
InternLM3开源发布!4T数据达到18T效果,成本省75%,首度融合深度思考与对话能力!
1月15日,上海人工智能实验室对书生大模型进行重要版本升级,书生·浦语3.0(InternLM3)通过精炼数据框架,大幅提升了数据效率,并实现思维密度的跃升。仅使用4T训练数据的InternLM3-8
1月15日,上海人工智能实验室对书生大模型进行重要版本升级,书生·浦语3.0(InternLM3)通过精炼数据框架,大幅提升了数据效率,并实现思维密度的跃升。仅使用4T训练数据的InternLM3-8B-Instruct,其综合性能超过了同量级开源模型,节约训练成本75%以上;同时,InternLM3首次在通用模型中实现了常规对话与深度思考能力融合,可应对更多真实使用场景。
体验页面:
https://internlm-chat.intern-ai.org.cn
GitHub链接:
https://github.com/InternLM/InternLM
模型链接:https://www.modelscope.cn/models/Shanghai_AI_Laboratory/internlm3-8b-instruct
01.模型介绍
研究团队提出大规模数据精炼框架,大幅提高了训练数据的质量,在具体实践中,4T预训练数据可达主流开源模型18T效果。通过构建数据“思维密度”杠杆,撬动模型性能提升,为突破Scaling Law带来了新的研究范式。
通过数据精炼框架,研究团队使InternLM3大幅提升了数据效率,实现思维密度的跃升。该框架包括以下两个核心要素:
-
数据处理的智能化:为了实现数据的精细化处理,研究团队将数据分为千万个领域,在此类人力难以负担的规模上,通过智能体自我演进技术,大规模自动化质检,根据错例进行反思,为每个领域进行定制化处理。
-
高价值数据的合成:基于通专融合的方式,以通用模型快速迭代合成算法,再精选数据训练专用模型,通过在海量天然数据中进行素材挖掘,改进的树状搜索策略,以及多维度质量验证,合成大量内容丰富,质量可靠的高价值数据。
基于司南OpenCompass开源评测框架,研究团队使用统一可复现的方法,对书生·浦语3.0等模型进行了评测。评测采用了CMMLU、GPQA等十多个权威评测集,维度包括推理、数学、编程、指令跟随、长文本、对话及综合表现等多方面性能。评测结果显示,相比同量级开源模型,书生·浦语3.0在大多数评测集得分领先,综合性能十分接近GPT-4o-mini。
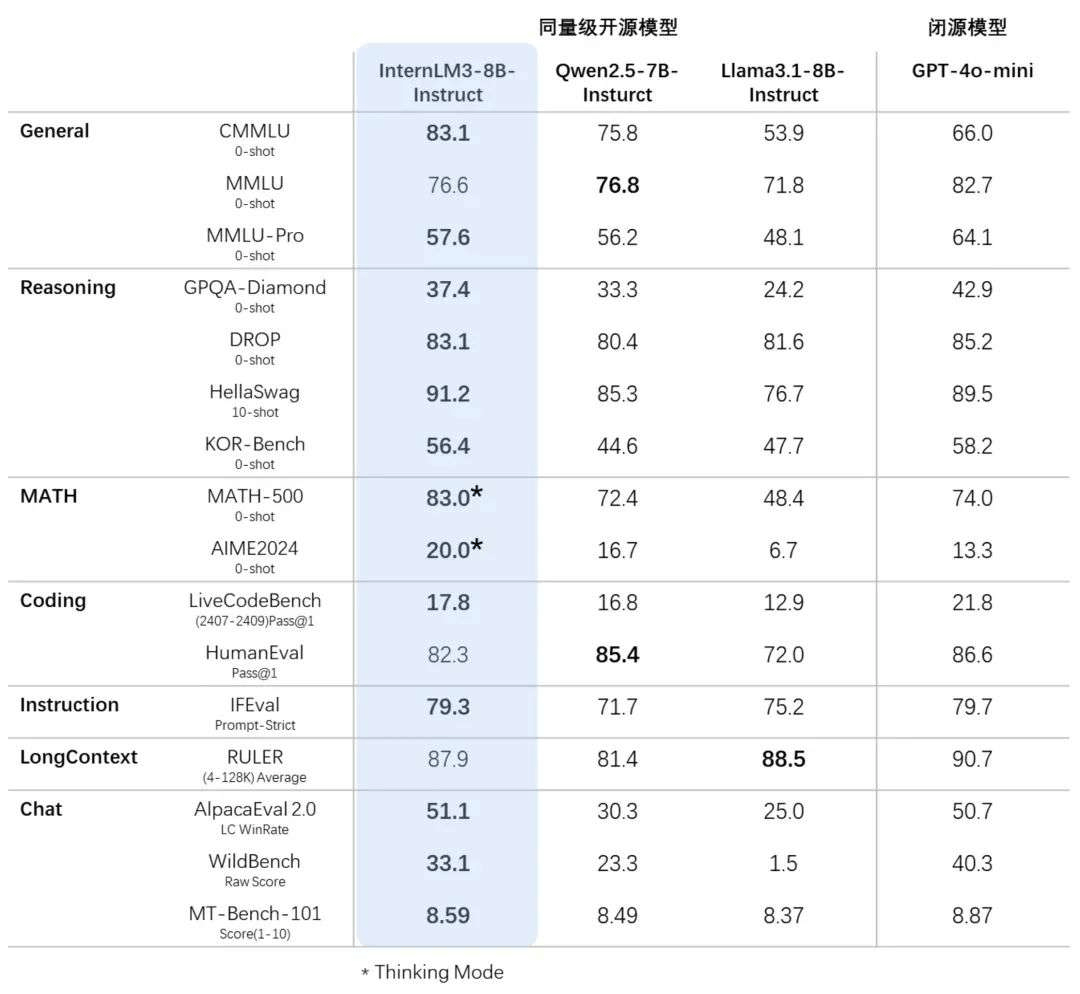
InternLM3采用“通专融合”路径,首次在通用模型中融合深度思考与常规对话,突破业界常规。
此前,上海AI实验室的强推理模型书生InternThinker,在数学竞赛评测集上超越了 o1-preview,虽具备长思维、自我反思纠正能力,但需单独构建。而InternLM3通过融合训练方案,实现一键切换模式,具备深度思考能力。后训练阶段,构建合成数据探索方案,基于世界知识树(World Knowledge Tree)进行指令标注与合成,运用多智能体方式生成高质量回复,挖掘指令潜力,打造数十万微调指令数据集,大幅提升对话体验。
如下图所示,在进行推理任务时,用户可以将书生·浦语3.0从常规对话模式一键转变成深度思考模式。
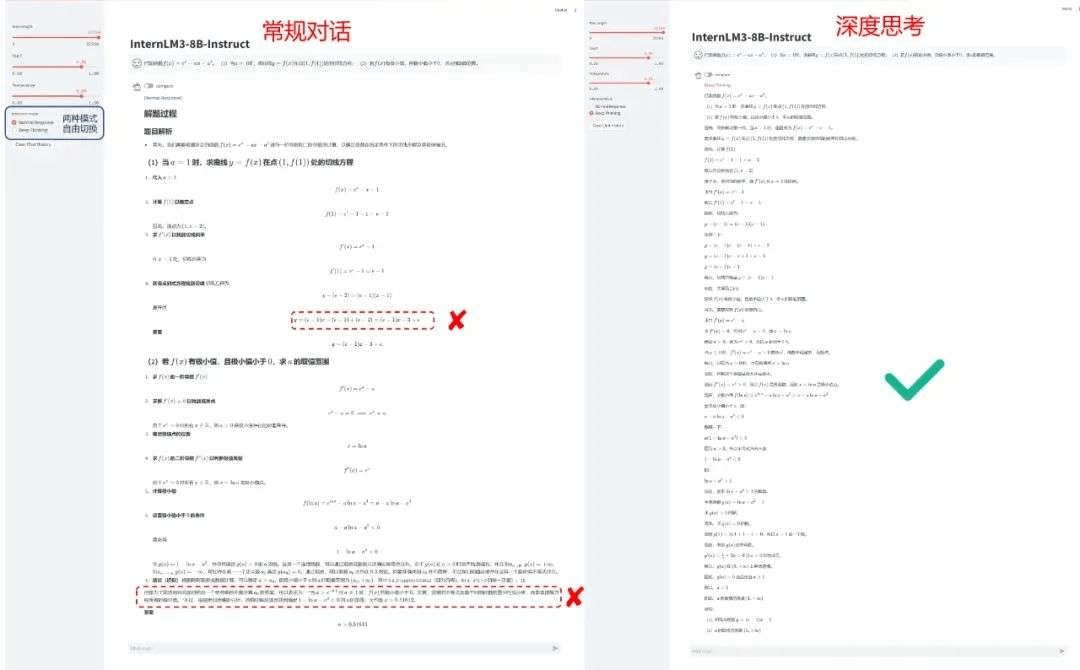
InternLM3在推理、数学、创作、智能体任务上均有非常优秀的表现,丰富案例可通过官方发布了解:书生·浦语大模型升级,突破思维密度,4T数据训出高性能模型
02.模型推理
使用transformers推理模型:
import torch
from modelscope import AutoTokenizer, AutoModelForCausalLM
model_dir = "Shanghai_AI_Laboratory/internlm3-8b-instruct"
#model = AutoModelForCausalLM(model_dir, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
# Set `torch_dtype=torch.float16` to load model in float16, otherwise it will be loaded as float32 and might cause OOM Error.
model = AutoModelForCausalLM.from_pretrained(model_dir, trust_remote_code=True, torch_dtype=torch.float16)
# (Optional) If on low resource devices, you can load model in 4-bit or 8-bit to further save GPU memory via bitsandbytes.
# InternLM3 8B in 4bit will cost nearly 8GB GPU memory.
# pip install -U bitsandbytes
# 8-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_8bit=True)
# 4-bit: model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, load_in_4bit=True)
model = model.eval()
model = model.cuda()
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文."""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": "Please tell me five scenic spots in Shanghai"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt").cuda()
generated_ids = model.generate(tokenized_chat, max_new_tokens=1024, temperature=1, repetition_penalty=1.005, top_k=40, top_p=0.8)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(tokenized_chat, generated_ids)
].cuda()
response = tokenizer.batch_decode(generated_ids)[0]
print(response)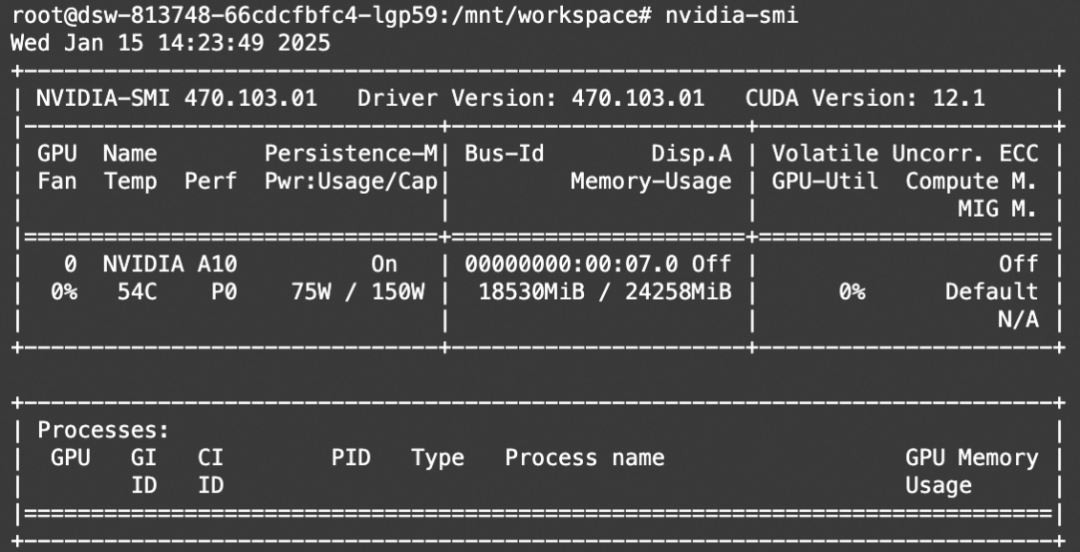
03.模型微调
这里我们介绍使用ms-swift 3.0对internlm3-8b-instruct进行自我认知微调。
在开始微调之前,请确保您的环境已正确安装
# 安装ms-swift
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .[llm]微调脚本如下:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Shanghai_AI_Laboratory/internlm3-8b-instruct \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--system 'You are a helpful assistant.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author 魔搭 \
--model_name 狗蛋训练显存占用:

推理脚本:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--temperature 0 \
--max_new_tokens 2048微调后推理效果:

点击链接,直达模型体验~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献659条内容
已为社区贡献659条内容

所有评论(0)