

AI Safeguard联合 CMU,斯坦福提出端侧多模态小模型
随着人工智能的快速发展,多模态大模型(MLLMs)在计算机视觉、自然语言处理和多模态任务中扮演着重要角色。

添加图片注释,不超过 140 字(可选)
01.介绍
随着人工智能的快速发展,多模态大模型(MLLMs)在计算机视觉、自然语言处理和多模态任务中扮演着重要角色。然而,受限于硬件资源和能效需求,将这些模型部署到移动设备和边缘设备上⼀直是⼀个巨大挑战。在这⼀背景下,Ivy-VL凭借卓越的性能,成为面向移动端多模态模型的新标杆。
Ivy-VL 是由 AI Safeguard 联合CMU与斯坦福开发的⼀款轻量级多模态模型。秉承⾼效、轻量化和强性能的设计理念,Ivy-VL 解决了多模态⼤模型在端侧部署中的诸多难题。模型的问世不仅推动了移动端 AI 应⽤的发展,也为更多设备在低功耗环境下运行先进 AI 技术铺平了道路。
模型下载链接:
-
ModelScope: https://modelscope.cn/models/AI-Safeguard/Ivy-VL-llava
-
Hugging Face: https://huggingface.co/AI-Safeguard/Ivy-VL-llava
模型体验链接:
https://modelscope.cn/studios/AI-Safeguard/Ivy-VL
02.模型亮点
1、极致轻量化
Ivy-VL 的参数量仅为 3B,极⼤地降低了计算资源需求,与7B 以几十B的多模态模型相比,具有更小的硬件占⽤。模型可⾼效运行于 AI 眼镜、智能手机等资源受限的设备上。
2、卓越性能
Ivy-VL在多个多模态榜单中夺得 SOTA(state-of-the-art)成绩。通过精⼼优化的数据集训练,Ivy- VL 展现了远超同类模型的性能,证明了小模型同样可以实现⼤突破。在专业多模态模型评测榜单OpenCompass上面,做到了 4B 以下开源模型第⼀的性能。超越了顶尖的端侧 SOTA 模型,包括Qwen2-VL-2B,InternVL2-2B,InternVL2.5-2B,SmolVLM-Instruct, Aquila-VL-2B 以及PaliGemma 3B 等模型。
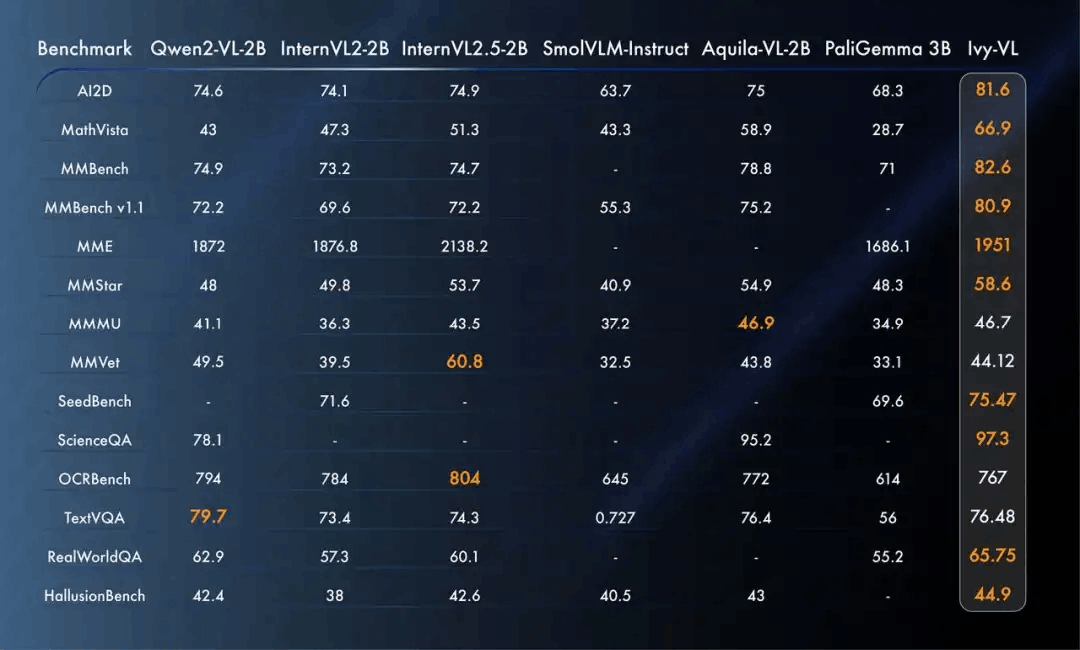
添加图片注释,不超过 140 字(可选)
3、低延迟和高响应速度
3B 的LLM 模型大小,显著提升了Ivy-VL 的响应速度,确保其在端侧设备上实现实时推理。在⽣成速度、能效⽐和准确率之间,达到了完美平衡。
4、强大的跨模态理解能力
Ivy-VL基于 LLaVA-One-Vision,结合先进的视觉编码器(google/siglip-so400m-patch14- 384)与强⼤的语⾔模型(Qwen2.5-3B-Instruct),Ivy-VL 在视觉问答、图像描述、复杂推理等任务中表现优异,完美满⾜端侧应⽤的多模态需求。
5、开放生态
Ivy-VL 将模型开源,并且允许商用,⽅便开发者快速上手。无论是 AI 创新团队还是个⼈开发者,都可以利⽤ Ivy-VL 构建⾃⼰的多模态应⽤。
03.核心应用场景
-
智能穿戴设备: 支持 AI 眼镜实现实时视觉问答,辅助增强现实(AR)体验。
-
手机端智能助手: 提供更智能的多模态交互能⼒,让手机⽤户体验更⾃然的 AI 服务。
-
物联⽹设备: 助⼒智能家居和IoT 场景实现更⾼效的多模态数据处理。
-
移动端教育与娱乐: 在教育软件中增强图像理解与交互能⼒,推动移动学习与沉浸式娱乐体验
04.测试用例
Ivy-VL 在科学⾃然问题中获得了很好的性能,可以发现在第⼀张图中,Ivy-VL能准确 de 识别是哪个⽣物体的生命周期,第⼆张图中判断图中哪个阶段代表冬至。
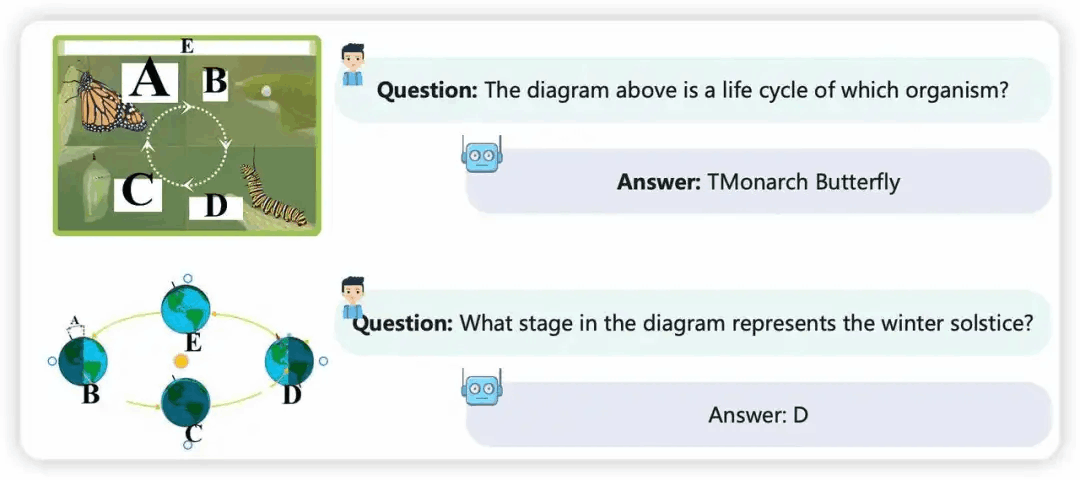
添加图片注释,不超过 140 字(可选)
在推理和图表问题中,可以看出,在第⼀张图中,Ivy-VL 可以准确的识别出图中量杯的总容积是多少。第⼆张图中,需要进⾏的推理问题,模型同样给出正确的答案。

添加图片注释,不超过 140 字(可选)
05.Ivy-VL 的未来展望
Ivy-VL 的诞⽣标志着轻量级多模态模型在端侧设备上的⼀次重要突破。未来,AI Safeguard将持续优化 Ivy-VL,进⼀步提升其在视频模态任务中的表现,并探索更多⾏业应⽤场景。
Ivy-VL 为多模态大模型的边缘部署和普及开创了全新可能。无论是推动移动设备 AI 应⽤, 还是服务于广泛的 IoT 设备,Ivy-VL 都将是行业的理想之选。
点击链接跳转原文:Ivy-VL-llava

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献449条内容
已为社区贡献449条内容

所有评论(0)