
王炸组合,阶跃星辰SOTA模型Step-Video和Step-Audio模型开源
2025 年 2 月 18 号,阶跃星辰宣布开源了两款 Step 系列多模态模型——Step-Video-T2V 视频生成模型和 Step-Audio 语音交互模型。
01.前言
2025 年 2 月 18 号,阶跃星辰宣布开源了两款 Step 系列多模态模型——Step-Video-T2V 视频生成模型和 Step-Audio 语音交互模型。
技术报告:
-
https://arxiv.org/pdf/2502.10248
-
https://github.com/stepfun-ai/Step-Audio/blob/main/assets/Step-Audio.pdf
开源链接:
-
https://github.com/stepfun-ai/Step-Video-T2V
-
https://github.com/stepfun-ai/Step-Audio
模型链接:
-
stepvideo-t2v: https://www.modelscope.cn/collections/stepvideo-t2v--wenshengshipin-238aa2a1985d40
-
Step-Audio: https://www.modelscope.cn/collections/Step-Audio-a47b227413534a
Step-Video-T2V:性能领跑全球开源视频生成大模型
这是一个最先进的 (SoTA) 文本转视频预训练模型,具有 300 亿个参数,能够生成高达 204 帧的视频。为了提高训练和推理效率,阶跃提出了一种用于视频的深度压缩 VAE,实现了 16x16 空间和 8 倍时间压缩比。在最后阶段应用直接偏好优化 (DPO) 来进一步提高生成视频的视觉质量。Step-Video-T2V 的性能在一个新的视频生成基准Step-Video-T2V-Eval上进行评估,展示了其 SoTA 文本生成视频质量。
模型亮点:
在 Step-Video-T2V 中,视频由高压缩 Video-VAE 表示,可实现 16x16 空间和 8x 时间压缩比。用户提示使用两个双语预训练文本编码器进行编码,以处理英语和中文。使用流匹配训练具有 3D 全注意力的 DiT,并将其用于将输入噪声降噪到潜在帧中,其中文本嵌入和时间步长作为条件因素。为了进一步提高生成视频的视觉质量,应用了基于视频的 DPO 方法,该方法可有效减少伪影并确保更流畅、更逼真的视频输出。
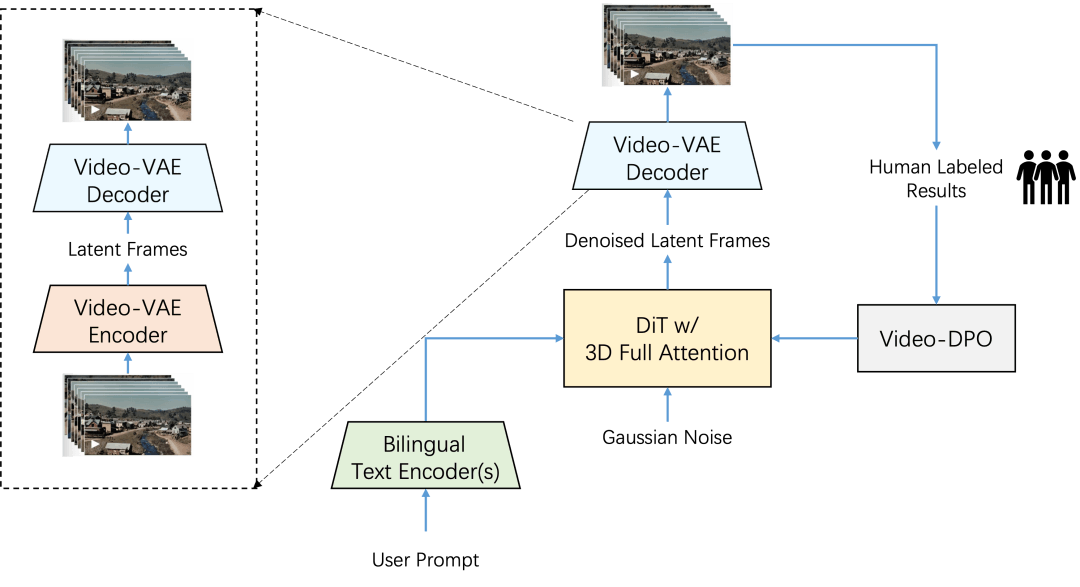
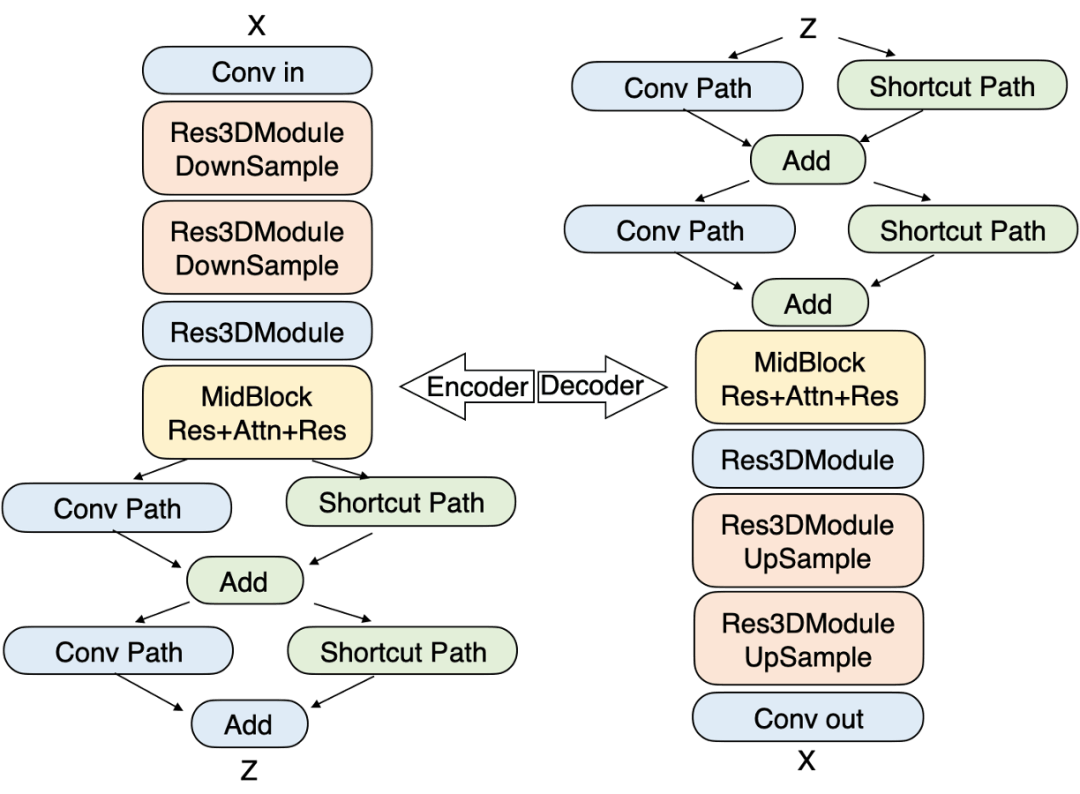
视频 VAE:
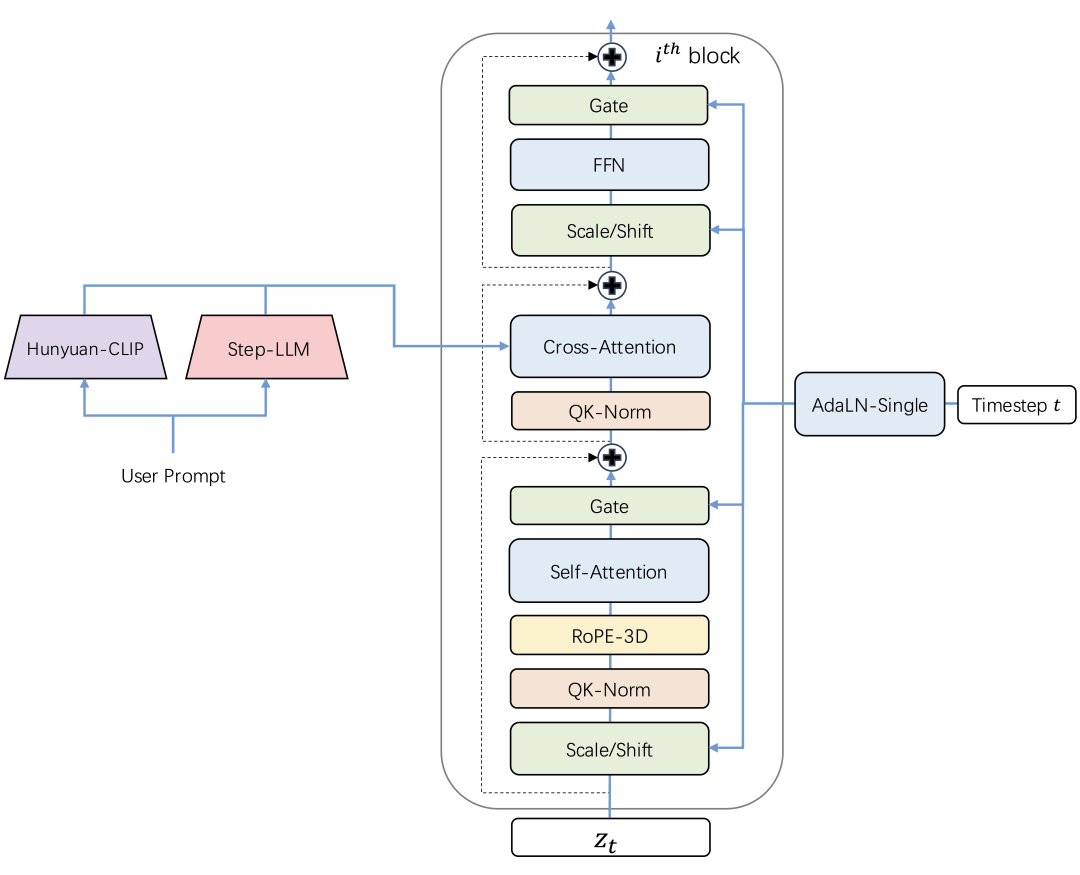
带 3D 全注意力机制的 DiT:
Step-Video-T2V 建立在 DiT 架构之上,该架构有 48 层,每层包含 48 个注意力头,每个注意力头的尺寸设置为 128。利用 AdaLN-Single 来纳入时间步条件,同时引入自注意力机制中的 QK-Norm 来确保训练稳定性。此外,还采用了 3D RoPE,在处理不同视频长度和分辨率的序列时发挥着关键作用。
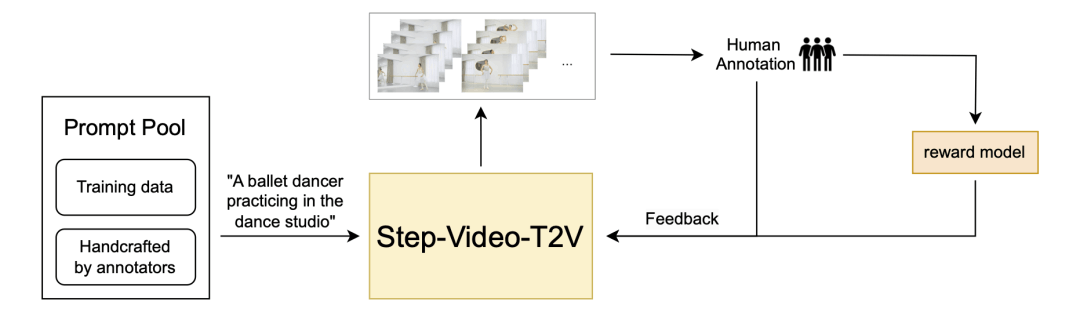
视频-DPO
在 Step-Video-T2V 中,研究团队通过直接偏好优化 (DPO) 融入人类反馈,进一步提升生成视频的视觉质量。DPO 利用人类偏好数据来微调模型,确保生成的内容更符合人类的期望。整体 DPO 流程如下所示,突出了其在提高视频生成过程的一致性和质量方面的关键作用。
为了对开源视频生成模型的性能进行全面评测,阶跃发布并开源了针对文生视频质量评测的新基准数据集 Step-Video-T2V-Eval。该测试集包含 128 条源于真实用户的中文评测问题,旨在评估生成视频在运动、风景、动物、组合概念、超现实、人物、3D 动画、电影摄影等 11 个内容类别上质量。
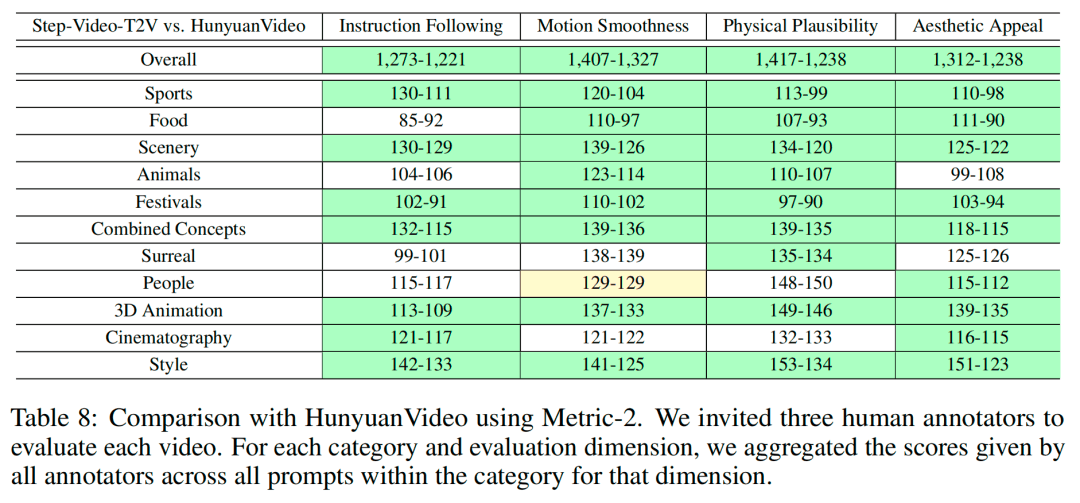
图为 Step-Video-T2V-Eval 评测结果
评测结果显示,Step-Video-T2V 的模型性能在指令遵循、运动平滑性、物理合理性、美感度等方面的表现均显著超过市面上既有的开源视频模型。
在生成效果上,Step-Video-T2V 在复杂运动、美感人物、视觉想象力、基础文字生成、原生中英双语输入和镜头语言等方面具备强大的生成能力,且语义理解和指令遵循能力突出,能够高效助力视频创作者实现精准创意呈现。
Step-Video-T2V 对复杂运动场景场景具有优异的把控能力,无论是高雅优美的芭蕾舞、对抗激烈的空手道、紧张刺激的羽毛球,还是高速翻转的跳水,都能展现。在下面这个视频中,模型对熊猫、地面坡度、滑板等多个事物之间的空间关系、大幅度运动的规律都有着深刻的理解,生成的画面真实且符合物理规律。而生成复杂运动,理解物理空间规律也是当下视频生成模型最大的挑战。
https://live.csdn.net/v/464259
Step-Video-T2V 支持推、拉、摇、移、旋转、跟随等多种镜头运动方式,以及不同景别之间的切换,能够很好地生成大幅度运镜。
https://live.csdn.net/v/464261
Step-Video-T2V 生成的人物形象更逼真、更生动,细节更丰富,表情更自然。五官、发型、皮肤纹理都更加细腻。
https://live.csdn.net/v/464262
Step-Audio:业内首款产品级开源语音交互模型
Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤),方言(如 粤语,四川话),可控制语速及韵律风格,支持RAP和哼唱等。其核心技术突破体现在以下四大技术亮点:
-
1300亿多模态模型: 单模型能实现理解生成一体化,完成语音识别、语义理解、对话、语音克隆、语音生成等功能,开源千亿参数多模态模型 Step-Audio-Chat 版本。
-
高效数据生成链路: 基于130B 突破传统 TTS 对人工采集数据的依赖,生成高质量的合成音频数据,并同步开源首个基于大规模合成数据训练,支持 RAP 和哼唱的指令加强版语音合成模型 Step-Audio-TTS-3B 。
-
精细语音控制: 支持多种情绪(如生气,高兴,悲伤)、方言(包括粤语、四川话等)和唱歌(包括 RAP、干声哼唱)的精准调控,满足用户对多样化语音生成的需求。
-
扩展工具调用: 结合RLHF方法,通过 ToolCall 机制和角色扮演增强,进一步提升其在 Agents 和复杂任务中的表现
模型亮点:
在Step-Audio系统中,音频流采用Linguistic tokenizer(码率16.7Hz,码本大小1024)与Semantice tokenizer(码率25Hz,码本大小4096)并行的双码本编码器方案,双码本在排列上使用了2:3时序交错策略。通过音频语境化持续预训练和任务定向微调强化了130B参数量的基础模型(Step-1),最终构建了强大的跨模态语音理解能力。为了实现实时音频生成,系统采用了混合语音解码器,结合流匹配(flow matching)与神经声码技术。
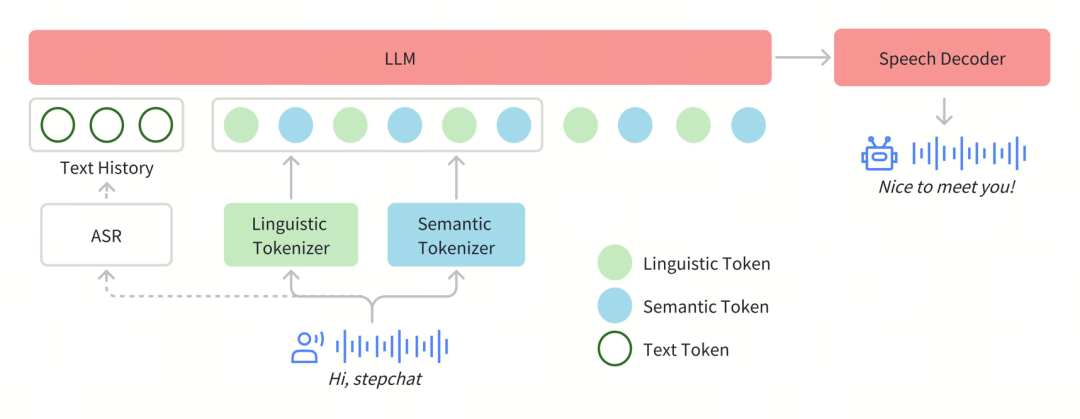
分词器
通过token级交错方法实现Linguistic token与Semantic token的有效整合。Linguistic tokenizer的码本大小是1024,码率16.7Hz;而Semantic tokenizer则使用4096的大容量码本来捕捉更精细的声学细节,码率25Hz。鉴于两者的码率差异,研究团队建立了2:3的时间对齐比例——每两个Linguistic token对应三个Linguistic token形成时序配对。
语言模型
为了提升Step-Audio有效处理语音信息的能力,并实现精准的语音-文本对齐,研究团队在Step-1(一个拥有1300亿参数的基于文本的大型语言模型LLM)的基础上进行了音频持续预训练。
语音解码器
Step-Audio语音解码器主要是将包含语义和声学信息的离散标记信息转换成连续的语音信号。该解码器架构结合了一个30亿参数的语言模型、流匹配模型(flow matching model)和梅尔频谱到波形的声码器(mel-to-wave vocoder)。为优化合成语音的清晰度(intelligibility)和自然度(naturalness),语音解码器采用双码交错训练方法(dual-code interleaving),确保生成过程中语义与声学特征的无缝融合。
实时推理
为了实现实时的语音交互,研究团队对推理管线进行了一系列优化。其中最核心的是控制模块(Controller),该模块负责管理状态转换、协调响应生成,并确保关键子系统间的无缝协同。这些子系统包括:
-
语音活动检测(VAD):实时检测用户语音起止
-
流式音频分词器(Streaming Audio Tokenizer):实时音频流处理
-
Step-Audio语言模型与语音解码器:多模态回复生成
-
上下文管理器(Context Manager):动态维护对话历史与状态

后训练细节
在后训练阶段,研究团队针对自动语音识别(ASR)与文本转语音(TTS)任务进行了专项监督微调(Supervised Fine-Tuning, SFT)。对于音频输入-文本输出(Audio Question Text Answer, AQTA)任务,采用了多样化高质量数据集进行SFT,并采用了基于人类反馈的强化学习(RLHF)以提升响应质量,从而实现对情感表达、语速、方言及韵律的细粒度控制。

在 LlaMA Question、Web Questions 等 5 大主流公开测试集中,Step-Audio 模型性能均超过了行业内同类型开源模型,位列第一。Step-Audio 在 HSK-6(汉语水平考试六级)评测中的表现尤为突出,是最懂中国话的开源语音交互大模型。
比如下面这段对话中,模型能够深入理解中文的博大精深,而不会被「绕晕」。
https://live.csdn.net/v/464263
对于各种不同地区的方言,Step-Audio 也可以精准把握。在这段对话中,模型可以用地道的粤语流畅地对话。
https://live.csdn.net/v/464264
(跃问 App 生成)
此外,由于目前行业内语音对话测试集相对缺失,阶跃自建并开源了多维度评估体系 StepEval-Audio-360 基准测试,从角色扮演、逻辑推理、生成控制、文字游戏、创作能力、指令控制等 9 项基础能力的维度对开源语音模型进行全面测评。通过人工横评后的结果显示,Step-Audio 的模型能力十分均衡,且在各个维度上均超过了此前市面上效果最佳的开源语音模型。
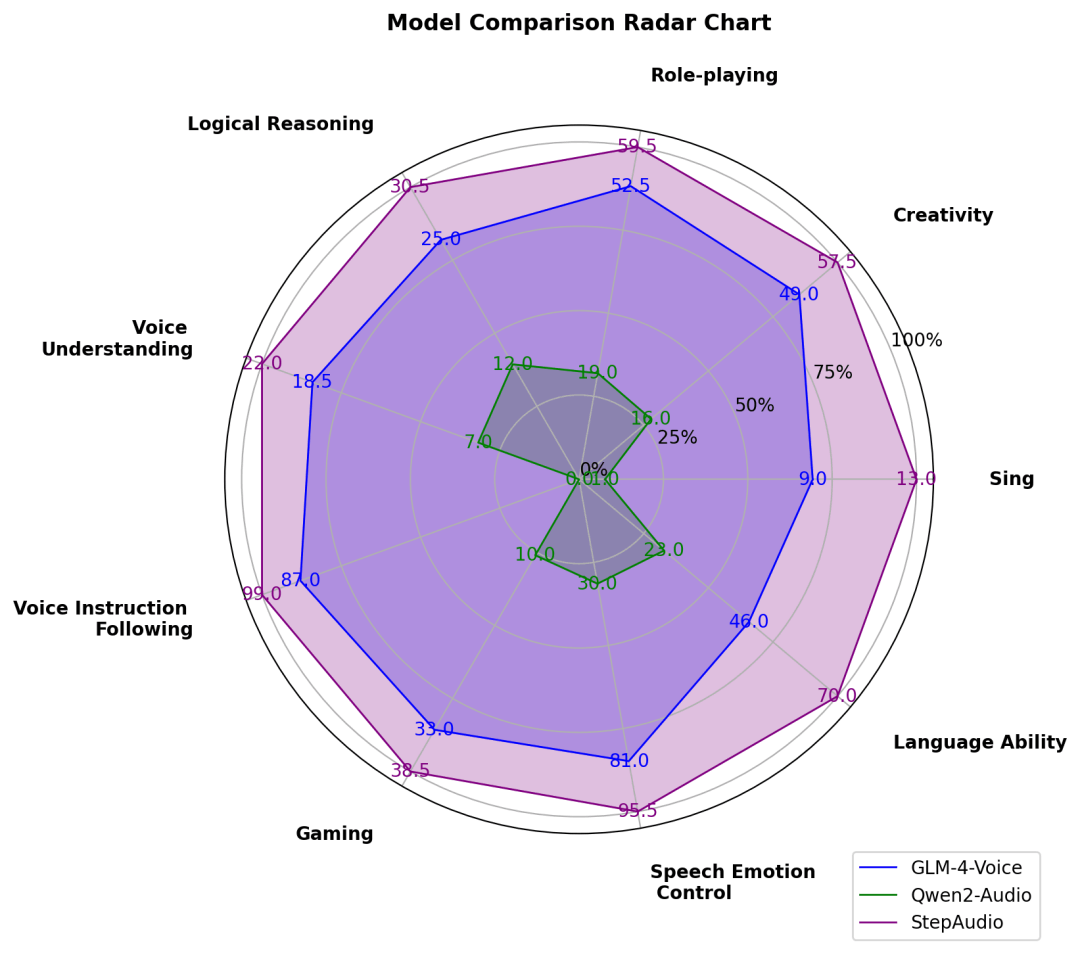
02.模型推理
Step-Video-T2V推理
单卡体验
魔搭社区的开源项目 DiffSynth-Studio(https://github.com/modelscope/DiffSynth-Studio) 为 Step-Video-T2V 模型提供了显存管理优化,支持模型在 80G 显存的单卡 A100 上进行推理。
下载并安装 DiffSynth-Studio:
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .运行 Step-Video-T2V 模型:
python examples/stepvideo/stepvideo_text_to_video.py提示词、帧数等参数可在样例代码 stepvideo_text_to_video.py中进行修改。
代码链接:https://github.com/modelscope/DiffSynth-Studio/blob/main/examples/stepvideo/stepvideo_text_to_video.py
多卡并行部署
阶跃星辰官方提供了多卡并行部署的支持,其中文本编码器和 VAE 部分由独立的进程维护,DiT 部分可以选择 4 卡并行或 8 卡并行,每张卡需要至少 80G 显存。如果要在单台机器上运行,至少需要 5 个 80G 显存的 GPU。
下载源代码并安装依赖:
git clone https://github.com/stepfun-ai/Step-Video-T2V.git
conda create -n stepvideo python=3.10
conda activate stepvideo
cd Step-Video-T2V
pip install -e .
pip install flash-attn --no-build-isolation ## flash-attn is optional下载模型:
pip install modelscope
modelscope download --model stepfun-ai/stepvideo-t2v --local_dir ./stepfun-ai/stepvideo-t2v启动文本编码器和 VAE 部分的服务进程:
python api/call_remote_server.py --model_dir stepfun-ai/stepvideo-t2v &配置 DiT 进程参数:
parallel=4
url='127.0.0.1'
model_dir="stepfun-ai/stepvideo-t2v"启动 DiT 进程并生成视频:
torchrun --nproc_per_node $parallel run_parallel.py --model_dir $model_dir --vae_url $url --caption_url $url --ulysses_degree $parallel --prompt "一名宇航员在月球上发现一块石碑,上面印有“stepfun”字样,闪闪发光" --infer_steps 50 --cfg_scale 9.0 --time_shift 13.0Step-Audio推理
安装依赖:
git clone https://github.com/stepfun-ai/Step-Audio.git
conda create -n stepaudio python=3.10
conda activate stepaudio
cd Step-Audio
pip install -r requirements.txt推理代码如下,你需要在`Step-Audio`目录下运行代码:
import os
import torchaudio
import argparse
from stepaudio import StepAudio
from modelscope import snapshot_download
os.makedirs('output', exist_ok=True)
tokenizer_path = snapshot_download('stepfun-ai/Step-Audio-Tokenizer')
tts_path = snapshot_download('stepfun-ai/Step-Audio-TTS-3B')
model_path = snapshot_download('stepfun-ai/Step-Audio-Chat')
model = StepAudio(
tokenizer_path=tokenizer_path,
tts_path=tts_path,
llm_path=model_path,
)
# example for text input
text, audio, sr = model(
[{"role": "user", "content": "你好,我是你的朋友,我叫小明,你叫什么名字?"}],
"闫雨婷",
)
print(text)
torchaudio.save("output/output_e2e_tqta.wav", audio, sr)
# example for audio input
text, audio, sr = model(
[
{
"role": "user",
"content": {"type": "audio", "audio": "output/output_e2e_tqta.wav"},
}
],
"闫雨婷",
)
print(text)
torchaudio.save("output/output_e2e_aqta.wav", audio, sr)显存资源占用:4 * 65GiB
03.模型微调
使用ms-swift可以对Step-Audio-Chat进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。
ms-swift开源地址:
https://github.com/modelscope/ms-swift
在这里,将展示可运行的微调demo,并给出自定义数据集的格式。
在开始微调之前,请确保您的环境已准备妥当。
# pip install git+https://github.com/modelscope/ms-swift.git
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .
pip install funasr sox conformer openai-whisper librosa微调脚本如下:
CUDA_VISIBLE_DEVICES=0,1,2,3 \
swift sft \
--model stepfun-ai/Step-Audio-Chat \
--dataset 'speech_asr/speech_asr_aishell1_trainsets:validation#2000' \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05训练显存占用:
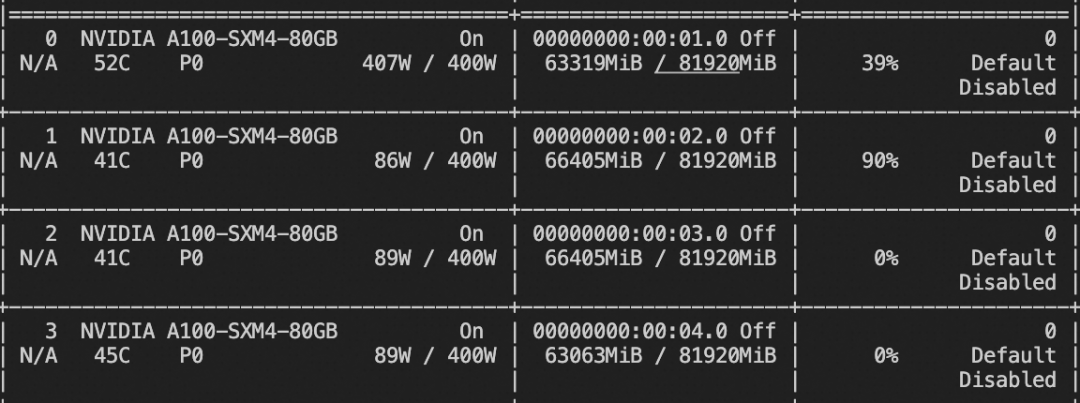
如果要使用自定义数据集进行训练,你可以参考以下格式,并指定`--dataset <dataset_path>`。
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<audio>语音说了什么"}, {"role": "assistant", "content": "今天天气真好呀"}], "audios": ["/xxx/x.mp3"]}
{"messages": [{"role": "user", "content": "<audio>"}, {"role": "assistant", "content": "你好小明,我是小黄。"}, {"role": "user", "content": "<audio>"}, {"role": "assistant", "content": "是啊,今天天气真不错!"}], "audios": ["/xxx/a.mp3", "/xxx/b.mp3"]}训练完成后,使用以下命令对训练后的权重进行推理:
提示:这里的`--adapters`需要替换成训练生成的last checkpoint文件夹。由于adapters文件夹中包含了训练的参数文件`args.json`,因此不需要额外指定`--model`,swift会自动读取这些参数。如果要关闭此行为,可以设置`--load_args false`。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream false \
--max_batch_size 1 \
--load_data_args true \
--max_new_tokens 2048推送模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'点击链接直达模型详情https://modelscope.cn/models/stepfun-ai/stepvideo-t2v

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 1
1 0
0- 0



 已为社区贡献645条内容
已为社区贡献645条内容

所有评论(0)