

CompassArena上新!JudgeCopilot与新一代Bradley-Terry模型竞技体验
2024 年 5 月,上海人工智能实验室司南 OpenCompass 团队携手魔搭 ModelScope,联合推出了大模型评测平台——CompassArena(大模型竞技场),为大模型领域引入了一种全
2024 年 5 月,上海人工智能实验室司南 OpenCompass 团队携手魔搭 ModelScope,联合推出了大模型评测平台——CompassArena(大模型竞技场),为大模型领域引入了一种全新的竞技模式。
平台自上线以来广受关注,在过去的几个月里,吸引了海量社区用户踊跃参与并无私贡献。依托用户的真实体验数据,CompassAren 持续优化,如今迎来新升级,将为用户带来更加科学、全面的模型评估体验!
此次升级亮点:
-
全新 Judge Copilot 功能,充分利用强大的评价模型,快速评估两大模型之间的优劣,为用户提供精准、高效的主观评测辅助。
-
榜单算法全新升级,对原始的 Bradley-Terry 统计算法进行了改进,通过引入控制变量来降低混淆因素的影响,让模型排名更加科学、精准。
-
新增 20+ 全新模型,涵盖国内外商业模型及开源模型,进一步丰富了对战体验。
魔搭社区体验链接:
https://www.modelscope.cn/studios/opencompass/CompassArena
全新 Judge Copilot 功能:
评价大模型打辅助,主观评测更准更有趣
CompassArena 全新上线的 Judge Copilot 功能,充分利用了强大的评价模型(LLM-as-a-Judge ) Compass-Judger-1-32B-Instruct,为用户带来了全方位对比分析对话模型表现的能力。无论是模型的逻辑性、创造性,还是语言表达的流畅性,Judge Copilot 都能快速评估两大模型之间的优劣,为用户提供精准、高效的主观评测辅助。
功能亮点
-
多维度评价:Judge Copilot 会从多个维度对模型的对话质量进行全面分析和综合比较。
-
实时对比:支持实时快速生成优劣对比结果,帮助用户直观判断模型表现。
-
智能决策辅助:为用户提供综合性推荐意见,降低主观评测的复杂性。
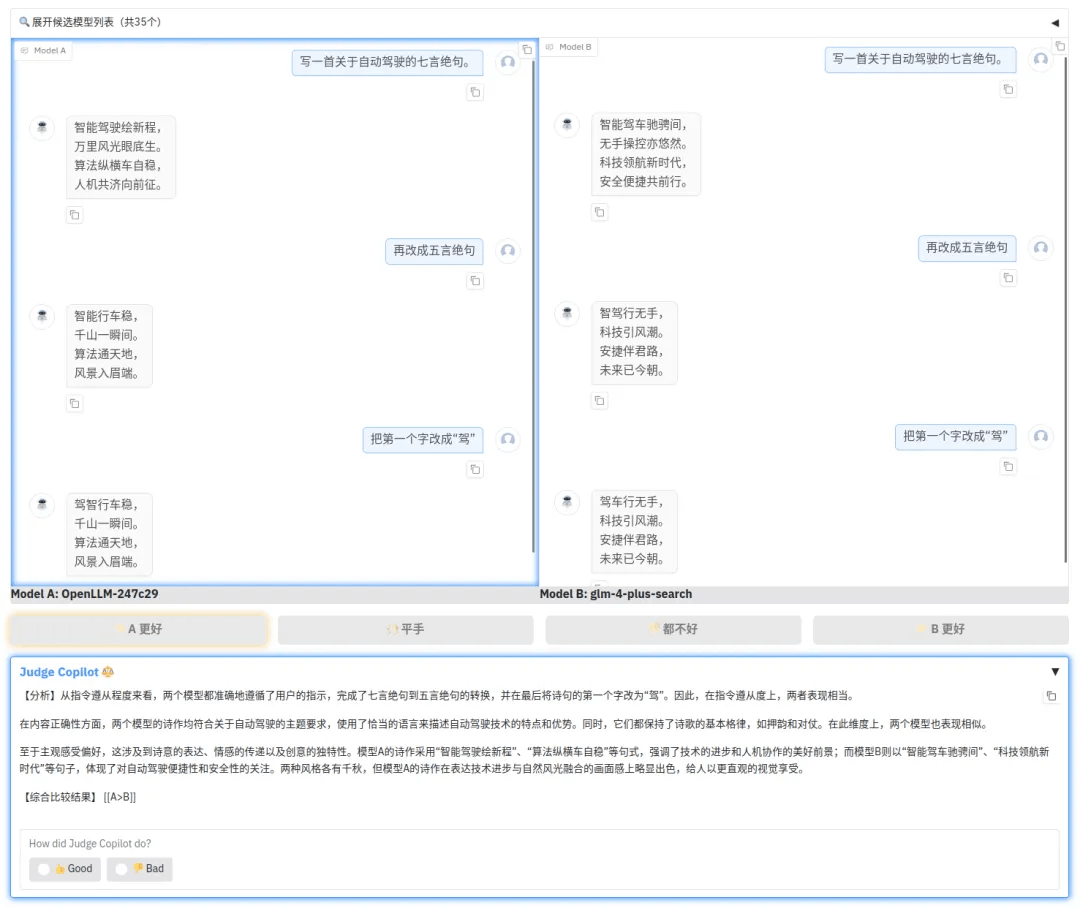
示例1
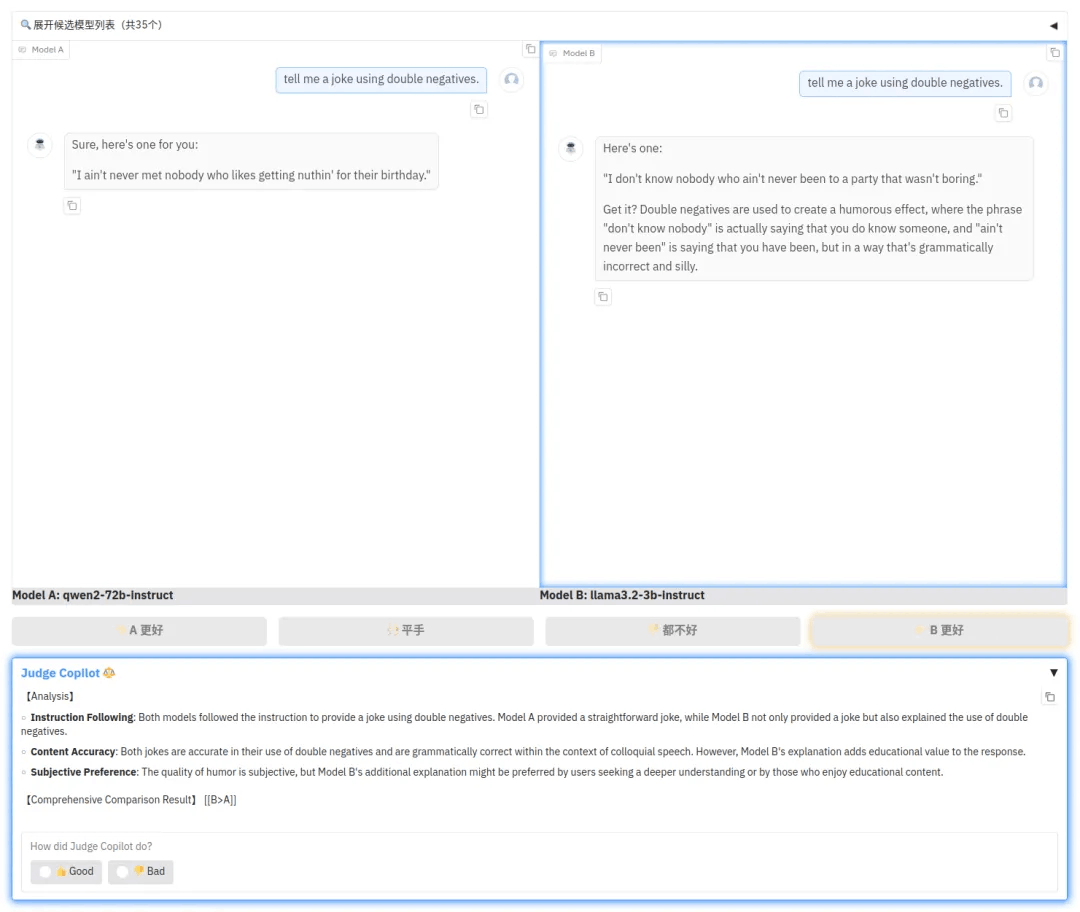
示例2
CompassArena 高度重视 Judge 模型在实际应用中的表现。为了进一步提升 Judge 模型的综合能力和对齐效果,CompassArena 将积极收集用户的反馈意见。用户可以通过点击“赞”和“踩”按钮来表达他们对 Judge 模型的评价。
榜单算法升级:
Bradley-Terry 模型 + 控制变量
为了进一步提升榜单的准确性,CompassArena 对原始的 Bradley-Terry 统计算法进行了改进,通过引入控制变量来降低混淆因素的影响,让模型排名更加科学、精准。
引入控制变量
Bradley-Terry 模型是一种广泛应用于排名和比较的统计方法,用于估计模型的强度系数。然而,这个强度系数的估计有可能受模型能力以外的因素的影响,如模型的输出长度、输出风格和模型是否使用了外部工具辅助。
在此次升级中,CompassArena 借鉴了 LMSYS Chatbot Arena 的风格控制(style control)方法,并在此基础上进行了改进,使排名计算更加精确和可解释。具体来说:
-
风格控制变量的改进:在风格特征的定义中,CompassArena 增加了额外的回复风格统计(如表情符号数量),使风格控制更加适应多样化的输出样式。
-
去除归一化步骤:在计算长度与风格变量的相对差值时,CompassArena 去除了归一化的步骤,使模型的系数具有更直观的解释,同时不影响对系数估计的准确性。
-
新增搜索功能控制变量:CompassArena 进一步引入了“是否开启搜索功能”这一控制变量,用于区分模型在使用外部工具辅助时的表现差异。
通过这些改进,CompassArena 对模型对战结果的影响因素进行了更精细的控制,有效减少了混淆因素对排名的干扰。在因果推断中,混淆因素会同时影响因变量和自变量,从而导致模型系数的偏差。通过改进后的 Bradley-Terry 模型,CompassArena 能够更准确地分离干扰因素,确保排名更加准确和公正。
控制变量定义:
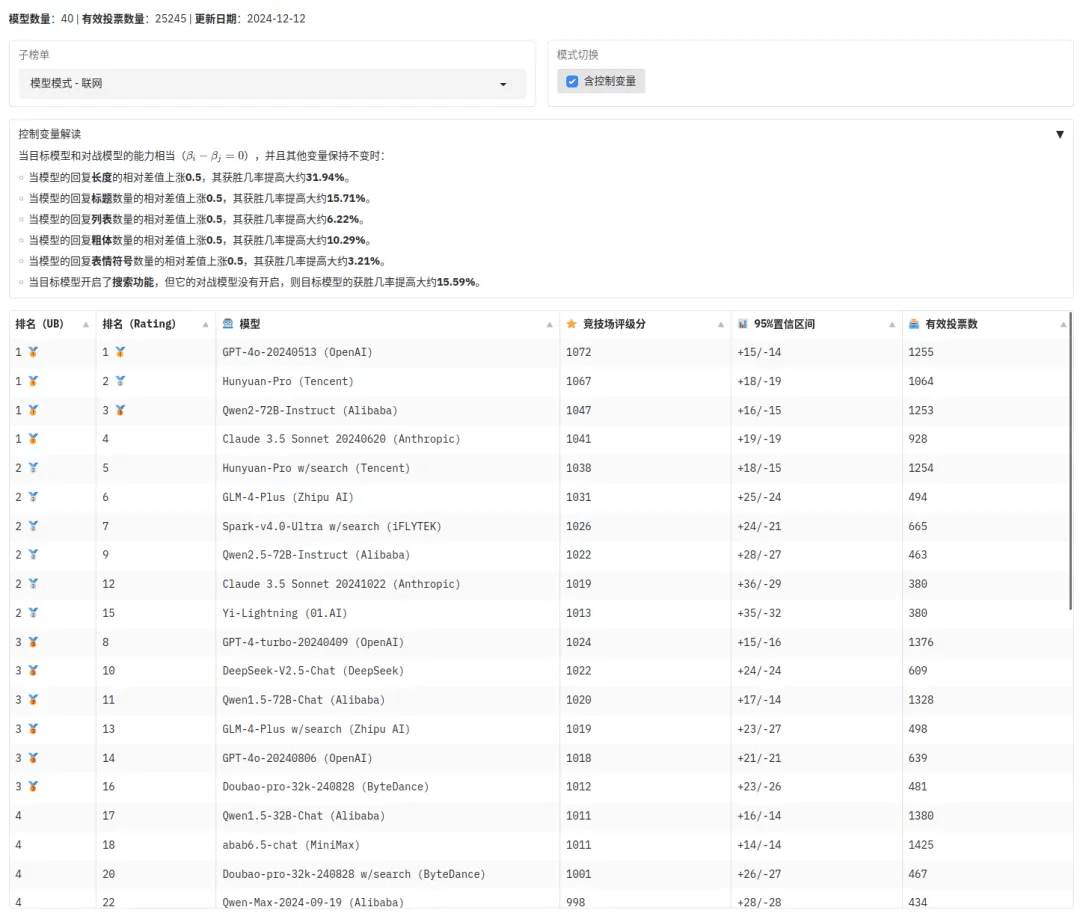
添加图片注释,不超过 140 字(可选)
在榜单界面将模式切换成“含控制变量”后,页面将显示控制变量的相关解读,同时模型排名也会随之更新
引入控制变量前后排名对比
我们可以通过对比加入和不加入控制变量的 Bradley-Terry 模型拟合结果分析这些外在因素对模型能力评估的影响。
原始 Bradley-Terry 算法下的排名:
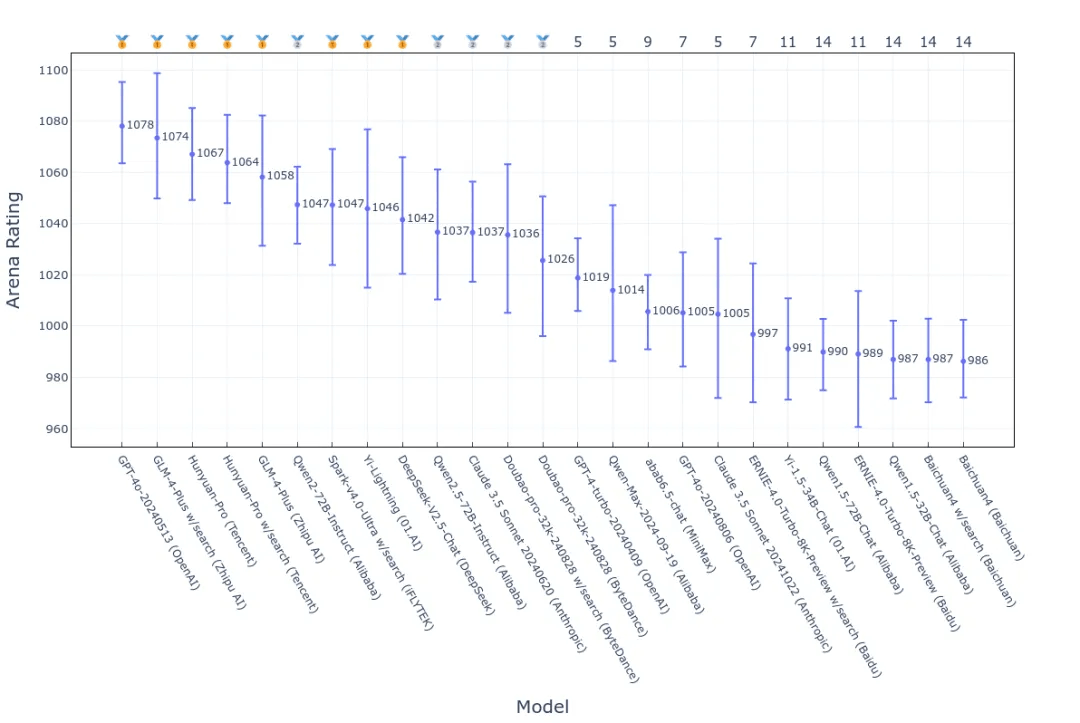
添加图片注释,不超过 140 字(可选)
引入控制变量后的排名:
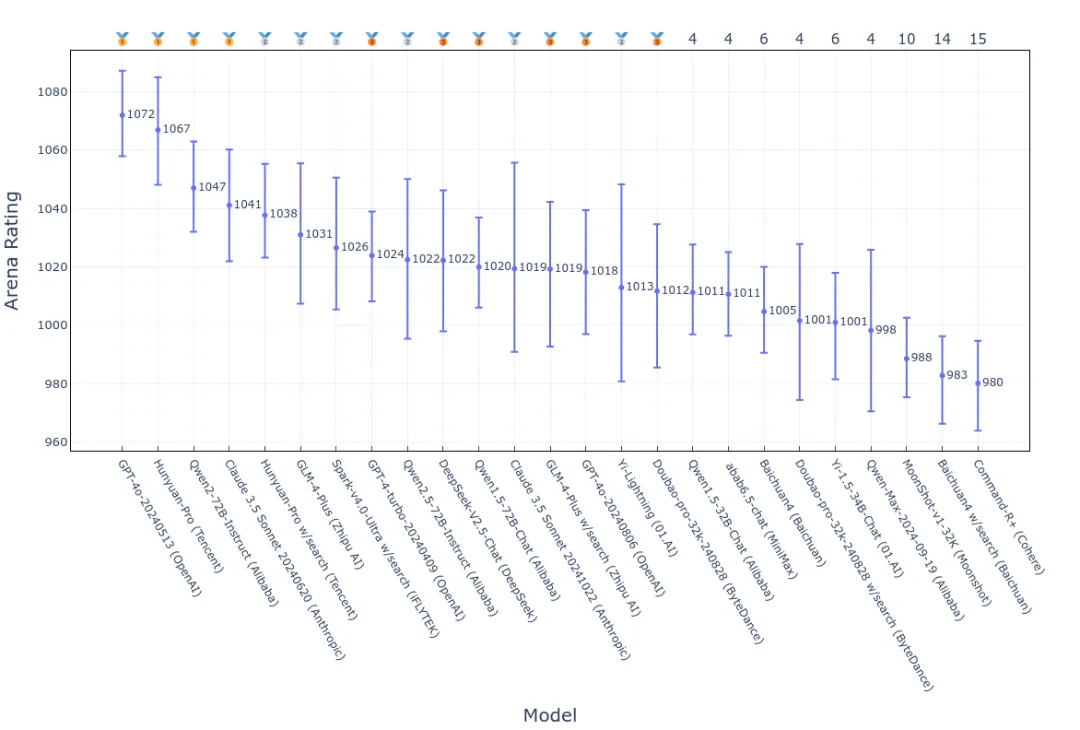
添加图片注释,不超过 140 字(可选)
经过对比分析后发现:
-
第一梯队模型的变化:GPT-4o-20240513 在引入控制变量后仍稳居首位,表明其出色表现主要归功于模型自身的强大能力,而非外部因素的影响。相比之下,其他排名靠前的大模型,如 GLM-4-Plus、Hunyuan-Pro 和 Qwen2-72B-Instruct,则在一定程度上受到对话风格和搜索功能的影响,导致其排名发生变化。
-
风格因素对个别模型的影响显著:引入风格控制后,Claude 3.5 Sonnet 20240620 和 GPT-4-turbo-20240409 分别大幅上升了七位和六位排名,而 Yi-Lightning 则下滑了七位排名。
-
搜索功能对大模型的增益作用:引入搜索功能的控制变量后,具备搜索功能的模型(标记为 w/search)的排名发生了显著变化。例如,GLM-4-Plus w/search、Doubao-pro-32k-240828 w/search 和 ERNIE-4.0-Turbo-8K-Preview w/search 的排名均比原排名下降了至少五位。值得注意的是,Hunyuan-Pro w/search 和 Spark-v4.0-Ultra w/search 的排名在控制搜索功能后并未发生明显变化,这表明这些模型的能力估计较为准确,受搜索功能的影响较小。
-
置信区间的扩大:引入额外的控制变量可能会增加大模型能力估计的不确定性,尤其是在样本量有限或不变的情况下,回归模型的复杂度增加,导致置信区间变宽。
控制变量解析
通过拟合包含控制变量的 Bradley-Terry 统计模型,我们可以估计众多外在因素的影响程度。具体影响程度可以通过几率比(OddsRatio)的形式表达:

在以上公式中:
-
为控制变量 的回归系数
-
为控制变量 的几率比,即大模型获胜几率(winning odds)在控制变量 增加 个单位时的乘法增长量
当目标模型和对战模型的能力相当( ),并且其他变量保持不变时:
-
当模型的回复长度的相对差值上涨 0.5,其获胜几率提高大约 31.94%。
-
当模型的回复标题数量的相对差值上涨 0.5,其获胜几率提高大约 15.71%。
-
当模型的回复列表数量的相对差值上涨 0.5,其获胜几率提高大约 6.22%。
-
当模型的回复粗体数量的相对差值上涨 0.5,其获胜几率提高大约 10.29%。
-
当模型的回复表情符号数量的相对差值上涨 0.5,其获胜几率提高大约 3.21%。
-
当目标模型开启了搜索功能,但它的对战模型没有开启,则目标模型的获胜几率提高大约 15.59%。
新增模型一览
此次升级,我们迎来了 20+ 全新模型的加入,涵盖国内外商业模型及开源模型,进一步丰富了对战体验。
国内商业模型
-
360gpt2-pro
-
deepseek-v2.5-chat
-
doubao-pro-32k-240828
-
ernie-4.0-turbo-8k-preview
-
glm-4-plus
-
qwen-max-2024-09-19
-
spark4.0-ultra
国外商业模型
-
claude-3.5-sonnet-20241022
-
gemini-exp-1121
-
gpt-4o-2024-11-20
-
gpt-4o-2024-08-06
-
o1-preview-2024-09-20
开源模型
-
c4ai-command-r-plus-08-2024
-
llama3.1-8b-instruct
-
llama3.1-70b-instruct
-
llama3.1-405b-instruct
-
llama3.2-3b-instruct
-
Ministral-8B-Instruct-2410
-
Mistral-Large-Instruct-2407
-
Mistral-Small-Instruct-2409
-
qwen2.5-7b-instruct
-
qwen2.5-14b-instruct
-
qwen2.5-32b-instruct
-
qwen2.5-72b-instruct
-
yi-lightning

此次新增模型所属机构一览(排名不分先后)
欢迎大家点击下方链接或点击“阅读原文”,体验相关功能及查看完整对战榜单!
魔搭社区体验链接:
https://www.modelscope.cn/studios/opencompass/CompassArena

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献449条内容
已为社区贡献449条内容

所有评论(0)