
极致的显存管理!6G显存运行混元Video模型
混元 Video 模型自发布以来,已成为目前效果最好的开源文生视频模型,然而,这个模型极为高昂的硬件需求让大多数玩家望而却步。魔搭社区的开源项目 DiffSynth-Studio 近期为混元 Vide
混元 Video 模型自发布以来,已成为目前效果最好的开源文生视频模型,然而,这个模型极为高昂的硬件需求让大多数玩家望而却步。魔搭社区的开源项目 DiffSynth-Studio 近期为混元 Video 模型提供了更高效的显存管理的支持,目前已支持使用24G显存进行无任何质量损失的视频生成,并在极致情况下,用低至 6G 的显存运行混元 Video 模型!
模型官网:
https://aivideo.hunyuan.tencent.com/
魔搭社区模型链接:
https://modelscope.cn/models/AI-ModelScope/HunyuanVideo
开源项目 DiffSynth-Studio 链接:
https://github.com/modelscope/DiffSynth-Studio
01.样例展示
先来看几个由 混元 Video 模型,在DiffSynth-Studio 引擎上基于无损的优化实现,在仅占用24G显存的情况下生成的视频!
活泼可爱的动物:
https://developer.aliyun.com/live/254774?spm=a2c6h.26396819.creator-center.22.404f3e184PVTfF
精细的人像:
复杂的多人场景:
大幅度的运镜:
呼之欲出的画作:
02.显存管理
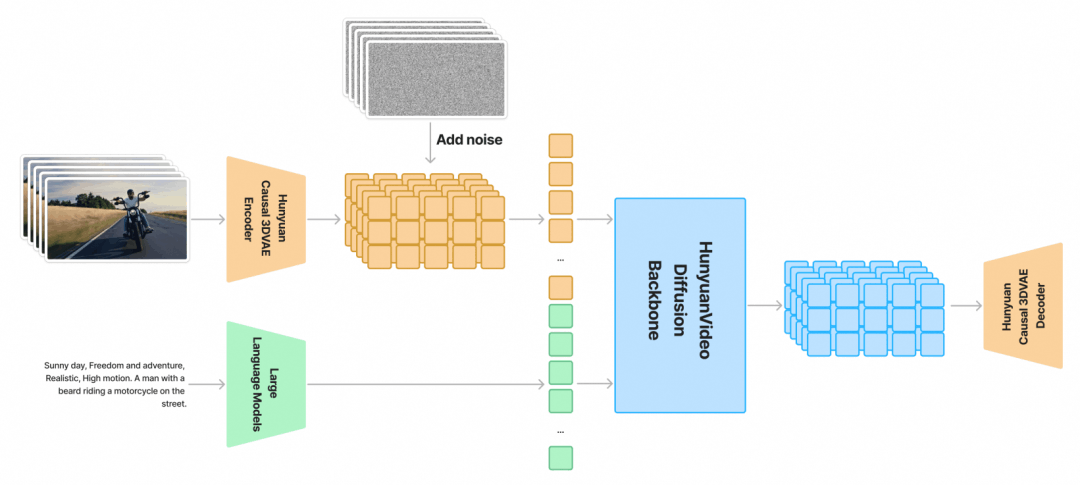
混元 Video 模型沿用了自 Latent Diffusion 以来的经典“三段式”模型结构,包括 Text encoder、DiT、VAE。这三部分是按顺序调用的,所以我们可以进行 offload,在不调用模型时将其从显存中移动到内存中。但只做 offload 是远远不够的,我们还需要对每一个模块进行优化。
VAE
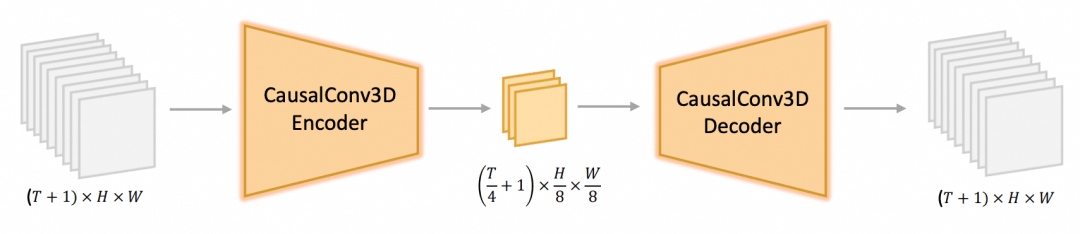
显存的第一个瓶颈在 VAE。VAE 部分基于 CausalConv3D 构建,这个结构与 OpenSoraPlan、CogVideoX 非常相似。在空间维度上,每个 8*8 的区域合并成一组向量;在时间维度上,把第一帧单独编码,其后的每 4 帧压缩成一组向量。
CogVideoX 的实践经验表明,以滑动窗口的方式进行 VAE 编解码不会对结果产生明显影响,但能够显著减少显存需求。以 129 帧 720P 视频为例,不开启滑动窗口时,80G 显存也无法进行推理,当滑动窗口大小为 17*16*16(对应 65 帧 128*128 分辨率的视频)时,显存需求可以降低到 6G。这部分优化在官方原版代码中已经实现,我们在 DiffSynth-Studio 中进行了重构以便更方便地控制窗口大小和步长。
DiT
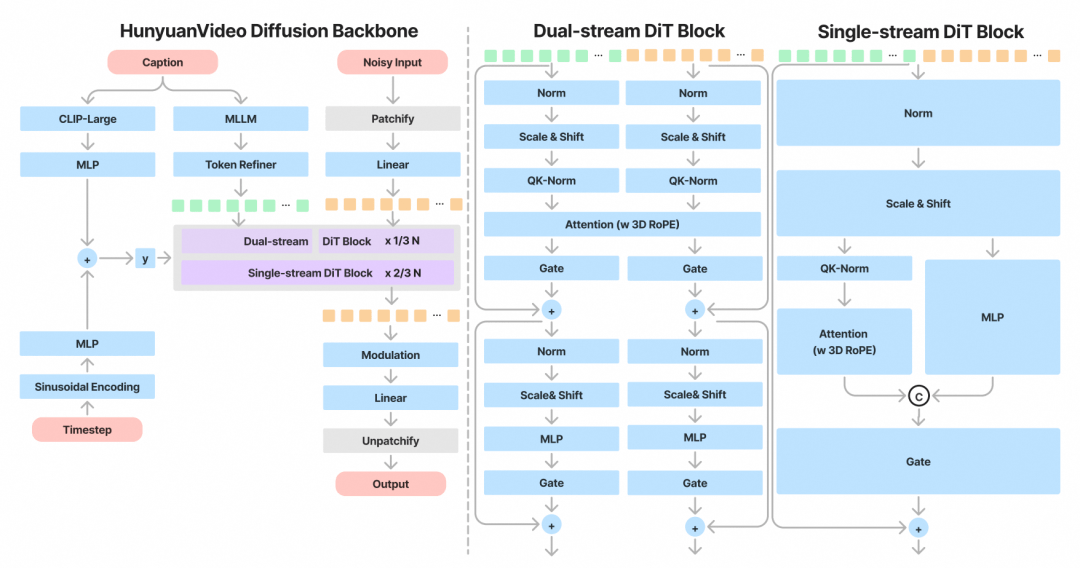
显存的第二个瓶颈在 DiT 部分,模型的参数量非常大,视频的向量表示也很大,所以我们做了非常激进的显存管理策略——逐个 Layer offload。把整个 DiT 模型放在内存中,在每个 Layer 推理时临时加载进显存,这样一来模型所占的显存几乎可以忽略不计。在大部分模型上,这种激进的显存管理策略会显著增加推理时间,但对于混元 DiT 模型来说,模型本身前向推理一次就需要 60s(A100 上的测试结果),显存管理只会增加约 3s 的推理时间,这部分时间完全可以接受。DiT 的优化足以把显存需求降低到 24G。
Text Encoder
129 帧 720P 视频的显存优化已经接近极限,但我们也注意到近期开源社区中出现的在低分辨率下训练的 LoRA 模型。混元 Video 模型在低分辨率下的效果并不好,但是这些 LoRA 可以很好地改善模型在低分辨率下的效果。例如 WalkingAnimation(可在 CivitAI:https://civitai.com/models/1032126/walking-animation-hunyuan-video 或魔搭社区:https://modelscope.cn/models/AI-ModelScope/walking_animation_hunyuan_video/summary下载),其训练分辨率为 512*384。在这个分辨率下,显存的第三个瓶颈出现在 Text Encoder 上。
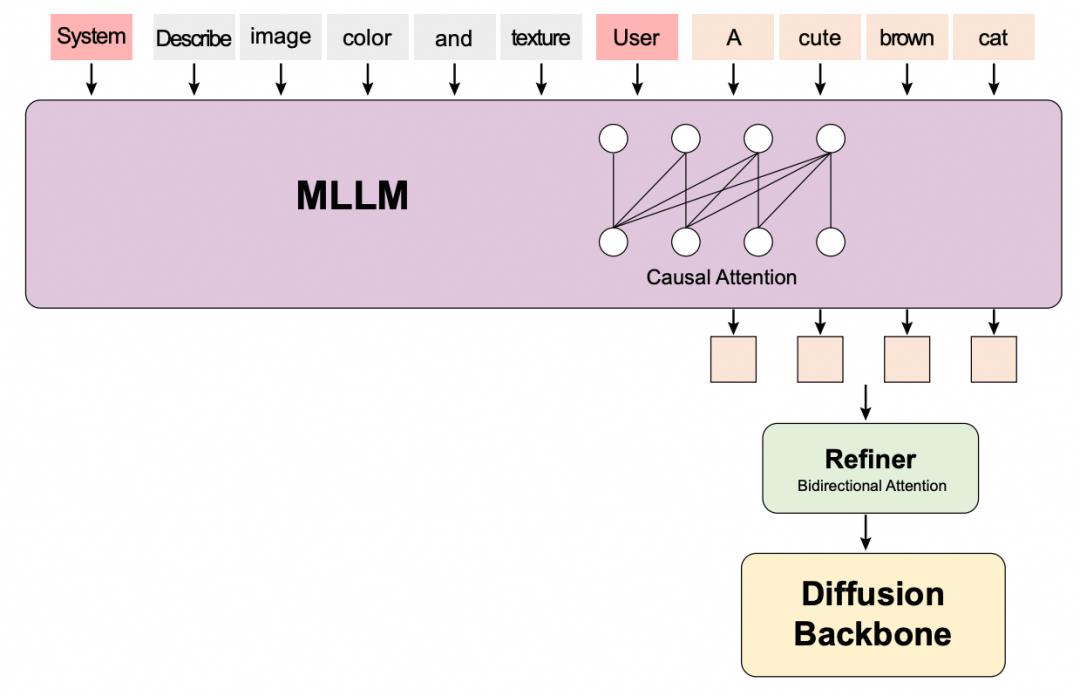
混元 Video 的 Text Encoder 有两个——CLIP 和 LLaVA,其中 CLIP 所需的显存很小,但 LLaVA 作为一个 LLM,需要至少 16G 显存。与 DiT 类似,我们在 LLaVa 上也进行逐个 Layer offload,成功将其显存需求降低到 6G 以内。
03.代码样例
首先 clone 并安装 DiffSynth-Studio:https://github.com/modelscope/DiffSynth-Studio
git clone https://github.com/modelscope/DiffSynth-Studio.git
cd DiffSynth-Studio
pip install -e .我们提供了三种显存限制下的样例脚本,用于应对不同的硬件限制。
80G
代码链接
https://github.com/modelscope/DiffSynth-Studio/blob/main/examples/HunyuanVideo/hunyuanvideo_80G.py
运行命令:
python examples/HunyuanVideo/hunyuanvideo_80G.py
帧数:129
分辨率:720*1280
对于 A100 和 H100 等大显存 GPU,无需显存管理。我们把原版模型代码中的 flash attention 替换为了 torch 的 scaled_dot_product_attention,这个函数会自动根据硬件选择最佳的注意力机制实现。以下是这个脚本生成的视频:
24G
代码链接
https://github.com/modelscope/DiffSynth-Studio/blob/main/examples/HunyuanVideo/hunyuanvideo_24G.py
运行命令:
python examples/HunyuanVideo/hunyuanvideo_24G.py
帧数:129
分辨率:720*1280
这个脚本启用了本文中提到的所有显存管理。由于没有使用模型量化,所以不存在任何量化误差,生成的视频与脚本hunyuanvideo_80G.py完全一致。
6G
代码链接
https://github.com/modelscope/DiffSynth-Studio/blob/main/examples/HunyuanVideo/hunyuanvideo_6G.py
运行命令:
python examples/HunyuanVideo/hunyuanvideo_6G.py
帧数:129
分辨率:512*384
这个脚本使用了 WalkingAnimation(可在 CivitAI 或魔搭社区下载)这个 LoRA 来改善混元 Video 底模在低分辨率下的效果。这个 LoRA 可以生成各种人物的行走动作。通过在代码中修改 prompt,我们可以生成各种动漫角色行走动作的视频,以下是这个脚本生成的视频:
此外,我们还额外提供了视频生视频的功能。
代码链接:
https://github.com/modelscope/DiffSynth-Studio/blob/main/examples/HunyuanVideo/hunyuanvideo_v2v_6G.py
运行命令:
python examples/HunyuanVideo/hunyuanvideo_v2v_6G.py
帧数:129
分辨率:512*384
使用这个脚本可以实现视频编辑,例如把以下视频中角色的衣服颜色修改为紫色,所需的显存仍然是 6G。
点击链接阅读原文:腾讯混元视频生成HunyuanVideo

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献665条内容
已为社区贡献665条内容

所有评论(0)