
腾讯开源混元视频生成模型,这效果!太稳了吧
腾讯开源了超过130亿参数的混元视频生成模型HunyuanVideo,性能领先且具有高视觉质量、运动多样性和文本-视频对齐的特点,旨在推动开源视频生成模型的发展。
01.引言
腾讯今天开源了 HunyuanVideo,这是一种新颖的开源视频基础模型,其视频生成性能可与领先的闭源模型相媲美,甚至优于它们。HunyuanVideo 具有一个综合框架,该框架集成了多项关键贡献,包括数据管理、图像-视频联合模型训练以及旨在促进大规模模型训练和推理的高效基础设施。此外,通过有效的模型架构和数据集扩展策略,本次开源的时一个具有超过 130 亿个参数的视频生成模型,是所有开源模型中最大的模型。
研究团队进行了大量的实验,并实施了一系列有针对性的设计,以确保高视觉质量、运动多样性、文本-视频对齐和生成稳定性。根据专业人工评估结果,HunyuanVideo 的表现优于之前的先进模型,包括 Runway Gen-3、Luma 1.6 和 3 个表现最好的中文视频生成模型。通过发布基础模型及其应用程序的代码和权重,研究团队旨在弥合闭源和开源视频基础模型之间的差距。这一举措将使社区中的每个人都能尝试自己的想法,从而培育一个更具活力和生机的视频生成生态系统。
代码仓库:
https://github.com/Tencent/HunyuanVideo
模型合集:
https://modelscope.cn/collections/HunyuanVideo-ad614176424b47
模型架构
HunyuanVideo 在时空压缩的潜在空间上进行训练,该空间通过因果 3D VAE 进行压缩。文本提示使用大型语言模型进行编码,并用作条件。高斯噪声和条件作为输入,生成模型生成输出潜在,通过 3D VAE 解码器将其解码为图像或视频。
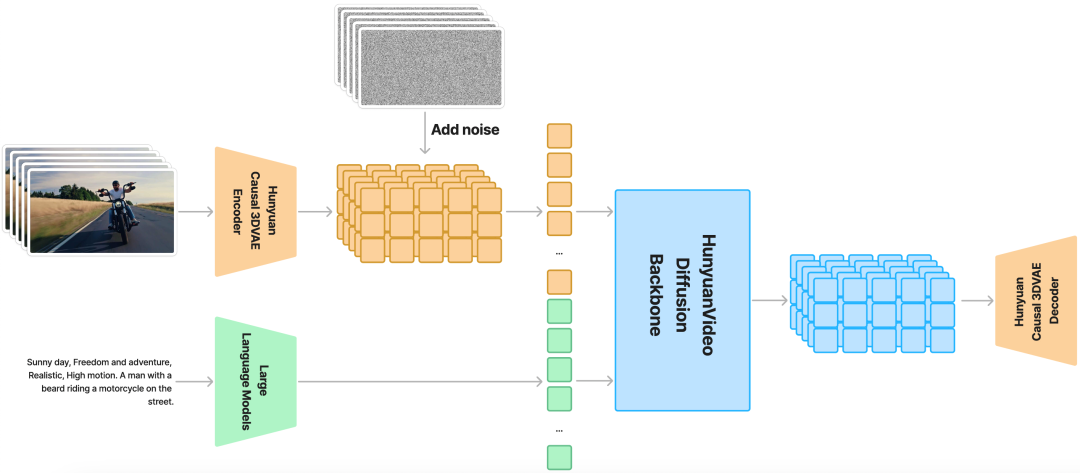
模型特点
统一的图像和视频生成架构
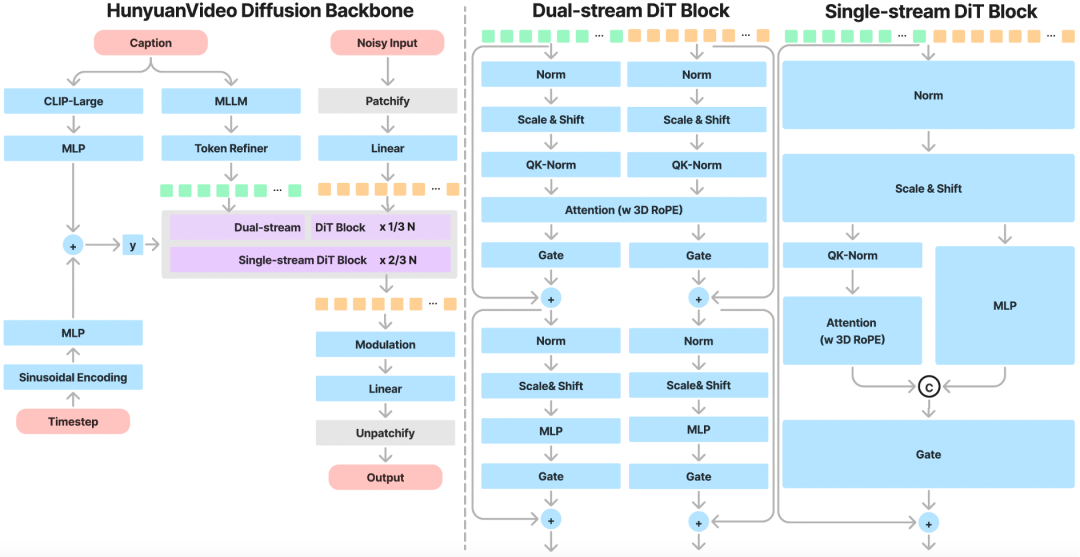
HunyuanVideo引入Transformer设计,采用Full Attention机制,实现图像和视频的统一生成。具体来说,研究团队采用“Dual-stream to Single-stream”混合模型设计进行视频生成。在Dual-stream阶段,视频和文本token通过多个Transformer块独立处理,使每个模态都能学习到自己合适的调制机制,而不会相互干扰。在Single-stream阶段,将视频和文本token连接起来,并将它们输入到后续的Transformer块中,实现有效的多模态信息融合。这种设计可以捕捉视觉和语义信息之间的复杂交互,从而提高整体模型性能。
MLLM 文本编码器
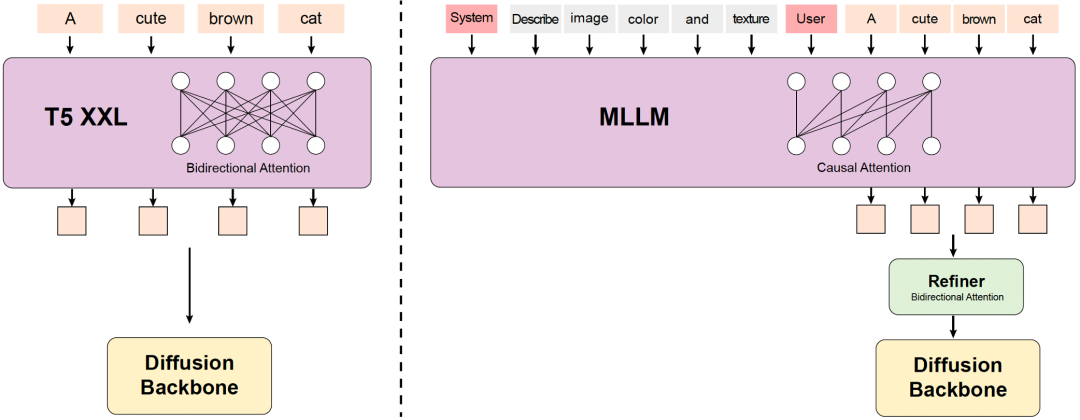
以前的一些文本到视频模型通常使用预训练的 CLIP 和 T5-XXL 作为文本编码器,其中 CLIP 使用 Transformer 编码器,T5 使用编码器-解码器结构。相比之下,HunyuanVideo使用具有解码器结构的预训练多模态大型语言模型 (MLLM) 作为文本编码器,它具有以下优点:(i)与 T5 相比,经过视觉指令微调后的 MLLM 在特征空间中具有更好的图像-文本对齐,这减轻了扩散模型中指令跟踪的难度;(ii)与 CLIP 相比,MLLM 在图像细节描述和复杂推理方面表现出了卓越的能力;(iii)MLLM 可以通过遵循用户提示前面的系统指令来充当零样本学习者,帮助文本特征更多地关注关键信息。此外,MLLM 基于因果注意,而 T5-XXL 利用双向注意,为扩散模型提供更好的文本指导。因此,研究团队引入了一个额外的双向 token 细化器来增强文本特征。
3D VAE
HunyuanVideo 使用 CausalConv3D 训练 3D VAE,将像素空间的视频和图像压缩到紧凑的潜在空间中。研究团队将视频长度、空间和通道的压缩比分别设置为 4、8 和 16。这可以显著减少后续扩散变压器模型的 token 数量,使研究团队能够以原始分辨率和帧速率训练视频。

提示重写
为了解决用户提供的提示的语言风格和长度的多变性,针对Hunyuan-Large 模型进行了微调作为研究团队的提示重写模型,以使原始用户提示适应模型首选的提示。
提供了两种重写模式:普通模式和主模式,可以使用不同的提示来调用。
普通模式旨在增强视频生成模型对用户意图的理解,从而更准确地解释所提供的指令。
主模式增强了对构图、灯光和相机运动等方面的描述,这倾向于生成具有更高视觉质量的视频。然而,这种强调有时可能会导致一些语义细节的丢失。
社区推荐的扩写提示词:
您是制作视频的机器人团队的一员。您与一个助手机器人一起工作,它会将您说的任何话画在方括号中。
例如,输出“树林里一个美丽的早晨,阳光透过树梢”将触发您的伙伴机器人输出一个森林早晨的视频,如所述。想要制作详细、精彩的视频的人会提示您。实现这一点的方法是接受他们的简短提示,并使其极其详细和描述性。
有几条规则需要遵循:
您只会根据用户请求输出一个视频描述。
当请求修改时,您不应该简单地使描述更长。您应该重构整个描述以整合建议。
输出语言和输入语言保持一致。
输入:{prompt}比较
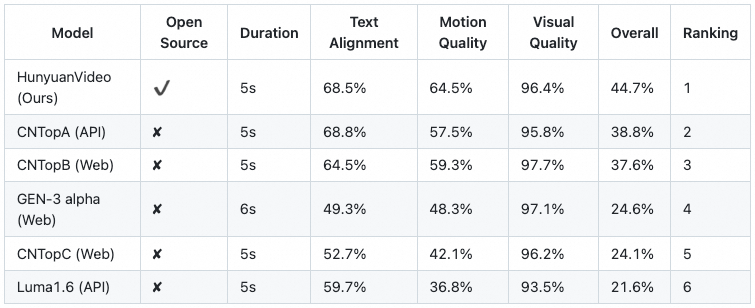
为了评估 HunyuanVideo 的性能,研究团队从闭源视频生成模型中选取了五个强大的基线。总共使用了 1,533 个文本提示,在一次运行中用 HunyuanVideo 生成了相同数量的视频样本。为了公平比较,只进行了一次推理,避免了对结果的挑选。与基线方法进行比较时,保留了所有选定模型的默认设置,以确保一致的视频分辨率。视频根据三个标准进行评估:文本对齐、运动质量和视觉质量。超过 60 名专业评估人员进行了评估。值得注意的是,HunyuanVideo 表现出最佳的整体性能,尤其是在运动质量方面表现出色。
02.模型效果
提示词:视频展示了一位青少年在城市滑板公园中炫技,他脚踏滑板,身手矫健,连续完成多个高难度动作。镜头紧随其后,精准捕捉每一次翻转和旋转,展现出少年的极限运动风采。背景中,城市的建筑群和人群成为动感画面的一部分,增添了场景的活力与张力。

提示词:Several gigantic, furry mammoths walked across the grassy snowfield, their long fur gently swaying in the wind. In the distance, snow-covered trees and dramatic snow-capped mountains could be seen. Thin clouds floated in the afternoon breeze, and warm sunlight streamed down from high above. A low-angle shot captured these enormous, furry mammals, with the depth of field creating a stunning scene.

提示词:The sleek, silver exterior of a high-speed train mirrors the vibrant tapestry of the suburbs of Tokyo as it glides effortlessly through the urban landscape. The windows reflect a dynamic scene: rows of compact, meticulously maintained homes with tile roofs, punctuated by the occasional burst of cherry blossoms. The view transitions to bustling stations, where passengers in business attire and students in uniforms are fleeting silhouettes against the bright cityscape. As the train speeds up, the reflection becomes a blurred mosaic of life in motion, capturing the essence of Tokyo's suburbs in a shimmering, ever-changing mirror.

提示词:A kaleidoscope of colorful paper airplanes, each intricately folded and gliding effortlessly, swarms through the dense, verdant jungle. They weave and dart among the towering ferns, colossal tree trunks, and thick, hanging vines with the grace of a flock of migrating birds. Sunlight filters through the canopy, casting dappled shadows that dance across the paper crafts, as they continue their whimsical journey through the lush, untamed wilderness.
03.最佳实践
克隆存储库:
git clone https://github.com/tencent/HunyuanVideo
cd HunyuanVideo安装依赖:
python -m pip install -r requirements.txt
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.5.9.post1
下载模型:
模型文件路径:
HunyuanVideo
├──ckpts
│ ├──README.md
│ ├──hunyuan-video-t2v-720p
│ │ ├──transformers
├ │ ├──vae
│ ├──text_encoder
│ ├──text_encoder_2
├──...
下载HunyuanVideo 模型
modelscope download --download AI-ModelScope/HunyuanVideo --local_dir ./ckpts下载Text Encoder
多模态模型下载(text_encoder)
cd ckpts
modelscope download AI-ModelScope/llava-llama-3-8b-v1_1-transformers --local_dir ./llava-llama-3-8b-v1_1-transformers
cd ../
python hyvideo/utils/preprocess_text_encoder_tokenizer_utils.py --input_dir ckpts/llava-llama-3-8b-v1_1-transformers --output_dir ckpts/text_encoder
CLIP模型下载(text_encoder_2 folder)
cd ckpts
modelscope download AI-ModelScope/clip-vit-large-patch14 --local_dir ./text_encoder_2推理代码
cd HunyuanVideo
python3 sample_video.py \
--video-size 720 1280 \
--video-length 129 \
--infer-steps 30 \
--prompt "a cat is running, realistic." \
--flow-reverse \
--seed 0 \
--use-cpu-offload \
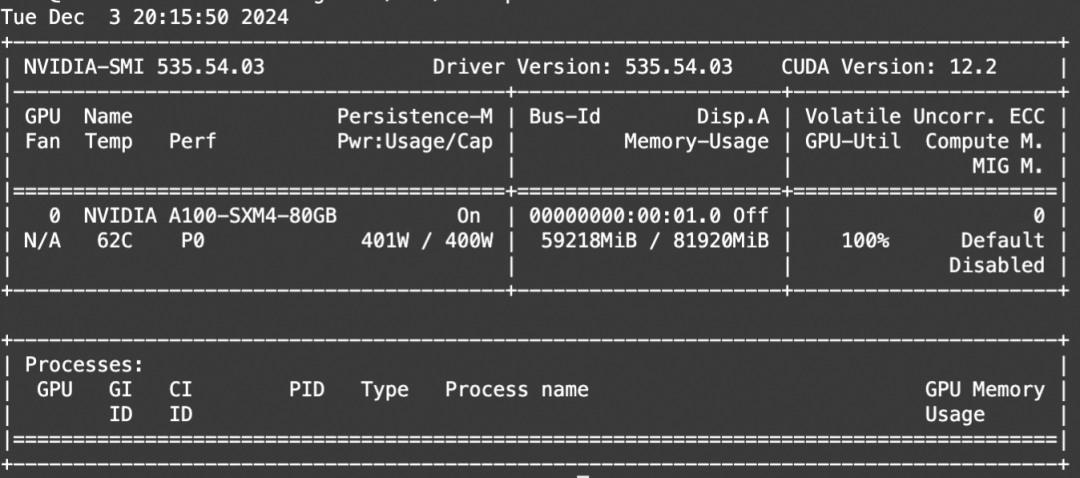
--save-path ./results耗时:单卡A100,30步,大约30分钟

显存占用:约60G
相关链接:
https://github.com/Tencent/HunyuanVideo?tab=readme-ov-file

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐


 0
0 0
0- 0



 已为社区贡献657条内容
已为社区贡献657条内容

所有评论(0)