
PromptScope: 一个灵活高效的In-Context Training框架
PromptScope 是一个同时支持中英文的 In-Context Training 框架,专为大型语言模型(LLM)性能调优设计。
01.项目简介
PromptScope 是一个同时支持中英文的 In-Context Training 框架,专为大型语言模型(LLM)性能调优设计。In-Context Training 通过调整模型输入(Instruction/样例),优化模型在特定任务中的表现。相比于 In-Weight Training(如 SFT、DPO、RLHF),PromptScope 具有低成本和更高的灵活性。
- 适用场景包括
-
缺乏可用于训练的 GPU 资源
-
需要对闭源模型进行性能优化
- PromptScope 的主要特点
-
全面的优化方法:支持基于样例的优化和基于指令的优化
-
卓越的优化效果:基于TipsOptimizer的方法在中英文开源数据集上效果优于主流优化算法
-
高度的灵活性:支持中英文并且提供主流优化算法实现
- 关于TipsOptimizer
-
TipsOptimizer是通过从训练集中根据正负样例,总结出一些Tips,添加到原始system prompt中,来帮助模型提升在指定任务上的表现,只需要提供“训练数据”和“评分函数”,就可以进行优化。以下是一个例子,对比展示优化前后的system prompt:
|
优化前 |
请判断下面的新闻属于以下哪个类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐 |
|
优化后 |
请判断下面的新闻属于以下哪个类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐- 当新闻内容主要涉及特定领域的科技进步或科学研究时,建议将其分类为“科技”,不建议简单地因为提及国家机构或政策就归类为“时政”。- 在判断新闻类别时,应重点关注文章的主要信息和核心主题,而不是被次要信息所干扰。- 对于跨领域的内容,需要仔细区分主次,确保将新闻准确归入最能反映其主要内容的类别。- 当新闻内容涉及金融产品(如基金)的整体市场表现及行业内部结构变化时,建议归类为“财经”,不建议仅因提及股市就将其分类为“股票”。...(红色部分为新增Tips) |
欢迎关注PromptScope,在Github上(https://github.com/modelscope/promptscope) 为我们star 🌟。
02.项目结构
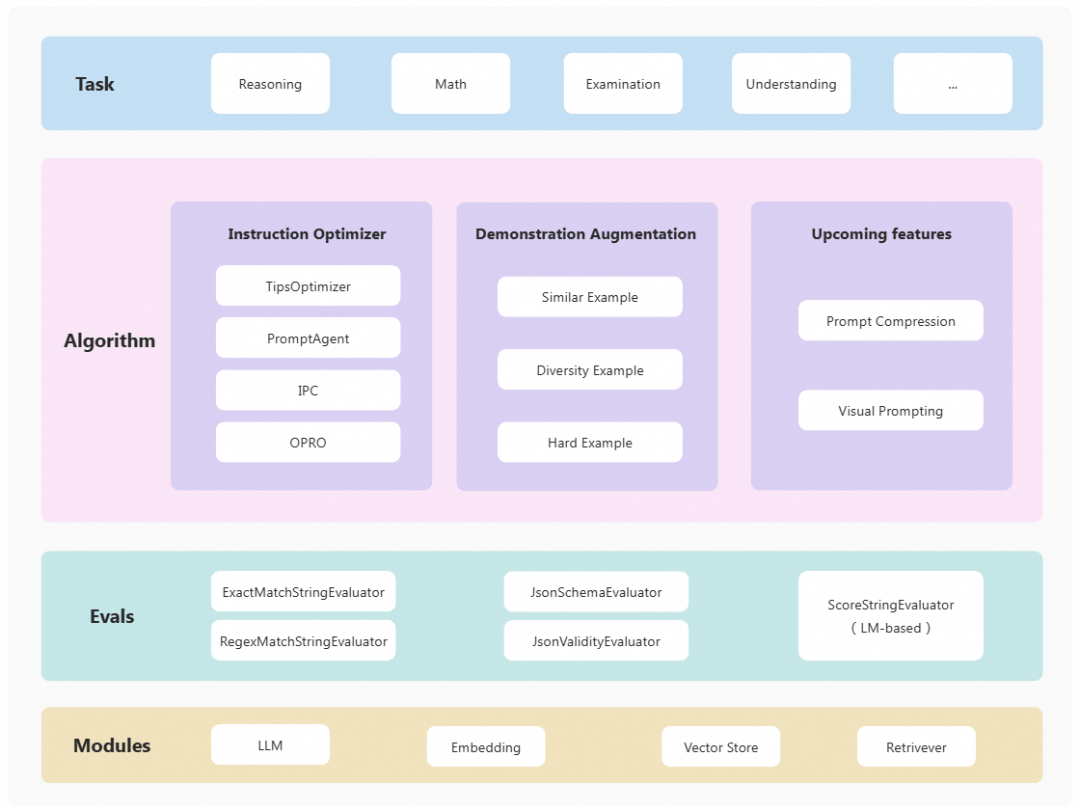
03.效果对比
● 优化器:qwen-max
● 推理模型:qwen-plus
|
|
英文 |
中文 |
|
|
|
|
|
|
GSM8K |
BBH(word_sorting) |
BBH(object_counting) |
THUNews |
CMMLU(nutrition) |
CMMLU(college_medical_statistics) |
|
Raw |
96.1% |
57.0% |
97.0% |
85.0% |
93.2% |
73.6% |
|
OPRO |
96.3% |
56.0% |
97.0% |
84.0% |
90.4% |
75.5% |
|
PromptAgent |
95.7% |
60.0% |
97.0% |
80.8% |
95.9% |
71.7% |
|
TipsOptimizer |
96.1% |
64.0% |
98.0% |
90.0% |
95.9% |
83.0% |
04.运行方式
-
步骤一:开通DashScope平台模型调用权限
-
具体开通和获取DashScope API-KEY的方式可参考:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key?spm=a2c4g.11186623.0.0.97dc6d52Otm9R1
-
步骤二:下载PromptScope仓库
git clone https://github.com/modelscope/PromptScope-
步骤三:配置DashScope API-KEY
export DASHSCOPE_API_KEY="sk-xxxxx"-
步骤四:加载训练和测试数据
with open("../../data/college_medical_statistics/sample_train_data.jsonl", "r") as f:
train_set = []
for line in f:
train_set.append(json.loads(line))
with open("../../data/college_medical_statistics/sample_test_data.jsonl", "r") as f:
test_set = []
for line in f:
test_set.append(json.loads(line))
with open("../../data/college_medical_statistics/init_system_prompt.txt", "r") as f:
init_system_prompt = f.read().strip()-
以下是训练/测试数据格式的组织形式:
[
{
"input": "输入(必填)",
"output": "回复(必填)"
}
]-
步骤五:构建评分函数
def is_good_case(prediction, ground_truth):
# extract final answer
prediction = prediction.split("<answer>")[-1].split("</answer>")[0].strip()
ground_truth = ground_truth
if ground_truth in prediction:
return True, 1 # good case, 得分为1
else:
return False, 0 # bad case, 得分为1-
步骤六:开始运行
from prompt_scope.core.llms.dashscope_llm import DashscopeLLM
from prompt_scope.core.offline.tips_generation.static_tips_generation import StaticTipsGeneration
# 加载推理模型
infer_llm = DashscopeLLM(model="qwen-plus", temperature=0.0)
# 加载优化模型
optim_llm = DashscopeLLM(model="qwen-max", temperature=0.0)
# 运行代码
stg = StaticTipsGeneration(
init_system_prompt=init_system_prompt,
infer_llm=infer_llm,
train_set=train_set,
test_set=test_set,
is_good_case_func=is_good_case,
details_save_dir=f"{current_file_dir}/details_result",
language="cn"
)
tips = stg.run()05.后续计划
-
更多模型支持(基于api/本地部署)
-
支持多模态In-Context Training方式
-
更多Optimizer方式,也欢迎大家共建
欢迎关注PromptScope,在Github上(https://github.com/modelscope/promptscope) 为我们star 🌟。
点击链接阅读原文,即可跳转模型代码

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献643条内容
已为社区贡献643条内容

所有评论(0)