
from PIL import Image
from transformers import AutoTokenizer, AutoModel, AutoImageProcessor, AutoModelForCausalLM
from transformers.generation.configuration_utils import GenerationConfig
from transformers.generation import LogitsProcessorList, PrefixConstrainedLogitsProcessor, UnbatchedClassifierFreeGuidanceLogitsProcessor
import torch
from modelscope import snapshot_download
# model path
EMU_HUB = snapshot_download("BAAI/Emu3-Stage1")
VQ_HUB = snapshot_download("BAAI/Emu3-VisionTokenizer")
import sys
sys.path.append(EMU_HUB)
from processing_emu3 import Emu3Processor
# prepare model and processor
model = AutoModelForCausalLM.from_pretrained(
EMU_HUB,
device_map="cuda:0",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained(EMU_HUB, trust_remote_code=True, padding_side="left")
image_processor = AutoImageProcessor.from_pretrained(VQ_HUB, trust_remote_code=True)
image_tokenizer = AutoModel.from_pretrained(VQ_HUB, device_map="cuda:0", trust_remote_code=True).eval()
processor = Emu3Processor(image_processor, image_tokenizer, tokenizer, chat_template="{image_prompt}{text_prompt}")
# Image Generation
# prepare input
POSITIVE_PROMPT = " masterpiece, film grained, best quality."
NEGATIVE_PROMPT = "lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry."
classifier_free_guidance = 3.0
prompt = "a portrait of young girl."
prompt += POSITIVE_PROMPT
kwargs = dict(
mode='G',
ratio="1:1",
image_area=model.config.image_area,
return_tensors="pt",
padding="longest",
)
pos_inputs = processor(text=prompt, **kwargs)
neg_inputs = processor(text=NEGATIVE_PROMPT, **kwargs)
# prepare hyper parameters
GENERATION_CONFIG = GenerationConfig(
use_cache=True,
eos_token_id=model.config.eos_token_id,
pad_token_id=model.config.pad_token_id,
max_new_tokens=40960,
do_sample=True,
top_k=2048,
)
h = pos_inputs.image_size[:, 0]
w = pos_inputs.image_size[:, 1]
constrained_fn = processor.build_prefix_constrained_fn(h, w)
logits_processor = LogitsProcessorList([
UnbatchedClassifierFreeGuidanceLogitsProcessor(
classifier_free_guidance,
model,
unconditional_ids=neg_inputs.input_ids.to("cuda:0"),
),
PrefixConstrainedLogitsProcessor(
constrained_fn ,
num_beams=1,
),
])
# generate
outputs = model.generate(
pos_inputs.input_ids.to("cuda:0"),
GENERATION_CONFIG,
logits_processor=logits_processor,
attention_mask=pos_inputs.attention_mask.to("cuda:0"),
)
mm_list = processor.decode(outputs[0])
for idx, im in enumerate(mm_list):
if not isinstance(im, Image.Image):
continue
im.save(f"result_{idx}.png")
# Multimodal Understanding
text = "The image depicts "
image = Image.open("assets/demo.png")
inputs = processor(
text=text,
image=image,
mode='U',
padding="longest",
return_tensors="pt",
)
GENERATION_CONFIG = GenerationConfig(
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=1024,
)
outputs = model.generate(
inputs.input_ids.to("cuda:0"),
GENERATION_CONFIG,
attention_mask=inputs.attention_mask.to("cuda:0"),
)
outputs = outputs[:, inputs.input_ids.shape[-1]:]
answers = processor.batch_decode(outputs, skip_special_tokens=True)
for ans in answers:
print(ans)
统一多模态模型来了!智源发布多模态世界模型Emu3!
2024年10月21日,智源研究院正式发布原生多模态世界模型Emu3。
·
2024年10月21日,智源研究院正式发布原生多模态世界模型Emu3。该模型使用单一的Transformer进行训练,并通过将图像、文本和视频等不同模态的数据转化为离散空间中的令牌来进行预测。只基于下一个token预测,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成,并超越传统任务特定模型的效果,在生成和感知任务中都达到了SOTA的水平。此外,该模型还可以生成高保真度的视频序列。研究团队认为,这种方法是构建跨语言多模态智能的重要一步,并开源了关键技术和模型以支持进一步的研究。
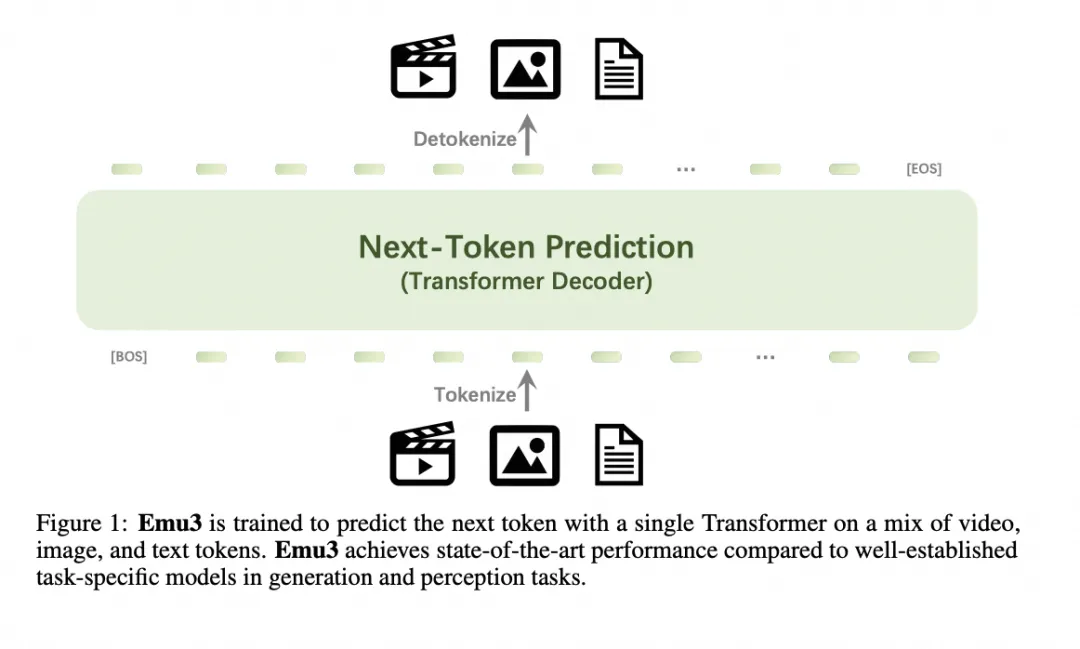
模型效果:
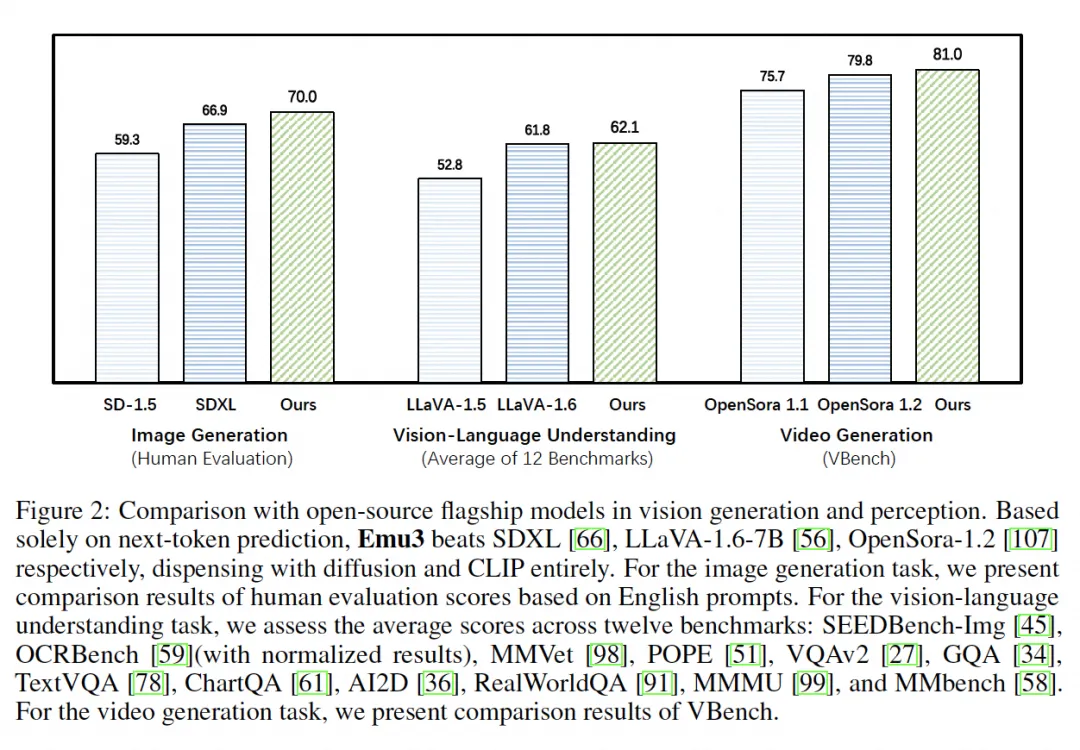
在图像生成方面,通过自动化评价指标对Emu3在四个流行文本到图像基准数据集(MSCOCO-30K、GenEval、T2I-CompBench和DPG-Bench)上的性能进行了评估。结果表明,尽管Emu3没有使用任何预训练的语言模型,但在与扩散方法、自回归扩散方法和基于自回归的方法的比较中表现出色,特别是在密集注释的任务上。此外,研究团队还通过引入重写器进一步评估了Emu3的表现,并将其与其他最先进的扩散模型进行了比较,结果表明Emu3在这些基准数据集上的表现与其相当甚至更好。
其次,在视频生成方面,研究团队将Emu3与13个最佳开源和专有文本到视频模型进行了定量比较。作者使用的评估工具VBench可以评估每个模型的质量和语义能力。结果显示,尽管Emu3不如一些先进的专有模型如Kling和Gen-3,但它在大多数开源文本到视频模型中的表现都很好。
最后,在视觉语言理解方面,研究团队测试了Emu3在各种公共视觉语言基准数据集上的表现。结果表明,Emu3可以在多个基准数据集上超越其竞争对手,这证明了Emu3在多模态理解方面的潜力。
01
图片生成效果测试
简单 Prompt

复杂 Prompt

多实体生成能力很能打,颜色能做到分别控制
多风格

强
多样性

模型地址:
https://modelscope.cn/collections/Emu3-9eacc8668b1043
论文地址:
https://arxiv.org/pdf/2409.18869
代码地址:
https://github.com/baaivision/Emu3
02
模型推理
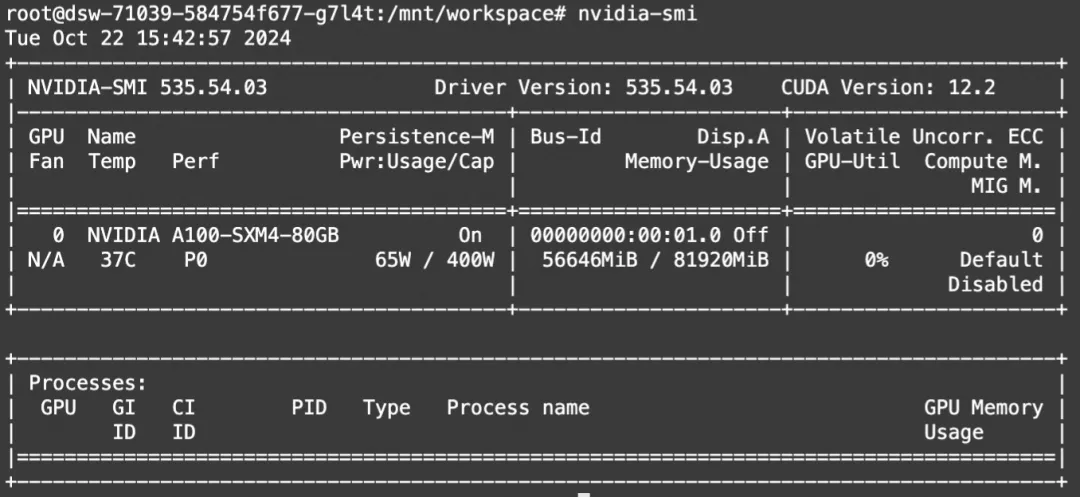
模型推理(单卡80G显存):
图片生成显存占用:
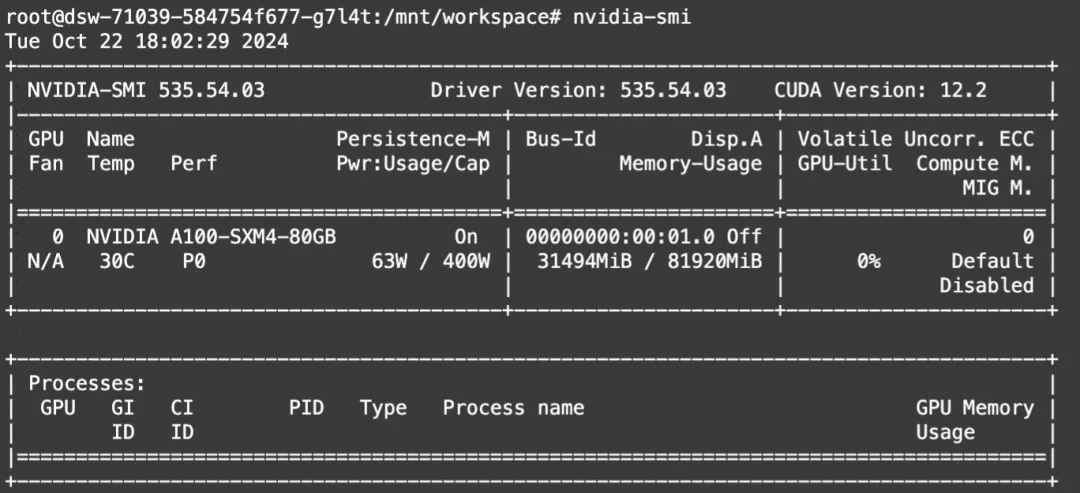
多模态理解显存占用:
03
模型微调
我们使用ms-swift对Emu3-Chat进行微调。ms-swift是魔搭社区官方提供的大模型与多模态大模型微调推理框架。
ms-swift开源地址:
https://github.com/modelscope/ms-swift
通常,多模态大模型微调会使用自定义数据集进行微调。在这里,我们将展示可直接运行的demo。我们使用 coco-en-mini数据集:https://modelscope.cn/datasets/modelscope/coco_2014_caption进行微调。
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/ms-swift.git
cd ms-swift
pip install -e .[llm]微调脚本:
# 默认:微调 LLM, 冻结 image tokenizer
CUDA_VISIBLE_DEVICES=0 swift sft \
--model_type emu3-chat \
--model_id_or_path BAAI/Emu3-Chat\
--sft_type lora \
--dataset coco-en-mini#500
# Deepspeed ZeRO2
NPROC_PER_NODE=4 \
CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type emu3-chat \
--model_id_or_path BAAI/Emu3-Chat \
--sft_type lora \
--dataset coco-en-mini#500 \
--deepspeed default-zero2训练显存占用:
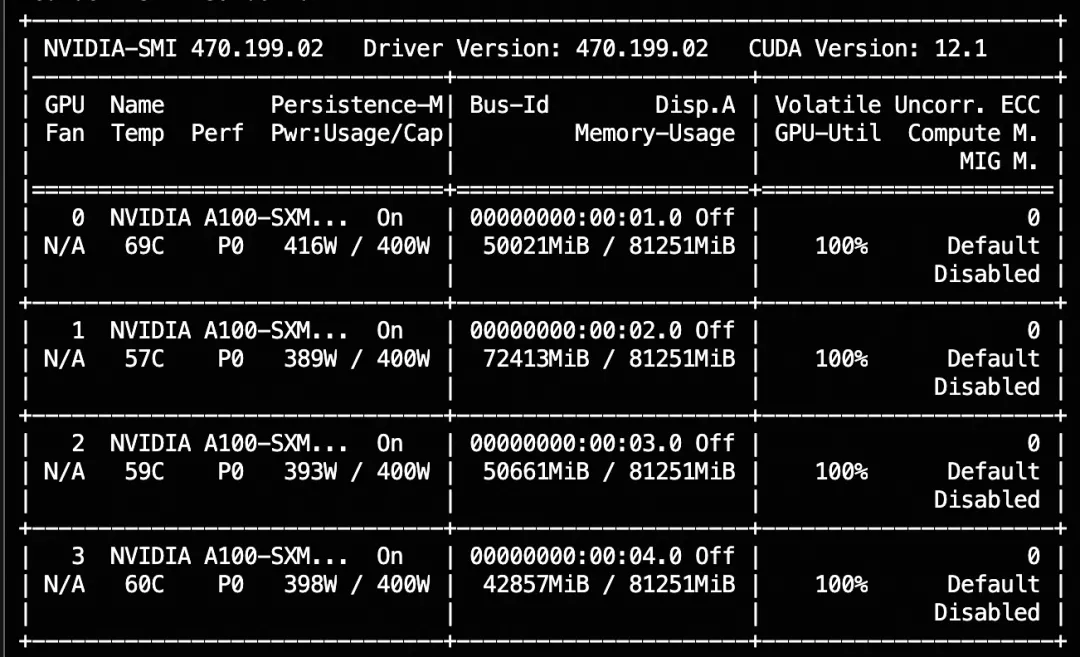
如果要使用自定义数据集,只需按以下方式进行指定:
# val_dataset可选,如果不指定,则会从dataset中切出一部分数据集作为验证集
--dataset train.jsonl \
--val_dataset val.jsonl \
{"query": "<image>55555", "response": "66666", "images": ["image_path"]}
{"query": "<image><image>eeeee", "response": "fffff", "history": [], "images": ["image_path1", "image_path2"]}
{"query": "EEEEE", "response": "FFFFF", "history": [["query1", "response1"], ["query2", "response2"]]}训练loss图:
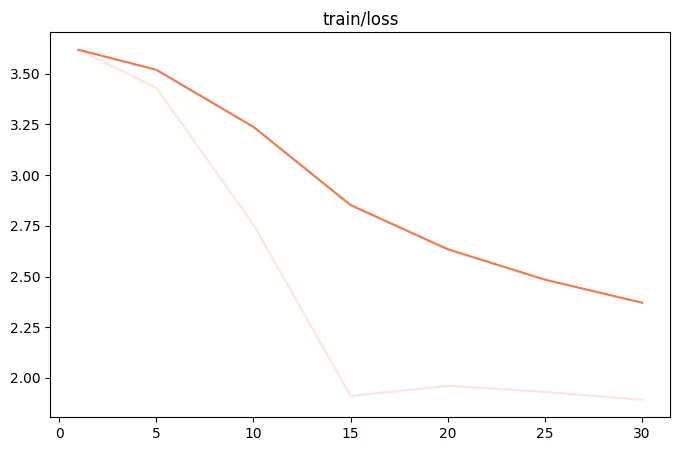
微调后推理脚本如下:
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/emu3-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true
# or merge-lora & infer
CUDA_VISIBLE_DEVICES=0 swift infer \
--ckpt_dir output/emu3-chat/vx-xxx/checkpoint-xxx \
--load_dataset_config true --merge_lora true微调后模型对验证集进行推理的结果:

点击链接👇,即可跳转详情~

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!
更多推荐



 0
0 0
0- 0



 已为社区贡献660条内容
已为社区贡献660条内容

所有评论(0)