
Megrez-3B-Omni: 首个端侧全模态理解开源模型
Megrez-3B-Omni是由无问芯穹(Infinigence AI)研发的端侧全模态理解模型,基于无问大语言模型Megrez-3B-Instruct扩展,同时具备图片、文本、音频三种模态数据的理解
01.引言

Megrez-3B-Omni是由无问芯穹(Infinigence AI)研发的端侧全模态理解模型,基于无问大语言模型Megrez-3B-Instruct扩展,同时具备图片、文本、音频三种模态数据的理解分析能力,在三个方面均取得最优精度:
-
在图像理解方面,基于SigLip-400M构建图像Token,在OpenCompass榜单上(综合8个主流多模态评测基准)平均得分66.2,超越LLaVA-NeXT-Yi-34B等更大参数规模的模型。Megrez-3B-Omni也是在MME、MMMU、OCRBench等测试集上目前精度最高的图像理解模型之一,在场景理解、OCR等方面具有良好表现。
-
在语言理解方面,Megrez-3B-Omni并未牺牲模型的文本处理能力,综合能力较单模态版本(Megrez-3B-Instruct)精度变化小于2%,保持在C-EVAL、MMLU/MMLU Pro、AlignBench等多个测试集上的最优精度优势,依然取得超越上一代14B模型的能力表现
-
在语音理解方面,采用Qwen2-Audio/whisper-large-v3的Encoder作为语音输入,支持中英文语音输入及多轮对话,支持对输入图片的语音提问,根据语音指令直接响应文本,在多项基准任务上取得了领先的结果
基础信息
|
|
Language Module |
Vision Module |
Audio Module |
|
Architecture |
Llama-2 with GQA |
SigLip-SO400M |
Whisper-large-v3 (encoder-only) |
|
# Params (Backbone) |
2.29B |
0.42B |
0.64B |
|
Connector |
- |
Cross Attention |
Linear |
|
# Params (Others) |
Emb: 0.31B Softmax: 0.31B |
Connector: 0.036B |
Connector: 0.003B |
|
# Params (Total) |
4B |
||
|
# Vocab Size |
122880 |
64 tokens/slice |
- |
|
Context length |
4K tokens |
||
|
Supported languages |
Chinese & English |
||
图片理解能力
Megrez-3B-Omni与其他开源模型在主流图片多模态任务上的性能比较
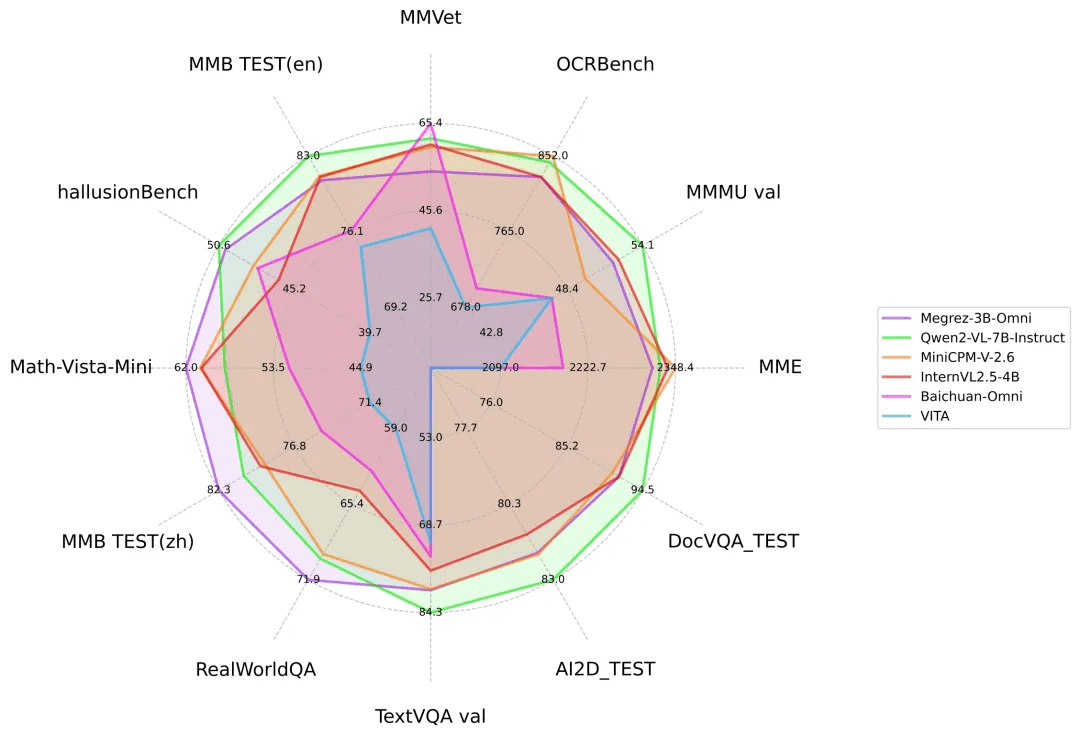
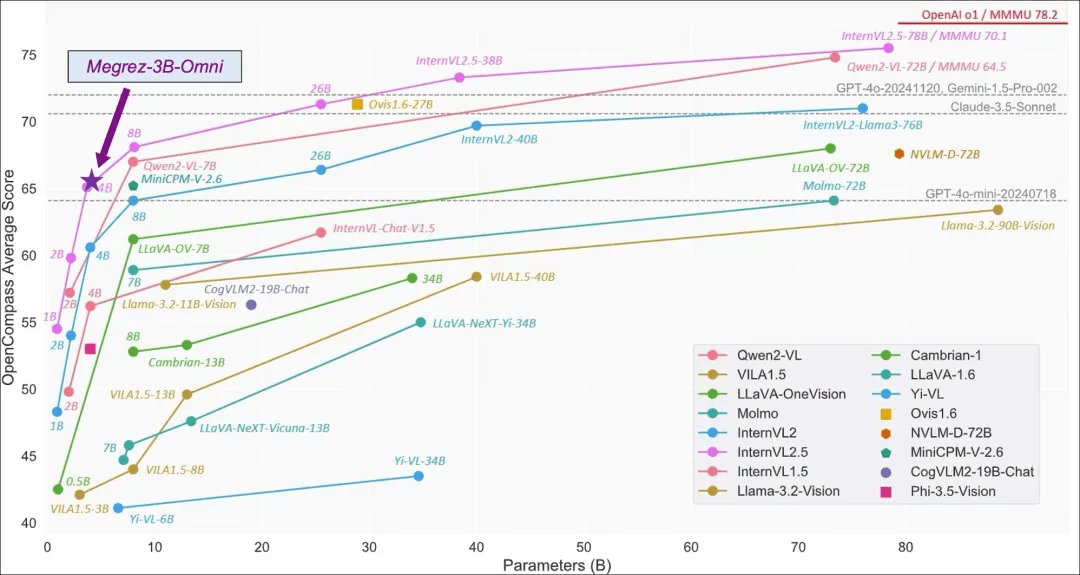
Megrez-3B-Omni在OpenCompass测试集上表现
模型链接:
https://modelscope.cn/models/InfiniAI/Megrez-3B-Omni
体验链接:
https://modelscope.cn/studios/AI-ModelScope/Megrez-3B-Omni
02.模型体验
数学运算

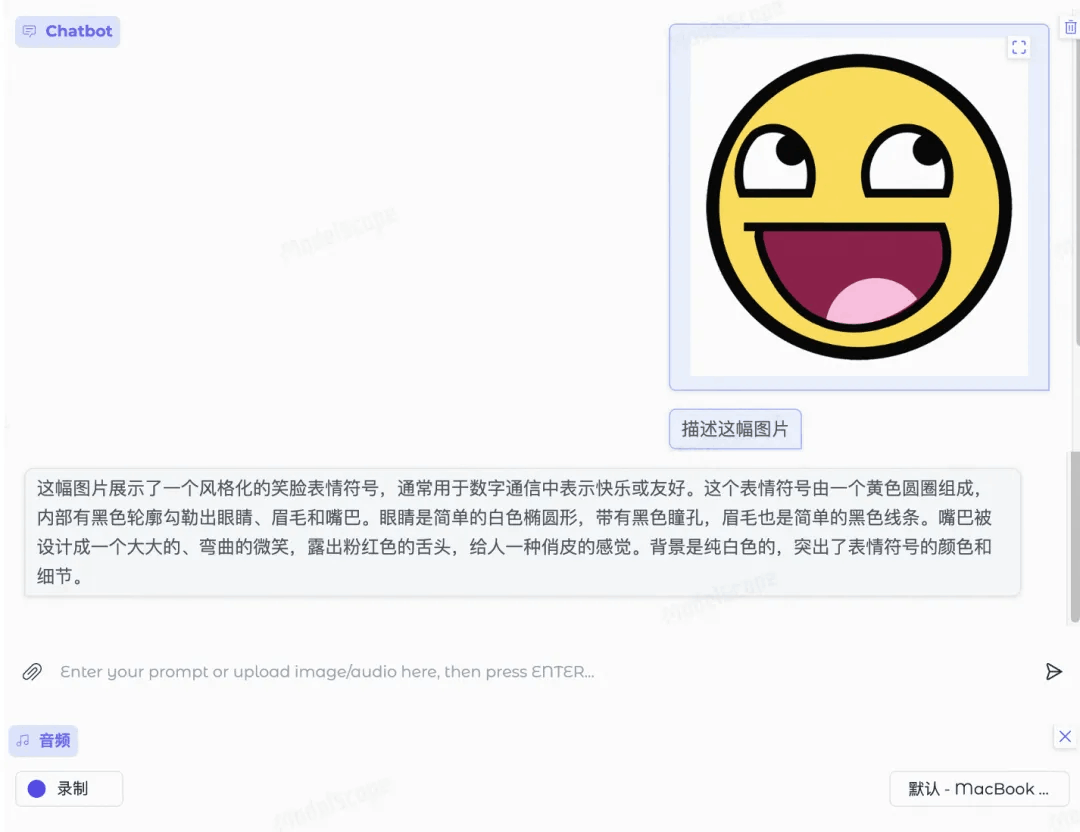
图片描述
数数

音频理解

03.快速上手
使用魔搭免费算力(单卡A10),完成模型推理实践。
模型下载
魔搭cli下载
modelscope download --model InfiniAI/Megrez-3B-Omni魔搭python SDK下载
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('InfiniAI/Megrez-3B-Omni')模型推理
如下是一个使用transformers进行推理的例子,通过在content字段中分别传入text、image和audio,可以图文/图音等多种模态和模型进行交互。
import torch
from modelscope import AutoModelForCausalLM
model = (
AutoModelForCausalLM.from_pretrained(
"InfiniAI/Megrez-3B-Omni",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
.eval()
.cuda()
)
# Chat with text and image
messages = [
{
"role": "user",
"content": {
"text": "Please describe the content of the image.",
"image": "./data/sample_image.jpg",
},
},
]
# Chat with audio and image
messages = [
{
"role": "user",
"content": {
"image": "./data/sample_image.jpg",
"audio": "./data/sample_audio.m4a",
},
},
]
MAX_NEW_TOKENS = 100
response = model.chat(
messages,
sampling=False,
max_new_tokens=MAX_NEW_TOKENS,
temperature=0,
)
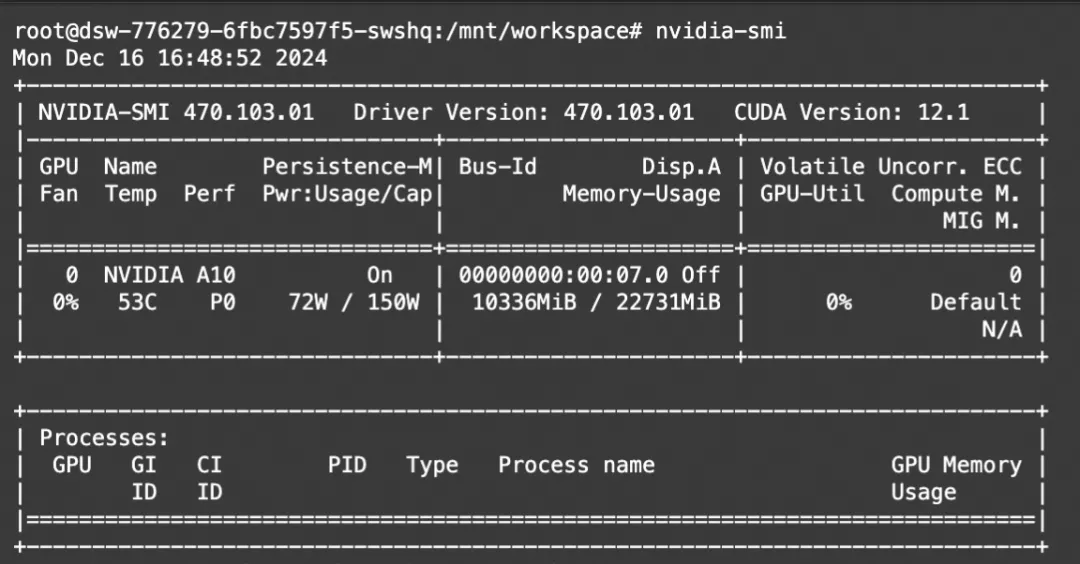
print(response)显存占用:
注意事项
-
请将图片尽量在首轮输入以保证推理效果,语音和文本无此限制,可以自由切换
-
语音识别(ASR)场景下,只需要将content['text']修改为“将语音转化为文字。”
-
OCR场景下开启采样可能会引入语言模型幻觉导致的文字变化,可考虑关闭采样进行推理(sampling=False),但关闭采样可能引入模型复读
使用vllm模型推理
环境安装
pip install vllm==0.6.3.post1 flash_attn==2.5.8 xformers==0.0.27.post2注册MegrezO
from vllm import ModelRegistry
from megrezo import MegrezOModel
ModelRegistry.register_model("MegrezO", MegrezOModel)推理代码
from PIL import Image
from vllm import LLM
from vllm import SamplingParams
# Load the model.
model_path = "{{PATH_TO_HF_PRETRAINED_MODEL}}" # Change this to the path of the model.
llm = LLM(
model_path,
trust_remote_code=True,
gpu_memory_utilization=0.5,
)
sampling_params = SamplingParams(
temperature=0,
max_tokens=1000,
repetition_penalty=1.2,
stop=["<|turn_end|>", "<|eos|>"],
)
img = Image.open("../data/sample_image.jpg")
conversation = [
{
"role": "user",
"content": {
"text": "图片的内容是什么?",
"image": img,
},
},
]
# Convert the conversation to vLLM acceptable format.
prompt = llm.get_tokenizer().apply_chat_template(
conversation,
tokenize=False,
add_generation_prompt=True,
)
vllm_inputs = [
{
"prompt": prompt,
"multi_modal_data": {
"image": img,
},
}
]
# Generate the outputs.
outputs = llm.generate(
vllm_inputs,
sampling_params,
)
# Print the outputs.
for output in outputs:
print(output.outputs[0].text)
或者直接使用example_infer_vllm.py 运行:
git clone https://github.com/infinigence/Infini-Megrez-Omni.git
cd Infini-Megrez-Omni/vllm_demo
# 修改模型路径
python example_infer_vllm.py推理速度:

模型微调
我们使用ms-swift对Megrez-3B-Omni进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型微调部署框架。
ms-swift开源地址:
https://github.com/modelscope/ms-swift
在这里,我们将展示可直接运行的demo,并给出自定义数据集的格式。
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .[llm]微调脚本:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model InfiniAI/Megrez-3B-Omni \
--train_type lora \
--dataset modelscope/coco_2014_caption:validation#20000 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model Shanghai_AI_Laboratory/internlm-xcomposer2d5-ol-7b \
--train_type lora \
--dataset modelscope/coco_2014_caption:validation#20000 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--freeze_vit true \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4自定义数据集格式如下(system字段可选),只需要指定`--dataset <dataset_path>`即可:
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<image>图片中是什么"}, {"role": "assistant", "content": "一个可爱的小猫"}], "images": ["/xxx/x.jpg"]}
{"messages": [{"role": "system", "content": "你是个有用无害的助手"}, {"role": "user", "content": "<audio>音频中说了什么"}, {"role": "assistant", "content": "今天的天气真好呀"}], "audios": ["/xxx/x.wav"]}
{"messages": [{"role": "user", "content": "<image><audio>"}, {"role": "assistant", "content": "今天天气真好呀,可爱的小猫在草地上奔跑"}], "images": ["/xxx/x.jpg"], "audios": ["/xxx/x.wav"]}训练显存资源:

训练完成后,使用以下命令对训练后的权重进行推理
这里`--adapters`需要替换成训练生成的last checkpoint文件夹. 由于adapters文件夹中包含了训练的参数文件,因此不需要额外指定`--model`:
# 使用训练时的验证集进行推理
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--load_data_args true点击阅读原文链接即可跳转体验:https://modelscope.cn/models/InfiniAI/Megrez-3B-Omni

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献645条内容
已为社区贡献645条内容

所有评论(0)