
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-Coder-32B-Instruct-GPTQ-Int4"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "write a quick sort algorithm."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]

Qwen2.5-Coder深夜开源炸场,Prompt编程的时代来了!
通义千问团队开源「强大」、「多样」、「实用」的 Qwen2.5-Coder 全系列,致力于持续推动 Open Code LLMs 的发展。
·
01引 言
通义千问团队开源「强大」、「多样」、「实用」的 Qwen2.5-Coder 全系列,致力于持续推动 Open Code LLMs 的发展。
-
强大:Qwen2.5-Coder-32B-Instruct 成为目前 SOTA 的开源代码模型,代码能力追平 GPT-4o。在展现出强大且全面的代码能力的同时,具备良好的通用和数学能力;
-
多样:在之前开源的两个尺寸 1.5B/7B 的基础上,本次开源共带来四个尺寸的模型,包括 0.5B/3B/14B/32B。截止目前 Qwen2.5-Coder 已经覆盖了主流的六个模型尺寸,以满足不同开发者的需要;
-
实用:在两种场景下探索 Qwen2.5-Coder 的实用性,包括代码助手和 Artifacts,一些样例展示出 Qwen2.5-Coder 在实际场景中应用的潜力;
强大:代码能力达到开源模型 SOTA
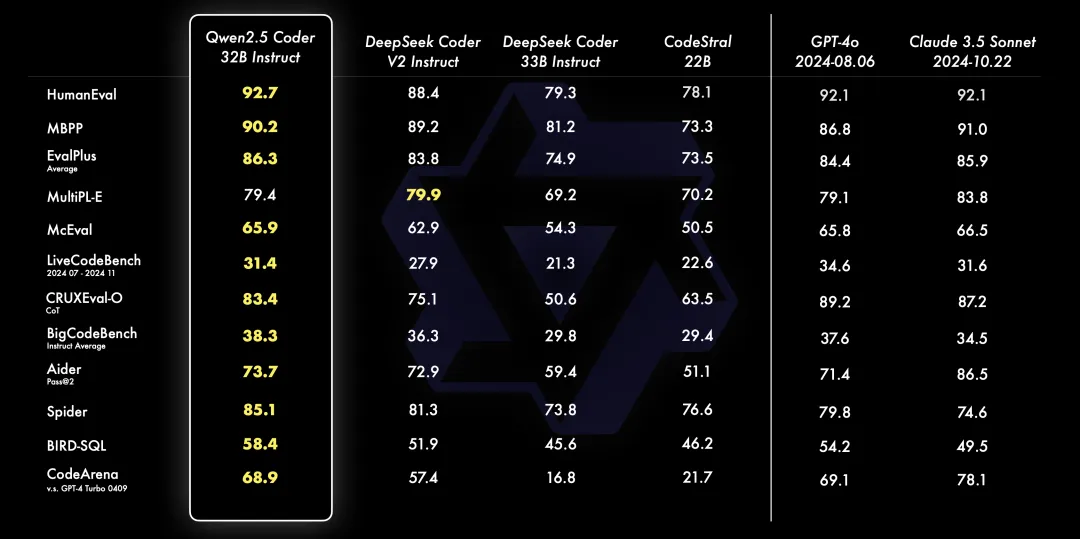
-
代码生成:Qwen2.5-Coder-32B-Instruct 作为本次开源的旗舰模型,在多个流行的代码生成基准(EvalPlus, LiveCodeBench, BigCodeBench)上都取得了开源模型中的最佳表现,并且达到和 GPT-4o 有竞争力的表现。
-
代码修复:代码修复是一个重要的编程能力,Qwen2.5-Coder-32B-Instruct 可以帮助用户修复代码中的错误,让编程更加高效。Aider 是流行的代码修复的基准,Qwen2.5-Coder-32B-Instruct 达到 73.7 分,在 Aider 上的表现与 GPT-4o 相当。
-
代码推理:代码推理指的是模型能否学习代码执行的过程,准确的预测模型的输入与输出。上个月发布的 Qwen2.5-Coder-7B-Instruct 已经在代码推理能力上展现出了不俗的表现,本次 32B 模型在代码推理上更进一步。
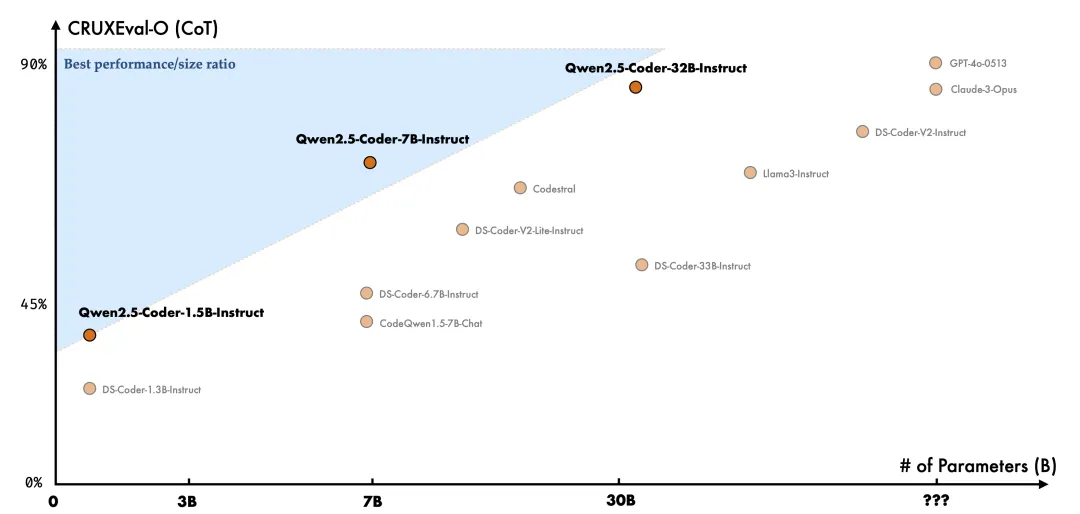
-
多编程语言:智能的编程助手应该熟悉所有编程语言,Qwen2.5-Coder-32B-Instruct 在 40 多种编程语言上表现出色,在 McEval 上取得了 65.9 的分数,其中 Haskell, Racket 等语言表现令人印象深刻,这得益于在预训练阶段独特的数据清洗和配比。
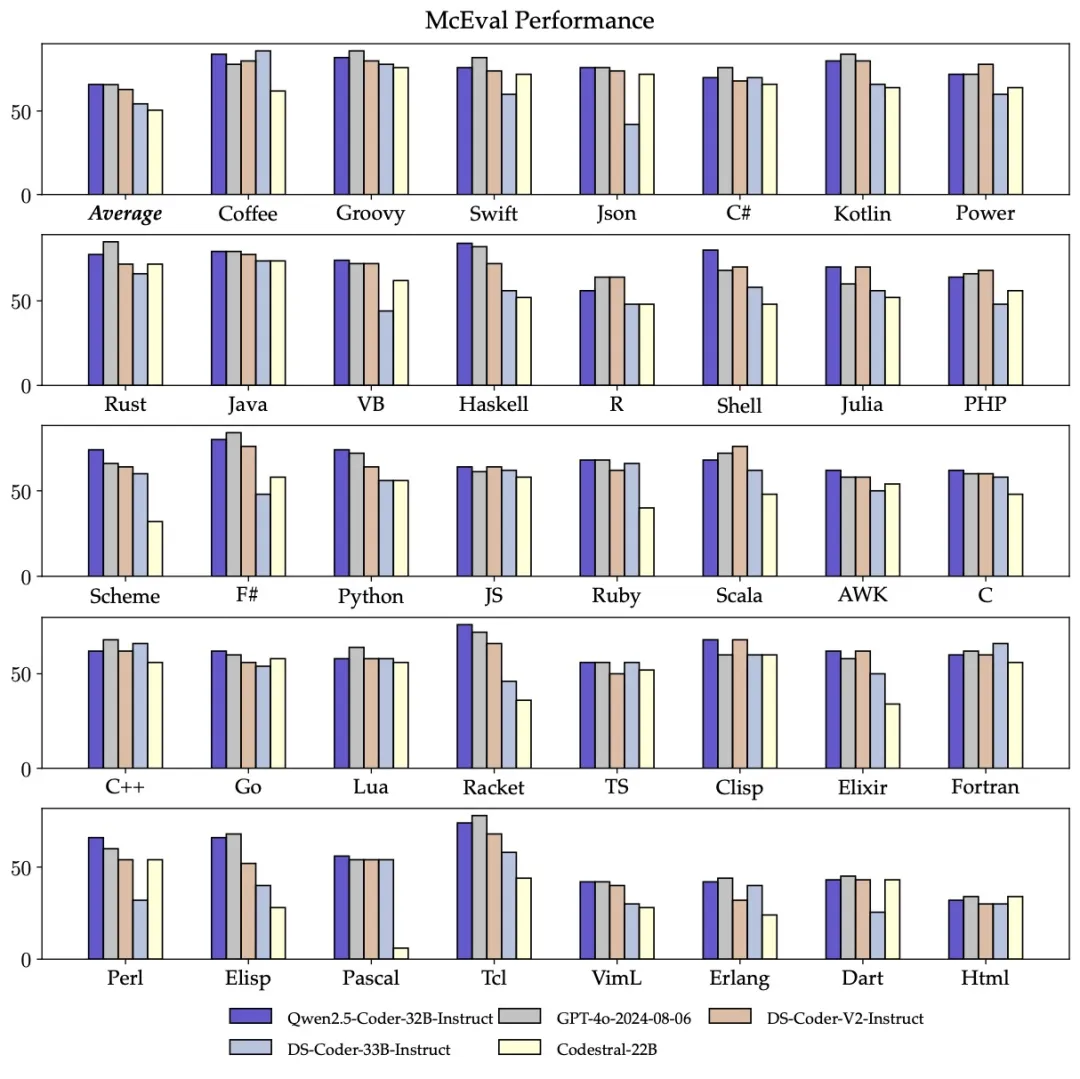
另外,Qwen2.5-Coder-32B-Instruct 的多编程语言的代码修复能力仍然令人惊喜,这将有助于用户理解和修改自己熟悉的编程语言,极大缓解陌生语言的学习成本。与 McEval 类似,MdEval 是多编程语言的代码修复基准,Qwen2.5-Coder-32B-Instruct 在 MdEval 上取得了 75.2 的分数,在所有开源模型中排名第一。
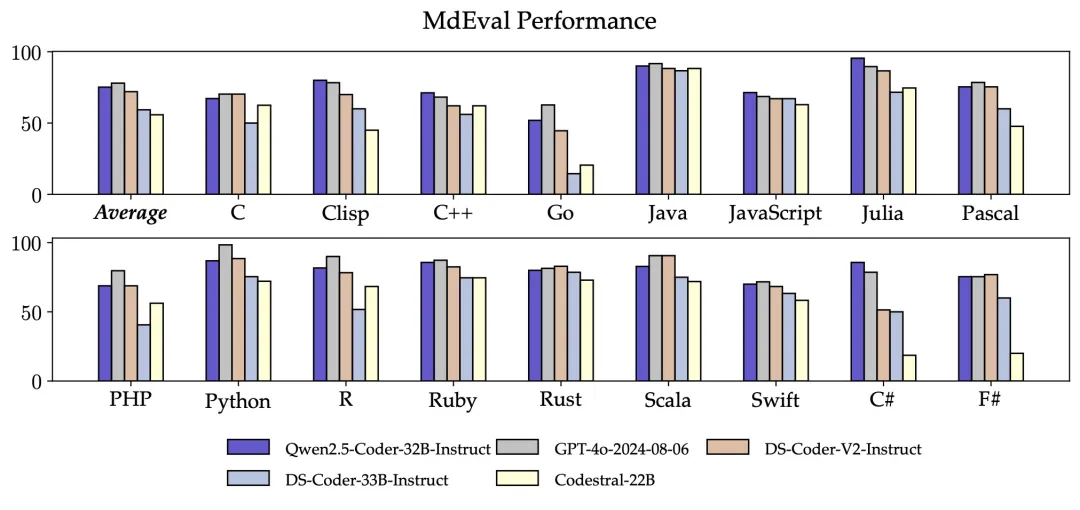
-
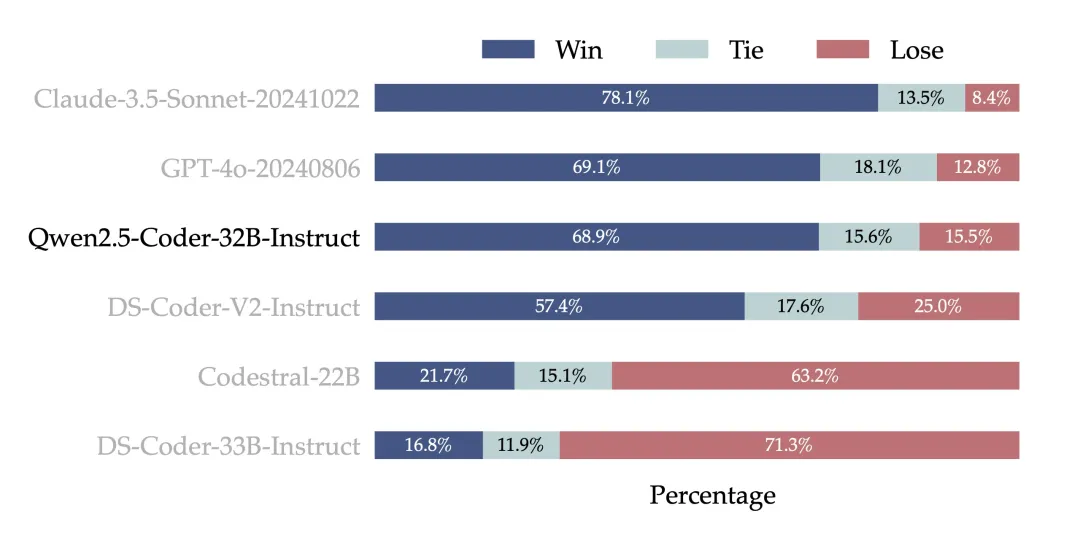
人类偏好对齐:为了检验 Qwen2.5-Coder-32B-Instruct 在人类偏好上的对齐表现,构建了一个来自内部标注的代码偏好评估基准 Code Arena(类似 Arena Hard)。采用 GPT-4o 作为偏好对齐的评测模型,采用 'A vs. B win' 的评测方式,即在测试集实例中,模型 A 的分数超过模型 B 的百分比。下图结果表现出 Qwen2.5-Coder-32B-Instruct 在偏好对齐方面的优势。
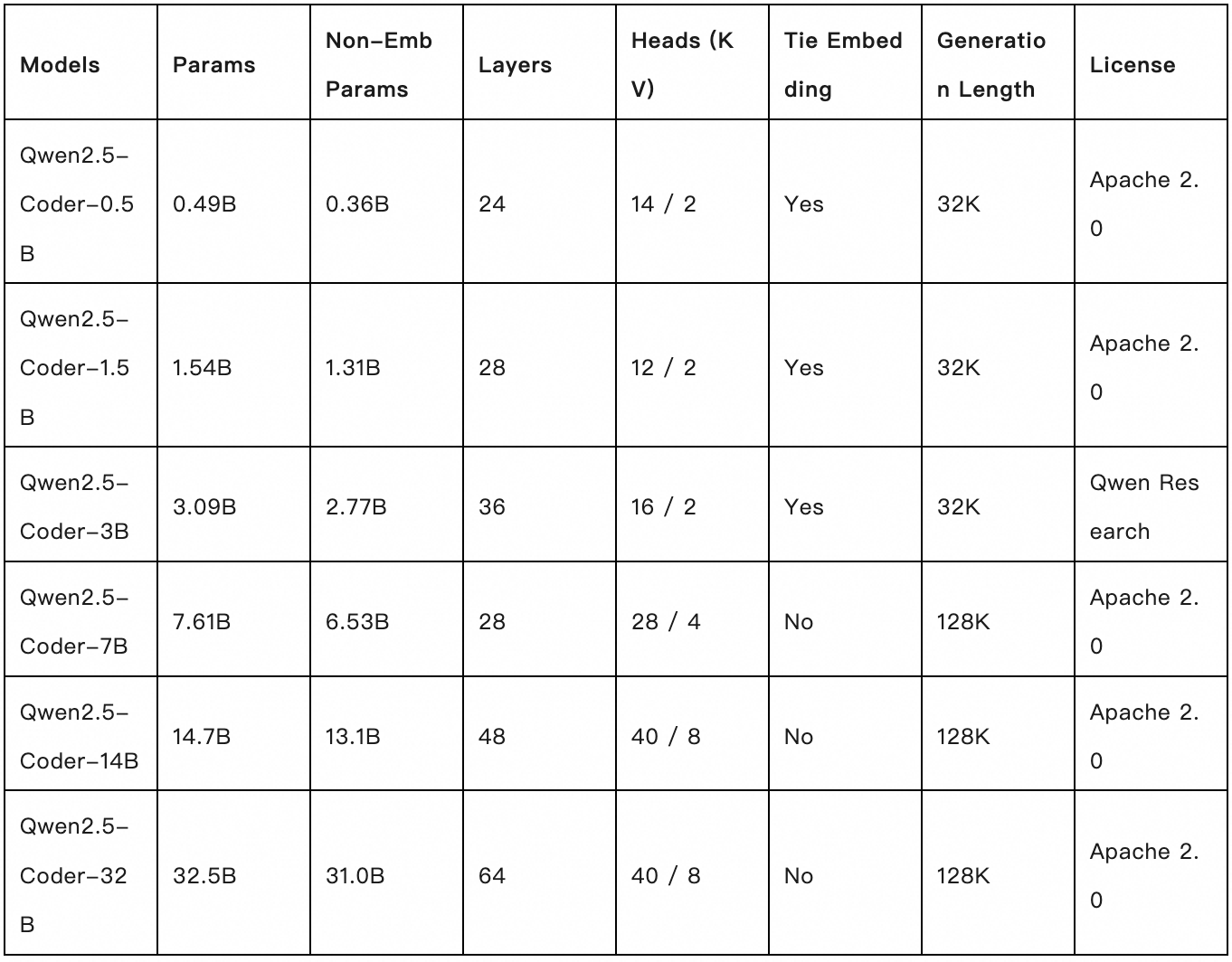
全面:丰富的模型尺寸
本次 Qwen2.5-Coder 开源了丰富的模型尺寸,共包含 0.5B/1.5B/3B/7B/14B/32B 六个尺寸,不仅能够满足开发者在不同资源场景下的需求,还能给研究社区提供良好的实验场。下表是详细的模型信息:
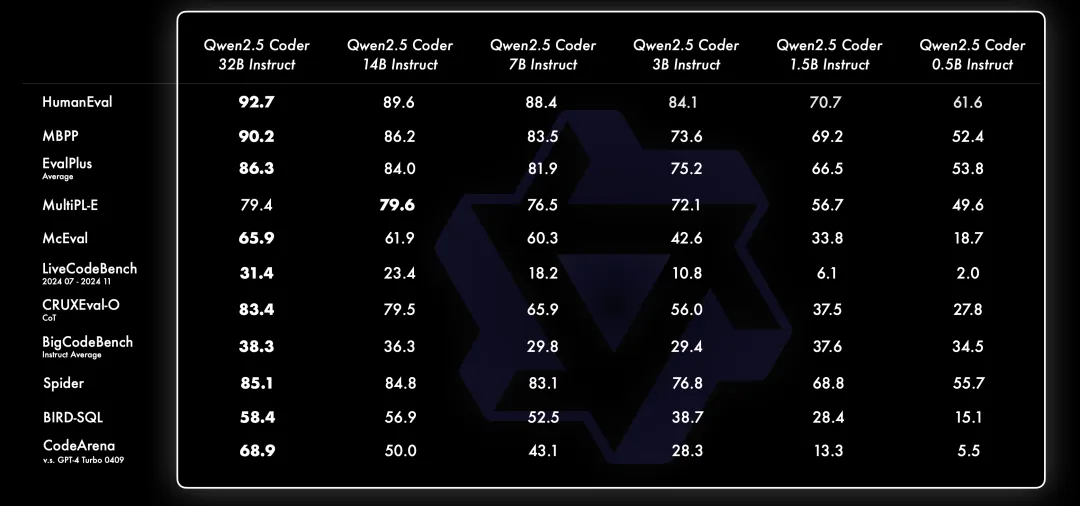
一直相信 Scaling Law 哲学。评估了不同尺寸的 Qwen2.5-Coder 在所有数据集上的表现,以验证 Scaling 在 Code LLMs 上的有效性。对于每一个尺寸,都开源了 Base 和 Instruct 模型,其中 Instruct 模型作是一个可以直接聊天的官方对齐模型,Base 模型作为开发者微调自己模型的基座。
下面是不同尺寸的 Instruct 模型表现:
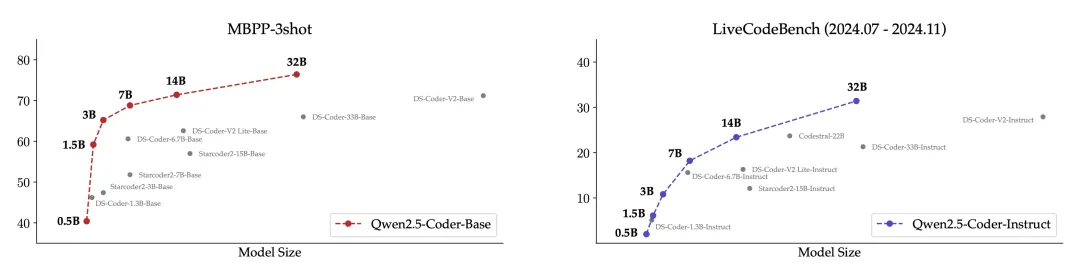
模型尺寸和模型效果之间符合预期的存在正相关,并且 Qwen2.5-Coder 在所有尺寸下都取得了 SOTA 的表现,这鼓励着继续探索更大尺寸的 Coder。
模型许可
Qwen2.5-Coder 0.5B/1.5B/7B/14B/32B 采用 Apache 2.0 的许可,3B 为 Research Only 许可;
02模型链接和体验
Qwen2.5-Coder模型链接:
https://modelscope.cn/collections/Qwen25-Coder-9d375446e8f5814a
模型集合demo链接:
https://modelscope.cn/studios/Qwen/Qwen2.5-Coder-demo
创空间体验链接:
https://modelscope.cn/studios/Qwen/Qwen2.5-Coder-Artifacts

Artifacts体验链接:
https://modelscope.cn/studios/Qwen/Qwen2.5-Coder-Artifacts
03模型推理
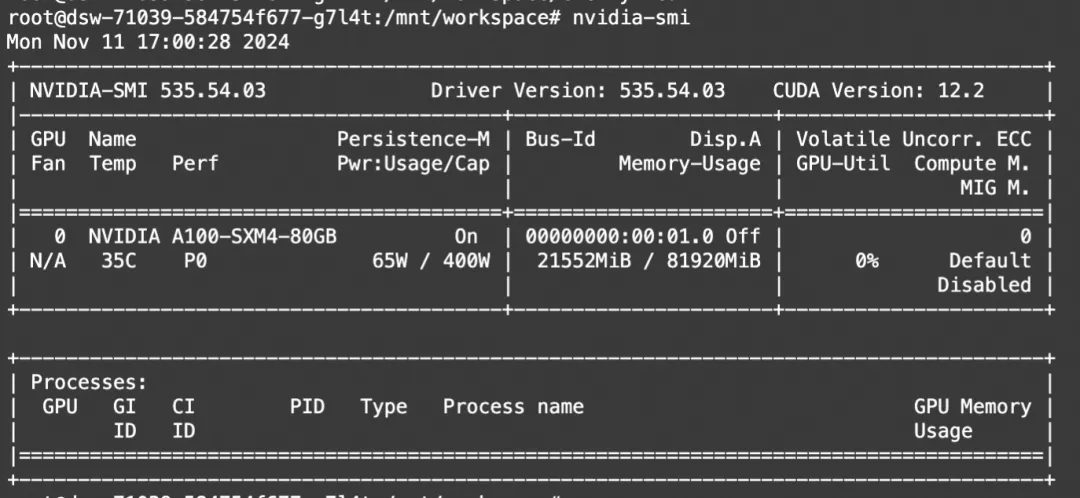
transformers: 单卡运行Qwen2.5-32B-Instrtuct量化模型。
显存占用:
Ollama:一行命令使用Ollama运行魔搭Qwen2.5-Coder GGUF模型
-
设置ollama下启用
ollama serve
-
ollama run ModelScope任意GGUF模型
ollama run modelscope.cn/Qwen/Qwen2.5-32B-Instruct-GGUF
在安装了Ollama的环境上(建议使用>=0.3.12版本),直接通过上面的命令行,就可以直接在本地运行 Qwen2.5-32B-Instruct-GGUF模型。
vLLM,推理加速
pip install vllm -U
export VLLM_USE_MODELSCOPE=True
vllm serve Qwen/Qwen2.5-Coder-7B-Instruct
推理代码:
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
completion = client.completions.create(model="Qwen/Qwen2.5-Coder-1.5B-Instruct",
prompt="San Francisco is a")
print("Completion result:", completion)
04模型微调
我们介绍使用ms-swift对qwen2.5-coder进行自我认知微调,并对微调后模型进行推理。swift开源地址:https://github.com/modelscope/ms-swift
自我认知数据集链接:https://modelscope.cn/datasets/swift/self-cognition
如果需要使用其他数据集进行微调,只需要修改 --dataset即可。自定义dataset支持传入本地路径、modelscope和huggingface中的dataset_id。文档可以查看:https://swift.readthedocs.io/zh-cn/latest/Instruction/%E8%87%AA%E5%AE%9A%E4%B9%89%E4%B8%8E%E6%8B%93%E5%B1%95.html#id3
在开始微调之前,请确保您的环境已正确安装:
# 安装ms-swift
git clone https://github.com/modelscope/ms-swift.git
cd swift
pip install -e .[llm]
微调脚本:
# Experimental environment: A10, 3090, V100, ...
# 15GB GPU memory
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type qwen2_5-coder-3b-instruct \
--model_id_or_path qwen/Qwen2.5-Coder-3B-Instruct \
--dataset swift/self-cognition#500 \
AI-ModelScope/Magpie-Qwen2-Pro-200K-Chinese#500 \
AI-ModelScope/Magpie-Qwen2-Pro-200K-English#500 \
--logging_steps 5 \
--max_length 4096 \
--learning_rate 1e-4 \
--output_dir output \
--lora_target_modules ALL \
--model_name 小黄 'Xiao Huang' \
--model_author 魔搭 ModelScope \
--system 'You are a helpful assistant.'
微调显存消耗:

微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的last checkpoint文件夹。
# Experimental environment: A10, 3090, V100, ...
# 直接推理
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/qwen2_5-coder-3b-instruct/vx-xxx/checkpoint-xxx
# 使用vLLM进行推理加速
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/qwen2_5-coder-3b-instruct/vx-xxx/checkpoint-xxx \
--infer_backend vllm --max_model_len 8192 --merge_lora true
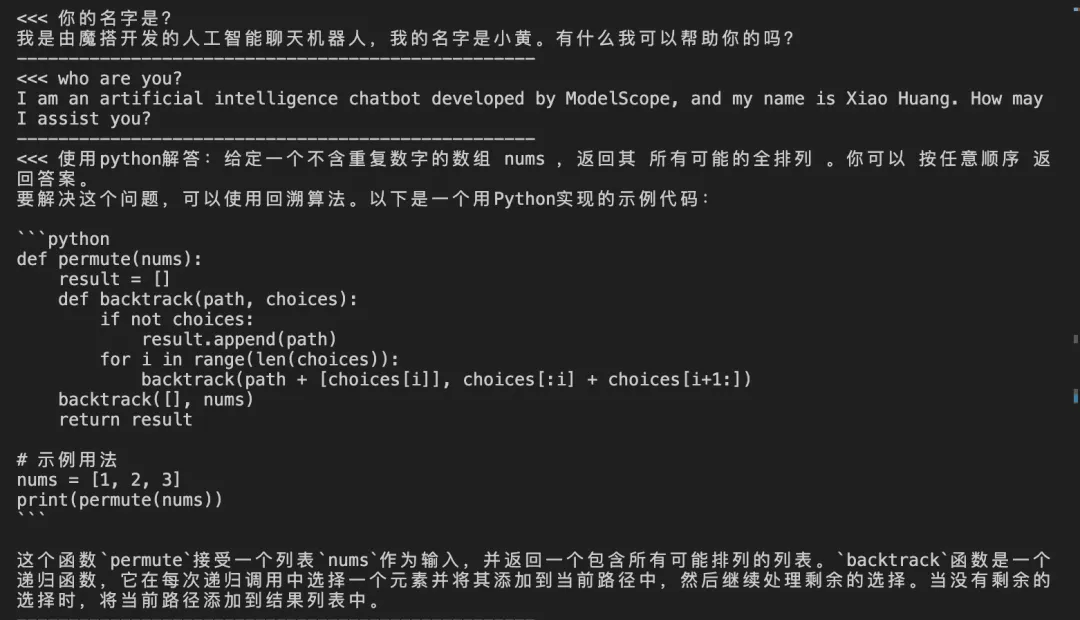
推理结果:
05模型应用:Cursor,Artifacts 和 interpreter
实用的 Coder 一直是Qwen的愿景,为此本次探索了 Qwen2.5-Coder 在代码助手、 Artifacts 、interpreter场景下的实际表现。
Qwen2.5-Coder 遇到 Cursor:万能代码小助手
智能代码助手目前已经得到广泛的应用,但目前大多依赖闭源模型,希望 Qwen2.5-Coder 的出现能够为开发者提供一个友好且强大的选择。
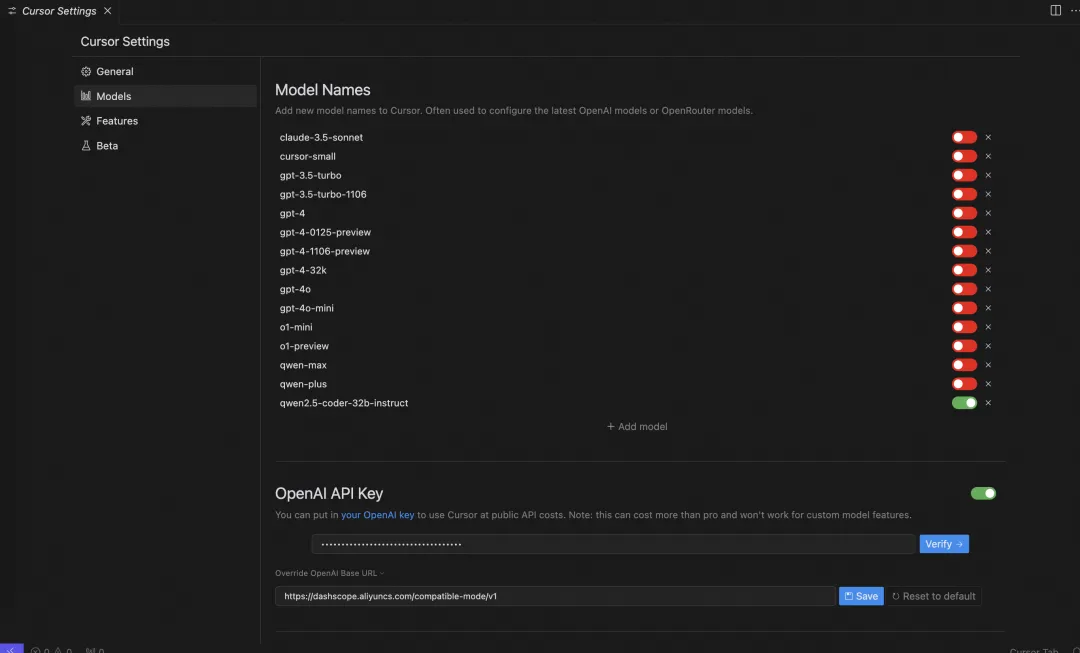
配置Qwen2.5-Coder-32B-Instruct的openai兼容api(URL和API Key)
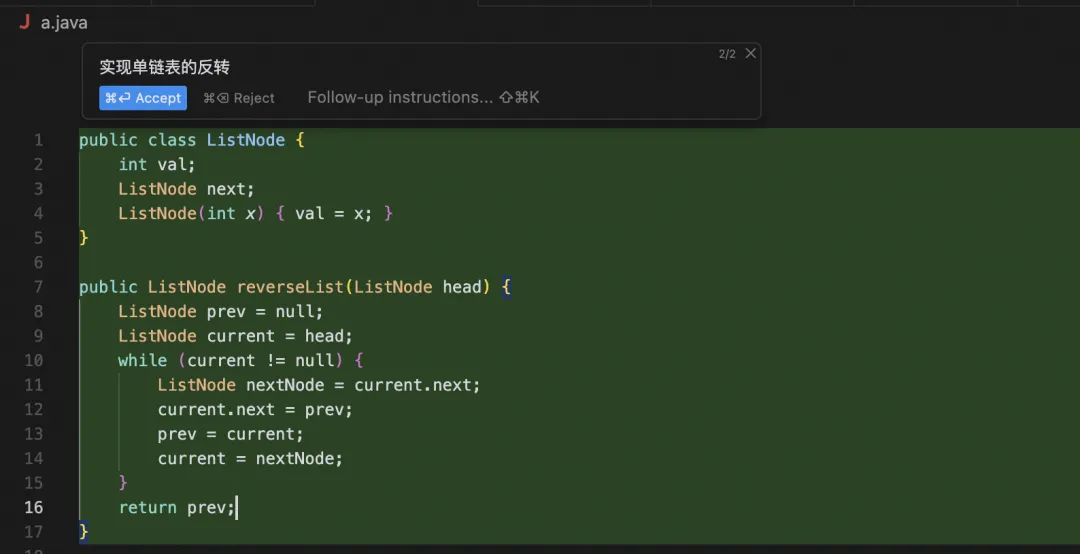
体验Qwen2.5-Coder强大的生成/编辑/补全能力吧!(Command+K)
Qwen2.5-Coder 遇到 Artifacts:prompt编程不是梦
Artifacts 是代码生成的重要应用之一,帮助用户创作一些适合可视化的作品,clone魔搭创空间,即可本地搭建一个Artifacts。
git clone https://www.modelscope.cn/studios/Qwen/Qwen2.5-Coder-Artifacts.git
cd Qwen2.5-Coder-Artifacts
pip install -r requirements.txt
pip install gradio
python app.py
制作游戏
制作动图

SVG作画

Qwen2.5-Coder 遇到 Interpreter:AI操作电脑
在MAC安装环境
pip install open-interpreter
进入Python环境:
from interpreter import interpreter
interpreter.llm.api_base = "YOUR_BASE_URL"
interpreter.llm.api_key = "YOUR_API_KEY"
interpreter.llm.model = "openai/Qwen-Coder-32B-Instruct"
interpreter.chat("Can you set my system to light mode?")
示例视频:
点击链接👇,直达模型体验
https://modelscope.cn/studios/Qwen/Qwen2.5-Coder-demo?from=csdnzishequ_text

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献411条内容
已为社区贡献411条内容

所有评论(0)