
Valley2,基于电商场景的多模态大模型
Valley2是一种新颖的多模态大型语言模型,旨在通过可扩展的视觉-语言设计增强各个领域的性能,并拓展电子商务和短视频场景的实际应用边界。
Valley2是一种新颖的多模态大型语言模型,旨在通过可扩展的视觉-语言设计增强各个领域的性能,并拓展电子商务和短视频场景的实际应用边界。Valley2在电子商务和短视频领域中实现了最先进的性能。它引入了如大视觉词汇、卷积适配器(ConvAdapter)和Eagle模块等创新,提高了处理多样化真实世界输入的灵活性,同时增强了训练和推理效率。
模型链接:
https://www.modelscope.cn/models/bytedance-research/Valley-Eagle-7B
代码链接:
https://github.com/bytedance/Valley
论文链接:
https://arxiv.org/abs/2501.05901
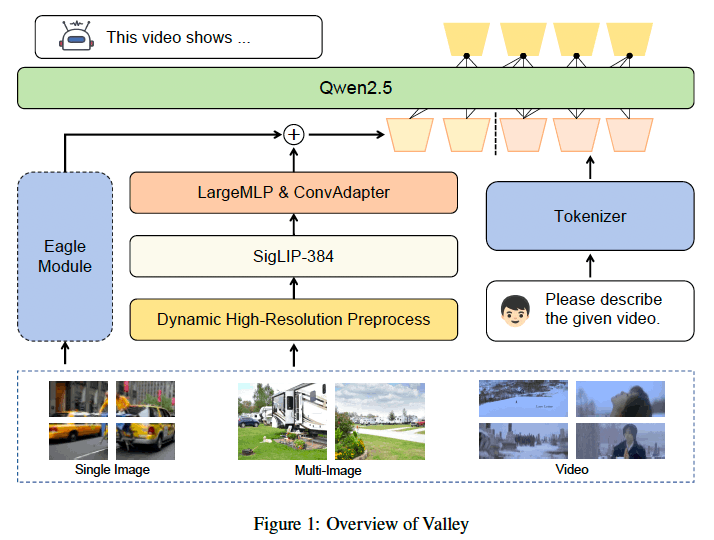
01.模型架构
采用了Qwen2.5作为其LLM主干,SigLIP-384作为视觉编码器,并结合MLP层和卷积进行高效的特征转换。
projector:采用了一个带有大型隐藏层MLP的projector,用轻量级的ConvAdapter替换了之前的PixelShuffle方法。
Eagle模块 :通过添加额外的视觉编码器以减少失真并确保兼容极端输入,从而扩展令牌表示。
数据
02.数据和训练方式
数据
Valley2的数据由三个部分组成:
-
OneVision风格的数据用于每个阶段的多模态大型模型训练。
-
针对电子商务和短视频领域的数据和评估。
-
构建用于复杂问题解决的链式思维(CoT)数据。
训练
训练过程包括四个阶段:文本-视觉对齐、高质量知识学习、指令微调以及链式思维后训练。

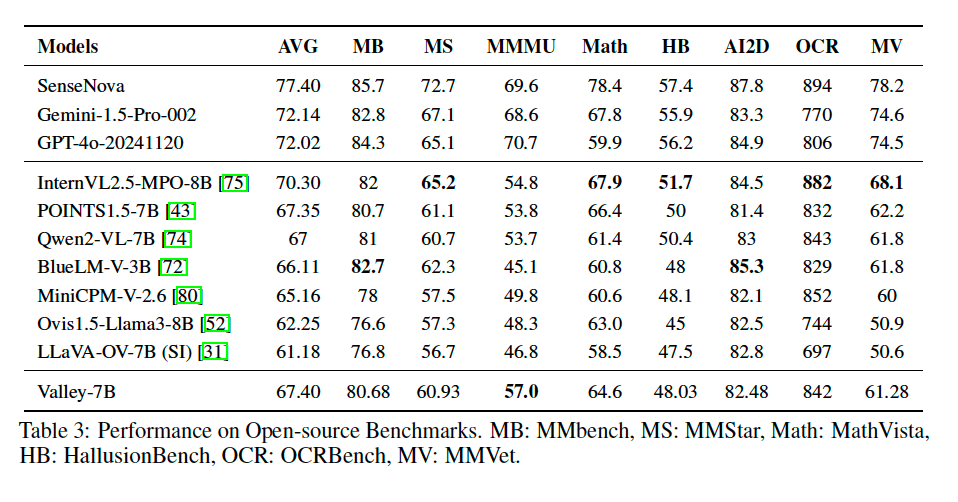
03.实验结果
Valley2在多个公开基准测试中表现优异,特别是在MMBench、MMStar、MathVista等多个基准上得分较高。此外,在Ecom-VQA基准测试中,Valley2也超越了其他相同规模的模型。
cot-post train 前后对比:
04.模型效果

05.模型推理
下载模型代码
!git clone https://github.com/bytedance/Valley.git
%cd Valley
模型推理
from valley_eagle_chat import ValleyEagleChat
from modelscope import snapshot_download
import urllib.request
# 需要把模型文件中的config.json的eagle_vision_tower和mm_vision_tower改为本地路径
model_dir = snapshot_download("bytedance-research/Valley-Eagle-7B")
!modelscope download --model=Qwen/Qwen2-VL-7B-Instruct --local_dir=./Qwen2-VL-7B-Instruct
!modelscope download --model=AI-ModelScope/siglip-so400m-patch14-384 --local_dir=./siglip-so400m-patch14-384
model = ValleyEagleChat(
model_path=model_dir,
padding_side = 'left',
)
url = 'http://p16-goveng-va.ibyteimg.com/tos-maliva-i-wtmo38ne4c-us/4870400481414052507~tplv-wtmo38ne4c-jpeg.jpeg'
img = urllib.request.urlopen(url=url, timeout=5).read()
request = {
"chat_history": [
{'role': 'system', 'content': 'You are Valley, developed by ByteDance. Your are a helpfull Assistant.'},
{'role': 'user', 'content': 'Describe the given image.'},
],
"images": [img],
}
result = model(request)
print(f"\n>>> Assistant:\n")
print(result)
from valley_eagle_chat import ValleyEagleChat
import decord
import requests
import numpy as np
from torchvision import transforms
model = ValleyEagleChat(
model_path=model_dir,
padding_side = 'left',
)
url = 'https://videos.pexels.com/video-files/29641276/12753127_1920_1080_25fps.mp4'
video_file = './video.mp4'
response = requests.get(url)
if response.status_code == 200:
with open("video.mp4", "wb") as f:
f.write(response.content)
else:
print("download error!")
exit(1)
video_reader = decord.VideoReader(video_file)
decord.bridge.set_bridge("torch")
video = video_reader.get_batch(
np.linspace(0, len(video_reader) - 1, 8).astype(np.int_)
).byte()
print([transforms.ToPILImage()(image.permute(2, 0, 1)).convert("RGB") for image in video])
request = {
"chat_history": [
{'role': 'system', 'content': 'You are Valley, developed by ByteDance. Your are a helpfull Assistant.'},
{'role': 'user', 'content': 'Describe the given video.'},
],
"images": [transforms.ToPILImage()(image.permute(2, 0, 1)).convert("RGB") for image in video],
}
result = model(request)
print(f"\n>>> Assistant:\n")
print(result)
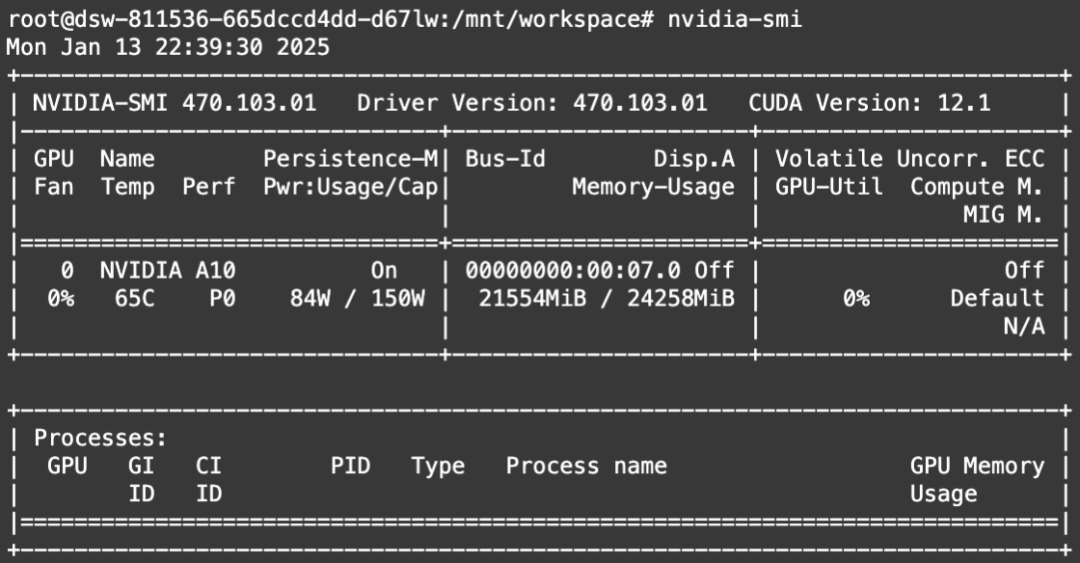
显存占用:
06.未来工作
计划发布包含文本、图像、视频和音频模态的全能模型,并引入基于Valley的多模态嵌入训练方法,以支持下游检索和探测应用。
总之,Valley2代表了多模态大型语言模型的一个重要进展,展示了如何通过改进结构、数据集构建及训练策略来提升模型性能。
点击链接阅读原文:Valley-Eagle-7B

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐
 0
0 0
0- 0



 已为社区贡献477条内容
已为社区贡献477条内容

所有评论(0)