
魔搭社区每周速递(12.08-12.14)
魔搭ModelScope本期社区进展:新增1599个模型,46个数据集,67个创新应用,8篇内容

🙋魔搭ModelScope本期社区进展:
📟1599个模型:Llama 3.3、deepseek-vl2、DeepSeek-V2.5-1210、Ivy-VL、Tora_T2V_diffusers、InternViT-6B-448px-V2_5等;
📁46个数据集:P-MMEval、一招金融数据集、BiomedParseData、subsplease_animes等;
🎨67个创新应用:Llama-3.3-70B-Instruct、ShowUI、通用交互式图像编辑和生成等;
📄 8篇内容:
-
AI Safeguard联合 CMU,斯坦福提出端侧多模态小模型
-
CAMEL AI 上海黑客松重磅来袭!快来尝试搭建你的第一个多智能体系统吧!
-
TeleAI 星辰语义大模型全尺寸开源,function call能力突出
-
基于可图Kolors的皮影戏风格LoRA训练&创作
-
千问开源P-MMEval数据集,面向大模型的多语言平行评测集
-
Llama 3.3开源!70B媲美405B性能,支持128K上下文
-
AI赋能大学计划·大模型技术与应用实战学生训练营——电子科技大学站圆满结营
-
InternVL 2.5,首个MMMU超过70%的开源模型,性能媲美GPT-4o
01.精选模型
Llama 3.3
Llama 3.3 是一个预训练并经过指令调优的生成模型,参数量为70B(文本输入/文本输出),指令调优的纯文本模型针对多语言对话用例进行了优化,调优版本使用监督微调(SFT)和基于人类反馈的强化学习(RLHF)来与人类对有用性和安全性的偏好保持一致。
-
训练数据:新的公开在线数据混合集
-
参数量:70B
-
输入模态:多语言文本
-
输出模态:多语言文本和代码
-
上下文长度:128K
-
GQA:是
-
训练tokens:15T+(仅指预训练数据)
-
知识截止日期:2023年12月
-
支持的语言: 英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语
模型链接:
https://www.modelscope.cn/models/LLM-Research/Llama-3.3-70B-Instruct
代码示例:
transformers推理
import transformers
import torch
from modelscope import snapshot_download
model_id = snapshot_download("LLM-Research/Llama-3.3-70B-Instruct")
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])更多详情请见:
Llama 3.3开源!70B媲美405B性能,支持128K上下文
DeepSeek-VL2
DeepSeek-VL2 是DeepSeek最新推出的MoE 视觉-语言模型,它在性能上显著超越了其前身DeepSeek-VL。DeepSeek-VL2在各种任务中展现出卓越的能力,包括但不限于视觉问题回答、OCR、文档/表格/图表理解以及视觉定位。DeepSeek-VL2 系列由三个变体组成:DeepSeek-VL2-Tiny、DeepSeek-VL2-Small和DeepSeek-VL2,分别激活了10亿、28亿和45亿参数。与现有的开源密集型和基于MoE的模型相比,DeepSeek-VL2在激活参数相似或更少的情况下,实现了具有竞争力或最先进的性能。
模型链接:
https://modelscope.cn/models/deepseek-ai/deepseek-vl2
代码推理:
# pip install git+https://github.com/deepseek-ai/DeepSeek-VL2.git
# pip install "transformers<4.42"
import torch
from modelscope import AutoModelForCausalLM, snapshot_download
from deepseek_vl.models import DeepseekVLV2Processor, DeepseekVLV2ForCausalLM
from deepseek_vl.utils.io import load_pil_images
# specify the path to the model
model_path = snapshot_download("deepseek-ai/deepseek-vl2-small")
vl_chat_processor: DeepseekVLV2Processor = DeepseekVLV2Processor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: DeepseekVLV2ForCausalLM = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True)
vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
## single image conversation example
conversation = [
{
"role": "<|User|>",
"content": "<image>\n<|ref|>The giraffe at the back.<|/ref|>.",
"images": ["./images/visual_grounding.jpeg"],
},
{"role": "<|Assistant|>", "content": ""},
]
# load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation,
images=pil_images,
force_batchify=True,
system_prompt=""
).to(vl_gpt.device)
# run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
# run the model to get the response
outputs = vl_gpt.language.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)
Ivy-VL
Ivy-VL 是由 AI Safeguard 联合CMU与斯坦福开发的⼀款轻量级多模态模型,秉承⾼效、轻量化和强性能的设计理念,聚焦于多模态⼤模型在端侧部署的需求。
Ivy-VL 的参数量仅为 3B,极⼤地降低了计算资源需求,在端侧设备上可实现实时推理。Ivy-VL在多个多模态榜单中夺得 SOTA成绩,在专业多模态模型评测榜单OpenCompass上面,做到了 4B 以下开源模型第⼀的性能。
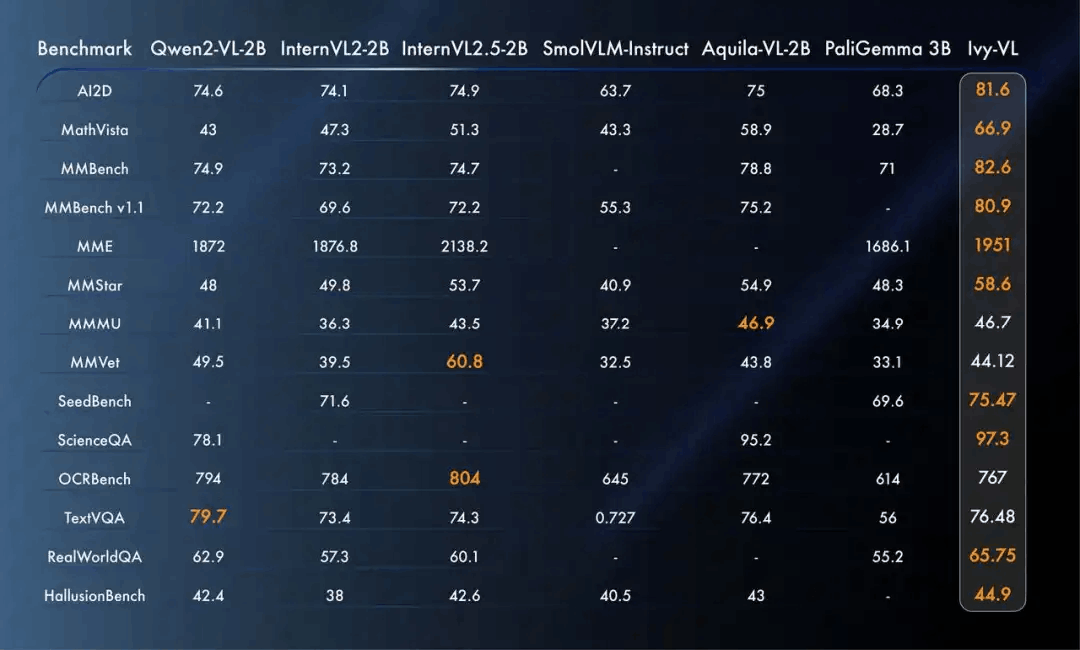
模型链接:
https://modelscope.cn/models/AI-Safeguard/Ivy-VL-llava
Tora_T2V_diffusers
Tora是由阿里云技术团队推出的首个面向轨迹的扩散变换器框架,通过集成文本、视觉和轨迹条件,展现了在生成高质量、可控运动视频内容方面的突破性进展,其设计允许精确控制视频内容的动态,实验结果证明了其在高运动保真度和物理世界运动模拟方面的卓越性能。
模型链接:https://modelscope.cn/models/Alibaba_Research_Intelligence_Computing/Tora_T2V_diffusers
02.数据集推荐
P-MMEval
多语言基准 P-MMEval,涵盖有效的基础数据集和能力专业化数据集。我们扩展了现有的基准,确保所有数据集的语言覆盖范围一致,并在多种语言之间提供并行样本,支持来自 8 个语系(即 en、zh、ar、es、ja、ko、th、fr、pt、vi)的多达 10 种语言。因此,P-MMEval 有助于对多语言能力进行整体评估并对跨语言可迁移性进行比较分析。
数据集链接:
https://modelscope.cn/datasets/Qwen/P-MMEval
一招金融数据集
一招数据集由哈尔滨工业大学&招商银行联合推出,是一个2TB高质量多模态的大模型训练数据集(包含936GB中文文本数据集,100GB英文文本数据集和1TB的高质量多模态数据集)。该数据集不仅包含广泛的金融事件、市场动态,还涵盖各种金融产品和交易模式,以确保模型在复杂的金融环境中展现出卓越的泛化能力和预测准确性。
数据集链接:
https://modelscope.cn/datasets/CMB_AILab/YiZhao-FinDataSet
BiomedParseData
BiomedParseData 是生物医学领域数据集,旨在支持和促进生物医学信息的解析与研究。
数据集链接:
https://modelscope.cn/datasets/AI-ModelScope/BiomedParseData
subsplease_animes
subsplease_animes 是一个专注于动漫字幕的数据集,用于支持动漫领域的字幕生成和语言处理研究。
数据集链接:
https://modelscope.cn/datasets/deepghs/subsplease_animes
03.精选应用
Llama-3.3-70B-Instruct
Llama 3.3 是一个70B参数的多语言自回归语言模型,通过SFT和RLHF调优,支持多语言文本和代码的生成,具备128K的上下文长度,覆盖多种语言,训练数据超过15T tokens。
体验直达:
https://modelscope.cn/studios/LLM-Research/Llama-3.3-70B-Instruct
ShowUI
上传一张图+一句话即可检测到图像上的坐标。
体验直达:
https://modelscope.cn/studios/AI-ModelScope/ShowUI
通用交互式图像编辑和生成
你可以上传图像进行编辑,或者通过输入'@'来生成图像并从画廊中选择,但请注意,当前模型仅支持英文指令。
体验直达:
https://modelscope.cn/studios/iic/ACE-Chat
04.社区精选文章

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献660条内容
已为社区贡献660条内容

所有评论(0)