
通义万相Wan2.1视频模型开源!视频生成模型新标杆,支持中文字效+高质量视频生成
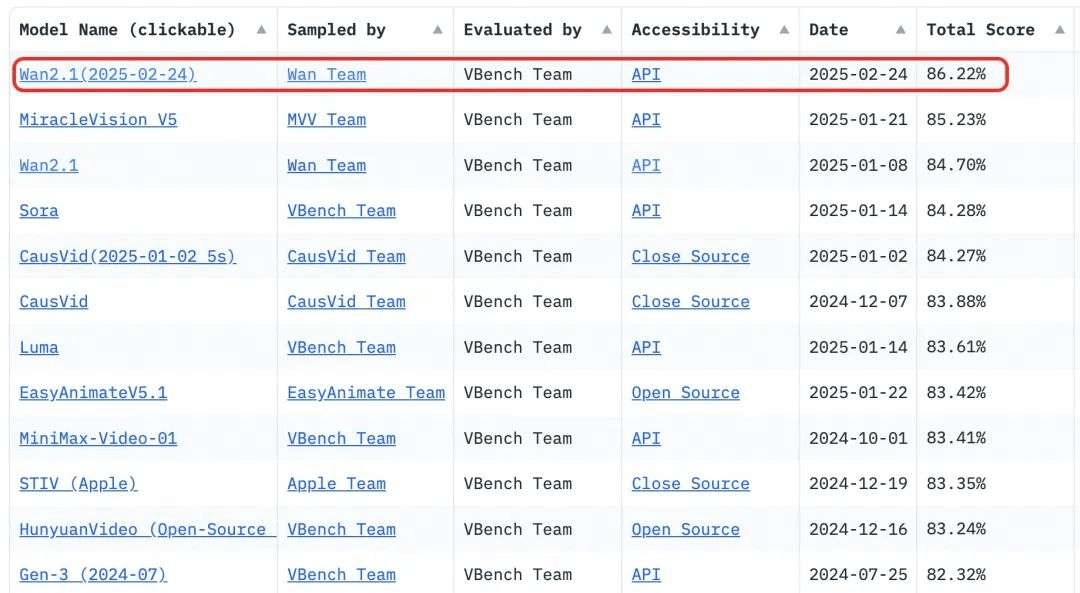
2025年1月,阿里通义万相Wan2.1模型登顶Vbench榜首第一,超越Sora、HunyuanVideo、Minimax、Luma、Gen3、Pika等国内外视频生成模型。而在今天,万相Wan2.
前言
2025年1月,阿里通义万相Wan2.1模型登顶Vbench榜首第一,超越Sora、HunyuanVideo、Minimax、Luma、Gen3、Pika等国内外视频生成模型。而在今天,万相Wan2.1视频生成大模型正式开源!
Github:
https://github.com/Wan-Video
模型:
https://modelscope.cn/organization/Wan-AI
截止到目前,Wan2.1在vbench榜单中仍处在榜首位置。
01.模型生成效果
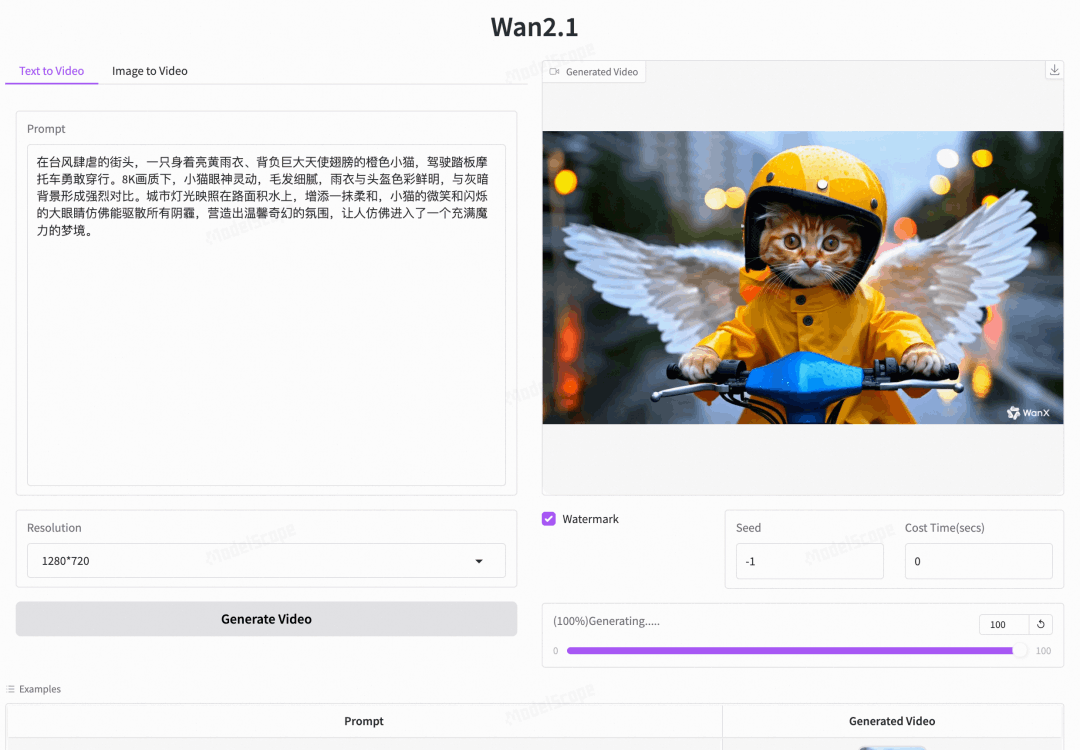
万相Wan2.1是首个具备支持中文文字生成能力,且同时支持中英文文字特效生成的视频生成模型。用户只需输入简短的文字描述,即可生成具有电影级效果的文字和动画。支持多种场景下的字体应用,包括特效字体、海报字体以及真实场景中的字体展示,满足各种专业需求。
https://live.csdn.net/v/465537
以红色新年宣纸为背景,出现一滴水墨,晕染墨汁缓缓晕染开来。文字的笔画边缘模糊且自然,随着晕染的进行,水墨在纸上呈现“福”字,墨色从深到浅过渡,呈现出独特的东方韵味。背景高级简洁,杂志摄影感。
https://live.csdn.net/v/465538
视频展示了令人捧腹的一幕:一只橘色的猫咪站在厨房的桌子前,宛如一位经验丰富的厨师。它身着专业的厨师装备——一件可爱的围裙,围裙上醒目地绣着中文“猫大师”,仿佛在宣告它的烹饪大师身份。猫咪用爪子灵活地拿着面团搓,动作滑稽但专注认真,让人忍俊不禁。厨房背景整洁明亮,台面上摆放着各种厨具和食材。镜头从侧面捕捉到猫咪的每一个细微动作,特写镜头展现了它认真的表情。近景动态画面,充满趣味性和创意。
万相Wan2.1已上线魔搭社区创空间,可以直接体验
DEMO:
https://modelscope.cn/studios/Wan-AI/Wan-2.1
02.Wan2.1的技术创新
万相大模型架构是主流的DiT,基于线性噪声轨迹Flow Matching范式训练,通过两个重要的技术创新实现了生成能力的大幅提升。
(一)特征缓存机制实现高效VAE
为了高效支持任意长度视频的编码和解码,万相在3D VAE的因果卷积模块中实现了特征缓存机制,从而代替直接对长视频端到端的编解码过程。这使显存的使用仅与Chunk大小相关而与原始视频长度无关,从而实现无限长1080P视频的高效编解码。
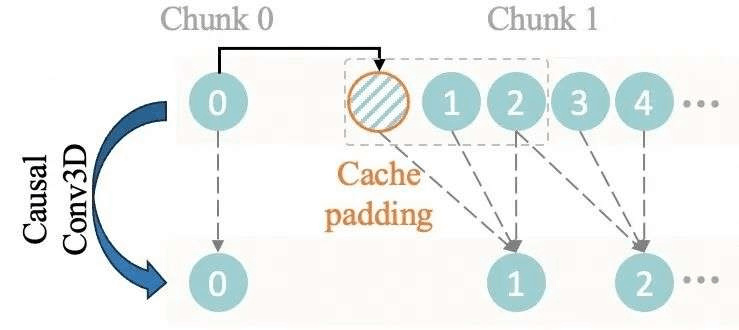
特征缓存机制
实验结果表明,万相的视频VAE在各项指标上均表现出极具竞争力的性能,展现出卓越视频质量和高处理效率的双重优势。下图展示了不同VAE模型的模型计算效率和视频压缩重构指标的结果以及对应可视化对比,可以看到万相VAE在较小的模型参数下,实现了业内领先的视频压缩重构质量。
值得注意的是,在相同的硬件环境(单个A800 GPU)下,Wan2.1的VAE重建速度比现有的最先进方法(如HunYuanVideo)快2.5倍。由于Wan2.1的VAE模型小尺寸设计和特征缓存机制,这种速度优势在更高分辨率下将更加明显。
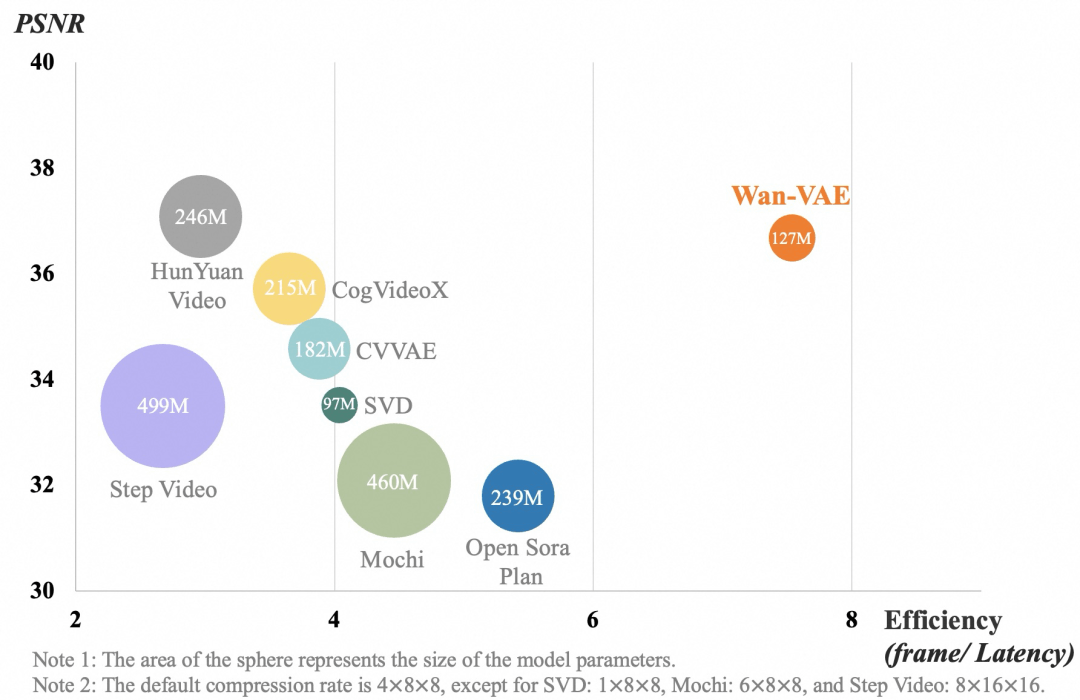
万相视频VAE和其他VAE对比
(二)共享时间步特征映射实现高效视频DiT
万相模型架构基于主流的视频DiT结构,整体训练则采用了线性噪声轨迹的流匹配(Flow Matching)方法。关键的是,万相通过一组在所有Transformer Block中共享参数的MLP,将输入的时间步特征T映射为模型中AdaLN层的可学习缩放与偏置参数。实验证明在相同的参数规模下,这种共享时间步特征映射层参数的方法在保持模型能力同时可以显著降低参数和计算量。
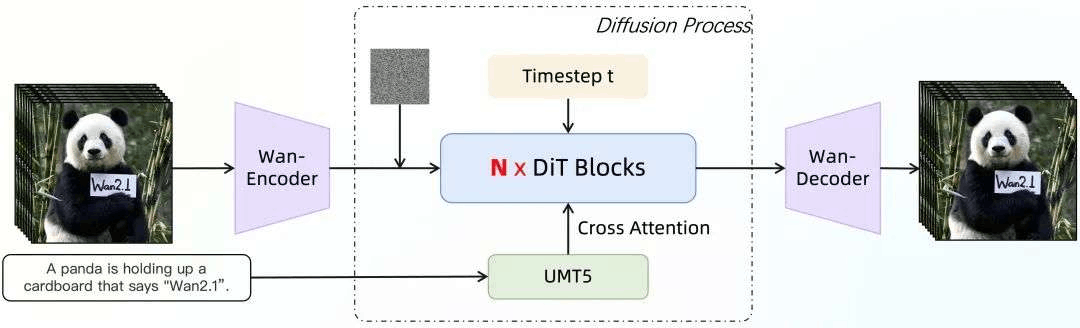
万相视频模型架构图
数据精制和训练流程
万相构建了O(1)B量级视频和 O(10)B量级图像的训练数据集,这些数据来源于内部版权资源和公开数据集,同时设计了一个四步数据清洗流程,重点关注基础维度、视觉质量和运动质量。对应的整个预训练过程也分为四个阶段,每个阶段逐渐增加分辨率和视频时长,让模型在一定算力限制下得到更充分的训练。最终的SFT阶段,进行了更严格的数据过滤,保障模型稳定收敛到高质量视频输出。
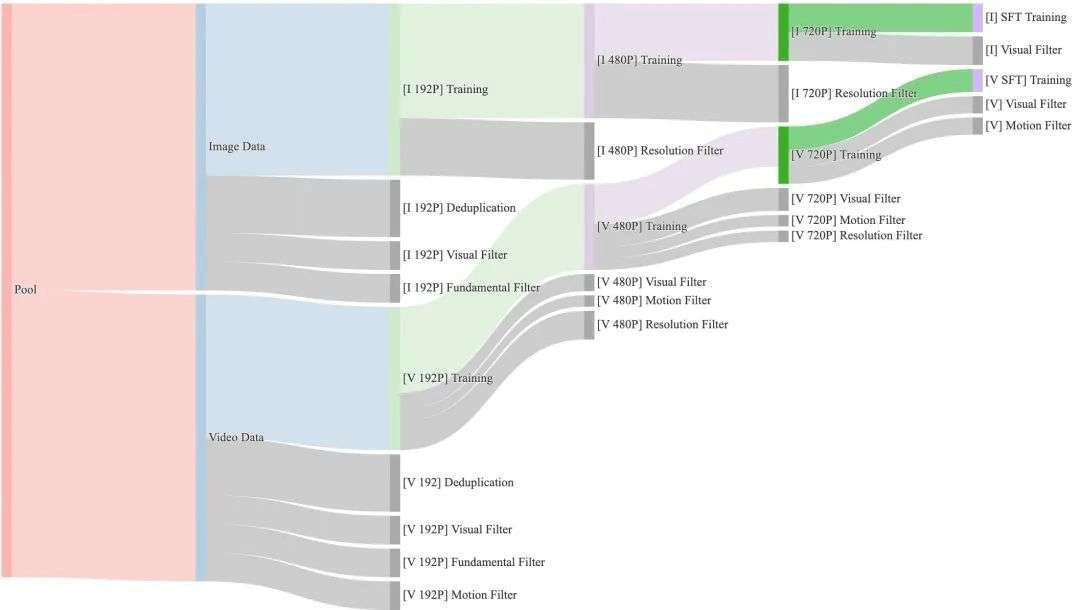
数据清洗流程
全系列模型开源
万相团队开源全部推理代码和权重,包括两种尺寸的模型,1.3B参数的极速版和14B参数的专业版。即使是1.3B参数的极速版,其度量结果不仅超过了更大尺寸的开源模型,甚至还和一些闭源的模型结果接近。推理仅需8.19GB显存进行推理,可在消费级显卡上使用。其他不同参数量的模型,在不同GPU卡型上的推理耗时(秒)和显存消耗可以在下面的表格中查看。
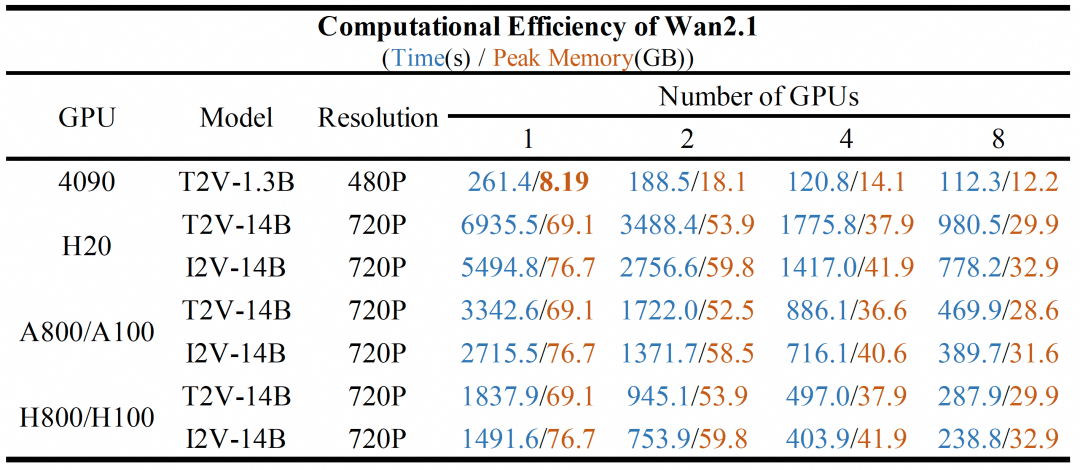
Wan2.1系列模型在不同GPU配置上推理性能
03.模型推理与训练定制
魔搭社区的DiffSynth-Studio项目是社区针对AIGC模型生态,提供的全链路的推理和训练优化的开源工具(https://github.com/modelscope/DiffSynth-Studio)。
本次DiffSynth-Studio也第一时间为Wan2.1系列模型提供了全面支持。
详细信息可参考:
https://github.com/modelscope/DiffSynth-Studio/tree/main/examples/wanvideo
安装
通过以下命令可下载并安装 DiffSynth-Studio:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .模型下载
modelscope download --model Wan-AI/Wan2.1-T2V-1.3B --local_dir ./models/Wan-AI/Wan2.1-T2V-1.3B
modelscope download --model Wan-AI/Wan2.1-T2V-14B --local_dir ./models/Wan-AI/Wan2.1-T2V-14B
modelscope download --model Wan-AI/Wan2.1-I2V-14B-480P --local_dir ./models/Wan-AI/Wan2.1-I2V-14B-480P
modelscope download --model Wan-AI/Wan2.1-I2V-14B-720P --local_dir ./models/Wan-AI/Wan2.1-I2V-14B-720P模型推理
1.3B 模型
运行 1.3B 文生视频模型的代码(提示词等参数可在代码文件中进行修改):
python examples/wanvideo/wan_1.3b_text_to_video.py1.3B 模型需要 6G 显存即可运行。
14B 模型
运行 14B 文生视频和图生视频模型的代码:
python examples/wanvideo/wan_14b_text_to_video.py
python examples/wanvideo/wan_14b_image_to_video.py对于 14B 的模型,由于模型参数量较大,我们在DiffSynth里默认开启了 FP8 量化,24G 显存即可运行。此外,DiffSynth提供了显存管理技术,可以通过控制代码中的 num_persistent_param_in_dit参数,来平衡显存需求和计算速度。该参数越大,计算速度越快,对应需要的显存也越多。用户可根据自己的设备配置,来选择合适的参数,具体参数可在上述脚本中调整。以下是我们在 A100 单卡上实测的结果:
|
torch_dtype |
num_persistent_param_in_dit |
计算速度 |
显存需求 |
默认设置 |
|
torch.bfloat16 |
None |
18.5s/it |
40G |
|
|
torch.bfloat16 |
7000000000 |
20.8s/it |
24G |
|
|
torch.bfloat16 |
0 |
23.4s/it |
10G |
|
|
torch.float8_e4m3fn |
None |
18.3s/it |
24G |
✅ |
|
torch.float8_e4m3fn |
0 |
24.0s/it |
10G |
|
此外DiffSynth里面也全面支持了Wan2.1的图生视频模型,具体可以参见https://github.com/modelscope/DiffSynth-Studio/tree/main/examples/wanvideo 目录下的i2v范例。
模型微调训练(LoRA)
DiffSynth-Studio 同时也提供了Wan2.1系列模型的 LoRA 微调训练支持。以Wan 文生视频1.3B为例,开发者可按以下步骤进行微调训练。
第一步:安装额外依赖包。
pip install peft lightning pandas第二步:按以下格式整理视频数据集文件。
data/example_dataset/
├── metadata.csv
└── train
├── video_00001.mp4
└── video_00002.mp4其中的 metadata.csv中保存了每个视频的文本描述,格式如下:
file_name,text
video_00001.mp4,"video description"
video_00001.mp4,"video description"第三步:启动数据处理进程,如果数据量过大,可通过修改 CUDA_VISIBLE_DEVICES来开启多卡并行处理。
CUDA_VISIBLE_DEVICES="0" python examples/wanvideo/train_wan_t2v.py \
--task data_process \
--dataset_path data/example_dataset \
--output_path ./models \
--text_encoder_path "models/Wan-AI/Wan2.1-T2V-1.3B/models_t5_umt5-xxl-enc-bf16.pth" \
--vae_path "models/Wan-AI/Wan2.1-T2V-1.3B/Wan2.1_VAE.pth" \
--tiled \
--num_frames 81 \
--height 480 \
--width 832数据处理完毕后,文件列表如下。其中的 .pth文件为模型处理得到的中间变量,对于存在长度过短、无法读取等问题的视频,无对应的 .pth文件生成。
data/example_dataset/
├── metadata.csv
└── train
├── video_00001.mp4
├── video_00001.mp4.tensors.pth
├── video_00002.mp4
└── video_00002.mp4.tensors.pth第四步:开始训练,如果有多个 GPU,可通过修改 CUDA_VISIBLE_DEVICES来开启多卡并行训练。
CUDA_VISIBLE_DEVICES="0" python examples/wanvideo/train_wan_t2v.py \
--task train \
--dataset_path data/example_dataset \
--output_path ./models \
--dit_path "models/Wan-AI/Wan2.1-T2V-1.3B/diffusion_pytorch_model.safetensors" \
--steps_per_epoch 500 \
--max_epochs 10 \
--learning_rate 1e-4 \
--lora_rank 4 \
--lora_alpha 4 \
--lora_target_modules "q,k,v,o,ffn.0,ffn.2" \
--accumulate_grad_batches 1 \
--use_gradient_checkpointing第五步:测试 LoRA 模型的效果,将 LoRA 模型文件的路径填入以下代码中,即可运行测试 LoRA 模型的效果。
import torch
from diffsynth import ModelManager, WanVideoPipeline, VideoData, save_video
model_manager = ModelManager(torch_dtype=torch.bfloat16, device="cpu")
model_manager.load_models([
"models/Wan-AI/Wan2.1-T2V-1.3B/diffusion_pytorch_model.safetensors",
"models/Wan-AI/Wan2.1-T2V-1.3B/models_t5_umt5-xxl-enc-bf16.pth",
"models/Wan-AI/Wan2.1-T2V-1.3B/Wan2.1_VAE.pth",
])
model_manager.load_lora("models/lightning_logs/version_1/checkpoints/epoch=0-step=500.ckpt", lora_alpha=1.0)
pipe = WanVideoPipeline.from_model_manager(model_manager, device="cuda")
pipe.enable_vram_management(num_persistent_param_in_dit=None)
# Text-to-video
video = pipe(
prompt="...",
negative_prompt="...",
num_inference_steps=50,
seed=0, tiled=True
)
save_video(video, "video_with_lora.mp4", fps=30, quality=5)点击链接直达体验~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献662条内容
已为社区贡献662条内容

所有评论(0)