
魔搭社区每周速递(12.22-12.28)
魔搭ModelScope本期社区进展:1039个模型,128个数据集,63个创新应用,6篇内容。

🙋魔搭ModelScope本期社区进展:
📟1039个模型:DeepSeek-V3、QVQ-72B-Preview、ModernBERT、InternVL2_5-26B-MPO-AWQ等;
📁128个数据集:SWE-agent-trajectories、SWE-bench-extra、fineweb-c等;
🎨63个创新应用:QVQ-72B-preview、HelloMeme、CogAgent-Demo等;
📄 6篇内容:
-
魔搭llamafile集成:让大模型开箱即用
-
ModernBERT-base:终于等到了 BERT 回归
-
Qwen开源视觉推理模型QVQ,更睿智地看世界!
-
MNN推理框架将大模型放进移动端设备,并达到SOTA推理性能!
-
1分钟,用咒语+qwen-coder手搓一张会下雪的圣诞贺卡
-
HelloMeme:充分利用 SD1.5 基模的理解能力,实现表情与姿态的迁移
01.精选模型
DeepSeek-V3
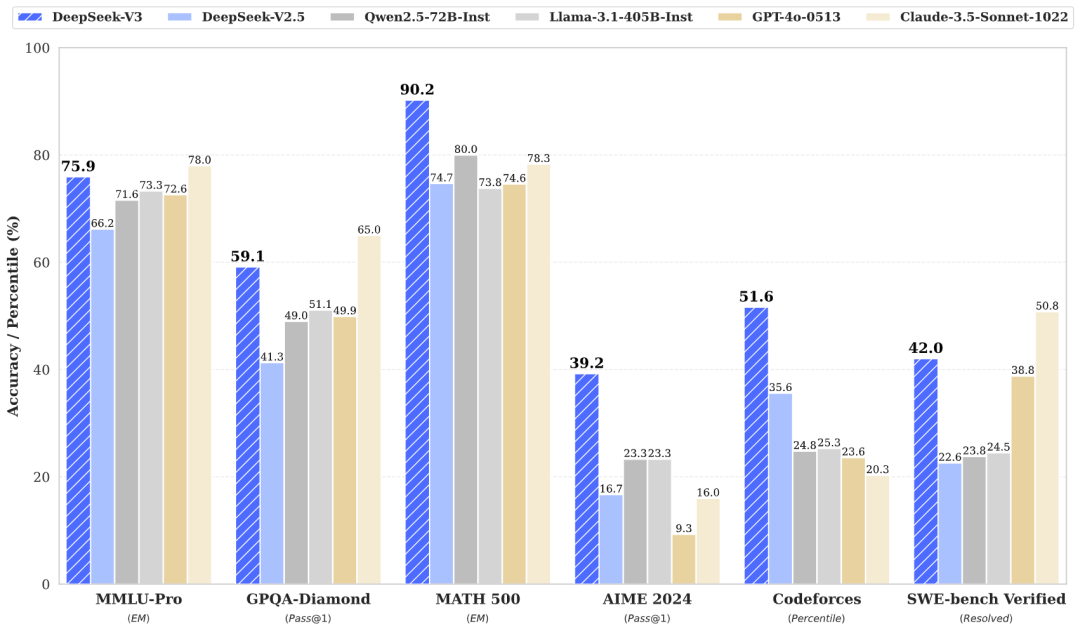
DeepSeek-V3是幻方最新推出的一个强大的专家混合(MoE)语言模型,总参数量为 6710 亿,每个 token 激活 370 亿参数。为了实现高效推理和具有成本效益的训练,DeepSeek-V3 延续前一代 DeepSeek-V2 依然采用了多头潜在注意力(MLA)和 DeepSeekMoE 架构。
DeepSeek-V3 在各项性能测试中均表现优异,在 MMLU、MMLU-Pro 和 GPQA中,分别取得了 88.5、75.9 和 59.1 的高分,超越了所有其他开源模型,并在性能上接近封闭模型如 GPT-4o 和 Claude-Sonnet-3.5。
模型链接:
DeepSeek-V3:
https://www.modelscope.cn/models/deepseek-ai/DeepSeek-V3
DeepSeek-V3-Base:
https://www.modelscope.cn/models/deepseek-ai/DeepSeek-V3-Base
QVQ-72B-Preview:
QVQ-72B-Preview是Qwen团队最新开源的视觉推理模型,基于 Qwen2-VL-72B 构建,专长于视觉理解和推理。在MMMU多学科评测中得分70.3,超越前代。在MathVista、MathVision和OlympiadBench等数学科学领域基准测试中,表现卓越,展现了其在复杂数学和科学问题解决上的强大能力。
模型链接:
https://modelscope.cn/models/Qwen/QVQ-72B-Preview
示例代码
transformers推理代码:
from modelscope import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
"Qwen/QVQ-72B-Preview", torch_dtype="auto", device_map="auto"
)
# default processer
processor = AutoProcessor.from_pretrained("Qwen/QVQ-72B-Preview")
# The default range for the number of visual tokens per image in the model is 4-16384. You can set min_pixels and max_pixels according to your needs, such as a token count range of 256-1280, to balance speed and memory usage.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/QVQ-72B-Preview", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are a helpful and harmless assistant. You are Qwen developed by Alibaba. Answer in the language of the question. You should think step-by-step."}
],
},
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/QVQ/demo.png",
},
{"type": "text", "text": "What value should be filled in the blank space?"},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=8192)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)更多详情请见:
ModernBERT
ModernBERT是由Answer.AI 和 LightOn 发布的一款现代化的双向编码器 Transformer 模型(BERT 风格),预训练于 2 万亿个英文和代码数据标记,原生上下文长度可达 8,192 个token。集成了Rotary Positional Embeddings、Unpadding、GeGLU层、Alternating Attention和Flash Attention等多项最新架构改进,专为跨推理GPU的高效率设计。
ModernBERT 的原生长上下文长度使其非常适合需要处理长文档的任务,例如检索、分类和大型语料库内的语义搜索。该模型在大量的文本和代码语料库上进行了训练,适用于广泛的下游任务,包括代码检索和混合(文本 + 代码)语义搜索。
模型链接:
ModernBERT-base:
https://modelscope.cn/models/AI-ModelScope/ModernBERT-base
ModernBERT-large:
https://modelscope.cn/models/AI-ModelScope/ModernBERT-large
示例代码:
环境安装
!pip install git+https://github.com/huggingface/transformers.git使用 AutoModelForMaskedLM模型推理
from transformers import AutoTokenizer, AutoModelForMaskedLM
from modelscope import snapshot_download
model_id = snapshot_download("answerdotai/ModernBERT-base")
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
text = "The capital of France is [MASK]."
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
# To get predictions for the mask:
masked_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)
predicted_token_id = outputs.logits[0, masked_index].argmax(axis=-1)
predicted_token = tokenizer.decode(predicted_token_id)
print("Predicted token:", predicted_token)
# Predicted token: Paris使用pipeline:
import torch
from transformers import pipeline
from pprint import pprint
pipe = pipeline(
"fill-mask",
model="answerdotai/ModernBERT-base",
torch_dtype=torch.bfloat16,
)
input_text = "He walked to the [MASK]."
results = pipe(input_text)
pprint(results)更多详见:
ModernBERT-base:终于等到了 BERT 回归
02.数据集推荐
SWE-agent-trajectories
数据集包含80,036条由SWE-agent框架生成的软件工程代理轨迹,旨在解决GitHub问题并生成代码补丁。
数据集链接:
https://modelscope.cn/datasets/AI-ModelScope/SWE-agent-trajectories
SWE-bench-extra
数据集包含6,415个来自1,988个Python存储库的问题-拉取请求对,旨在训练和评估解决GitHub问题的软件工程代理系统,通过基于执行的验证和过滤步骤确保数据质量。
数据集链接:
https://modelscope.cn/datasets/AI-ModelScope/SWE-bench-extra
fineweb-c
这个基于FineWeb2数据集的社区项目旨在通过多语言教育内容注释,提升全球人工智能技术的可访问性和效果,特别是优化大型语言模型的开发。
数据集链接:
https://modelscope.cn/datasets/AI-ModelScope/fineweb-c
03.精选应用
QVQ-72B-preview
QVQ是一个开源多模态推理模型,基于Qwen2-VL-72B构建,通过结合视觉理解和复杂问题解决能力,在MMMU评测中获得70.3分的优异成绩,尤其在需要复杂分析思维的视觉推理任务中表现出色。
体验直达:
https://modelscope.cn/studios/Qwen/QVQ-72B-preview
-
小程序:
HelloMeme
用户可以直接上传图片或视频,尝试不同的模型版本,生成具有丰富表情和自然姿态的结果。此外,HelloMeme还支持视频生成,展现了在复杂视觉任务中的潜力。
体验直达:
https://modelscope.cn/studios/songkey/HelloMeme
-
小程序:
CogAgent-Demo
支持上传mac截图,并输入指令之后会在右侧显示出图像区域
体验直达:
https://modelscope.cn/studios/ZhipuAI/CogAgent-Demo
-
小程序:
04.社区精选文章

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献644条内容
已为社区贡献644条内容

所有评论(0)