
MiniCPM-o 2.6:流式全模态,端到端,多模态端侧大模型来了!
MiniCPM-o 2.6 是 MiniCPM-o 系列的最新、性能最佳模型。该模型基于 SigLip-400M、Whisper-medium-300M、ChatTTS-200M 和 Qwen2.5-
01.介绍
MiniCPM-o 2.6 是 MiniCPM-o 系列的最新、性能最佳模型。该模型基于 SigLip-400M、Whisper-medium-300M、ChatTTS-200M 和 Qwen2.5-7B 构建,共 8B 参数,通过端到端方式训练和推理。相比 MiniCPM-V 2.6,该模型在性能上有了显著提升,并支持了实时语音对话和多模态流式交互的新功能。MiniCPM-o 2.6 的主要特性包括:
-
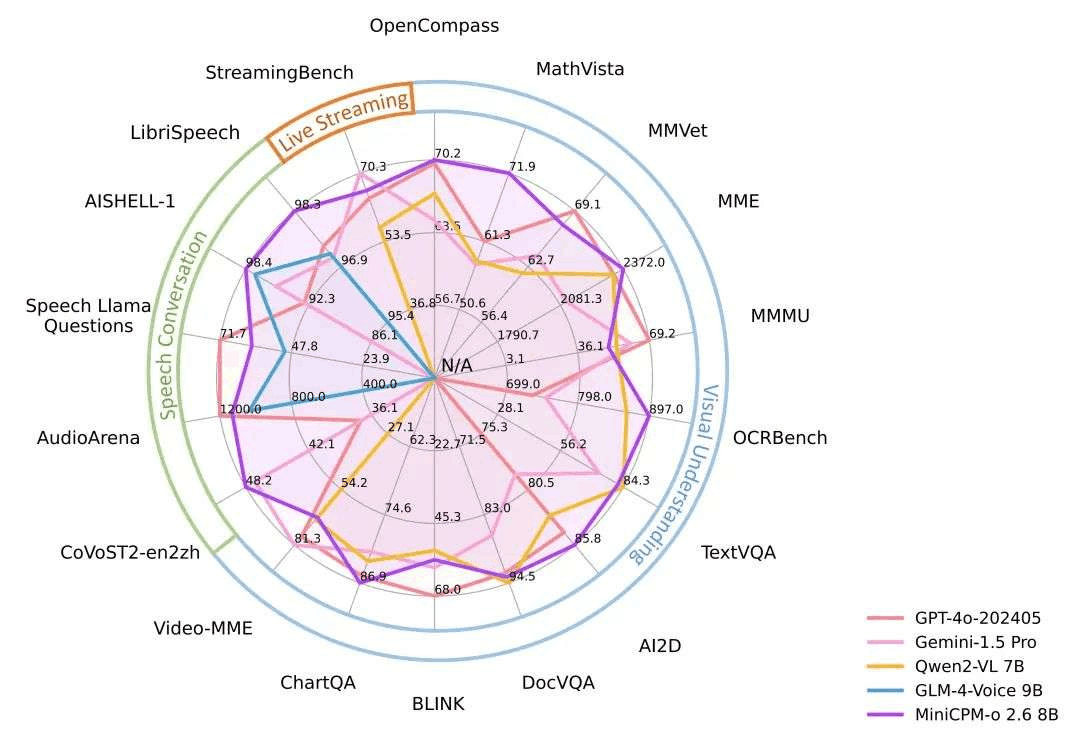
🔥 领先的视觉能力。MiniCPM-o 2.6 在 OpenCompass 榜单上(综合 8 个主流多模态评测基准)平均得分 70.2,以 8B 量级的大小在单图理解方面超越了 GPT-4o-202405、Gemini 1.5 Pro 和 Claude 3.5 Sonnet 等主流商用闭源多模态大模型。此外,它的多图和视频理解表现也优于 GPT-4V 和 Claude 3.5 Sonnet,并展现出了优秀的上下文学习能力。
-
🎙 出色的语音能力。MiniCPM-o 2.6 支持可配置声音的中英双语实时对话。MiniCPM-o 2.6 在语音理解任务(如 ASR 和 STT translation)上的表现优于 GPT-4o-realtime,并在语音对话的语义和声学评估中展现了开源模型中最高的语音生成性能。它还支持情绪/语速/风格控制、语音克隆、角色扮演等进阶能力。
-
🎬 强大的多模态流式交互能力。 作为一项新功能,MiniCPM-o 2.6 能够接受连续的视频和音频流,并和用户进行实时语音交互。在 StreamingBench(针对实时视频理解、全模态(视/音频)理解、多模态上下文理解的综合评测基准)中,MiniCPM-o 2.6 获得开源模型最高分并超过了 GPT-4o-realtime 和 Claude 3.5 Sonnet。
-
💪 强大的 OCR 能力及其他功能。 MiniCPM-o 2.6 进一步优化了 MiniCPM-V 2.6 的众多视觉理解能力,其可以处理任意长宽比的图像,像素数可达 180 万(如 1344x1344)。在 OCRBench 上取得25B 以下最佳水平,超过 GPT-4o-202405 等商用闭源模型。基于最新的 RLHF-V、RLAIF-V 和 VisCPM 技术,其具备了可信的多模态行为,在 MMHal-Bench 上超过了 GPT-4o 和 Claude 3.5,并支持英语、中文、德语、法语、意大利语、韩语等多种语言。
-
🚀 卓越的效率。 除了对个人用户友好的模型大小,MiniCPM-o 2.6 还表现出最先进的视觉 token 密度(即每个视觉 token 编码的像素数量)。它仅需 640 个 token 即可处理 180 万像素图像,比大多数模型少 75%。这一特性优化了模型的推理速度、首 token 延迟、内存占用和功耗。因此,MiniCPM-o 2.6 可以支持 iPad 等终端设备上的高效多模态流式交互。
-
💫 易于使用。 MiniCPM-o 2.6 可以通过多种方式轻松使用:(1) llama.cpp 支持在本地设备上进行高效的 CPU 推理,(2) int4 和 GGUF 格式的量化模型,有 16 种尺寸,(3) vLLM 支持高吞吐量和内存高效的推理,(4) 通过LLaMA-Factory框架针对新领域和任务进行微调,(5) 使用 Gradio 快速设置本地 WebUI 演示,(6) 在线demo。
模型架构
-
端到端全模态架构。 通过端到端的方式连接和训练不同模态的编/解码模块以充分利用丰富的多模态知识。
-
全模态流式机制。 (1) 我们将不同模态的离线编/解码器改造为适用于流式输入/输出的在线模块。 (2) 我们针对大语言模型基座设计了一种时分复用的全模态流式信息处理机制,将平行的不同模态的信息流拆分重组为周期性时间片序列。
-
可配置的声音方案。 我们设计了包含传统文本系统提示词和用于指定模型声音的语音系统提示词结构。从而,模型可在推理时灵活地通过文字或语音样例控制声音风格,支持声音克隆和声音生成等高级能力
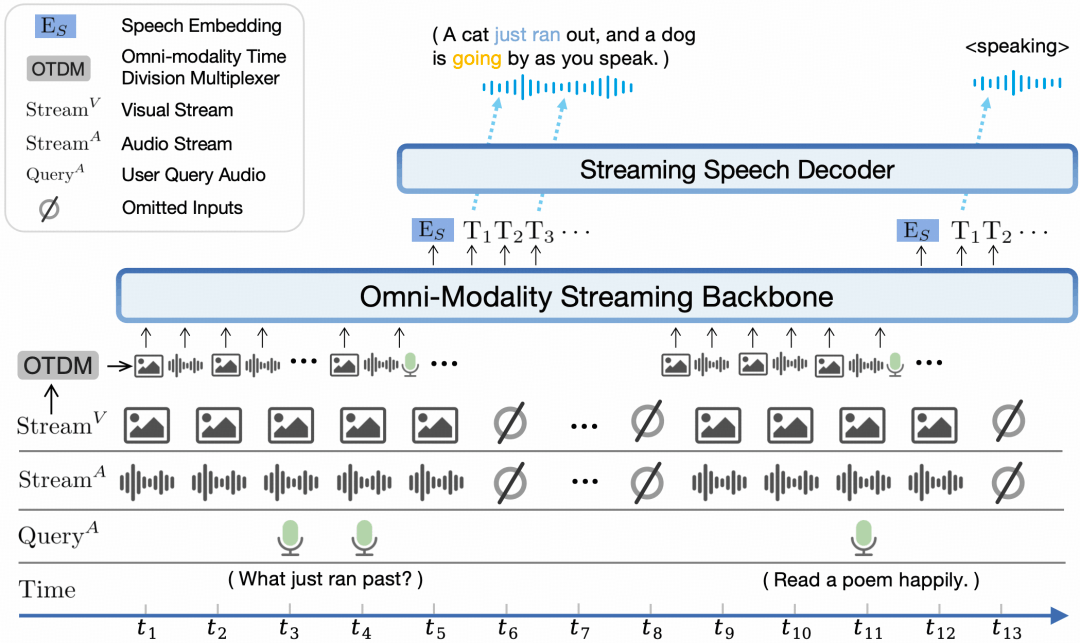
性能评估
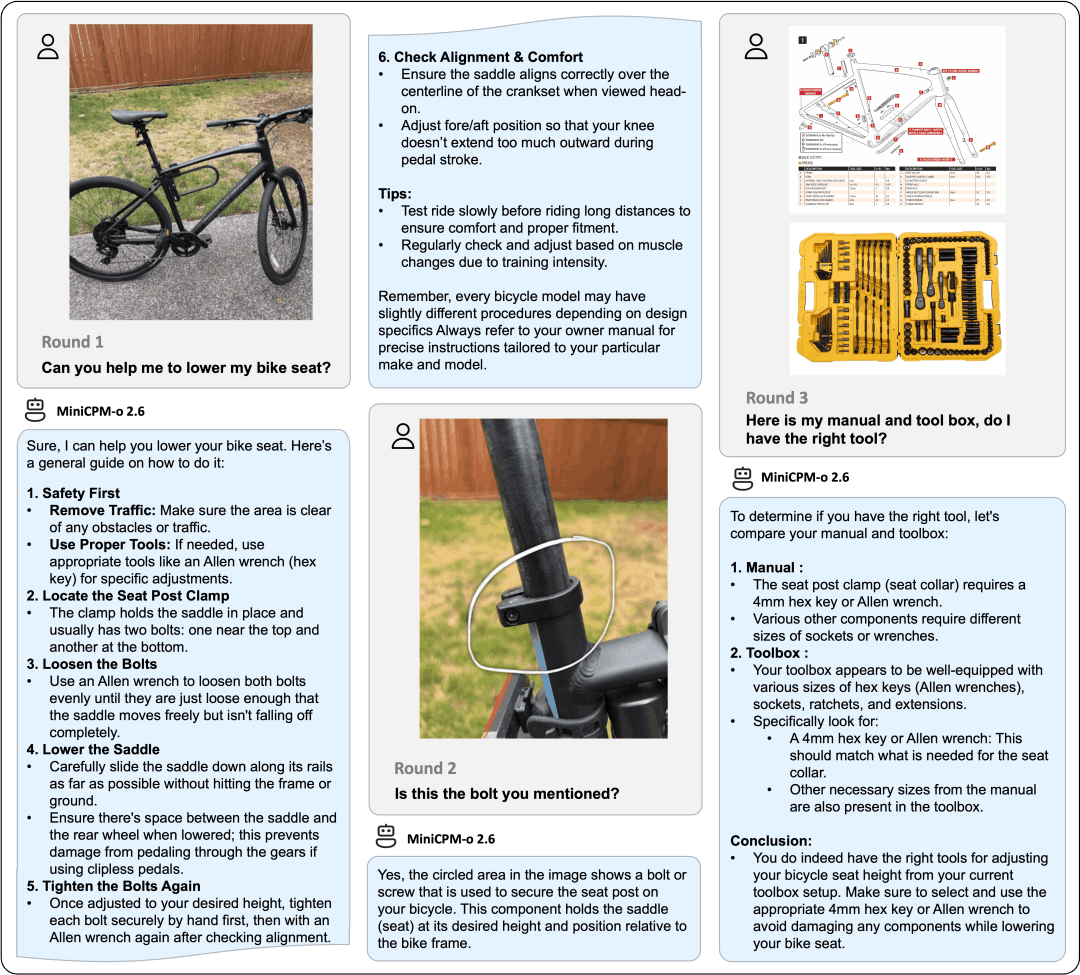
典型示例
以下示例为 MiniCPM-o 2.6 部署在 iPad Pro 上所录制得到。


模型地址:https://modelscope.cn/models/OpenBMB/MiniCPM-o-2_6
项目地址:https://github.com/OpenBMB/MiniCPM-o
02.模型推理
使用魔搭社区免费算力(24G显存)完成模型推理实践。
安装依赖
!pip install vector-quantize-pytorch==1.18.5
!pip install vocos==0.1.0
!pip install transformers==4.44.2推理代码
import torch
from PIL import Image
from modelscope import AutoModel, AutoTokenizer
# load omni model default, the default init_vision/init_audio/init_tts is True
# if load vision-only model, please set init_audio=False and init_tts=False
# if load audio-only model, please set init_vision=False
model = AutoModel.from_pretrained(
'openbmb/MiniCPM-o-2_6',
trust_remote_code=True,
attn_implementation='sdpa', # sdpa or flash_attention_2
torch_dtype=torch.bfloat16,
init_vision=True,
init_audio=True,
init_tts=True
)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('OpenBMB/MiniCPM-o-2_6', trust_remote_code=True)
# In addition to vision-only mode, tts processor and vocos also needs to be initialized
model.init_tts()
model.tts.float()
import math
import numpy as np
from PIL import Image
from moviepy.editor import VideoFileClip
import tempfile
import librosa
import soundfile as sf
def get_video_chunk_content(video_path, flatten=True):
video = VideoFileClip(video_path)
print('video_duration:', video.duration)
with tempfile.NamedTemporaryFile(suffix=".wav", delete=True) as temp_audio_file:
temp_audio_file_path = temp_audio_file.name
video.audio.write_audiofile(temp_audio_file_path, codec="pcm_s16le", fps=16000)
audio_np, sr = librosa.load(temp_audio_file_path, sr=16000, mono=True)
num_units = math.ceil(video.duration)
# 1 frame + 1s audio chunk
contents= []
for i in range(num_units):
frame = video.get_frame(i+1)
image = Image.fromarray((frame).astype(np.uint8))
audio = audio_np[sr*i:sr*(i+1)]
if flatten:
contents.extend(["<unit>", image, audio])
else:
contents.append(["<unit>", image, audio])
return contents
video_path="/mnt/workspace/video.mp4"
sys_msg = model.get_sys_prompt(mode='omni', language='en')
# if use voice clone prompt, please set ref_audio
# ref_audio_path = '/path/to/ref_audio'
# ref_audio, _ = librosa.load(ref_audio_path, sr=16000, mono=True)
# sys_msg = model.get_sys_prompt(ref_audio=ref_audio, mode='omni', language='en')
contents = get_video_chunk_content(video_path)
msg = {"role":"user", "content": contents}
msgs = [sys_msg, msg]
# please set generate_audio=True and output_audio_path to save the tts result
generate_audio = True
output_audio_path = '/mnt/workspace/4.wav'
res = model.chat(
msgs=msgs,
tokenizer=tokenizer,
sampling=True,
temperature=0.5,
max_new_tokens=4096,
omni_input=True, # please set omni_input=True when omni inference
use_tts_template=True,
generate_audio=generate_audio,
output_audio_path=output_audio_path,
max_slice_nums=1,
use_image_id=False,
return_dict=True
)
print(res)
03.模型微调
使用ms-swift对MiniCPM-o-2_6进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型微调部署框架。ms-swift开源地址:https://github.com/modelscope/ms-swift
在这里,将展示可直接运行的demo,并给出自定义数据集的格式。
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .[llm]图像OCR微调脚本如下:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model OpenBMB/MiniCPM-o-2_6 \
--dataset AI-ModelScope/LaTeX_OCR:human_handwrite#20000 \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4训练显存资源:

视频微调脚本如下:
CUDA_VISIBLE_DEVICES=0 \
MAX_NUM_FRAMES=64 \
swift sft \
--model OpenBMB/MiniCPM-o-2_6 \
--dataset swift/VideoChatGPT:all \
--train_type lora \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4训练显存资源:

自定义数据集格式如下(system字段可选),只需要指定`--dataset <dataset_path>`即可:
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}
{"messages": [{"role": "user", "content": "<image><image>两张图片有什么区别"}, {"role": "assistant", "content": "前一张是小猫,后一张是小狗"}], "images": ["/xxx/x.jpg", "xxx/x.png"]}
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<video>视频中是什么"}, {"role": "assistant", "content": "视频中是一只小狗在草地上奔跑"}], "videos": ["/xxx/x.mp4"]}训练完成后,使用以下命令对训练时的验证集进行推理
这里`--adapters`需要替换成训练生成的last checkpoint文件夹. 由于adapters文件夹中包含了训练的参数文件,因此不需要额外指定`--model`:
CUDA_VISIBLE_DEVICES=0,1 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream false \
--max_batch_size 1 \
--load_data_args true \
--max_new_tokens 2048点击链接,即可跳转模型链接~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献645条内容
已为社区贡献645条内容

所有评论(0)