
机器学习: 阿里巴巴发布基于:蒙特卡洛的应用Marco-o1
阿里巴巴发布了Marco-o1!!!Marco-o1通过集成。
本人项目地址大全:Victor94-king/NLP__ManVictor: CSDN of ManVictor
git地址:https://github.com/opendatalab/MinerU
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
阿里巴巴发布了Marco-o1!!!
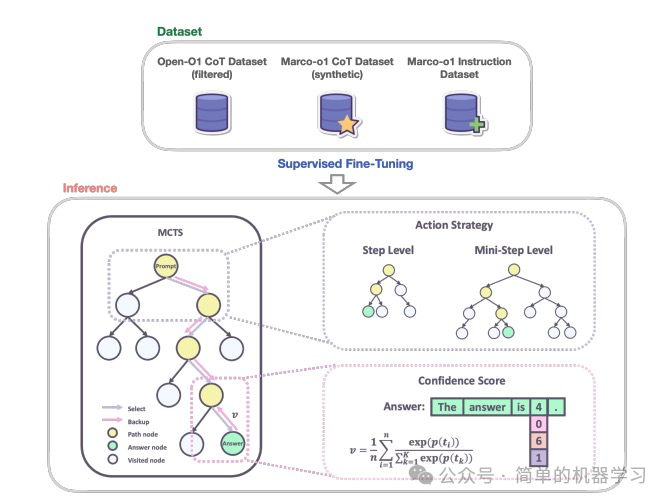
Marco-o1通过集成 思维链(CoT)微调 、 蒙特卡洛树搜索(MCTS )和创新的 推理行动策略 ,增强了推理能力。Marco-o1的MCTS集成允许扩展解空间,并对不同行动粒度(步骤和迷你步骤)的实验显示了更细搜索分辨率在提高准确性方面的潜力。此方法在推理任务中展示了显著改进,并在翻译复杂俚语表达方面取得了成功。
第一步:开发Marco-o1-CoT模型
数据集
Marco-o1-CoT使用了多种数据集进行监督微调(Supervised Fine-Tuning, SFT),包括:
- Open-o1 CoT数据集(过滤后) :从Open-o1项目中获取了CoT数据集,并通过启发式和质量过滤过程对其进行了优化,以确保数据的高质量和结构化推理步骤的有效性。
- Marco-o1 CoT数据集(合成) :使用蒙特卡洛树搜索(MCTS)生成了合成CoT数据集,帮助制定复杂的推理路径,进一步增强了模型的推理能力。
- Marco指令数据集 :在执行复杂任务时,强大的指令跟随能力至关重要,因此整合了一组指令跟随数据,确保模型在广泛任务中保持其通用有效性。
全参数微调
使用上述数据集对基础模型(如Owen2-7B-Instruct)进行了全参数微调。具体步骤如下:
- 数据预处理 :将所有数据集合并,并进行预处理,确保数据格式一致。
- 模型初始化 :使用预训练的基础模型(如Owen2-7B-Instruct)进行初始化。
- 微调过程 :在合并后的数据集上进行全参数微调,使模型学习如何生成结构化推理步骤。
第二步:集成MCTS和推理行动策略
通过MCTS扩展解空间
蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)是一种用于决策过程的搜索算法,特别适用于那些状态空间巨大且难以通过传统搜索方法(如深度优先搜索或广度优先搜索)进行有效探索的问题。在Marco-o1模型中,作者将MCTS集成到大型语言模型(LLM)中,以增强其推理能力并扩展解空间。
MCTS的基本概念
MCTS的核心思想是 通过模拟(simulation)来评估和选择最有前途的行动路径 。它包括四个主要步骤:选择(Selection)、扩展(Expansion)、模拟(Simulation)和反向传播(Backpropagation)。
- 选择(Selection) :从根节点开始,根据某种策略选择一个子节点,直到到达一个未完全扩展的节点。
- 扩展(Expansion) :在未完全扩展的节点上添加一个或多个子节点。
- 模拟(Simulation) :从新扩展的节点开始,进行一次或多次模拟,直到达到终止状态。
- 反向传播(Backpropagation) :将模拟结果(如奖励)反向传播回根节点,更新路径上所有节点的统计信息。
MCTS在Marco-o1中的应用
- 节点作为推理状态: 在MCTS框架中,每个节点代表问题解决过程中的一个推理状态。例如,在解决一个数学问题时,每个节点可能代表一个中间步骤或一个子问题的解决方案。
- 行动作为LLM输出: 从一个节点出发的可能行动是由LLM生成的输出。这些输出代表了推理链中的潜在步骤或迷你步骤。例如,在解决一个复杂的逻辑问题时,LLM可能会生成多个可能的推理步骤,每个步骤对应一个行动。
- 回滚和奖励计算: 在回滚阶段,LLM继续推理过程直到达到终端状态。终端状态可以是问题的最终答案,也可以是一个中间状态,其中LLM无法继续推理。在每个终端状态,计算一个奖励分数,用于评估该推理路径的质量。
奖励分数的计算方法如下:
置信度分数 :对于回滚期间生成的每个token ,我们通过将softmax函数应用于其log概率和前5个替代token的log概率来计算其置信度分数。公式如下:
其中, 是第 个token的置信度分数, 是LLM生成的第 个token的log概率, 是前5个预测token的log概率。
平均置信度分数 :在获得回滚序列中所有token的置信度分数后,我们计算这些分数的平均值,作为该回滚路径的总体奖励分数。公式如下:
其中, 是总体奖励分数, 是回滚序列中的token总数。
指导MCTS
奖励分数 用于评估和选择MCTS中的有前途路径,有效指导搜索朝着更有信心和可靠的推理链。通过这种方式,MCTS能够探索大量可能的推理路径,并选择那些最有可能导致正确答案的路径。
通过将LLM与MCTS集成,显著扩展了模型的解空间。具体来说,MCTS允许模型在多个推理路径之间进行探索,并根据置信度分数选择最优路径。这种方法不仅提高了模型在复杂问题上的表现,还使其能够处理那些缺乏明确标准和难以量化奖励的开放式问题。
推理行动策略
推理行动策略是Marco-o1模型中的一个关键组成部分,旨在通过优化推理过程中的行动选择来提高模型的推理能力和准确性。推理行动策略涉及在蒙特卡洛树搜索(MCTS)框架内探索不同的行动粒度,并引入反思机制,以增强模型在复杂问题上的表现。以下是详细介绍:
行动选择
在MCTS中,行动选择是一个关键步骤,决定了模型如何探索解空间。使用行动作为MCTS搜索的粒度相对较粗,常常导致模型忽略解决复杂问题所需的细微推理路径。为了解决这个问题,文章中探索了MCTS搜索中的不同粒度级别。
步骤作为行动:
如果每个MCTS节点代表一个完整的思维或行动标签。这种方法可以高效探索,但可能会错过复杂问题解决所需的更细粒度的推理路径。
迷你步骤作为行动:
为了进一步扩展模型的搜索空间并增强其问题解决能力,文章尝试将这些步骤细分为更小的单位,称为“迷你步骤”。具体来说,将步骤细分为64或32个token的迷你步骤。这种更细的粒度允许模型更详细地探索推理路径。
- 64个token的迷你步骤 :将每个推理步骤细分为64个token的迷你步骤,允许模型在更细的粒度上进行搜索。
- 32个token的迷你步骤 :将每个推理步骤细分为32个token的迷你步骤,进一步增加搜索的粒度。
虽然token级别的搜索理论上提供了最大的灵活性和粒度,但由于所需的计算资源巨大和设计有效奖励模型的挑战,目前尚不切实际。
反思机制
在推理过程中,模型可能会在某些步骤上犯错,导致最终答案不正确。为了解决这个问题,引入了一种反思机制,提示模型在每个思维过程的末尾进行自我反思,并重新评估其推理步骤。
反思提示: 即在每个思维过程的末尾添加短语“Wait! Maybe I made some mistakes! I need to rethink from scratch.”,提示模型自我反思并重新评估其推理步骤。这种反思机制显著改善了模型在最初错误解决的难题上的表现。
自我批评: 从自我批评的角度来看,这种方法允许模型充当自己的批评者,识别其推理中的潜在错误。通过明确提示模型质疑其初步结论,鼓励其重新表达和改进其思维过程。这种自我批评机制利用了模型检测自身输出中不一致或错误的能力,从而导致更准确和可靠的问题解决。
实验结果
1. 数据集和模型配置
在以下两个数据集上测试Marco-o1模型的表现:
- MGSM(英语)数据集 :用于评估模型在英语推理任务上的表现。
- MGSM(中文)数据集 :用于评估模型在中文推理任务上的表现。
测试的模型配置:
- Owen2-7B-Instruct :作为基础模型进行对比。
- Marco-o1-CoT :通过思维链(CoT)微调后的模型。
- Marco-o1-MCTS(步骤) :使用每个推理步骤作为行动的MCTS增强模型。
- Marco-o1-MCTS(64个token的迷你步骤) :使用64个token的迷你步骤作为行动的MCTS增强模型。
- Marco-o1-MCTS(32个token的迷你步骤) :使用32个token的迷你步骤作为行动的MCTS增强模型。
2. 实验结果
在MGSM(英语)数据集上,各模型的准确性结果如下:
| 模型 | MGSM-En (Acc.) |
|---|---|
| Owen2-7B-Instruct | 84.23% |
| Marco-o1-CoT | 85.60% |
| Marco-o1-MCTS(步骤) | 90.40% |
| Marco-o1-MCTS(64个token的迷你步骤) | 88.40% |
| Marco-o1-MCTS(32个token的迷你步骤) | 87.60% |
结果表明:
- Marco-o1-CoT相对于Owen2-7B-Instruct有所提升,准确性提高了+1.37%。
- Marco-o1-MCTS(步骤) 表现最佳,准确性提高了+6.17%。
- Marco-o1-MCTS(64个token的迷你步骤) 和 Marco-o1-MCTS(32个token的迷你步骤) 也表现良好,但略低于步骤级别的MCTS。
在MGSM(中文)数据集上,各模型的准确性结果如下:
| 模型 | MGSM-Zh (Acc.) |
|---|---|
| Owen2-7B-Instruct | 76.80% |
| Marco-o1-CoT | 71.20% |
| Marco-o1-MCTS(步骤) | 80.00% |
| Marco-o1-MCTS(64个token的迷你步骤) | 80.40% |
| Marco-o1-MCTS(32个token的迷你步骤) | 82.40% |
结果表明:
- Marco-o1-CoT相对于Owen2-7B-Instruct有所下降,准确性降低了-5.60%。这可能是由于用于微调的CoT数据主要是英语,未能有效转移到中文数据集。
- Marco-o1-MCTS(步骤) 、 Marco-o1-MCTS(64个token的迷你步骤) 和 Marco-o1-MCTS(32个token的迷你步骤) 均表现良好,准确性分别提高了+3.20%、+3.60%和+5.60%。
- Marco-o1-MCTS(32个token的迷你步骤) 表现最佳,准确性提高了+5.60%。
为了展示Marco-o1模型在翻译任务中的能力,比较了其在翻译俚语和口语表达方面的表现与Google Translate。具体案例包括:
- 案例1 :将中文俚语“这双鞋有踩屎感”翻译为英语“This shoe has a comfortable sole”。
- 案例2 :将中文表达“美到我心巴上了,上身真的很韩,穿上软乎乎毛茸茸的厚度也刚好,里面搭配了打底衫,小特别且日常的穿搭”翻译为英语“It’s so beautiful that it’s captivating, the upper part has a distinctly Korean style, the soft and fluffy material is perfectly thick, and it’s complemented by a base layer, creating a unique and everyday-wear outfit”。
- 案例3 :将中文表达“太太太太好看了!而且价格这么便宜,超级板正不卷边,都买它,买它”翻译为英语“It’s so beautiful! And it’s so cheap, super straight and doesn’t curl. Buy it, buy it!”。
这些案例展示了Marco-o1在处理复杂翻译任务,特别是俚语和口语语言方面的先进理解和推理能力,优于标准翻译工具如Google Translate。

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)