
开源版Operator原生AI智能体来了?字节跳动开源UI-TARS模型
字节豆包大模型团队认为,如果想要AI智能体实现真正类人的自主任务执行能力,就必须解决当前通用大模型直接应用在GUI(图形用户界面)智能体上存在的一些技术缺陷和不足。

论文标题:
UI-TARS:开创性的与本机代理的自动化 GUI 交互
论文地址:
https://arxiv.org/pdf/2501.12326
官方网站地址:
https://github.com/bytedance/UI-TARS
模型地址:
https://modelscope.cn/collections/UI-TARS-bccb56fa1ef640
UI-TARS具有以下几项创新点:
-
GUI增强采集(Enhanced Perception):利用大规模GUI截图数据集,实现对UI元素的水域采集理解并准确生成描述;
-
统一动作建模(Unified Action Modeling):将动作标准化处理到跨平台的统一空间中,并通过大规模动作统计实现精确定位和交互;
-
系统2推理(System-2熟推理):将深思思考的推理纳入多步决策,并重点任务梳理、思考思维等多种推理模式。
-
迭代式反思训练(Iterative Training with Reflective Online Traces):通过在数百台虚拟机上自动收集、过滤和反射细化新的交易轨迹来解决数据瓶颈问题。同时基于迭代训练和反思训练,UI-TARS持续从错误中学习,并在最少的人为干预下感知不可预见的情况。
字节豆包大模型团队认为,如果想要AI智能体实现真正类人的自主任务执行能力,就必须解决当前通用大模型直接应用在GUI(图形用户界面)智能体上存在的一些技术缺陷和不足。
首先,用户指令的执行需要提取特定元素的坐标信息,而通用大模型通常缺乏所需要的精确数值理解能力。其次,通用大模型在处理目标驱动场景时往往无法理解,这就需要开发者提供详细的自然语言说明操作步骤,增加了开发者的负担。最后,同时发送图片信息与元素描述导致模型调用过程中消耗大量的令牌,会导致性能消耗,成本升高。
在操作员中,OpenAI通过GPT-4o的视觉能力与强化学习实现的高级推理相结合,让智能体可以像人类一样与图形界面进行交互,灵活地执行任务。
UI-TARS也很好地解决了上述瓶颈,它依托强大的通用多模态语言模型进行识别,并针对智能UI交互进行了定向训练。这样做的结果就是:UI-TARS在GUI智能体领域能够发挥出远胜于其他通用模型或GUI模型的表现,同时可以兼容各种形态的操作系统。
效果好不好,用权威基准测试结果来说话。在线动态可以环境模拟真实世界场景的交互,而GUI智能体通过实时执行操作来改变环境状态,从而可以满足用户需求。
其中在OSWorld上,当限定的最大步数为15时,UI-TARS的任务成功率达到了22.7%,超过了Claude的14.9%,也超过了Operator的19.7%。而当限定步数提升到50步时,UI-TARS的成功率达到了24.6%,同样也超过了Claude,但根据OpenAI公布的数据,Operator在50步时的表现达到了32.6%,相对UI-TARS有明显优势。这意味着测试时间缩放是UI-TARS下一步需要升级的方向。
不仅如此,在基于Andriod操作系统的AndroidWorld基准上,UI-TARS获得了46.6%的任务成功率,大幅超过了GPT-4o的34.5%。
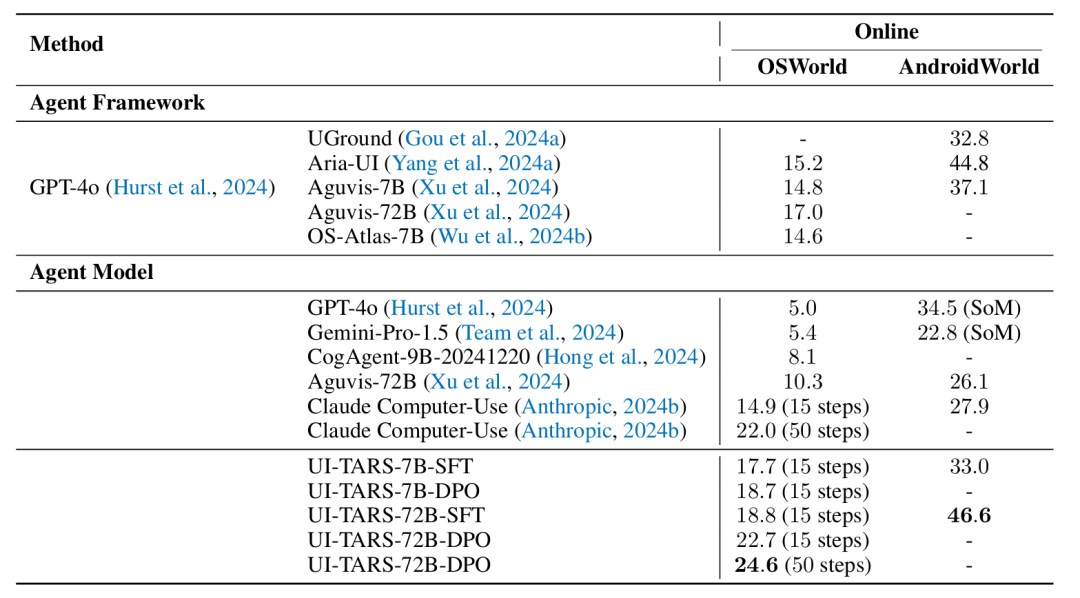
除了在线动态环境中实现能力新SOTA之外,UI-TARS同样在Multimodal Mind2Web(用于创建和评估执行语言指令的web智能体)以及Android Control(评估移动端环境中的规划和动作执行能力)、GUI Odyssey重点(于移动端环境中跨应用导航任务)等三个离线静态、预定义环境相关的基准测试中表现领先。
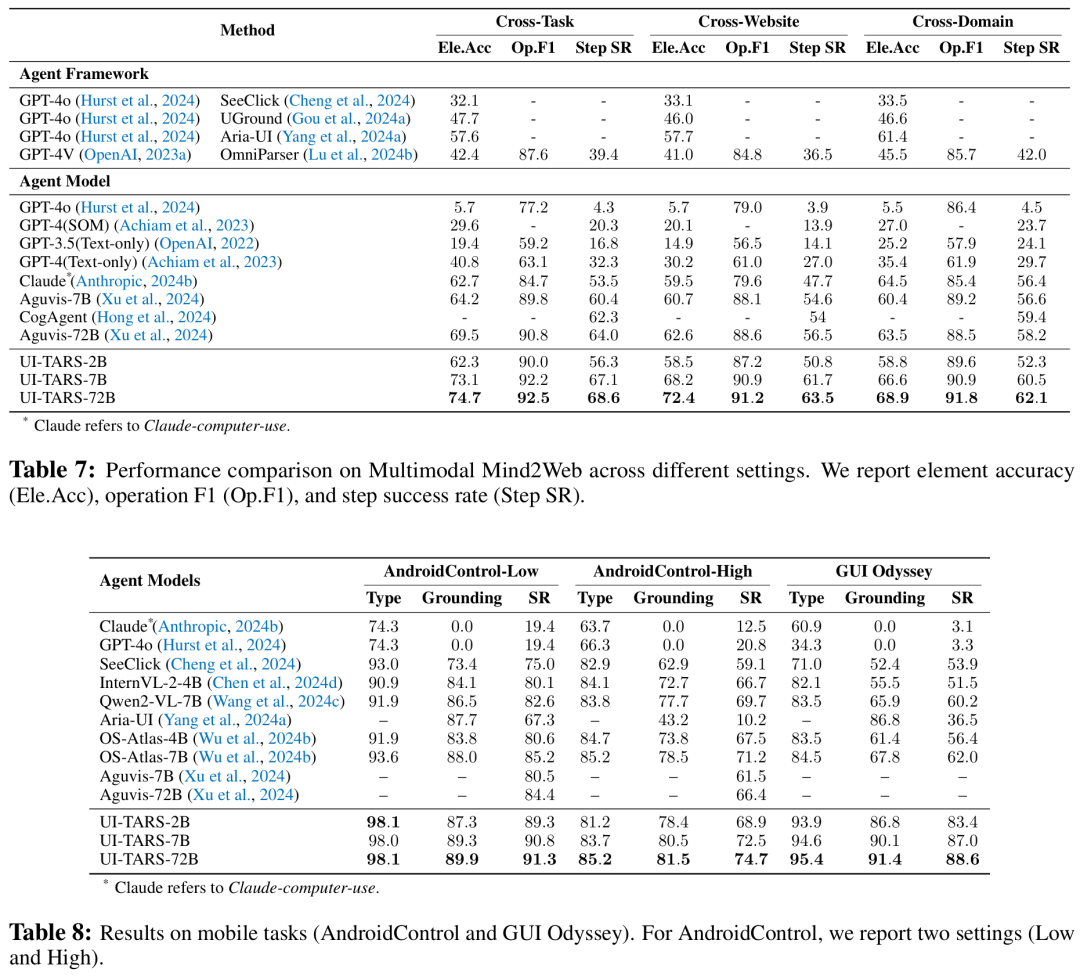
更进一步,UI-TAR的智能体系统是优质的,这被认为是智能体AI的下一个方向。
自从GPT-4出现后,智能体成为了AI领域研究的热门领域,最近又经历了一次范式革新。首先是智能体框架(Agent Framework),利用高性能基础模型(如 GPT-4o)的理解和推理能力来增强任务的灵活性。它们实现了自动化和灵活的交互,也可以借助更多模块不断增强,或完成多智能体定义协作,但它仍然依赖于人的工作流来构建操作。因此,智能体框架会面临一致性、模块不兼容等问题,维护其首要增量。
当前阶段,一些研究团队已经提出了智能体模型(Agent Model)新范式,其中任务以高精度的方式学习和执行,将感知、推理、记忆和动作统一在一个不断发展的模型中。
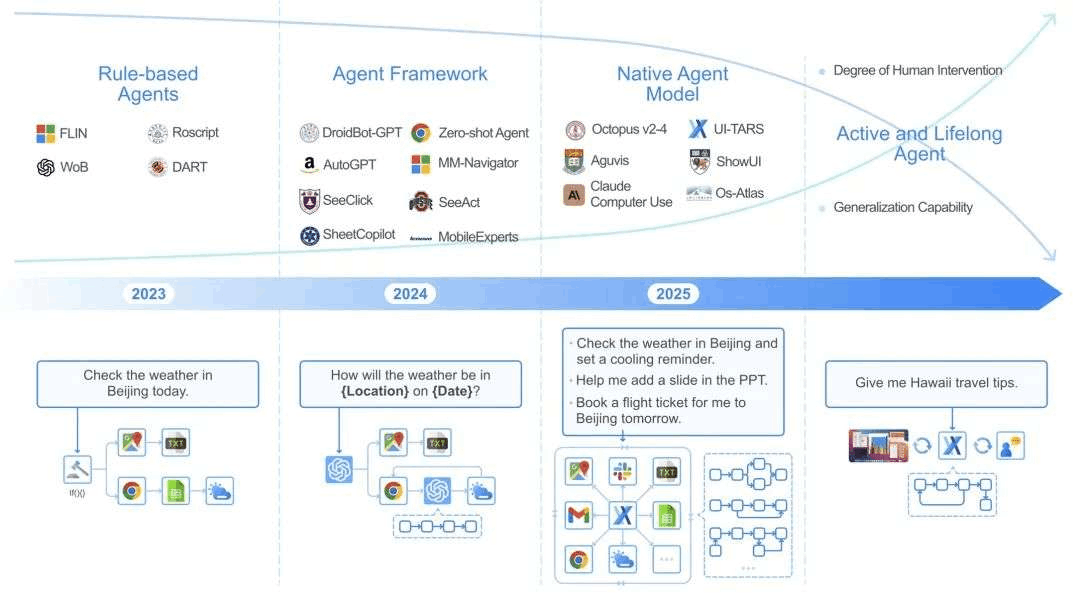
方法从根本上实现了数据驱动,让智能体可以适应新任务、界面或用户需求,无需依赖手动制作的提示或预规则定义,拥有强大的泛化能力,也可以进行自我改进。
向人类看齐:充分利用系统2推理能力
在技术报告中,UI-TARS的定位是「一个重建的GUI智能体模型,其设计目标是在不依赖繁琐的人工设计规则或级联模块的情况下进行兼容。」
从功能上看,UI-TARS可以直接采集屏幕截图、应用推理过程并自主生成有效操作。此外,UI-TARS还可以学习之前的经验,通过利用环境反馈来迭代改进其性能。下图展示了其整体架构。
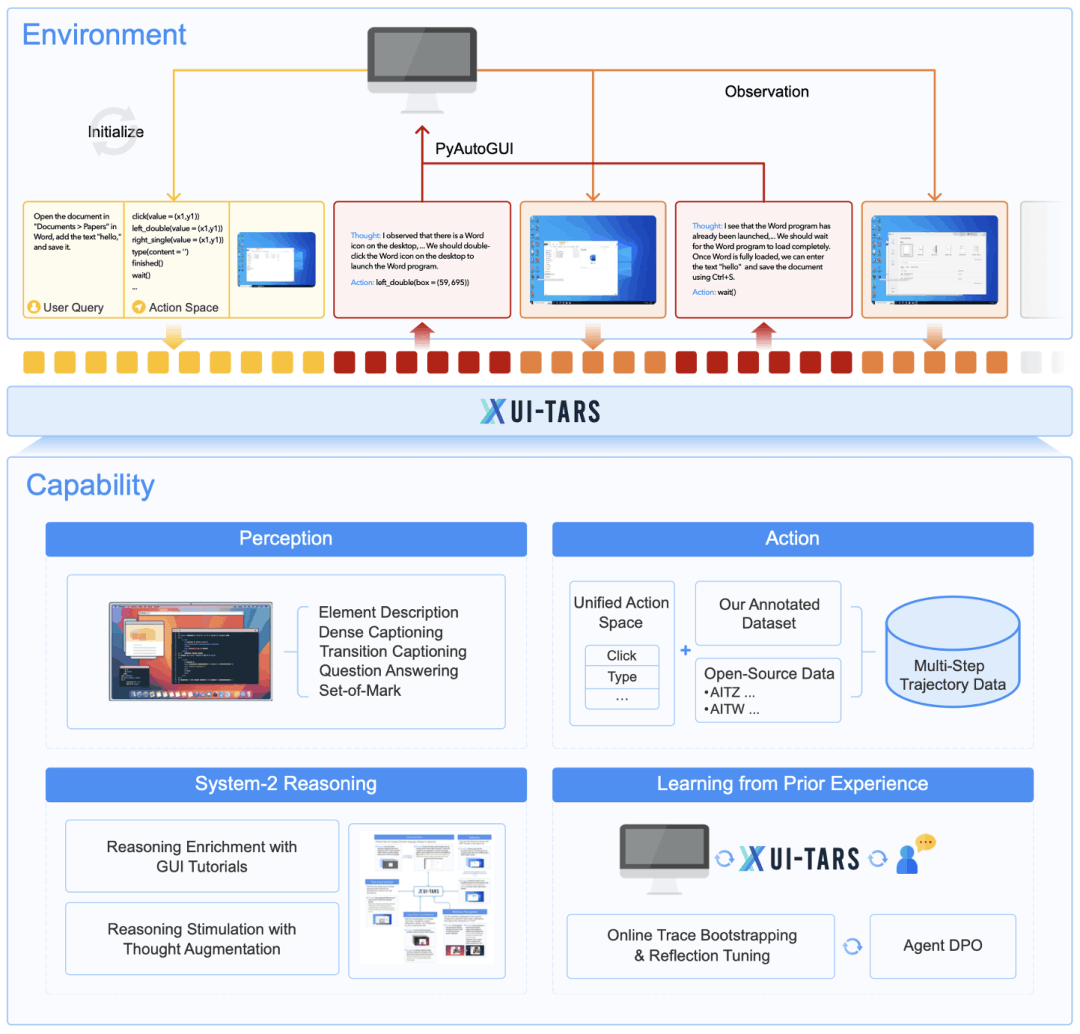
总体来说,UI-TARS 的能力都涉及感知、推理、动作以及经验学习进行的。
具体来说,给定一个初始任务指令,为了完成任务,UI-TARS 会迭代方式接收来自设备的观察结果并执行相应的操作。在每个时间步骤,UI-TARS 都会以任务指令、先前事件的历史记录和当前观察为输入,基于预定义的动作空间输出动作。执行完动作,设备会提供后续观察,持续迭代。
为了进一步增强智能体的推理能力,并让决策更加深思熟虑,字节豆包大模型团队还集成了一个以「思维(想法)」形式出现的推理组件,该组件会在每个动作生成之前。
这些「思维」能反应系统 2 思维的思考性质。它们是关键的中间步骤,可引导智能体在继续之前重新考虑之前的动作和观察,与环境交互,构成思考性事件,从而确保每个决定都是明确明确的,并且都是经过仔细思考的。
数据集、推理与长期记忆,UI-TARS集成了一系列创新
了解了 UI-TARS 的技术框架,我们再继续深入研究其各个方面的细节,看看这款电脑使用智能体的优良表现究竟来自哪里。同时,这也或许能让我们洞悉一二操作员等其他同类智能体的设计思路。
要训练GUI智能体,还需要过数据这一关。字节豆包大模型团队采用引入智能体方法,直接处理GUI截图输入,利用大规模统一数据集来提升性能。
具体实施包括:收集大规模数据集;为界面元素创建格式化描述(类型、视觉、位置、功能);提供密集描述包括空间关系和整体布局;标注状态转换数据;合成多样化问答数据集;增加标记集,在界面上添加不同属性标记的提示,帮助模型定位识别元素。
通过这些步骤,UI-TARS 能够更好地理解和处理 GUI 任务。
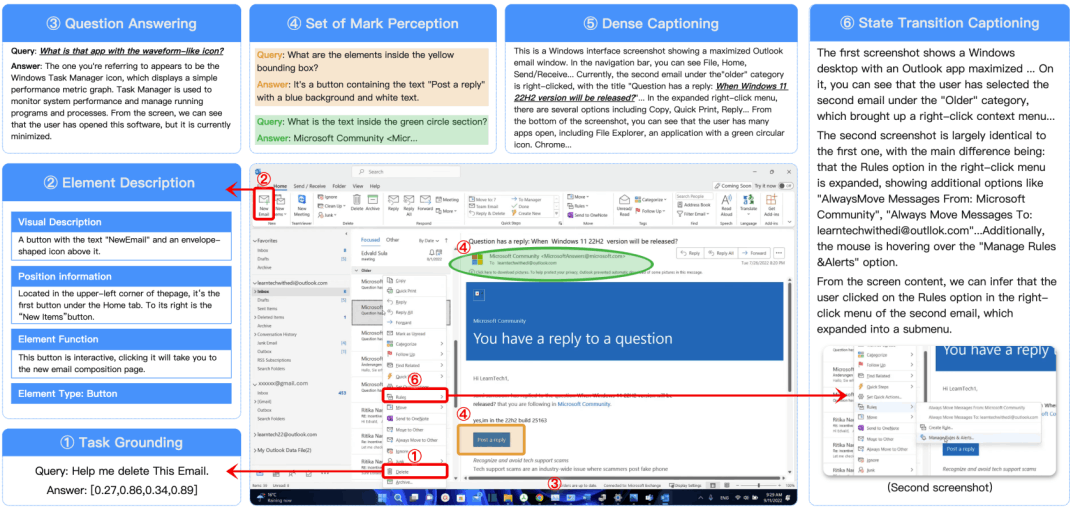
(图注) 水资源与接地数据样本
研究团队还进行了统一的动作空间建模与接地,在增强模型准确理解和定位视觉元素的能力的同时,让模型学会一些连续的多步轨迹,在完成一些任务时不假思索地完成,构成系统1思维。下表1给出了不同平台的统一动作空间,而表2则展示了接地与多步动作流程图数据的基本统计信息。

那么,UI-TARS是如何将System 2推理整合能力引入的呢?
具体来说,该团队采用的做法是首先使用 GUI 教程来增强模型的推理能力——他们因此编排了一个 6M 规模的高质量 GUI 教程,平均每个教程包含 510 个 token 和 3.3 张文本图像。
然后,再利用思维增强来进行推理模拟,重点通过标注「」来完成任务与动作之间的空白,从而增强前面提到的动作趋势数据。这些思维使模型能够明显地表示其决策过程,从而更好地与任务目标定位。

整体来看,UI-TARS 在推理方面采用的方法不同于操作员使用思维链的方式。从实验结果看,UI-TARS 的推理方法在可用步数预设时可能会更胜一筹,但当可用步数预设时,曼哈顿会有更明显的优势。
有了推理能力后,该团队还让 UI-TARS 具备了可从长期记忆学习之前的经验的能力。这样一来,这个智能体就可以在使用中不断迭代改进了。这主要涉及三个过程,即在线表格引导、反思、代理 DPO。
在线仪表引导的过程如下图所示,简单来说先让智能体在目标GUI环境内基于指令生成一些原始仪表,然后进行过滤,得到高质量的数据。然后利用结果仪表来实现自我提升。
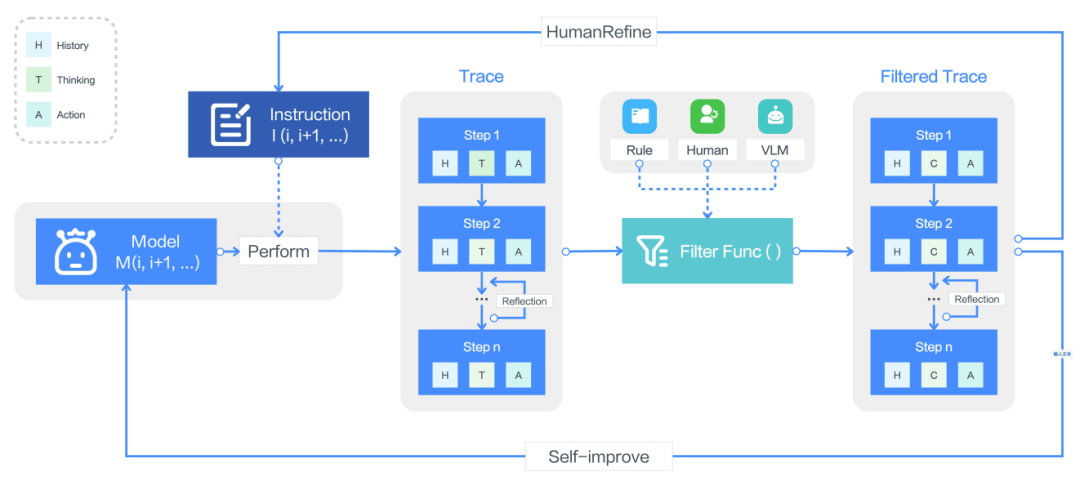
反思让模型看到自己犯下的真实世界错误并修正方案,从而让模型学会从次优决策中恢复。
Agent DPO可以通过直接编码对正确动作的偏好(而不是错误动作)来优化UI-TARS,从而更好地利用可用数据。
总之,通过这些技术创新,UI-TARS 拥有了强大的完成复杂任务的能力。
01.模型体验
调整主页字体设置
https://live.csdn.net/v/461794
修改ppt颜色
https://live.csdn.net/v/461795
手机端Agent
https://live.csdn.net/v/461796
02.魔搭最佳
模型部署
进入入口
以UI-TARS-7B-SFT为例,在页面上点击部署-阿里云PAI模型库部署:
根据页面提示登录阿里云
选择对应的GPU资源,点击配置
根据型号大小,推荐GPU型号
|
软件 |
GPU型号 |
GPU个数 |
|
2B |
T4 |
1 |
|
7B |
A10 |
1 |
|
72B |
图形处理器 |
2 |
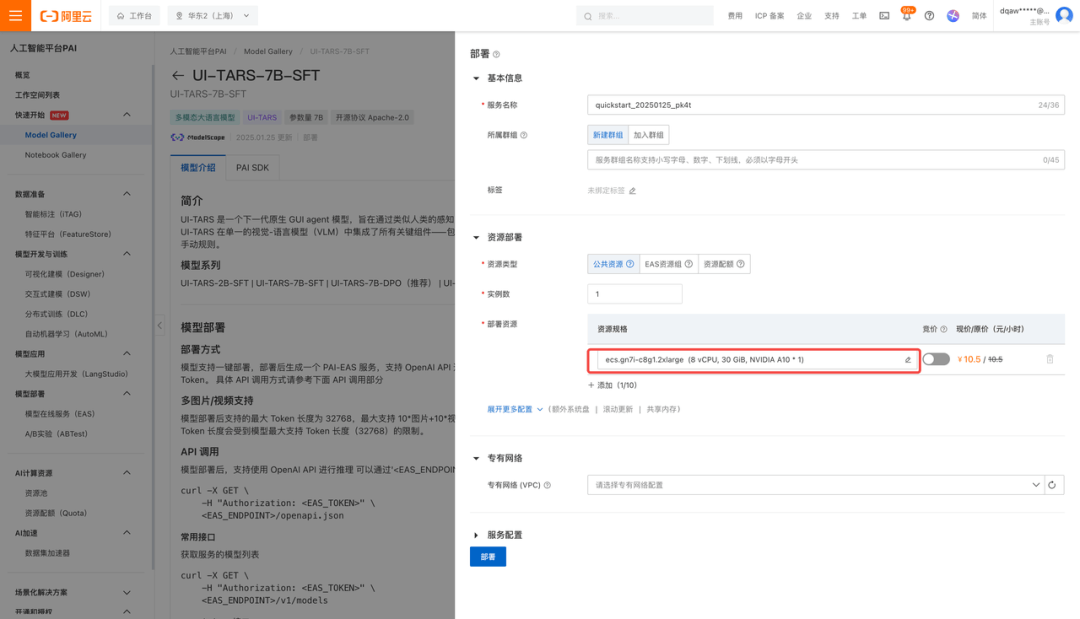
查看API信息
点击查看调用信息,获取对应接口的端点url和token
如果使用OpenAI API,对应的url参数值为<EAS API Endpoint>/v1
接口调用示例代码
示例代码为单图里面,后续每一步都可以按照操作步骤,截图再次运行推理代码。
使用推荐开源项目UI-TARS-desktop调用接口操作本地桌面应用,以及通过Midscene.js使用代码实现浏览器自动化操作。
UI-TARS-desktop客户端:https://github.com/bytedance/UI-TARS-desktop
Midscene.js 浏览器控制:https://github.com/web-infra-dev/midscene
import base64
import requests
from openai import OpenAI
openai_api_base = "<EAS API Endpoint>/v1"
openai_api_key = "<EAS API Token>"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
stream = True
instruction = "search for today's weather"
## Below is the prompt
prompt = r"""You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.
## Output Format
```\nThought: ...
Action: ...\n```
## Action Space
click(start_box='<|box_start|>(x1,y1)<|box_end|>')
left_double(start_box='<|box_start|>(x1,y1)<|box_end|>')
right_single(start_box='<|box_start|>(x1,y1)<|box_end|>')
drag(start_box='<|box_start|>(x1,y1)<|box_end|>', end_box='<|box_start|>(x3,y3)<|box_end|>')
hotkey(key='')
type(content='') #If you want to submit your input, use \"\
\" at the end of `content`.
scroll(start_box='<|box_start|>(x1,y1)<|box_end|>', direction='down or up or right or left')
wait() #Sleep for 5s and take a screenshot to check for any changes.
finished()
call_user() # Submit the task and call the user when the task is unsolvable, or when you need the user's help.
## Note
- Use Chinese in `Thought` part.
- Summarize your next action (with its target element) in one sentence in `Thought` part.
## User Instruction
"""
def encode_base64_content_from_url(content_url: str) -> str:
"""Encode a content retrieved from a remote url to base64 format."""
with requests.get(content_url) as response:
response.raise_for_status()
result = base64.b64encode(response.content).decode("utf-8")
return result
img_url = "https://pai-quickstart-cn-hangzhou.oss-cn-hangzhou.aliyuncs.com/modelscope/eas/macos_desktop.jpg"
image_base64 = encode_base64_content_from_url(img_url)
chat_completion_from_base64 = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": f"data:image/jpg;base64,{image_base64}"},
},
{"type": "text", "text": prompt + instruction},
],
},
],
frequency_penalty=1,
max_tokens=128,
stream=stream,
)
if stream:
for chunk in chat_completion_from_base64:
print(chunk.choices[0].delta.content, end="")
else:
result = chat_completion_from_base64.choices[0].message.content
print(result)模型调试
这里我们介绍使用ms-swift对bytedance-research/UI-TARS-2B-SFT进行扭转。更多RLHF训练方法可以查看:https://github.com/modelscope/ms-swift/tree/main/examples/train/multimodal/rlhf
在开始之前,请确保您的环境已正确安装:
# 安装ms-swift
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .我们给出了可运行的力矩演示和自定义数据集的样式,脚本脚本如下:
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
swift sft \
--model bytedance-research/UI-TARS-2B-SFT \
--dataset 'modelscope/coco_2014_caption:validation#20000' \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4活动显存:

关于自定义数据集,你可以组织成jsonl格式,下面给出了一条数据样本样本,训练时使用`--dataset <dataset_path>`指定即可:
{"messages": [{"role": "user", "content": [{"type": "text", "text": "You are a GUI agent. You are given a task and your action history, with screenshots. You need to perform the next action to complete the task.\n\n## Output Format\n```\\nThought: ...\nAction: ...\\n```\n\n## Action Space\n\nclick(start_box='<|box_start|>(x1,y1)<|box_end|>')\nleft_double(start_box='<|box_start|>(x1,y1)<|box_end|>')\nright_single(start_box='<|box_start|>(x1,y1)<|box_end|>')\ndrag(start_box='<|box_start|>(x1,y1)<|box_end|>', end_box='<|box_start|>(x3,y3)<|box_end|>')\nhotkey(key='')\ntype(content='') #If you want to submit your input, use \\\"\\\n\\\" at the end of `content`.\nscroll(start_box='<|box_start|>(x1,y1)<|box_end|>', direction='down or up or right or left')\nwait() #Sleep for 5s and take a screenshot to check for any changes.\nfinished()\ncall_user() # Submit the task and call the user when the task is unsolvable, or when you need the user's help.\n\n\n## Note\n- Use Chinese in `Thought` part.\n- Summarize your next action (with its target element) in one sentence in `Thought` part.\n\n## User Instruction\nI'm looking for a software to \"edit my photo with grounding\""}]}, {"role": "assistant", "content": "Thought: 左键单击桌面上的“Google Chrome”图标以打开浏览器,其位于桌面的中间偏左位置,第二列的第一个。图标是圆形的,外圈是红色、黄色、绿色组成的圆环,内圈是一个蓝色的圆形。\nAction: click(start_box='<|box_start|>(246,113)<|box_end|>')"}], "images": ["https://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/agent.png"]}推理脚本:
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048扔模型到ModelScope:
CUDA_VISIBLE_DEVICES=0 \
swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '<your-model-id>' \
--hub_token '<your-sdk-token>'点击链接阅读原文:UI-TARS

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献663条内容
已为社区贡献663条内容

所有评论(0)