码器
-
split_files/vae/wan_2.1_vae.safetensors → ComfyUI/models/vae
-
命令行如下:
# 文本编码器
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/text_encoders/umt5_xxl_fp16.safetensors --local_dir ./models/text_encoders/
# 扩散模型
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/diffusion_models/wan2.1_t2v_1.3B_bf16.safetensors --local_dir ./models/diffusion_models/
# 视频解码器
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/vae/wan_2.1_vae.safetensors --local_dir ./models/vae/2、启动comfyui
运行以下命令启动ComfyUI服务:
python main.py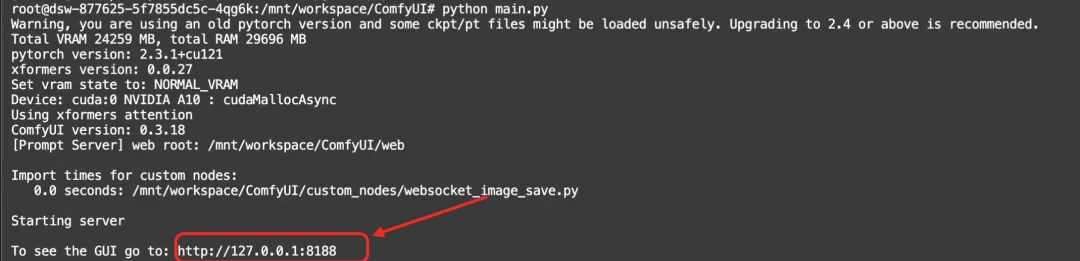
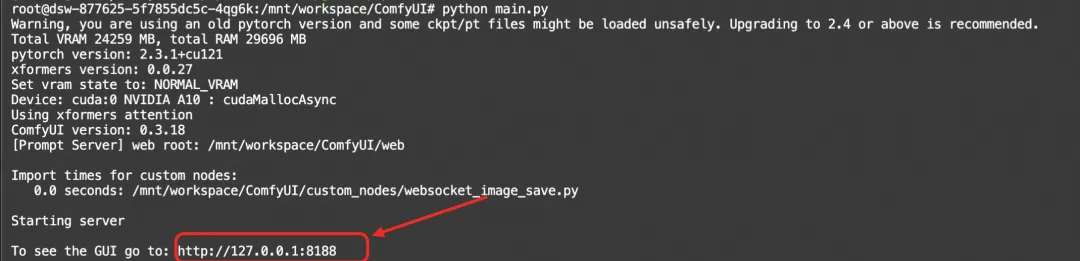
点击http://127.0.0.1:8188链接进入comfyui的界面
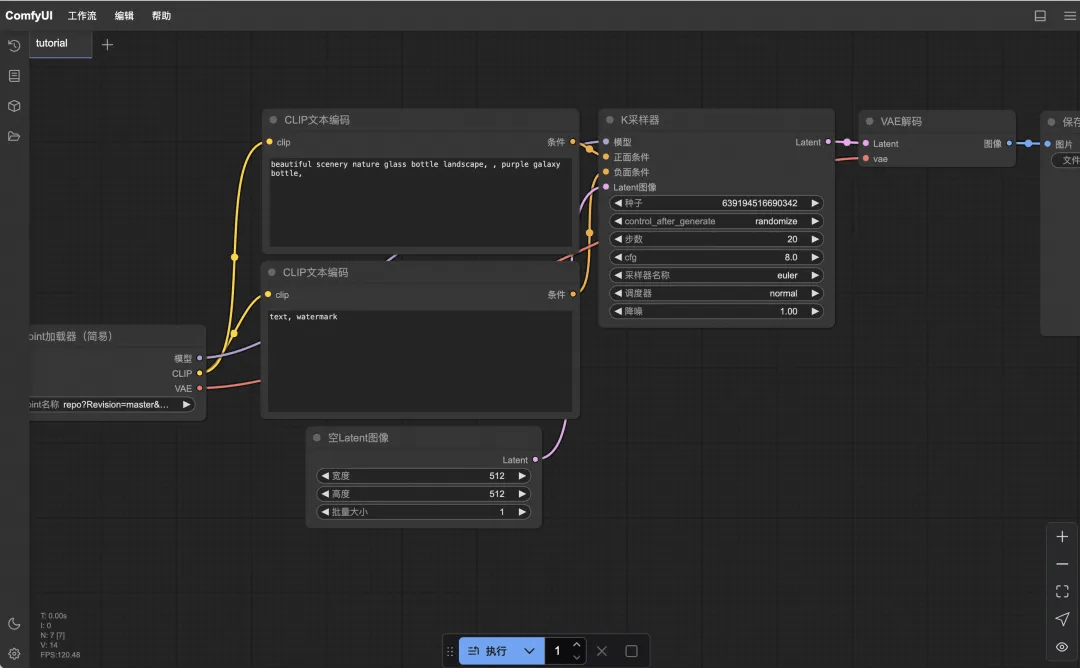
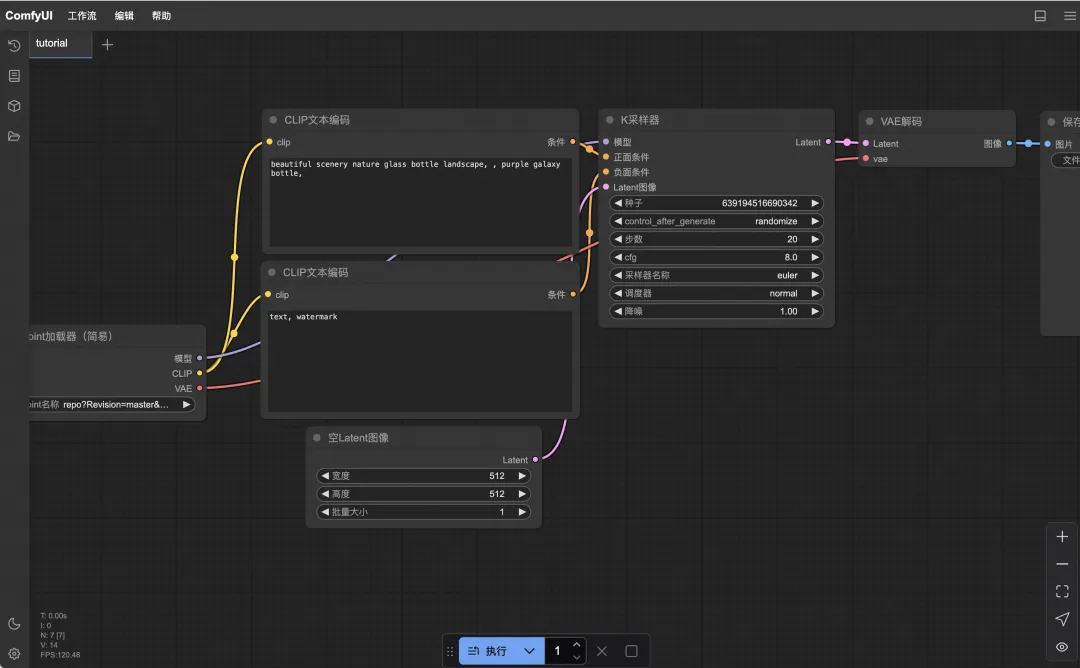
3、运行文生视频工作流
ComfyUI启动后会自动打开一个默认的工作流,可以不用管它。我们需要下载wan2.1的示例工作流文件,然后将文件拖入ComfyUI界面。
wan2.1的示例工作流文件:
https://modelscope.cn/notebook/share/ipynb/5eee8a46/text_to_video_wan.ipynb
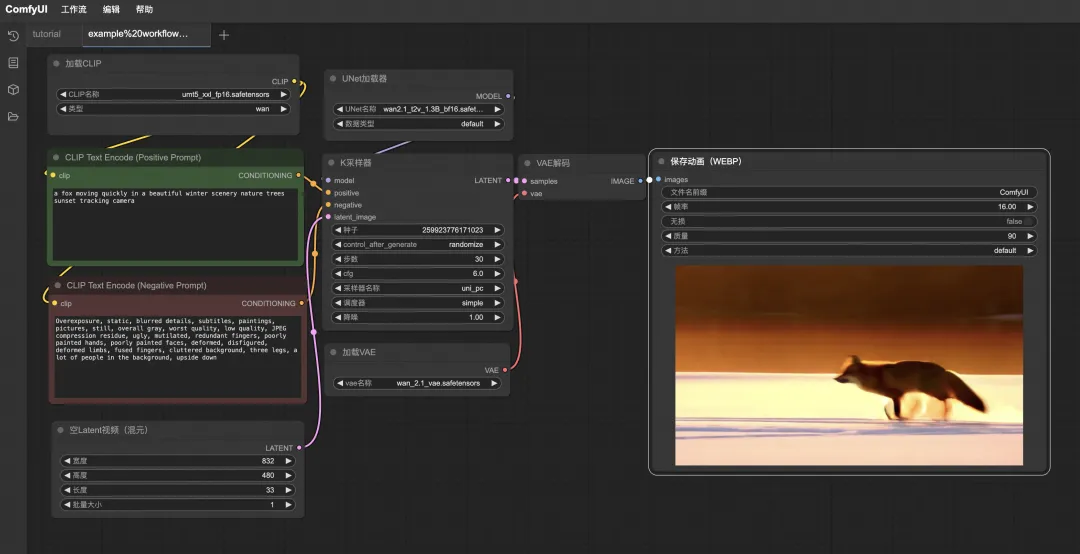
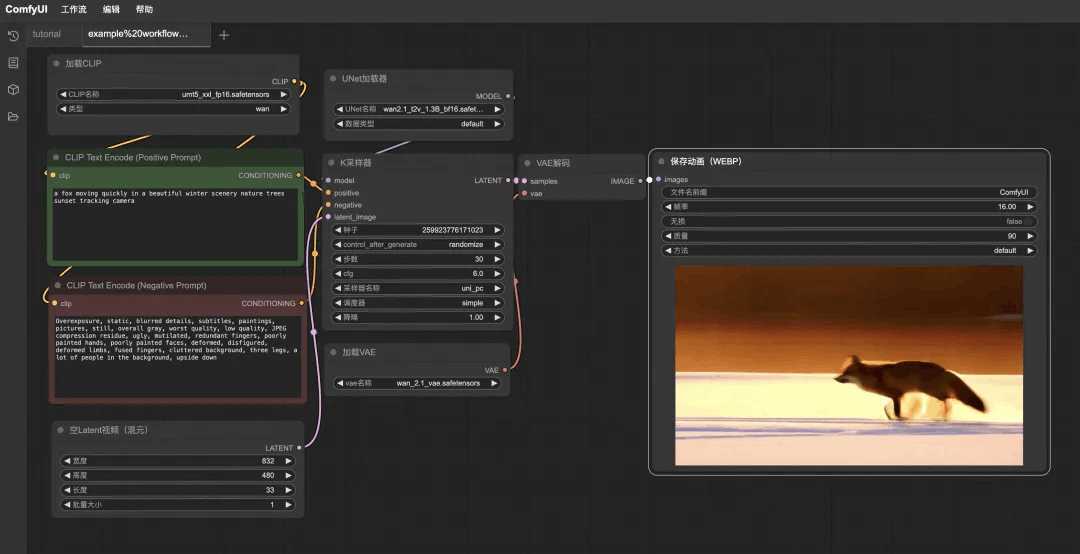
拖入后在界面中就可以看到工作流的样子,分别点击三个模型的下拉选项,检查一下模型文件是否存在,再点击“执行”开始视频生成。
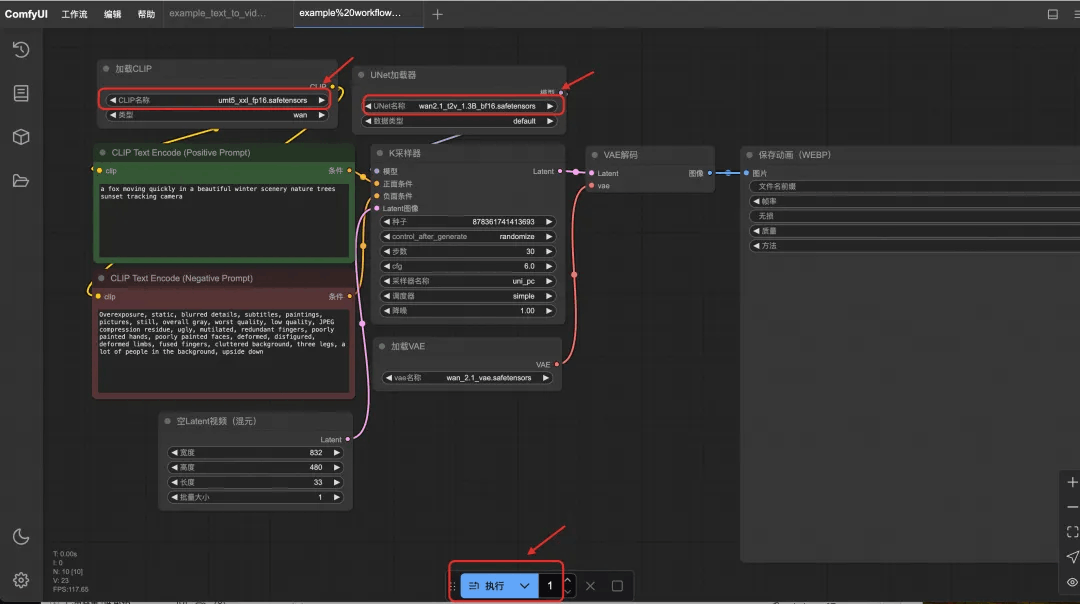
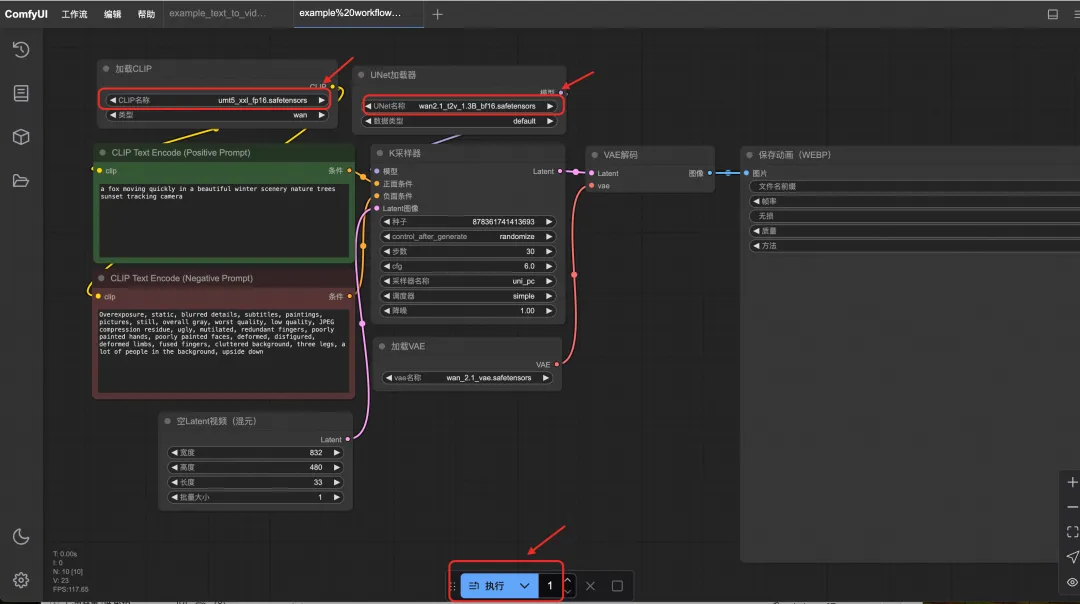
视频生成完成之后的页面:
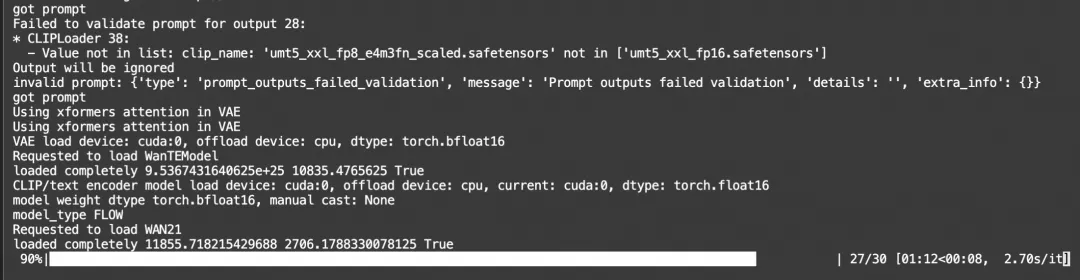
4、运行日志查看
终端界面上可以查看实时运行的日志:
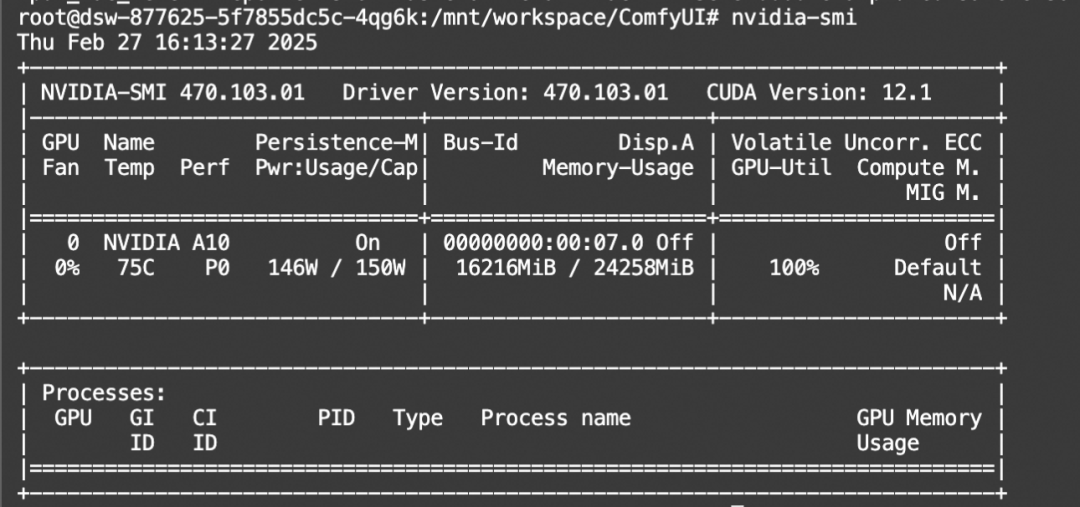
nvidia-smi命令可以查看显存占用:
02.本地搭建ComfyUI图生视频工作流
如果你自己拥有GPU,则可以选择在本地部署工作流。本节以通义万相wan2.1-i2v-14b的图生视频模型为例,教你一步步用命令行运行图生视频的工作流。
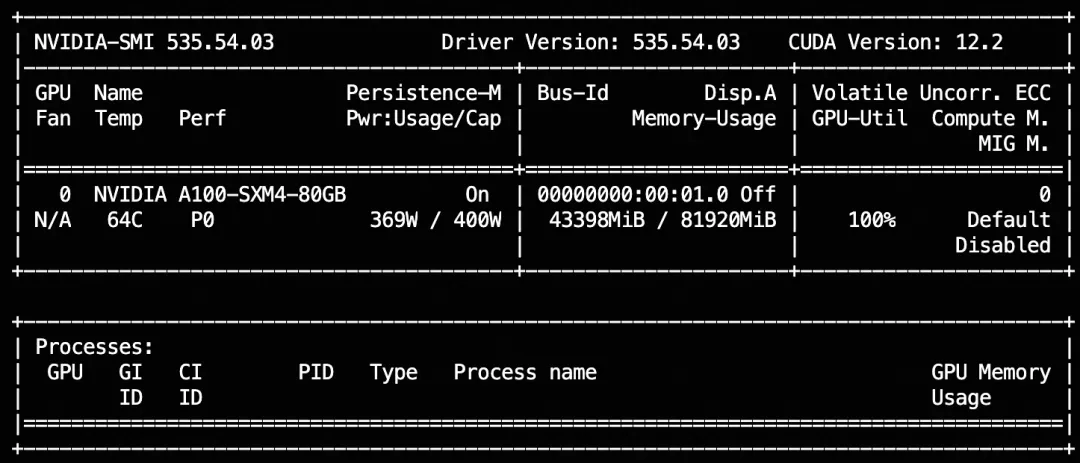
step1 检查显卡信息
要运行万相wan2.1-i2v-14b文生视频ComfyUI工作流,需要高规格的显卡。生成512*512大小的视频,显存大约需要44G;生成1280*720尺寸的视频,显存需要53GB。运行nvidia-smi命令,检查显卡是否符合要求。

step2 安装ComfyUI及其依赖
此步骤同上,请查阅上一节step2。
step3 图生视频工作流
1、模型下载
wan2.1-i2v-1.3b文生视频模型包含4个组件,图片编码器、文本编码器、视频扩散模型和视频解码器。我们需要从魔搭模型库中下载4个组件对应的模型文件,并将这些模型文件放置到对应文件夹:
-
图片编码器
-
split_files/clip_vision/clip_vision_h.safetensors →ComfyUI/models/clip_vision
-
-
文本编码器
-
split_files/text_encoders/umt5_xxl_fp16.safetensors →ComfyUI/models/text_encoders
-
-
视频扩散模型
-
split_files/diffusion_models/wan2.1_i2v_720p_14B_bf16.safetensors → ComfyUI/models/diffusion_models
-
-
视频解码器
-
split_files/vae/wan_2.1_vae.safetensors → ComfyUI/models/vae
-
命令行如下:
# 图片编码器
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/clip_vision/clip_vision_h.safetensors --local_dir ./models/clip_vision/
# 文本编码器
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/text_encoders/umt5_xxl_fp16.safetensors --local_dir ./models/text_encoders/
# 视频扩散模型
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/diffusion_models/wan2.1_i2v_720p_14B_bf16.safetensors --local_dir ./models/diffusion_models/
# 视频解码器
modelscope download --model Comfy-Org/Wan_2.1_ComfyUI_repackaged --include split_files/vae/wan_2.1_vae.safetensors --local_dir ./models/vae/2、启动comfyui
运行以下命令启动ComfyUI服务:
python main.py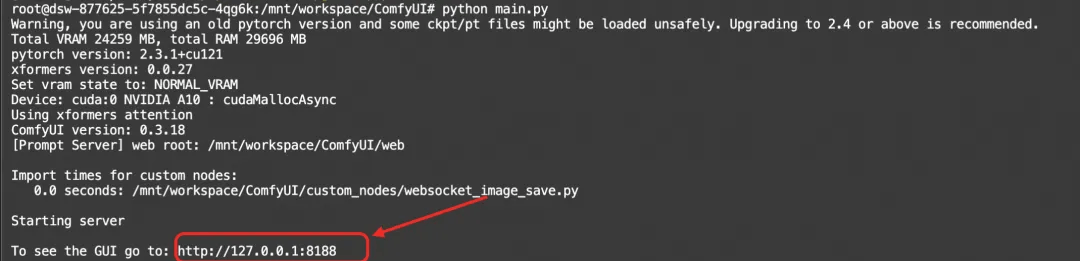
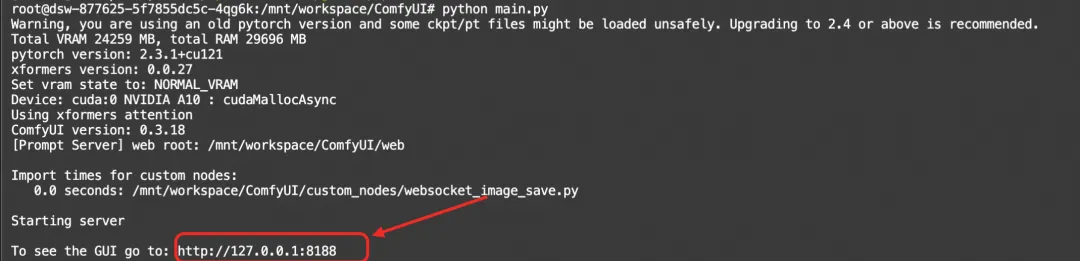
点击http://127.0.0.1:8188链接就可以进入comfyui的界面
3、上传工作流运行
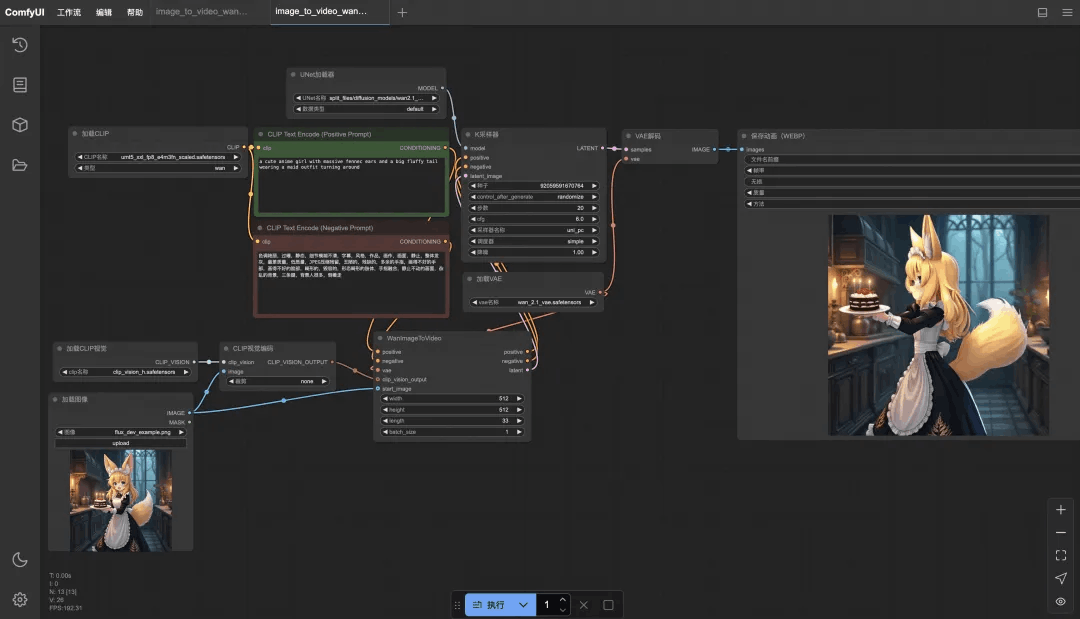
下载wan2.1的图生视频示例工作流文件,然后将文件拖入ComfyUI界面。
wan2.1的示例工作流文件:
https://modelscope.cn/notebook/share/ipynb/0e5bbc8b/image_to_video_wan_example.ipynb
拖入后在界面中就可以看到工作流的样子,分别点击三个模型的下拉选项,检查一下模型文件是否存在,再点击“执行”开始视频生成。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 2
2 3
3- 0



 已为社区贡献662条内容
已为社区贡献662条内容

所有评论(0)